基于形态运算的二值网格域描述单类分类方法
2015-11-26曲建岭郭超然孙文柱
高 峰,曲建岭,郭超然,孙文柱
(海军航空工程学院青岛校区,山东 青岛 266041)
0 引言
在设备状态监控、疾病检测和网络异常行为监视等模式识别过程中常遇到样本数不平衡的分类问题。在此类问题中,正常状态样本比较常见且容易获得,异常状态样本出现概率较小。因此,在对2 类样本分类过程中,常会因为2 类样本数量不平衡而影响分类结果精度。单类分类方法在训练过程中可以形成一类样本的域描述,在测试过程中接受域描述内的样本,拒绝域描述外的样本,从而有效解决样本数不平衡的分类问题。在单类分类过程中,数量较多并用于训练的一类样本称为目标样本,另一类样本称为非目标样本。
单类分类方法最早于1993 年由Moya 等人提出[1],经过20 多年的发展衍生出了许多新方法。现有的单类分类方法根据原理大致可分为3 类[2]:1)基于支持向量的单类分类[3-9];2)基于神经网络的单类分类[1,10-13];3)基于样本分布密度的单类分类[14-19]。在以上3 类方法中,基于支持向量机和神经网络的单类分类方法研究得较多,但在处理大样本单类分类问题时该方法效率较低。原因是支持向量的单类分类方法训练过程中需要求解计算复杂度为O(n3)的凸二次规划问题,耗时较长;而神经网络的单类分类方法容易陷入局部极小从而无法获得全局最优解。基于样本分布密度和样本聚类的单类分类方法计算速度较快,是解决大样本单类分类问题的理想方法。
在数字图像处理中,开运算和闭运算使得二值图像上的集合边界更加平滑。而在单类分类器中,同样要求目标样本的域描述具有平滑的边界。因此,本文将形态学中的开运算和闭运算与单类分类理论结合,形成一种新颖的单类分类方法——二值网格域描述方法(Binary Grid Domain Description,BGDD)。该方法首先将样本分布空间划分成等尺寸网格,将包含样本的网格定义为目标网格,不包含样本的网格定义为背景网格。通过对目标网格进行形态学闭运算和开运算形成训练样本的域描述。该分类器中的网格相当于二值图像中的像素,形态学闭运算和开运算能使得目标网格集合分布更加紧凑,边界更加圆滑,从而使目标样本域描述具有更好的泛化能力。
1 基本形态运算
给定ℝN上的集合X 和B,B 对X 的腐蚀[20]定义为:

其意义为B 的原点为x,B 包含于X 内的x 的所有轨迹点构成B 对X 的腐蚀。用于对X 进行操作的集合B 称为结构元素。二维空间上的腐蚀示例如图1 所示。
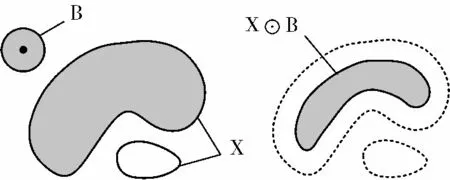
图1 二维空间上的腐蚀示例
膨胀是腐蚀的对偶运算。B 对X 的膨胀定义为:

二维空间上的膨胀示例如图2 所示。
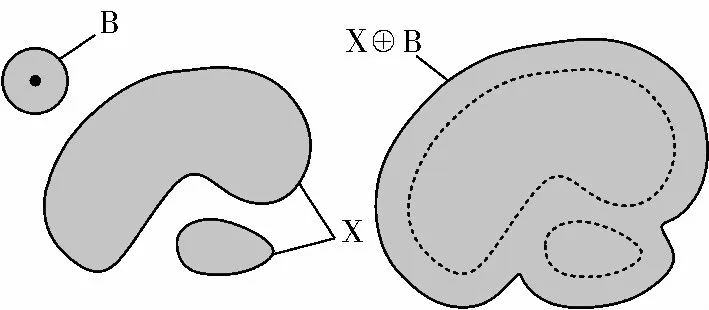
图2 二维空间上的膨胀示例
B 的反射定义为:


开运算可以起到平滑集合边界、去除细小毛刺的作用。二维空间上的开运算示例如图3 所示。
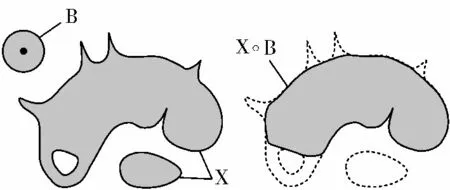
图3 二维空间上的开运算示例

闭运算同样可以平滑集合边界且能够填补集合内细小孔洞。二维空间上的闭运算示例如图4 所示。
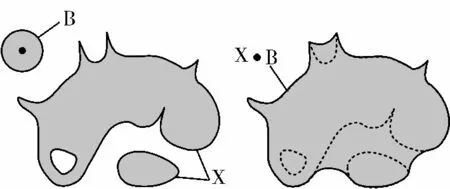
图4 二维空间上的闭运算示例
2 BGDD 方法
给定在N 维样本空间上的训练样本集:

BGDD 方法的步骤为:
步骤1 建立可覆盖Xtr的空间Q⊂ℝN,然后将Q 等分为kN个网格,其中每个特征维上分段数都为k。单个网格表示为qi(i=1,2,…,k1×k2×… ×kN);
步骤2 为qi定义对应的二值变量mi,mi取值由式(7)决定:
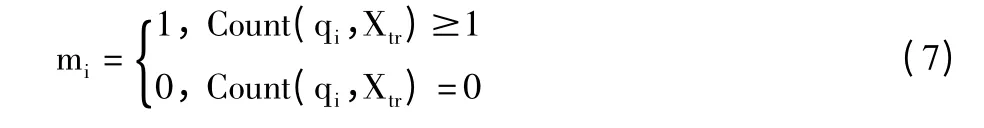
式(7)中,Count(qi,Xtr)表示qi中包含训练样本的个数。与mi=1 相对应的网格称为目标网格;与mi=0 相对应的网格称为背景网格。所有mi构成N维数组M。
步骤3 对M 进行闭运算:

步骤4 对M'进行开运算:

M″所对应的目标网格可视作训练样本的域描述。
在步骤3 和步骤4 中的结构元素B1与B2为圆形离散结构元素。半径r 分别为1、2 和3 的二维离散结构元素如图5 所示。

图5 半径分别为1、2 和3 的二维离散结构元素示例
在步骤3 中,结构元素B1的半径以迭代的方法确定。首先设B1为半径r=1 网格的球形,而后r 逐次增大1 网格,直到M'中的所有背景网格连接成整体。所有背景网格连接成整体意味着M'中所有目标网格中的孔洞被填补。
在步骤4 中结构元素B2半径确定方法为:首先设B1为半径r=1 网格的球形,而后r 逐次增大1 网格,直到M″中的所有目标网格连接成整体。所有目标网格连接成整体意味着M″中只含有一个簇,簇外的零散目标网格被消除。
3 实验及结果分析
为了测试BGDD 的分类性能,本节分别设计了基于Banana 人工数据集和Iris 真实数据集的2 组实验。其中,Banana 数据集由Prtools 工具箱生成,Iris数据集选自UCI 机器学习数据库。同时,将BGDD的分类结果和训练时间与其它5 种常用单类分类方法性能相比较,这5 种单类分类方法分别为:Kmeans、K-center、Parzen 窗、MOG(Mixture of Gaussians)和MPM(Minimax Probability Machine)。在分类方法性能比较过程中,选用ROC 曲线作为衡量分类方法性能的指标。ROC 曲线的横纵坐标分别为FPR(False Positive Rate)和TPR(True Positive Rate),其中,FPR 表示非目标样本被错误接受的比例,TPR 表示目标样本被接受的比例。因此,ROC 曲线越接近左上角说明分类方法的性能越优秀。
3.1 Banana 数据集实验
Banana 数据集包含2 类样本,每个样本有2 个特征,呈“C”形交叉分布,一般用来测试非线性分类的性能。实验过程中生成标准差为1 的5000 个第一类样本作为目标样本和500 个第二类样本作为非目标样本(如图6(a)),其中4500 个目标样本用于分类器训练,余下的500 个目标样本和500 个非目标样本用于分类器测试。
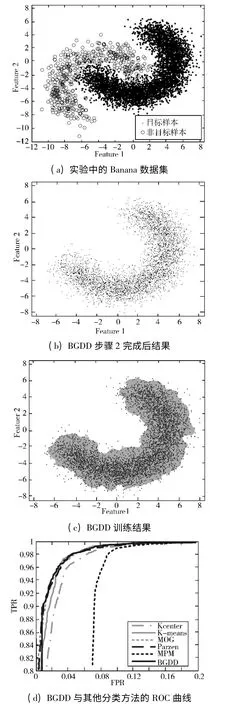
图6 Banana 数据集上的实验过程及结果
本实验中,BGDD 中2 个维度上网格分段数均设置为300。BGDD 步骤2 完成后,目标网格和背景网格分布如图6(b)所示,图中的灰色像素点为目标网格。图6(c)为BGDD 训练结果。图中的灰色区域为目标网格即训练样本的域描述,黑色点为训练样本。从图6(c)中可见,训练样本的域描述边界平滑,覆盖了目标样本密集的区域并拒绝了一些零散分布的目标样本。图6(d)显示了BGDD 以及其他5 种分类方法的ROC 曲线。可以看出:在Banana 数据集实验中,BGDD、MOG 和Parzen 的ROC 曲线几乎重合,说明这3 种单类分类方法性能几乎处于同一水平,其他依次为K-means、K-center 和MPM。
3.2 Iris 数据集实验
Iris 数据集包含3 类样本,每类50 个,共150 个样本,每个样本有4 个特征,分别是sepal length、sepal width、petal length 和petal width。本文选取类间距离较大的petal length 和petal width 这2 个特征进行分类。第二类样本在实验中被作为目标样本,第一和第三类样本被作为非目标样本。由于该数据集中样本数较少,实验中使用Prtools 工具箱对样本进行扩展,使得目标样本数为5000,非目标样本数为500。生成标准差为1 的5000 个第一类样本做为目标样本和500 个第二类样本做为非目标样本(如图7(a)),选取4500 个目标样本用于分类器训练,余下的500 个目标样本和500 个非目标样本用于分类器测试。实验步骤与在Banana 实验中相同。
与上一组实验相同,BGDD 中2 个维度上网格分段数仍设置为300。BGDD 步骤2 完成后目标网格和背景网格分布如图7(b)所示。图7(c)为BGDD 训练结果。图7(d)为BGDD 以及其他5 种分类方法的ROC 曲线。可以看出:在Iris 数据集实验中,BGDD的ROC 曲线最靠近图左上角,因此其分类性能超越了其他所有分类方法,Parzen 和MOG 次之,其余依次为K-means、K-center 和MPM。
3.3 时间复杂度分析
本节设置了一组实验的考查BGDD 的时间复杂度,所有实验运行在一台配置为Pentium Dual E2140 1.6 GHz 处理器,2 GB 内存和MATLAB v.7.6.0.环境的计算机上。

图7 Iris 数据集上的实验过程及结果
图8 为BGDD 和其他5 种单类分类器在二维和三维circular 数据集上的训练时间随样本数增长曲线。图中可见,在所有6 种分类器中,BGDD 的训练时间随样本数增长最慢,当样本数超过40,000(三维情况下超过300,000)时,BGDD 的训练时间最短。这是由于在BGDD 分类过程中将样本映射为网格。而在样本稠密的区域,许多样本映射到一个网格中,以致网格数量远远少于样本数。在后续的闭运算和开运算过程中,计算复杂度只取决于网格数。因此,BGDD 的计算复杂度对于样本数量增加不敏感。BGDD 的这种性质使得BGDD 可以应用于样本数量极大的单类分类场合。但同时在图8 中也应该看到,BGDD 在三维数据集上的训练时间远远高于二维数据集上的训练时间,而其他分类方法在三维数据集和二维数据集上训练时间相差不多,这表明BGDD 只适用于低维数据集单类分类。在处理高维数据集时,也可使用PCA、流形学习等特征降维方法将高维数据集映射成低维数据集后再应用BGDD 进行单类分类。
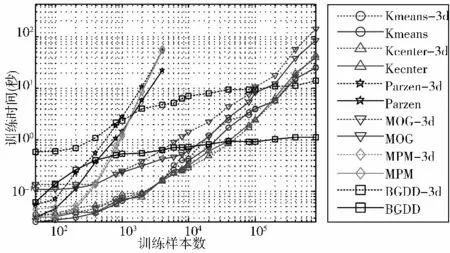
图8 二维和三维circular 数据集上分类器训练时间比较
4 结束语
本文将数学形态学中的形态滤波运算运用到模式识别理论中,提出了基于形态运算的二值网格单类分类方法,有效解决了样本数不平衡条件下的分类问题。为验证本文方法的有效性,在人工数据集和真实数据集上进行了实验并将实验结果与其他5 类经典分类器对比。实验结果显示:BGDD 的分类精度较高,尤其是在样本数较大的情况下训练时间较短,适用于低维大样本的单类分类场合,在工程中具有较高的应用价值。
[1]Moya M,Koch M,Hostetler L.One-class classifier networks for target recognition applications[C]// World Congress on Neural Networks.1993:797-801.
[2]潘志松,陈斌,缪志敏,等.One Class 分类器研究[J].电子学报,2009,37(11):2496-2503.
[3]Tax D M J.One-class Classification:Concept-learning in the Absence of Counter-examples[D].Netherlands:Delft University of Technology,2001.
[4]Yan Yuesong,Wang Qiong,Ni Guiqiang,et al.One-class support vector machines based on matrix patterns[C]//Proceedings of the 2011 International Conference on Informatics,Cybernetics,and Computer Engineering.2012,111:223-231.
[5]Kang I,Jeong M K,Kong D.A differentiated one-class classification method with applications to intrusion detection[J].Expert Systems with Applications,2012,39(4):3899-3905.
[6]Cyganek B.One-class support vector ensembles for image segmentation and classification[J].Journal of Mathematical Imaging and Vision,2012,42(2-3):103-117.
[7]Wang Chengqun,Lu Jiangang,Hu Chonghai,et al.Kernel matrix learning for one-class classification[J].Advances in Neural Networks,2008,5263:753-761.
[8]Labusch K,Timm F,Martinetz T.Simple incremental one-class support vector classification[J].Lecture Notes in Computer Science,2008,5096:21-30.
[9]Camci F,Chinnam R B.General support vector representation machine for one-class classification of non-stationary classes[J].Pattern Recognition:The Journal of the Pattern Recognition Society,2008,41(10):3021-3034.
[10]Moya M M,Hush D R.Network constraints and multi-objective optimization for one-class classification[J].Neural Networks,1996,9(3):463-474.
[11]Bishop C M,Hinton G,Hinton G E.Neural Networks for Pattern Recognition[M].Oxford University Press,1995.
[12]Japkowicz N.Concept-learning in the Absence of Counterexamples:An Autoassociation-based Approach to Classification[D].The State University of New Jersey,1999.
[13]Ypma A,Duin R P W.Novelty detection using self-organizing maps[C]// Proc.of ICONIP’97.1997:1322-1325.
[14]Hempstalk K,Frank E,Witten I H.One-class classification by combining density and class probability estimation[J].Lecture Notes in Computer Science,2008,5211:505-519.
[15]Angiulli F.Prototype-based domain description for oneclass classification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(6):1131-1144.
[16]Angiulli F.Condensed nearest neighbor data domain description[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(10):1746-1758.
[17]Yeung D Y,Chow C.Parzen-window network intrusion detectors[C]// Proceedings of the 16th International Conference on Pattern Recognition.1994:385-388.
[18]Lipka N,Stein B,Anderka M.Cluster-based one-class ensemble for classification problems in information retrieval[C]// Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval.2012:1041-1042.
[19]Cabral G G,Oliveira A L I,Cahú C B G.Combining nearest neighbor data description and structural risk minimization for one-class classification[J].Neural Computing &Applications,2009,18(2):175-183.
[20]Soille P.Morphological Image Analysis:Principles and Applications[M].2nd ed.Berlin:Springer,2003.
