数据挖掘中常用分类算法的分析比较*
2015-12-09丁浩
丁 浩
(安徽工商职业学院 国际贸易系,安徽 合肥231131)
1 数据挖掘中的分类问题及其研究现状
从本质上来说,数据挖掘(Data Mining)就是“从大量数据中获取有效的、潜在有用的并且最终可理解的知识或模式的非平凡过程”[1].可以这样理解,就是从大量的数据里提取或者“挖掘”知识.数据挖掘涉及统计学、数据库、人工智能和机器学习等多个领域,是一门交叉学科.其工作的简要过程,如图1所示.
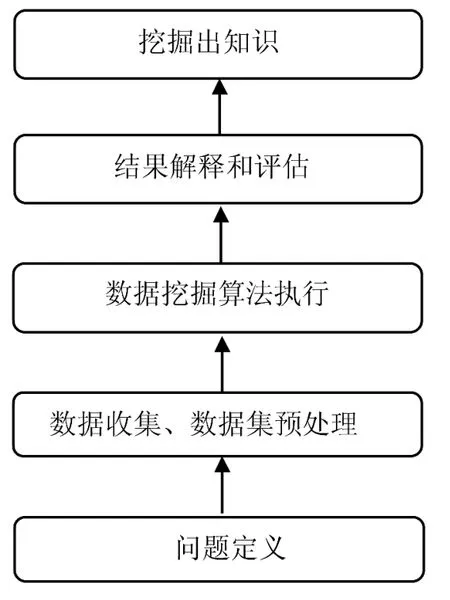
图1 数据挖掘的一般过程
数据挖掘的主要任务有分类、预测、关联分析、聚类、时序模式分析及偏差分析等.数据分类是数据挖掘中一项非常重要的技术,一直是研究的热点之一.由于不同的分类算法会产生不同的分类器,而分类器的好坏又会直接影响到分类结果的准确性和数据挖掘的效率,因而当对大规模的海量数据进行分类时,选择最合适的分类算法是非常关键的.
近年来,国内外对数据挖掘分类算法的研究主要集中在以下两个方面:一是直接将传统的分类算法或者组合应用到实际案例中,开发出各种应用系统;二是对传统分类算法进行改进或在小数据集上验证各种改良算法.而对各种分类算法进行深入的对比研究的并不多[2].本文对各种分类算法进行深入的分析比较,总结了各自的优缺点及适用情境,为今后各种分类方法的选择应用提供参考和借鉴,也便于相关研究者明确算法的改进点和研究方向.
2 常用分类算法的分析比较
目前数据挖掘中使用频率最高的分类算法主要有三类:①基于决策树的分类算法,如ID3、C4.5等;②基于神经网络的分类算法,如人工神经网络;③基于统计学的分类算法,如朴素贝叶斯、贝叶斯网络等.
2.1 基于决策树的分类算法
决策树(Decision Tree,DC)分类法是一种以数据集为基础,从一组无次序、无规则的样本数据中推理出分类规则的归纳学习算法.是将构成决策方案的有关因素以树形图的方式表现出来,并据以分析和选择决策方案的一种系统分析分类方法,能够形象地显示出整个决策问题在不同阶段及各时间节点上的决策过程,层次分明,逻辑清晰,形象直观,表示出来很像一棵树[3].例如,一个年轻女孩在别人给她介绍男友时,是否去见面的决策过程(图2),就是一个简单的决策树.

图2 决策树示意图
常用的决策树算法有ID3算法、C4.5算法以及它们的升级版ID4、C5.0算法等.
与其他分类算法相比,决策树算法有如下优点:①易于理解和实现:对数据挖掘使用者来说,这种易理解性是一个非常显著的优点.②速度快:计算量相对较小,且容易转化成分类规则.③准确性高:使用决策树分类法可以得出准确率很高的分类规则,而且可以清楚地看出哪些字段是比较重要的.
决策树算法也存在一些缺点:首先,对于连续型变量必须离散化才能被学习和分类.其次,对于有时间顺序的数据,需要进行很多预处理,从而加大了工作量.还有,当类别太多时使用决策树算法,错误的可能性就会增加得比较快.
为此,有人提出了一些改进的决策树算法,如SLIQ(监 督学 习 任务,super-vised lear ning in quest)算法.该算法在决策树的构造过程中随记录个数和属性个数增长,采用了预排序以及广度优先增长策略[3].因此在一定程度上具有良好的可扩展性.但仍然存在着一些不足:一是该算法需要将类别列表存放于内存,能够处理的数据集大小必然就受到限制;二是采用了预排序,但排序算法的复杂度本身就是一个问题.因此,SLIQ算法几乎不可能达到随记录数增长的线性可扩展性.于是又有学者提出SPRINT(可扩展并行感应决策树,scalable parallelizable induction of decision trees)算法,以减少驻留内存的数据量,并且使寻找每个结点的最优分裂标准变得更简单,但该算法对非分裂属性的处理又很困难[3].
2.2 基于神经网络的分类算法
神经网络(Neural Net wor k,NN),全称人工神经网络,是模拟人脑结构和功能、由大量的“神经元”(或称节点)相互联接构成的一种可以进行分布式、并行动态信息处理的数学模型.一个神经网络由一个多层神经元结构组成,每一层神经元拥有输入和输出(同时也是后一层的输入).如一种常见的多层结构的前馈网络由三个层次结构组成:输入层、隐含层和输出层[4],如图3所示.

图3 神经网络模型
神经网络的优点很多:①分类精度高;②良好的鲁棒性;③较强的自主学习和记忆能力;④超强的容错能力;⑤可用于求解一些非常复杂的问题,因为神经网络具有很强的非线性拟合能力,甚至可以通过对变量反复多次进行线性组合后再进行非线性变换,从而可映射任意复杂的非线性关系.因此,在非线性问题的处理上神经网络堪为首选.
但是,神经网络算法也有其不足之处:其最突出问题是,要真正建立一个好的神经网络其实非常困难,工作量很大,时间周期也很长;另一个不足之处是对网络的解释,难以从网络中提取规则.这些使得神经网络在其出现初期曾经一度不被看好.为此,有学者提出在提取规则之前对网络进行前剪枝,以删除那些对分类准确性影响极小或者几乎没有影响的链枝和神经元,从而简化生成的网络.后来又出现了一些用训练过的神经网络提取规则的算法,“使得神经网络用于数据挖掘逐渐显示出其强大的生命力”[4].但是神经网络算法对海量数据处理时仍存在时间效率问题,因而需要同其他方法结合使用,方可达到理想的效果.
2.3 基于统计学的分类算法
基于统计学的分类算法,其最大特点是用概率来表示所有形式的不确定性,推理或学习都用概率规则来进行.换言之,就是在各种条件存在不确定而仅知其出现概率的情况下完成推理和决策任务.
朴素贝叶斯(Naive Bayes,NB)分类是统计学分类算法中最经典的一种,算法也十分简单:“对于给定的待分类项,求解在此项出现的条件下各个类别出现的概率,然后看哪个最大,就认为此待分类项属于哪个类别”[1].朴素贝叶斯分类算法基于独立性假设,也就是设在给定类别C的条件下,所有的属性xi(i=1,2,…n)相互独立.即:

从而建立一种相对简单的分类模型——朴素贝叶斯模型,如图4所示.模型中各个属性变量xi独立地作用于类变量C.

图4 朴素贝叶斯模型
朴素贝叶斯分类算法的主要特点和优势有:①算法逻辑简单,易于实现;②时间、空间开销较小,占用的系统资源较少,因而速度快;③有坚实的数学基础,分类精度较高;④性能稳定,即具有良好的鲁棒性.
尽管是带着一些朴素思想和过于简单化的假设,但朴素贝叶斯分类器在很多复杂的现实问题的处理中仍能够取得相当好的效果.对各种分类法比较的有关研究表明:朴素贝叶斯分类法在分类性能上并不逊色于决策树和神经网络等其他方法.实践证明,在处理大规模数据库时,朴素贝叶斯分类的运算性能和分类准确性甚至优于其他方法[5].因而在实际应用中,朴素贝叶斯分类被广泛采用.
当然其缺点也显而易见,就是必须以独立性假设为前提,因为该限制在现实中往往很难满足,从而可能会导致分类准确率下降,这在一定程度上限制了朴素贝叶斯算法的适用范围.
于是,又就出现了一些降低独立性要求的贝叶斯算法,如贝叶斯网络(Bayes Net wor k,BN),允许在变量子集间定义类条件独立性,采用一种带有概率注释的有向无环图来描述变量之间关系.如描述Smoking(吸烟)、l ung Cancer(肺癌)、Br onchitis(支气管炎)、X-ray(需照X光)以及Dyspnea(呼吸困难)之间的因果关系的贝叶斯网络(图5).

图5 贝叶斯网络模型
此外,改进的贝叶斯分类算法还有树扩展朴素贝叶斯TAN(Tree Aug mented Naive Bayes)算法等.但是,所有基于统计学的贝叶斯分类算法在处理非线性样本数据和含噪声或孤立点数据时,其分类准确性仍存在问题.
2.4 其他分类算法
基于数据库的分类算法,如MIND(mining in database)算法,采用数据库中用户定义的函数实现发现分类规则.该算法分类准确度高,执行速度快,有良好的可伸缩性,缺点是参数取值需用户完成等.
基于关联规则的分类算法,如CBA(classification based on association)算法.该算法分两步:①搜索所有右部为类别属性值的类别关联规则;②选择具有最高置信度的规则作为可能规则.这两步都具有线性可伸缩性.基于关联规则的分类算法还有CAEP、JEP、CMAR等[6].
基于类比学习的K-最临近分类算法,是一种懒散的学习法,由于要存储所有训练样本,因而在大的数据集上学习会出现困难.
此外,还有一些方法在商业化数据挖掘中较少用于分类,但随着时代进步和新技术的不断发展似乎也变得日趋流行,如基于案例的推理分类法CBR、遗传算法、粗糙集和模糊集方法等等.和前面几种相对成熟的分类算法相比,这些方法在分类准确率、时间效率、鲁棒性、可解释性及可伸缩性等方面都存在一定的差距,笔者不再一一分析介绍.
3 分类技术发展展望
虽然现在分类算法已有很多,有的还很成熟,但通过各种算法比较分析以及从国内外研究与应用的实际效果来看,尚未发现一种方法绝对优于其他方法.如今已进入大数据时代,面对海量数据,各种算法在准确性、时间效率、鲁棒性等方面都或多或少地出现了一些问题.因此,近年来越来越多的人采取将各种方法有机结合,取长补短,组合应用到数据挖掘中,取得了较好的效果.为了解决目前数据挖掘分类中出现的新问题,一些学者甚至已经开始尝试将人工智能领域最新技术——混合智能系统引入,进行模型整合.但是,与数据挖掘分类算法怎样结合以及模型整体结构、算法参数选取等[7]又成为需要解决的富有挑战性的新问题.
4 结束语
本文在对数据挖掘中分类算法的研究现状进行分析的基础上,对目前三种使用频率最高的分类算法,即决策树算法、神经网络算法和贝叶斯算法进行了详细的分析讨论,总结了各种算法的优点、缺陷和适用情境.对其他分类算法也作了一些简单的分析介绍.此外,还对数据挖掘分类技术的未来发展进行了展望.以期为今后各种分类方法在实际问题中的选择应用提供一些参考和借鉴,以便更有效地解决相关问题.同时也希望可以有助于相关研究者进一步明确各种算法的改进点和今后研究的努力方向.
[1]范明,孟小峰.数据挖掘概念与技术[M].北京:机械工业出版社,2007.
[2]王明星.数据挖掘算法优化研究与应用[D].合肥:安徽大学,2014.
[3]张曼,邵明文,史鸿戬.基于包含度的决策树分类算法的改进[J].电子技术与软件工程,2015(9):212-214.
[4]覃梅.数据挖掘分类算法在信用卡风险管理中的应用[J].现代计算机:专业版,2013(19):13-16.
[5]陶新民,郝思媛,张冬雪,等.不均衡数据分类算法的综述[J].重庆邮电大学学报:自然科学版,2013,25(1):102-110.
[6]LI Xiang,LI Tao.Classification Algorithm of Kernelbased In Adaboost[J].Co mputer Knowledge and Technology,2011,7(28):6970-6979.
[7]ZHU Ming,TAO Xin min.The SV M Classifier For Unbalanced Data Based on Combination of RU-Undersample And SMOTE[J].Inf or mation Technology,2012(1):39-41.
