无标注的含噪中文长篇幅语音文本的文语对齐研究*
2015-12-02王永远贾晓茹李传越
张 巍,王永远,贾晓茹,李传越
(中国海洋大学信息科学与工程学院,山东 青岛 266100)
近年来,随着互联网的飞速发展,网络上各种多媒体资源越来越多,可以直接在网络上获得大量的语音及其对应文本的资源。但是,这些资源中的文本和语音往往不是一一对应的,语音中有时会掺杂一些噪音,如背景音乐、掌声等;而文本中也会存在一些单词冗余或者缺失的现象,将这样的数据称为含有噪音的语音和文本。如何利用网络上大量的含噪文本与语音数据,尽可能多的找出其中能够一一对齐的部分,即文语对齐技术是有效利用这类资源的关键问题。随着网络上可用多媒体资源的爆炸性增长,这一思路引起了越来越多研究人员的兴趣。
文语对齐是语音识别中的一项重要技术,它主要是指将语音与其对应的含噪文本在时间上进行对齐的过程。对齐后的文本语音可用于声学模型的训练,语料库的自动构建和多媒体检索等领域[1-2]。
文语对齐的传统方法是利用一个已经训练好的声学模型,对要对齐的语音进行识别,产生包含识别结果的文本文件,然后利用该文本文件和原始文本进行比对,找出他们的共同部分。这样,文语对齐问题就转换成了文本与文本的对齐问题[3],语音识别模块是该技术的核心部分,识别器性能的好坏将直接影响到文语对齐的正确率。目前,大多数的文语对齐技术多依赖于一个经过大量数据训练的识别器,如在Braunschweiler[4]中用于执行语音识别的声学模型是利用了150h的语音进行训练得到的,Hazen T J[5]中同样使用了一个经过充分训练的声学模型来执行文语对齐的算法。而为了得到一个识别效果好的声学模型需要至少几十个小时甚至上百个小时正确语料进行训练,为了获该部分的数据,不管是通过人工录音还是直接从别处购买其成本都是昂贵的。而且人工录音产生的语音数据因为录音环境和麦克风本身的限制,不能很好的兼顾到各种实际中存在的语音环境和麦克风采集声音的不同角度,在实际的识别中也就没有了很好的鲁棒性。因此有必要找到一种方法能尽可能的摆脱对预先训练的,只适应特定环境的声学模型的依赖。
本文提出一种基于网上开放语音识别引擎来自动的获得语音和文本一一对应的数据的算法,以开放的识别器来替代需要大量有标注数据预先训练的识别器,从而摆脱了对需要大量有标注数据训练的声学模型的依赖。并接着利用得到的数据来训练一个面向识别领域的声学模型,接着以此声学模型为核心改进了传统的文语对齐SailAlign算法,对语音和文本重新进行迭代的、自适应的文语对齐。
1 基于开放识别引擎及有限状态机语言模型的文语对齐算法
在传统的文语对齐算法中,原始的语音经过预先训练的识别器识别后会产生带有时间信息的文本,该时间即为文本在音频文件中的位置信息。将该部分文本与原始的文本进行文本对齐后,将会得到二者的公共部分,也即语音中一定含有的部分,然后根据文本的时间信息,即可找到与之对应的的语音。
为了摆脱对预先训练的声学模型的依赖,考虑利用谷歌的开放语音识别引擎(Google voice recogni-tion,简记为GVR)来代替传统文语对齐技术中的语音识别器,对含噪的语音和文本进行识别。但是在利用GVR对语音进行识别产生的文本文件中并不包含时间信息,没有了时间信息也就无法正确找出文本所对应的语音。为此,提出了一种基于有限状态机(Finite State Automaton,简记为FSA)的语言模型识别算法来得到需要的时间信息,进而得到文本所对应的语音,称该算法为GVR-FSA算法。
1.1 GVR-FSA文语对齐算法
该算法首先利用GVR对原始的语音进行识别得到识别结果,接下里将该部分结果与原始的文本进行文本对齐,在对齐的结果文件中包含2个部分,即两者共同含有的部分和不一致的部分。共同的部分为语音中一定包含的部分,而另一部分是否包含并不确定,本文利用基于有限状态机的语言模型来描述文本的这一特性。然后再经过利用原始的含噪语音和文本进行训练的语音识别器(下文中将称该识别器为含噪识别器)对语音进行第二次识别,在本次识别过程中结合由上面得到基于有限状态机的语言模型来得到文本所对应的准确的时间信息。由于有限状态机对文本的结构做了进一步的规定,使得它比普通的、单纯统计概率的语言模型对文本的限制更加的严格[10],所以即使是利用含噪识别器对语音进行重识别的情况下仍能找出文本所对应的正确时间信息。实验数据表明由该算法得到的文本和语音不对应的时间误差在0.1%左右,大大低于在人工录音过程中对该误差的要求。
该算法的主要模块,流程图见图1。
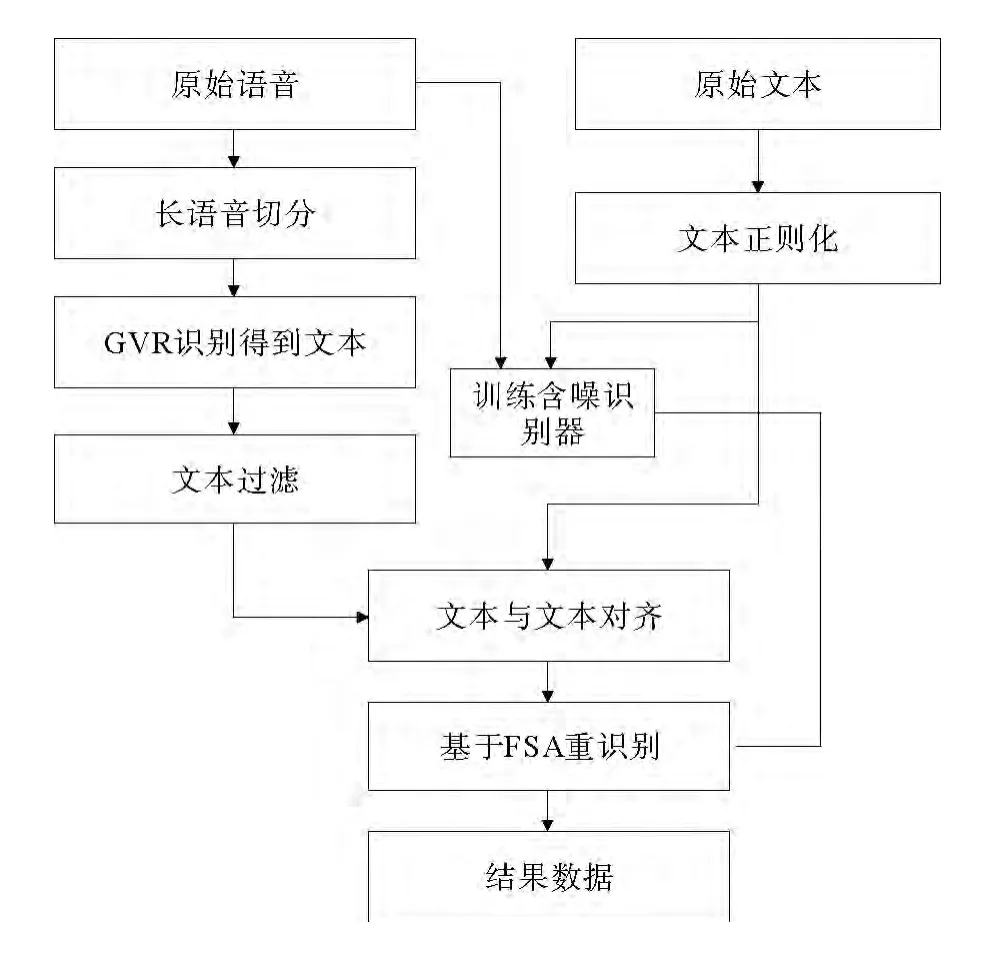
图1 GVR-FSA文语对齐算法的流程图Fig.1 The flow chart for the algorithm of the GVR speech-text alignment
1.2 各功能模块的功能描述
下面分别介绍上述算法流程图中各个模块的功能。
1.2.1 文本的正则化 在由网络得到的文本中常会含有一些乱码如“&nbsp”和“strong”等,还有一些和读音不一致的常用的符号如“%”,以及数字符号如“1984年”、“200多公里”等,这些都需要根据语音中的读音时进行转换,即将“&nbsp”和“strong”部分删除、将“%”转换成“百分之”、将“1984年”转换为“一九八四年”、将“200多公里”转换为“二百多公里”等。即将文本进行正则化处理,以得到较为规整的文本来提高文本与文本对齐的正确率。
1.2.2 含噪识别器的训练 将经过文本正则化处理的文本和原始的语音作为训练数据,来训练一个语音识别器,以执行GVR算法中的第二次语音识别。
由于语音和文本中含有噪声,不能保证语音和文本的一一对应,会有大量文本和语音对应不上的数据,由此训练的隐马尔科夫模型与准确的模型间会存在较大的误差。而如果我们识别器中的隐马尔可夫模型的数目越少,其受该部分错误数据的影响也就会越少。因此在这里我们训练了一个基于声韵母的单音素语音识别器。
1.2.3 原始语音文件切分 在网络上直接获得的语音一般都比较长,直接将其用GVR进行识别的识别正确率低;同时由于语音在通过网络提交给GVR时会受限于网络带宽,在网速不佳时识别速度也比较慢;经常会导致在返回的识别结果的文本文件中有大量的空文件,识别效果很不理想。
经过分析各种时长下语音的识别效果,我们发现GVR对时长为10~20s的语音识别效果最好。故我们对长语音首先进行了切分,以得到适合GVR识别的音频文件。然后将该部分短的音频文件提交至GVR进行识别。
1.2.4 GVR识别得到文本 谷歌语音识别引擎是开放的识别工具,在用户把音频文件按照要求的格式提交后,它会返回一个个包含识别结果的文本文件。为了在下面执行文本与文本对齐的方便,我们该部分得到的小的文本文件按照原始的语音数据汇总成一个较大的文本文件。
1.2.5 文本过滤 由GVR识别返回的文本结果中会含有一些噪音,如一般会有英文单词、数字和单个的字母等垃圾信息,为了提高在接下来文本与文本对齐的准确性,这里对该部分垃圾信息进行过滤。只保留返回结果中的汉字部分。
1.2.6 基于FSA的重识别 在得到文本过滤后的文本(下文中用识别文本来代表该部分文本)后,下一步的工作就是找出文本中正确识别的部分。为此将原始文本和识别文本进行文本对齐,对齐后两者同时含有的共同部分即为正确识别的文本。
在GVR返回的文本中,只有识别结果而无时间信息,无法得到该部分文本所对应的语音部分。为了得到所需要的时间信息,我们利用上面训练的含噪识别器,并结合基于有限状态机的语言模型[4]对语音进行第二次识别,以将该正确部分文本对应的语音找出,形成文本与语音一一对应的数据。
基于有限状态机的语言模型由两部分组成,一部分为正确文本,指的是在文本对齐中产生的正确识别部分的文本,即为识别文本与原始文本都含有的部分;另一部分为剩余文本,指的是原始文本中除去已正确识别出的文本外剩下的未对齐的部分。对于该部分文本不能确定它在原始的语音是否存在。因此,在构造该语言模型时将正确文本在语言模型中视为必会出现的状态,而将剩余文本作为可选的状态来完成有限状态自动机的构建。原理见图2。
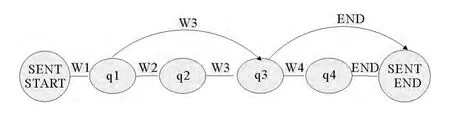
图2 有限状态机图示,W1和W3为正确部分,W2和W4为可选部分Fig.2 The diagram of the finite state automata,W1and W3are the right part,W1and W3are the optional part
2 改进的SailAlign文语对齐算法[6]
通过分析GVR-FSA算法的识别过程,发现在网络不稳定时,经常会得到许多空的返回文件,使得整个识别过程对网络的依赖性很大,算法的稳定性不好。在返回的非空文本中能够正确识别的文本约为50%(见实验部分),识别的正确率也比较低;而接下来还需要重新训练含噪识别器对语音进行二次识别,以获得时间信息,这又进一步增加了整个算法的时间复杂。
为了克服上述缺点,我们在利用GVR-FSA算法得到了语音文本一一对应的部分数据后,接着利用该部分数据训练了一个基于三音素的汉语连续语音的声学模型,以该模型作为语音识别器,并参考了传统的文语对齐算法SailAlign的架构来重新执行文语对齐。由于该识别器返回的识别结果中就包含了时间信息,因此也就不需要在GVR-FSA算法中所需要的重识别过程,整个算法的时间复杂度得到了降低,同时该语音识别器是通过要识别领域的文本和语音训练得到的,也能保证其较高的识别率。同时SailAlign算法在执行文语对齐得到了语音和文本一一对齐的数据后,接着利用该部分数据对声学模型进行了加强训练,然后利用新的声学模型对接下来的数据进行识别。整个过程是一个迭代的过程,与GVR-FSA算法相比,其识别器的识别率是在不断的提高的。SailAlign算法已在Black M P和Lee C C[7]中提到的关于对齐含有噪音的交互语音数据领域得到了成功的应用。
该算法的流程见图3。

图3 SailAlign算法的流程Fig.3 The process of the algorithm of the SailAlign
同时为了进一步提高该算法中语音识别器的识别率,对SailAlign算法中的语言模型部分进行了改进。SailAlign算法中的语言模型是基于要识别文本所建立的语言模型,在识别文本中的错误率不是很高的情况下,该算法能获得很好的效果。但随着文本错误率的升高,错误部分对整个语言模型的影响也越来越大,使得识别的准确率降低。为此我们使用了融合的语言模型来避免文本错误率升高对语音识别正确率的影响。具体是首先我们基于大量文本训练了一个通用的语言模型,将待识别的文本训练了一个特定的语言模型;在实际的语音识别中使用的语言模型是将上述两个语言模型进行融合得到的(融合的比例为通用的模型为0.2,特定的模型为0.8),以此来削弱文本错误率对识别结果的影响,同时又保证了识别结果向原文本的偏置。实验结果表明,融合的语言模型在文本噪音较大时仍能取得较高的识别正确率。但在识别过程中,由于使用了通用的语言模型与特定的语言模型融合的技术,使得每次的识别过程中的语言模型都比较大,识别的时间相对于原算法来说延长了很多。
2.1 语音数据的预处理
首先对音频文件进行切分,将长语音文件切分成较小的语音片段。(本文中约为10~15s)。与GVR部分不同的是,这里我们是在声学特征领域对音频文件进行切分,即首先对音频文件进行声学特征的抽取,然后直接在声学特征域内对音频进行切分,这样在以后的迭代识别中就不需要再进行声学特征的抽取了,使得整个算法过程更加高效[6]。
2.2 语音识别,文本与文本的对齐
与GVR文语对齐算法过程类似,接下来对切分成小音频段的语音进行识别,并将识别后的结果汇总成1个文本文件,并将该文本文件与原始文本进行对齐,找出正确识别的部分,并将剩下的文本和语音视为未对齐的部分,利用SailAlign进行重新对齐,即迭代的进行识别与对齐。
2.3 声学模型与语言模型的自适应
为了提高对噪音的鲁棒性,对每次迭代的识别和对齐后,我们都要用已经对齐的好的语音和文本来更新声学模型,而对于语言模型则是是在每次迭代后都再基于未对齐语音部分来重新建立。该过程将迭代进行3次,在最后的2次迭代过程中,声学模型将不在更新,只是对语言模型进行自适应。
3 实验结果及数据分析
使用开源的工具sox来对在GVR-FSA算法中的长语音进行切分;而在SailAlign算法中对音频进行切割的工具,使用的是Ghosh P K[9]描述的工具;语言模型的训练是使用的SRILM工具[8];文本与文本的对齐使用的动态规划的算法,利用的开源工具Sclite来实现的。
原始的语音和文本数据使用的是网上免费的新闻联播数据,约为20h,利用该部分数据,首先分别对GVR-FSA和SailAlign两种文语对齐算法的性能进行测试和比较;接着对改进前后的SailAlign算法中文本错误率对它的影响做了比对和分析;最后测试了2种文语对齐算法得到的对齐后数据的错误距离(error margin),以此来衡量两种文语对齐算法产生的数据的准确性,并对此进行了分析。错误距离即为算法得到的语音及其时间和实际语音所对应时间之间的误差所允许的时间间隔,本文将该间隔设为50ms,error margin大于50ms的数据被认为是对齐错误的数据。需要说明的是在实际测试算法对齐后数据的准确性时,我们统计的是error margin大于50ms的字的个数占原始文本中正确字的个数的百分比,即字错误率(Word error rate)。
初始的20h左右的含噪新闻联播数据经过GVRFSA算法对齐后,得到了文本和语音一一对齐的数据约为10h。然后利用该部分数据训练出一个基于三音素的连续语音声学模型,以用于实现SailAlign算法。SailAlign算法中的通用语言模型是用了搜狗实验室的新闻文本进行训练的。测试数据我们用的是1h的含噪语音和文本。
测试的结果见图4、5和6。
图4给出基于测试数据的GVR-FSA和SailAlign 2个算法中的正确率比较。在这里的正确率是指2种算法得到的准确文本中汉字的个数占原文本中汉字的总个数的百分比。
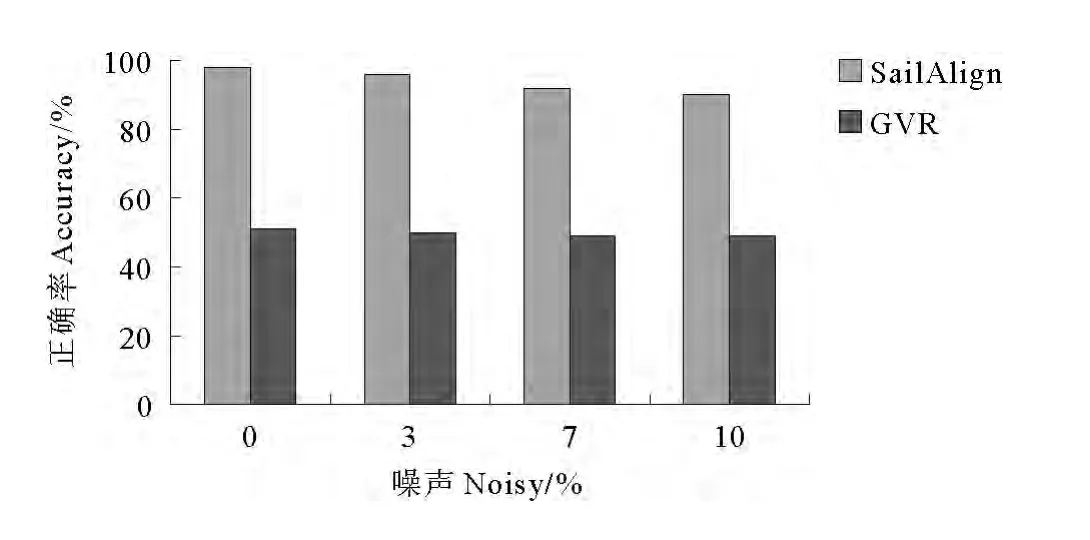
图4 SailAlign和GVR的性能比较Fig.4 The comparison of performance between the SailAlign and the GVR
从图中可以看出,由于SailAlign算法中使用了面向原始的语音和文本的数据来训练声学模型和语言模型,识别的性能有了显著的提高,同时该算法的鲁棒性也很高,在噪声达到10%时仍然有着较高的正确率。而GVR-FSA的鲁棒性虽然也较高,在各种噪音情况下基本保持了同样的识别正确率,但是其识别率较低,同时由于其对网络的依赖性,使得它稳定性和时间效率较低。
接下来对改进前后的SailAlign算法的识别性能进行了测试(见图5)。

图5 改进前后的SailAlign性能比较Fig.5 The performance comparison of the SailAlign
从图5中可以看出,文本中的噪音对只通过单文本训练的语言模型的识别性能影响比较明显,而通过加入通用的语言模型后,在噪声达到10%时仍能达到94.5%的识别率,这里94.5%指的是正确识别出的文本占原文本中正确文本的概率。SailAlign的鲁棒性得到了提高,在利用两种算法得到的语音和文本对应的数据中会存在有的语音和文本对应错误的情况,一般来说是指在文本开头或结尾的部分会存在多字或少字的现象,即该部分语音的时间与实际正确时间的前后时间误差超过了本文对error margin 50ms的要求,这里用WER来表示不匹配的概率。
图6给出的是在2种算法的WER比较。

图6 SailAlign和GVR的字错误率能比较Fig.6 The comparison of WER between the SailAlign and the GVR
从图中发现2种算法的WER都比较低,低于人工标注语音文本数据中所允许的0.1%的错误率。由算法得到的数据可直接应用于语料库的构建和多媒体的检索等领域。
4 总结展望
本文介绍了一种不依赖于预先训练好的声学模型的文语对齐的算法,实验表明,该算法在噪音比较高的情况下,仍然可以达到比较高的性能。SailAlign算法中用的声学模型是用了10h的语音文本数据训练得到的,增多训练的数据量将会进一步的减小WER。
接下来的研究工作主要是进一步摆脱对开放识别器的依赖,研究如何在没有开放语音识别器的情况下,也没有可用于训练声学模型的语音与文本数据情况下来进行文语对齐算法的技术。具体来说就是继续加强对语言模型的限制,利用本文中提到的基于有限状态机的语言模型方法对原始的文本进行处理,考虑到各种可能文本字符间的状态转移路径,然后将语音对各种路径进行一个打分,找到其中概率最大的路径,即为语音所对应的文本。而如何对转移路径进行打分将是该算法的关键。
[1]Moreno P J,Alberti C.A factor automaton approach for the forced alignment of long speech recordings[C].Proc of the IEEE International Conference on Acoustics,Speech,and Signal Processing,Taipei:ICASSP,2009:4869-4872.
[2]Caseiro D,Meinedo H,Serralheiro A,et al.Spoken book alignment using WFSTs[C].Proc of the second international conference on Human Language Technology Research.San Francisco:ACM,2002:194-196.
[3]Moreno P,Joerg C,van Thong J M,et al.A recursive algorithm for the forced alignment of very long audio segments[C].Proc of the Int’l Conf on Spoken Language Processing,Sydney:IEEE press,1998:2711-2714.
[4]Braunschweiler N,Gales M J F,Buchholz S.Lightly supervised recognition for automatic alignment of large coherent speech recordings[C].Proc of the Interspeech,Chiba:INTERSPEECH,2010:2222-2225.
[5]Hazen T J.Automatic alignment and error correction of human generated transcripts for long speech recordings[C].Proc of Interspeech,Pittsburgh:INTERSPEECH,2006:1606-1609.
[6]Katsamanis A,Black M P,Georgiou P G,et al.SailAlign:Robust long speech-text alignment[J].Proc of Workshop on New Tools and Methods for Very Large Scale Research in Phonetic Sciences,2011,1:28-31.
[7]Black M P,Katsamanis A,Lee C C,et al.Auto-matic classification of married couples’behavior using audio features[C].Proc of the Interspeech,Chiba:INTERSPEECH-2010,2010:2230-2033.
[8]Stolcke A.SRILM-an extensible language modeling toolkit[C].Proc Int’l Conf on Spoken Language Processing,Colorado:ICSLP,2002:269-273.
[9]Ghosh P K,Tsiartas A,Narayanan S S.Robust voice activity detection using long-term signal variability[J].IEEE Trans Audio Speech and Language Processing,2010:19:600-613.
[10]Stan A,Bell P,King S.A grapheme-based method for automatic alignment of speech and text data[J].IEEE Workshop on Spoken Language Technology,2012,1:286-290.
