日本留学生汉语中介语篇的信息结构特征及其篇章教学策略选择
2015-11-26张迎宝
□张迎宝
日本留学生汉语中介语篇的信息结构特征及其篇章教学策略选择
□张迎宝
与汉语母语者相比,日本留学生论证性语篇信息结构的构建呈现出信息输出量偏低,深层论据信息构建力不足,偏好使用核心型例和I缺省选择性信息模型等中介性特征。这些特征的发掘对对外汉语篇章教学策略的选择具有重要的参考价值。
论证性语篇 篇章信息结构 中介特征
篇章信息结构,又称篇章宏观结构(Van Dijk,1980)、篇章宏观信息结构(郭纯洁,2006),是负载不同功能的各种高层次信息单元之间建构起的一种功能关系网络,是语篇宏观结构组织建构的核心要素之一。目前,学界对该问题的研究主要集中在两个方面:一是本体研究,着力研究篇章信息结构的类型、组织特征、不同语言篇章信息结构的异同等(Van Dijk,1980;廖秋忠,1988;Büring2003;杜金榜,2007;郭纯洁,2006);二是习得研究,主要针对中介语篇章信息结构的构建偏误、发展特点、习得模式等进行探索(Kaplan,1966;吴丽君,2002;马明艳,2009)。两大板块中,前者方法成熟,成果丰富,后者起步较晚,研究相对薄弱。尤其是针对汉语中介语的探索,虽然以往的研究取得了一些成果,但是其中暴露出的问题也很多。具体来说,表现在以下三个方面:一是未能有效提取篇章信息结构的构成参项;二是将篇章信息结构视为平面、线性结构,忽视了其系统性与层级性;三是研究方法陈旧,主要依靠“思辨+举例”的分析模式,对语料库、实证分析等利用不充分。鉴于此,本文拟在提取篇章信息结构构成参项的基础上,采用定量统计与对比分析的方法,探讨日本留学生论证性中介语篇的信息结构特征,并提出相应的教学策略。
一、研究设计
(一)语料的收集与处理
本文使用的语料分为两部分。
一部分是日本留学生制作的汉语中介语语篇,该部分语料来自北京语言大学“HSK动态作文语料库”。为了保证语料内部的均衡性,我们以语料库中日本留学生对《吸烟对个人健康和公众利益的影响》这一测试题目写成的所有成品作文作为总样本库,随机抽样了其中的30篇,构成日本留学生论证性中介语篇抽样库,简称IJ组。
另一部分语料是母语为汉语的中国大学生的汉语语篇。这部分材料来自现场测试。参加测试的是38名大学生,其中男生18名,女生20名。这些被试的母语均为汉语,具有较好的汉语书面表达能力和良好的合作态度。测试题目、时间(限时30分钟)与日本留学生一致。测试结束后,我们对收集到的汉语语篇进行了评估,从中选取了30篇综合评估良好的作文作为本文的研究素材。为了研究的方便,我们将这30篇汉语语篇按CT1~CT30(CT代表Chinese Text)进行了编号。
(二)信息结构的形式化
1.篇章小句的切分。我们语料分析的第一步就是将所有语篇的小句切分出来,并用专门的符号Cn(n表示小句在语篇中的编号)进行标注。在具体操作中,我们以徐赳赳(2003:58)提出的标准作为主要的切分依据。
2.篇章信息结构树形图的绘制。根据廖秋忠(1988)对论证性语篇形式化的研究,结合本文使用的语料,我们将论证性语篇信息结构的形式规则,总结为以下7条。

其中,T代表整个语篇;I代表T中的引言部分或E中的总提部分;A代表核心论证部分;C代表结尾;P代表论点(论题);E代表论据;S代表C中总结论据重申论题的部分或E中的总结部分;AD代表C中与论题有关的引申部分或与论题无关的题外事项,这其中既可以包括作者提出的解决问题的措施、办法也可以包括作者发出的号召,提出的期望、忠告、建议等;CI代表说明澄清部分; E1E2……EN代表一级分论据,其中N表示一级分论据的数量,取大于等于1的整数;EN.1 EN.2……EN.n代表某一级分论据的下位分论据,即二级分论据,n表示二级分论据的数量,取大于等于1的整数。{{ }}表示信息模块之间存在上下位关系,内外括号间的成分为上位信息,内括号中的成分为下位信息。[ ]表示该成分为可缺失成分。
下面我们以HSK动态作文语料库内的一篇留学生作文为例进行简要说明。
“在公共场所、不允许抽烟”这个措施,我个人认为很有道理(C1)。
首先,从吸烟的利弊来看,吸烟明明是有害无益的(C2)。至今,连自己吸烟的人也知道吸烟对身体有害(C3)。但是,长年养成的嗜好,他们难以离开(C4),在公共场所有人吸烟的话(C5),他吐出的烟雾至少损害他的周围好几个人的健康(C6)。对他个人的健康不用说了(C7)。
其次,我们要考虑吸烟者和不吸烟的人的权利(C8)。这样的措施很有可能引起吸烟者的反对(C9)。那么我们应该保护谁的权利呢(C10)?我们不得不承认吸烟也是一种享受(C11)。可以算是一种爱好(C12)。但是,给别人添麻烦而且损害别人的健康的爱好不被承认是个爱好(C13)。
总之(C14),我赞成“在公共场所边走边不允许吸烟”这个措施(C15)。吸烟对人们的健康根本没有好处的(C16)。我希望(C17)不久的将来没有烟雾的世界会实现(C18)。(IJL6)
IJL6中,C1是论点,C2~C13中使用了两个论据从两个不同的角度来论证自己的观点:一是论据E1(C2~C7),吸烟对身体健康的危害;二是论据E2(C8~C13),吸烟对他人权利的侵犯。最后一段(C14~C18)为整个论证结构的结尾部分:作者一方面总结了上文的重述论点,另一方面就公共场所的吸烟现象提出了自己的希望。
通过分析、拆解,我们将该语篇的信息结构形式化为图1。

图1:篇章信息结构树形图
3.篇章信息结构模块间功能结构关系的确定。通过分析确定出信息结构树形图中模块与模块之间的功能结构关系。
(三)研究参项提取与数据收集分析
1.研究参项
结合论证性语篇的特点与树形图,我们提取出了信息结构的五个构成参项。
(1)信息层,指篇章信息结构系统中负载各种信息的不同层级。
(2)信息点,指的是篇章信息结构中负载不同信息的各类功能模块。
(3)信息量,指的是各类信息结构模块,即各种不同类型的信息点,携带已知信息与未知信息的量。本文中,我们主要以小句的数量作为判断宏观信息模块信息量的标准。
(4)信息模式,指篇章制作者在对各类信息模块进行筛选、分层、组配、排序等一系列认知操作之后会最终形成的各具特点的层级化信息模型。
(5)信息模块间结构关系,指篇章信息结构同一信息层上两个或多个信息模块之间存在的功能结构关系。
2.数据收集与分析
本文收集的主要是日本留学生样本组(IJ)与目标语对比组(CT)内所有语篇的信息结构参项数据。数据分析过程中,本文使用的主要分析工具是Excel和SPSS18.0 for Windows。
二、结果与讨论
(一)信息层的特征
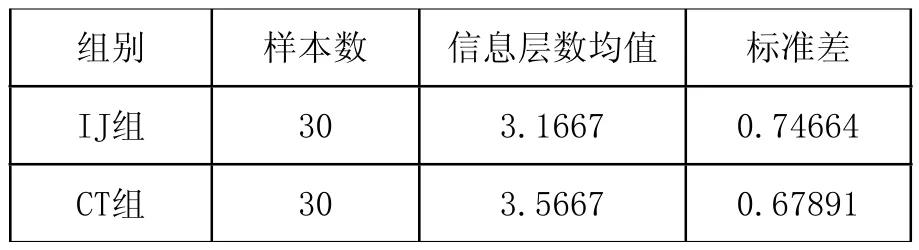
表1:IJ组和CT组内信息层总数的均值
根据表1,IJ组的30个样本共有95个信息层,均值为3.1667;CT组共有107个信息层样本均值为3.5667。独立样本t检验的结果表明:t=-2.171,p=0.034<0.05,两组之间存在显著差异,日本留学生论证性语篇的信息层级数显著低于汉语母语者。

表2:IJ组和CT组内不同类型信息层的数量
表2是两组不同类型信息层的数量比较,通过比较发现两组的首信息层和第二信息层数量相同,不存在差异,CT组的三、四、五信息层的数量均高于IJ组,t检验的结果表明CT组三、四、五信息层的数量,显著高于IJ组(t=-2.171,p=0.034<0.05)。也就是说,日本留学生汉语中介语篇的浅层信息数量与母语者之间不存在显著差异,但深层信息的数量显著低于汉语母语者。
(二)信息点的特征

表3:IJ组和CT组内信息点总数的均值
根据表3,IJ组内所有样本共227个信息点,均值为7.5667;CT组共有300个信息点,均值为10.0000。独立样本t检验表明:t=-4.781,p=0.000<0.05,两组之间存在显著差异。日本留学生论证性语篇的信息点配置量显著低于汉语母语者。

表4:IJ组和CT组内不同信息层的信息点数量
表4是两对比组内样本不同信息层的信息点数量对比。独立样本t检验显示首信息层的p=0.004<0.05,第三信息层的p=0.007<0.05,即首信息层和第三信息层的信息点数,两对比组存在显著差别。第二、四、五信息层的p值分别为0.149,0.063和0.271,均大于0.05,不存在显著差异。
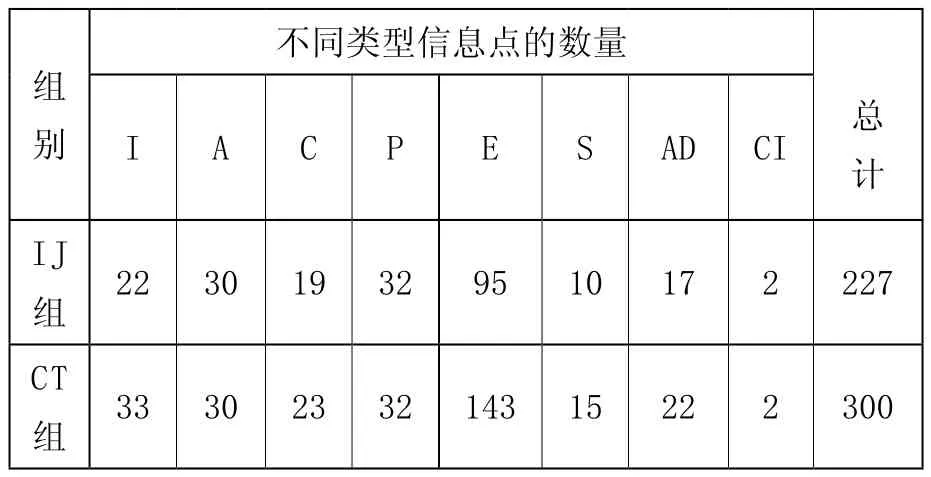
表5:IJ组和CT组内不同类型信息点的数量
表5呈现的是两对比组样本内不同类型信息点的数量。根据独立样本t检验:I类(p=0.033<0.05)、E类(p=0.000<0.05)信息点的配置数量存在显著差异,其余类型的信息点p值均大于0.05,不存在显著差异。
综合表3、4、5的分析,可以看出:日本留学生论证性语篇配置的总信息点数量远低于汉语母语者,具体来说,这种差异主要表现在:首信息层和第三信息层上的I类和E类信息点配置数量显著低于汉语母语者。
(三)信息量的特征
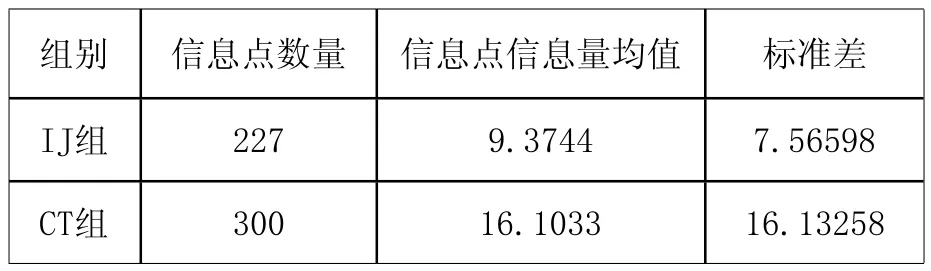
表6:IJ组和CT组内不同类型信息点的数量
根据表6,IJ组的30个样本共有227个信息点,总信息量为2128,均值为3.1667;CT组共有300个信息点,总信息量为4831,均值为16.1033。独立样本t检验的结果表明:t=-6.359,p=0.000<0.05,两组之间存在显著差异。日本留学生论证性中介语篇的信息点信息量均值显著少于汉语母语者,日本留学生在相同时间内的信息量输出能力显著低于汉语母语者。
(四)信息模式的特征

表7:IJ组和CT组内样本的信息模式类型及其分布
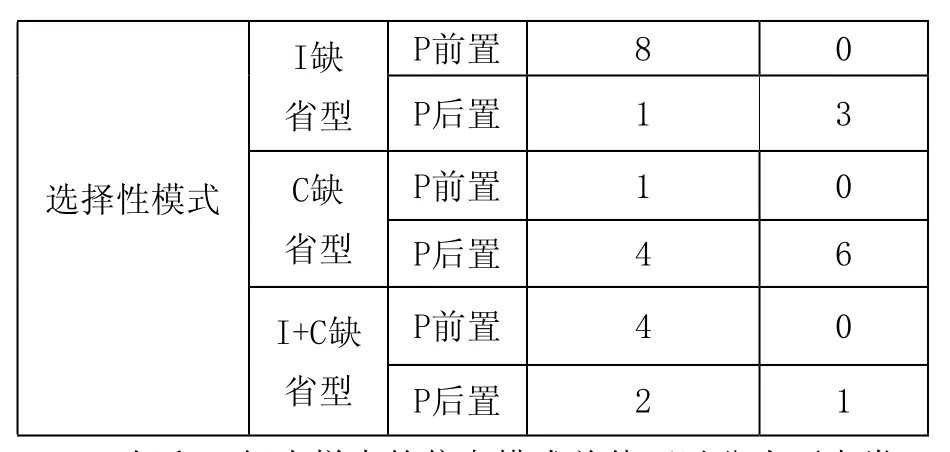
IJ组和CT组内样本的信息模式总体可以分为两大类:一类是全息性模式,指信息结构首信息层中“I”“A”“C”三类信息模块均为缺失的一类信息模型;另一类是选择性信息模式,指首信息层信息模块存在缺省的一类信息模型。根据表7中的数据,IJ组内样本全息性模式占33.3%,选择性模式占66.7%,选择性模式中比例最高的是“I缺省型”,其次是“I+C缺省型”和“C缺省型”;从P的位置来看,前置式占76.7%,后置式占23.3%。与IJ组相比,CT组以全息性模式为主(66.7%),选择性模式为辅(33.3%),P前置式(56.7%)略高于P后置式(43.3%)。
综合上述分析,与汉语母语者相比,日本留学生构建的汉语中介语篇,倾向于选用“I缺省型选择性模式”作为主要的信息模式类型,倾向于“全息性模式”作为辅助信息模型,倾向于将p类信息靠前配置。
(五)模块结构关系的特征

表8:IJ组和CT组内样本使用的结构关系类型及所占百分比
IJ组内各个信息模块共使用了9种不同的结构关系,使用的总频次为104次,CT组使用的结构关系类型也是9种,使用总频次为140次,显著高于IJ组。从各种结构关系的使用比例来看,“背景关系”日本留学生的使用比例为14.42%,汉语母语者的使用比例为18.57%,“对比关系”前者的使用比例为1.92%,后者的使用比例为7.14%,日本留学生这两种关系的使用比例分别比汉语母语者低了4.15% 和5.22%;“证据关系”中,IJ组的使用比例为28.85%,比CT组高出了7.42%。
通过以上数据分析,可以看出:日本留学生篇章结构关系整体建构能力要低于汉语母语者,但是在构建篇章时使用的结构关系型例与汉语母语者之间不存在显著差异;日本留学生“背景关系”“对比关系”的使用率低于汉语母语者,但“证据关系”的使用率要高于母语者,也就是说,日本留学生偏好集中使用论证结构的核心关系类型构建篇章,对不同类型结构关系的使用不均衡。
(六)日本留学生论证性语篇信息结构的中介特征
根据对不同构成参项特点的分析,我们将日本留学生论证性语篇信息结构的中介性特征总结如下:
第一,层级建构能力,尤其是深度信息层级的建构能力显著低于汉语母语者。通过日本留学生与汉语母语者之间的对比,我们发现留学生篇章信息结构的层级复杂度与总体建构力明显低于母语者,而这种差异主要在第三、四、五信息层之间,首信息层与第二信息层之间并无显著差异,也就是说,日本留学生建构浅层信息的能力较强,但是构建深层信息的能力不足。
第二,信息点的配置能力,尤其是I(引言)类信息和深层E(论据)类信息的配置能力显著低于汉语母语者。从各类不同信息点配置的数量均值来看,日本留学生信息模块的整体配置能力要低于母语者。这种差异主要体现在两类信息点的配置上:一类是I(引言)类信息,留学生的中介语篇更倾向于缺省该类信息;另一类是第三信息层E(论据)类信息,目标语篇显著高于中介语篇。
第三,篇章信息结构的核心信息导入方式与母语者不同。与汉语母语者通过附属背景信息导入核心信息不同,日本留学生更偏好在不涉及背景信息的状态下直接进入论证结构的核心部分。
第四,信息量输出能力显著低于汉语母语者。通过信息点信息量均值的比较,我们发现日本留学生信息点的信息量均值显著少于汉语母语者。也就是说,日本留学生在相同时间内的信息量输出能力显著低于汉语母语者。
第五,倾向于选用“I缺省,P前置,选择性模式”作为主导信息模型,选用“全息性模式”作为辅助信息模型。从对比结果看,汉语母语者在构建论证性语篇时,倾向于采用全息性信息模型,倾向于将P(论点)置于论据之前,日本留学生则不同,其在建构语篇时,偏好采用I缺省的选择性信息模型,将全息性模型作为附属模型。
第六,信息模块结构关系建构能力低于母语者,且各种结构关系使用不均衡,存在核心关系类型偏好。日本留学生使用的结构关系型例与汉语母语者基本一致,但是使用的数量远低于汉语母语者。日本留学生结构关系使用的另一特点是具有明显的偏好性,即偏好使用“论据”和“联合”两种关系进行篇章构建。这种倾向与留学生篇章建构的模式化特点存在密切关系。
综上,与汉语母语者相比,日本留学生论证性语篇信息结构的构建呈现出信息输出量偏低、深层论据信息构建力不足、偏好使用核心型例和I缺省选择性信息模型等中介性特点。
三、篇章信息结构教学策略的选择
1.充分重视语体的制约作用,实行分语体教学。语体对语篇的宏观信息结构有着十分重要的影响,语体不同其信息结构也会有所不同。这种差异性让我们提高宏观信息结构教学有效性与针对性最好的方式是进行分语体的教授与训练。大多数教材在编写中会提到某一种或几种篇章结构模式,但是对同一语体信息结构存在的多种变体关注度不够。鉴于此,教学过程可以在坚持分语体教学的基础上,建立以常用结构模式为核心的宏观信息结构原型范畴,做到分语体训练与分模式训练的有机结合。
2.充分重视微观信息结构系统的外在影响,在教学中做到宏观与微观相互结合。语篇内的信息结构可分为微观与宏观两大类。其中,前者是后者形成与建立的基础。两者之间存在正相关的关系。因此,在教学实践中除了对宏观信息结构进行有针对性的专门训练之外,教师还要不断提高留学生的微观信息结构构建能力,在日常教学中要有意识地通过“归纳主题句”“话题句扩展”“给话题作文”“篇章链接语填空”等训练手段来沟通学习者的这两种能力。
3.充分重视各个构建要素之间的区别与联系,在教学中进行分解性的“面—点”训练和组合性的“点—面”训练。篇章信息结构是一个多要素聚合而成的综合体,在教学实践中可以进行由面及点的分解性训练。比如,教师可以对论证性语篇中各个构成要素的建构能力进行分项训练,也可以在教学过程中进行由点及面的反向组合式练习,比如,教师可以在教学中通过“篇章连接词填空”“关联词改错”等方法训练留学生把握信息模块间功能关系的能力。
(本文为2014年广州市哲学社会科学“十二五”规划青年课题“基于中介语语料库的日本留学生论证性语篇信息结构习得研究”[项目批准号14Q02]、广州市教育科学“十二五”规划青年专项课题“语类理论视阈下的对外汉语篇章教学模式研究”[项目号:2013A069]的阶段性成果。)
[1]杜金榜.法律语篇树状信息结构研究[J].现代外语,2007,(1).
[2]廖秋忠.篇章中的论证结构[J].语言教学与研究,1988,(1).
[3]吴丽君.日本学生汉语习得偏误研究[M].北京:中国社会科学出版社,2002.
[4]马明艳.面向对外汉语教学的汉语语篇研究[M].北京:中国社会科学出版社,2009.
[5]Büring,D.On D-trees,beans,and B-accents.Linguistics and Philosophy,2003,(26):511-545.
[6]Kaplan,R.B.Cultural thought patterns in intercultural education .Language learning,1966,(16):1-20.
[7]van Dijk,T.A.Macrostructures:An Interdisciplinary Study of Global Structures in Discourse Interaction and Cognition.Hillsdale,N.J.:Lawrence Erlbaum Assaciate,1980.
(张迎宝 广东广州 广州大学人文学院 510006)
