基于双层语料过滤器的短语抽取方法
2015-11-25林伟佳郭靖羽丁东辉
林 波,林伟佳,郭靖羽,丁东辉,黄 翰
(1.中国移动通信集团广东有限公司,广东 广州 510006;2.华南理工大学软件学院,广东 广州 510006)
0 引言
互联网在给予人们丰富信息的过程中,也给予人们急切获取第一手重要热点信息带来的困扰。在信息爆炸的时代,人们被动地接受大量无效的垃圾信息,也花费大量的时间和精力去寻找关注感兴趣的网络话题[1-2]。尽管目前的搜索引擎能在一定程度上引导用户去获取特定的信息,针对时效性较高的网络话题,还是无法提供较为深入的隐含话题信息挖掘以及话题跟踪的统计显示。人们迫切需要在网络信息搜索方面能提供较为全面的网络话题挖掘与跟踪的服务,能够无论从时间线或者热门程度方面都能有直观的话题信息演化过程。人们不仅需要获知网络话题所涉及的概括性描述,也希望从中获知其他人针对该话题的具体细节评价和讨论。
国外针对短文本的提取已经有很多指导性工作。例如Mehran Sahami[3]等采用以Web 语义核函数为基础方法来抽取概念类似的短语,应用于文档的信息语义概括。D.Metaler[4]等从相似性的度量角度来挖掘发现短文本之间的关联程度。W.Yih[5]等通过对前人的工作进行方法完善,结合当时Web 的发展趋势适时扩展Web 语义核函数,深化了语义核函数的影响。Xuan-Hieu Phan[6]等人为了解决短文本的稀疏性问题,尝试性地提供采用隐匿的文档主题来建立较为广泛的模型架构。J.Hyneck 扩展了Apriori 的词集分类方法,并应用于文献的文档分类工作中。D.Song 以领域知识库的建立作为基本出发点,通过采集消息流和研究并预测其趋向来对短文本实现分类工作。S.Tant[7]等结合专利知识数据以及术语库来进行跨领域的术语提取。Dacheng Liu[8]等提出半自动的语料分割器针对专利知识数据进行专利术语的信息抽取。K.K.Bharti[9]等通过对文本不同维度的特征重要度进行排序,提出混合维度的文本特征选择方法来改进文本特征表示。
由于中文汉字的复杂性以及前期缺乏相关研究,学者未针对短文本进行系统分析,国内针对短文本的研究相对比较晚,其研究方向基本可以分为2 类:
1)基于词语规则的方法。基于词语规则方法本质是总结并分析不同词语之间相互关系来进行规则归纳,并对待处理文本执行后续工作。例如吴薇[10]利用正则表达式规则初始化步骤来对海量文本实现规则过滤。王鹏[11]使用词语之间的依存关联来进行词语的提炼,进而扩充文本的基本维度属性。王细薇[12]首先对短文本抽象概念词进行统计,然后使用词语的关联关系对候选词实现表征扩充。胡吉祥[13]基于短文本中词频或短语串频的统计信息来进行细粒度信息的提取以及特征表示。
2)基于文本语义的规则方法。基于语义方法本质是搜索通用知识库来进行文本语义信息的抽取。如宁亚辉[14]首先利用《知网》来获取不同层次的基础词汇本体,在这些候选种子词的基础上采用中心邻近的分类方法。盛宇利[15]基于“熟悉原理”、“典型原理”的心理认知学知识对文本进行初步的预处理,包括引入白名单词库以及典型词库来进行分词,提高词语的辨别准确度。王永恒利用词语语义特征构建了特征网络图,然后通过描述网络图的中心邻近程度来实现分类。
本文以文本短语为基本语义信息单位,针对中文短语抽取进行研究,提出基于双层语料过滤器(词性过滤器与短语扩展规则过滤器)的方法来进行文本语料的冗余信息过滤,并抽取文本主题短语信息。其中词性过滤器从通用的中文本质的词性规则出发来进行初步候选短语过滤,短语扩展规则过滤器从特点语料知识的统计分析规则来进行二次过滤。
1 短语串的语义表达优势
从中文的自然语言角度分析,汉语的语言结构的语义表达单元为:汉字-词汇-短语-句子-段落-文档[16]。其语义单元的级别越高,其包含的信息量也越多。由于汉语本身并非只有汉字的语义信息进行拼接,其信息内容本身存在上下文关系,因此随着语义表达单元包含的基本语素(汉字)单元数目增加,其信息内容的丰富程度远超于线性增长,其信息粒度也是随着层次的增加而逐步增大[17]。在日常的人类社会中,句子是作为常见的沟通交流的语义表达单元,能够清晰传递信息。句子尽管可作为基本的信息载体单元,但由于句子受限于客观的语法结构,其中也包含了大量冗余的无价值信息。其语义表达不够简练,人们理解句子的语义也是需要无意识地快速筛选出句子的主干意思来进行消息接收。
本文考虑采用相比句子较低层次的短语来作为语义表达单元。中文短语串相对于句子而言也有类似的词法结构(主谓结构、动宾结构等),在语义表达方面满足最基本的要求。中文短语串相对于低层次级别的词汇,其信息丰富量更多,短语串中的词汇间通过特定的组合搭配结构,能够表达出远多于纯粹词汇之间拼凑而成的信息。
目前在文本特征表示步骤中,词汇作为文档的特征项实际上仅仅作为一个标签属性值的形式存在,词汇自身并没有为特征表征提供更多的语义信息。然而通过短语抽取,在文本特征表达的同时还可以直观地理解文本的语义含义。在探索和挖掘中文短语结构组成的同时,有助于对中文自然语言处理研究提供可参考性的意见。
2 双层语料过滤器的主要思想
语料过滤器主要是基于中文短语本质的词性规则组成方式和基于统计分析理论来进行设计。
1)从词性规则组成方式:适用于大多数符合中文词法语法规则的中文短语,具有一般普遍性。
2)从统计分析理论出发:适用于针对某一类专有知识资料的语料过滤。由于针对特定某类的专有知识的短语特征较为明显,许多词语形成固定的短语搭配,容易从统计角度来获取词语之间的基于前后位置的频次关联关系。
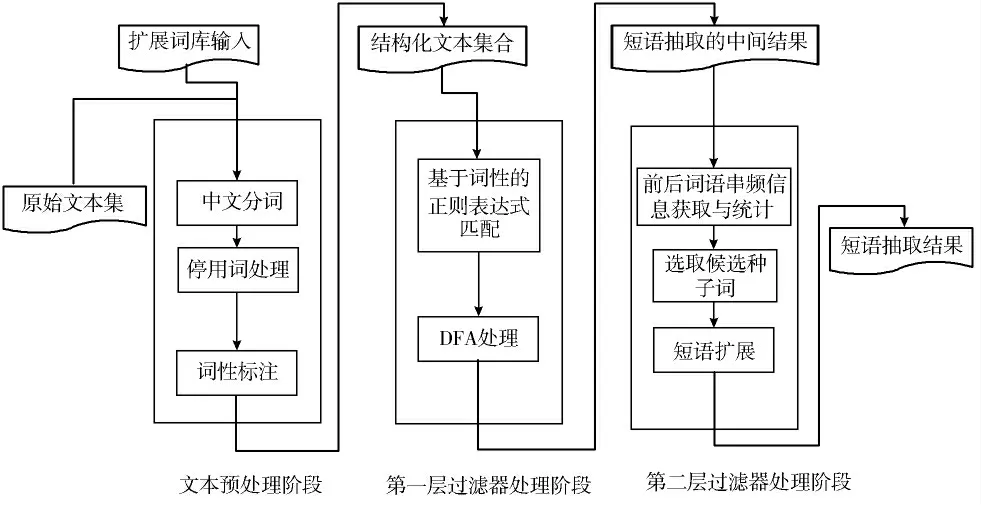
图1 短语抽取方法的主要处理步骤流程
短语抽取方法的主要处理流程步骤(见图1):
1)预处理阶段。在预处理阶段主要包括了常规的文本分析的预处理步骤,包括中文分词、停用词处理和词性标注。针对本文需要处理的文本语料由于其专有性比较强,语料中存在大量的专有名词,因此引入另外的扩展词库来提高中文分词的准确度和精度,扩展词库可不断进行知识术语关键词的存储和更新维护。
2)第一层过滤器处理阶段。第一层语料过滤器的输入文本是基于结构化的文本集合,该文本集合由最基本的中文词语所构成,每个词语都已经标注了词性。其中由于并非所有词性的词都能构成句子的细粒度短语,因此重点研究其中的名词、形容词、动词和副词4 种词性的词语,并根据中文的短语语法知识归纳出这4 种词性短语所构成的所有可能形式。从短语的结构考查分析,其中并列短语、偏正短语、动宾短语、主谓短语构成了句子的主要短语信息,因此根据这4 种基本短语规则组成方式作为第一层语料过滤器的模式匹配规则。通过输入短语规则组成的正则表达式,建立了相对应的第一层语料过滤器的短语抽取确定性有限状态自动机(Deterministic Finite Automaton,DFA),进而作为具体的算法处理来得到初步的短语筛选结果,这部分短语筛选结果将作为第二层语料过滤器的输入样本。
3)第二层过滤器处理阶段。第二层语料过滤器是基于词语串频的统计分析而建立的。词语串频信息是在测试样本中指前后2 个词同时出现的频次,同时包括2 个词语的字符内容以及位置信息。由于第一层过滤器是基于短语本质的规则组成方式而建立,其抽取出来的短语结果中有部分显然不是实际的短语,会出现信息冗余或者信息截断的现象。因此,针对包含了大量固定短语搭配的专有语料,分析词语串频次的信息来获取其中固定短语串的词语组成方式。在对所有初次筛选过后的短语结果中,以词语为单位来统计词语串频信息,然后在短语结果中选取候选种子词,并从最基本的候选种子词出发,从前向和后向2 个方向进行短语扩展,其扩展的主要判断依据也是依赖词语串频信息。当短语扩展达到了扩展的终止条件,则停止扩展步骤,获取最终的短语抽取结果。
3 第一层语料过滤器——词性过滤器
第一层语料过滤器是从短语结构构成的词性角度出发,采用正则表达式的规则来进行数学模型描述。词性过滤器的设计是通过DFA 的处理来进行实现。
3.1 基于词性的正则表达式匹配
笔者从搜狗实验室下载了100 篇较短的新闻语料文章,其中包含的句子数目为1 610 个,从中标注了句子的短语数目,进行统计分析,中文短语的含词量基本分布在1~7 个,因此以7 个词语作为短语长度的上限,见图2。
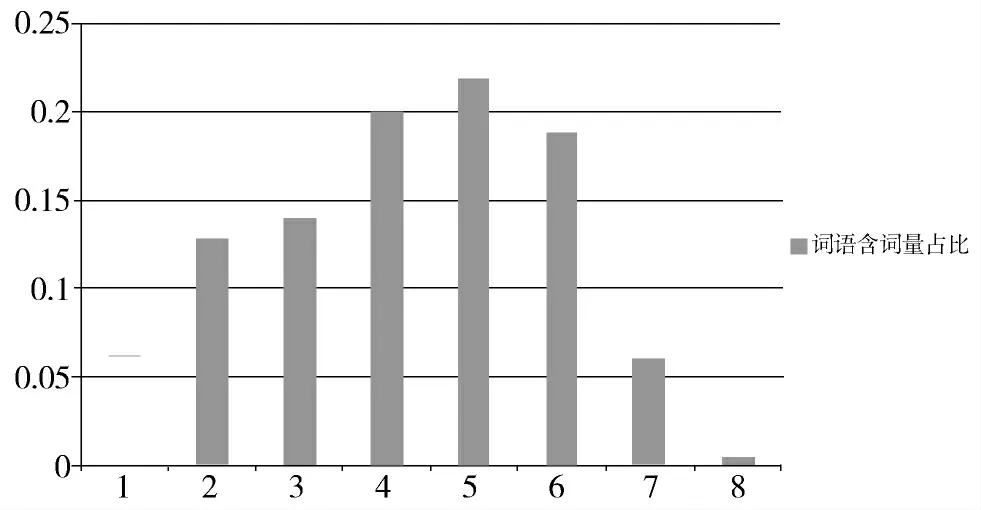
图2 搜狗新闻语料含词量占比
对其中的语料短语进行结构上的分析,短语的词性包括4 种词语词性:名词n、动词v、形容词adj 和副词adv。参考目前的中文汉语语法,用于表达中文语义的短语类型主要分类如下:
1)并列短语。地位平等,互不修饰,其形式包括:n+n/v+v/adj+adj/adv+adv。
2)偏正短语。前一个词语对后一个词语进行修饰限制,其形式包括:adj+n/adv+adj/adv+v。
3)动宾短语。动词和宾语是支配关系,其形式包括:v+n/v+v/v+adj。
4)主谓结构。形式包括:n+v/n+adj。
正则表达式(Regular Expressions)的本质核心是通过字符的格式匹配来进行词法分析。目前已经被ISO 国际标准组织批准认定,已经广泛应用到信息技术领域,许多计算机应用平台和脚本语言支持正则表达式的词法规则。基于上述中文短语的长度上限为7个词语,根据短语结构的词性组成内容,在短长度内能够枚举相对可能出现的词性短语组成的正则表达式:
1)以名词作为短语首词:
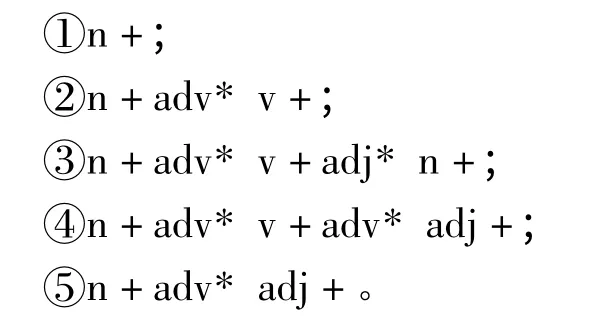
2)以动词作为短语首词:
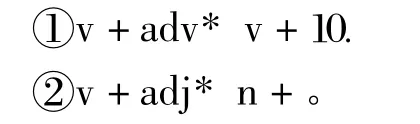
3)以形容词作为短语首词:

4)以副词作为短语首词:

以上基本包含了7 个或7 个词语长度以下的短语结构的组成方式,通过3.2 节中的DFA 处理和代码实现来获取初步的短语抽取结果。
3.2 基于词性的正则表达式匹配
基于3.1 节所列举的基于词性的正则表达式,设计确定性有限状态自动机来进行短语的抽取。图3~图6 分别为以不同词性(n,v,adj,adv)为开头的DFA 匹配处理过程。
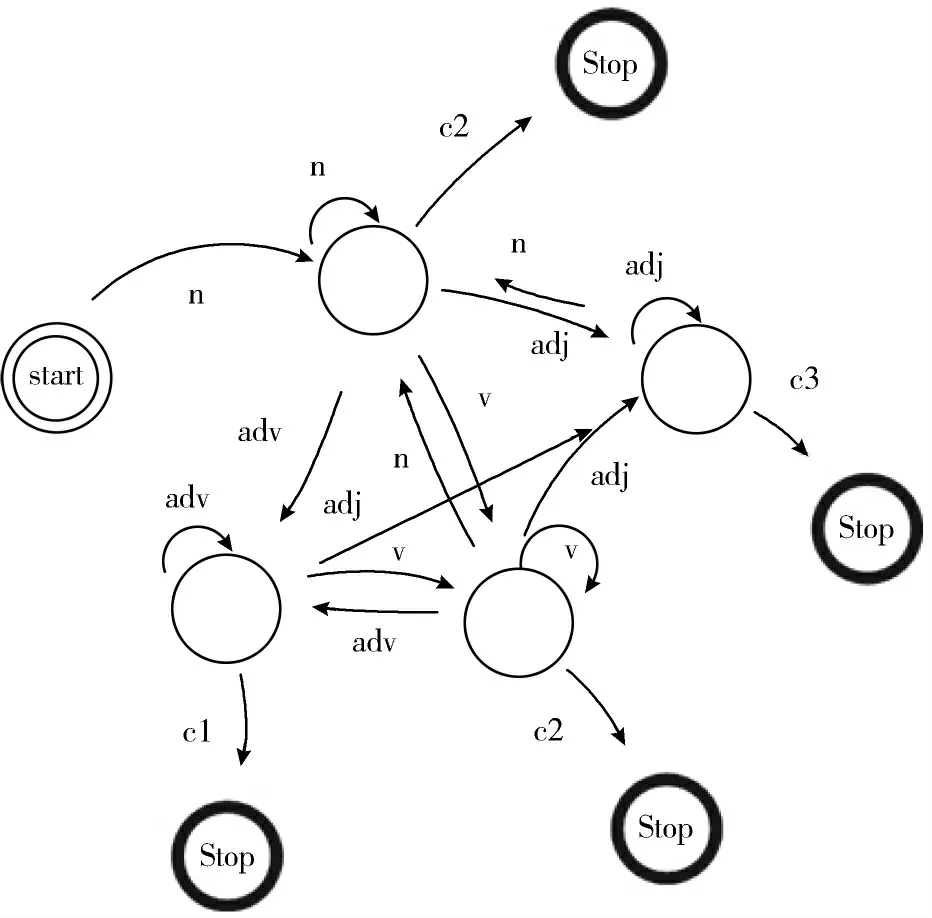
图3 以名词n 为开始的有限状态自动机

图4 以动词v 为开始的有限状态自动机
其中,在以上确定性有限状态自动机的状态中的转移条件如下:
1)n:匹配到名词n。
2)v:匹配到动词v。
3)adj:匹配到形容词adj。
4)adv:匹配到副词adv。
5)c1:匹配到除了adv 和v 以外的词。
6)c2:匹配到除了n、v、adj 和adv 以外的词。
7)c3:匹配到除了adj 和n 以外的词。

图5 以形容词adj 为开始的有限状态自动机

图6 以副词adv 为开始的有限状态自动机
在代码实现中,采用DFA 作为短语文本匹配的主要实现方式,并得到最初的短语抽取实验结果。由于在进行词性规则匹配的过程中,词语的词性有限并且可枚举,其状态转移条件相对简单,使用DFA 能够直观地表示整个词性规则匹配的过程。同时DFA 也具有良好的扩展性,例如在进行词性规则重构时出现了另外的词性需要处理(介词、代词等),只需要在原有的DFA 基础上增加状态转移条件即可完成扩展。
4 第二层语料过滤器——短语扩展过滤器
4.1 词语串频信息统计
词语串频信息包括前缀词语串频集合和后缀词语串频集合。前缀词语串频集合是指候选种子词的前缀词语所组成的集合,包括前缀词语的词语内容以及出现频次。本文用数学集合进行表示,对于某一种子词t,前缀词语串频集合p_set(prefix-set)定义如下:
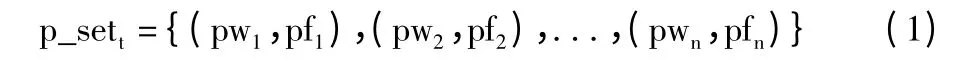
其中,pwi是第i 个前缀词,pfi是第i 个前缀词出现的频次。
类似地,后缀词语串频集合是指候选种子词的后缀词语所组成的集合,也包含了词语的词语内容以及出现频次。对于某一种子词t,后缀词语串频集合s_set(suffix-set)定义如下:
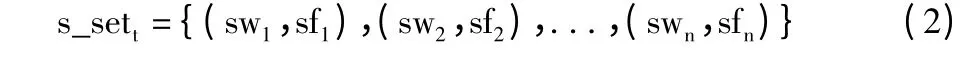
其中,swi是第i 个后缀词,sfi是第i 个后缀词出现的频次。
对于种子词,最频繁前缀词是前缀词语集合中频次最高的前缀词,最频繁后缀词是后缀词语集合中频次最高的后缀词。其定义分别如下:

前缀词最高频比max_p_freqt是最频繁前缀词的频次与所有前缀词频次求和的比率。

后缀词最高频比max_s_freqt是最频繁后缀词的频次与所有后缀词频次求和的比率。

针对目前热门词“股市”在网络上进行搜索,摘录了一些句子文本集合进行举例说明。
1)安本亚洲高管周二警告称,中国股市资金流动情况已经“有点像赌场”。
2)因全球股市上涨和美元走坚,打击了黄金作为避险资产的魅力。
3)股市市场是已经发行的股票转让、买卖和流通的场所,包括交易所市场和场外交易市场2 大类别。
4)繁荣股市帮助实体经济扩大股权融资、降低过高负债、减少财务成本创造了条件。
5)比如,16 日中国股市上涨,创5 年来的新高,就在于市场预期央行降准降息会陆续出台。
6)在其看来,股市上涨的根本原因是均值回归。
7)近日有一种观点认为,股市上涨与楼市低迷是密不可分的,是楼市释放了大量资金,提供了强有力的货币基础。
8)股市行情大盘指数飙高,同时余额宝收益受影响。
9)GDP 在增长,却导致股市低迷。
通过对文本集合进行分词并统计词语串频信息,候选种子词“股市”的词语串频信息如下(见图7):

图7 基于种子词“股市”的前缀词语串频集合和后缀词语串频集合
4.2 词语串频信息参数分析
前缀词语串频集合p_set 和后缀词语串频集合s_set 包含了种子词在上下文中的词语串共现的信息。p_set 和s_set 的集合越大,表示该种子词越容易和其他词语进行组合,从而完成词语的扩展。然而对于文本的大规模统计分析而言,p_set 和s_set 中每个前缀词语或者后缀词语相对应的频次pf 和sf 大小决定了该前缀词语或者后缀词语是否会成为种子词扩展。本文定义一个阈值thresholdt来进行pf 和sf 的对比,当pf 和sf 的值高于阈值threshold,则判断前缀词语或者后缀词语符合短语扩展的条件从而进行短语扩展。假设qi,t为布尔变量对应于某个前缀或后缀词语能否作为种子词t 的扩展词来进行短语扩展,那么:

因此对于4.1 节的例子,当threshold=2 时,那么“股市”作为其种子词将会在文本1)中扩展为“中国股市”,在文本2)、6)、7)中将扩展为“股市上涨”,在文本5)中将扩展为“中国股市上涨”。然而当threshold=4 时,“股市”作为其种子词只能扩展为在文本2)、5)~7)中扩展成为“股市上涨”。
4.3 候选种子词选取与短语扩展
基于4.2 节对于种子词的分析,p_set 和s_set 的集合大小越大越容易成为种子词。单纯计算p_set和s_set 的集合元素的个数进行求和是有所欠缺考虑的。
假设某种子词p 的p_set 元素个数为10,s_set 的元素个数为2,其元素个数总和为12。然而同一短语中的另外一个种子词q 的s_set 元素个数为5,s_set的元素个数为2,其元素个数总和为7。直观而言,在集合元素大小的比较中,种子词q 与种子词p 相比处于劣势。从词语扩展性的角度而言,种子词p 很有可能作为其他词语的后缀词而出现(因为其p_set 的元素个数远远大于s_set 的个数),其后缀扩展性比较差,而种子词q 的p_set 与s_set 的元素个数相当,因此种子词q 容易作为文本短语中位置处于中心的词,起着联系前后的作用。因此在候选种子词的选择上,仿照笛卡儿乘积的思想,选取p_set 和s_set 的集合元素的个数分别加上1,再进行乘积计算作为判断依据,用candidate-value 表示:
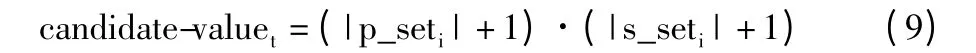
2 个乘数之所以要加上1,主要是避免某些词语的p_set 或者s_set 中元素个数为0 直接导致其candidate-value 的值为0,但是实际上该词语在进行候选种子词时依然有其贡献度。
假设seed_word 是所需寻找的候选种子词用于扩展,{t1,t2,...,tn}是短语中的词语集合,那么:

在选取种子词后就能够对短语进行扩展,因此其主要的第二层语料过滤器的流程步骤如下:
1)输入中间短语结果。
2)遍历短语中每一个词,统计每个词语的词语串频信息,包括得到p_set 和s_set,max_pw,max_p_freq,max_sw,max_s_freq。
3)根据公式(10)选取候选种子词。
4)进行并行操作:向前进行短语扩展和向后进行短语扩展。在扩展的过程中,如果达到短语的扩展边界则认为达到扩展终止条件,或者当找不到前缀词或者后缀词作为新的扩展种子词时则停止扩展。
5)输出短语抽取结果。
第二层语料过滤器的流程步骤如图8 所示。
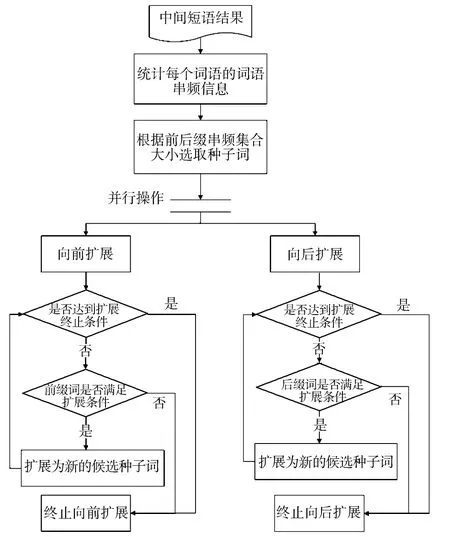
图8 第二层语料过滤器的流程步骤
第二层语料过滤器的伪代码如下:
算法1 第二层语料过滤器算法描述


5 实验与计算结果
本文根据第一层语料过滤器设计了DFA 进行初步的短语抽取,同时根据算法1 设计第二层语料过滤器,并对目前已有的文本数据资源进行实验结果分析。算法采用Java 语言编写实现。
本实验运行在CPU 为Intel(R)Core(TM)i5-3210M,内存为DDR3 1333,4 GB,显卡为NVIDIA Ge-Force GT 540M,硬盘容量为500GB,操作系统为Window 7 x64 的机器上(见表1)。

表1 软硬件系统环境
该文本数据资源来源于广东移动公司的投诉文本记录(已经对移动客户的私隐信息进行消除),抽取了其中500 条投诉文本记录,并逐条拟定其关键短语并进行实验对比。该500 条投诉文本记录分成10组进行测试。平均每条投诉文本记录的长度为51.7个汉语字符。
采用准确率、召回率来评价实验的结果,定义如下:

其中,{result_phrase}是自动抽取的关键短语结果,{tag_phrase}是笔者拟定的关键短语结果。
表2 是基于实验结果的数据,图9~图11 是实验的P 值、R 值、F1 值曲线图。
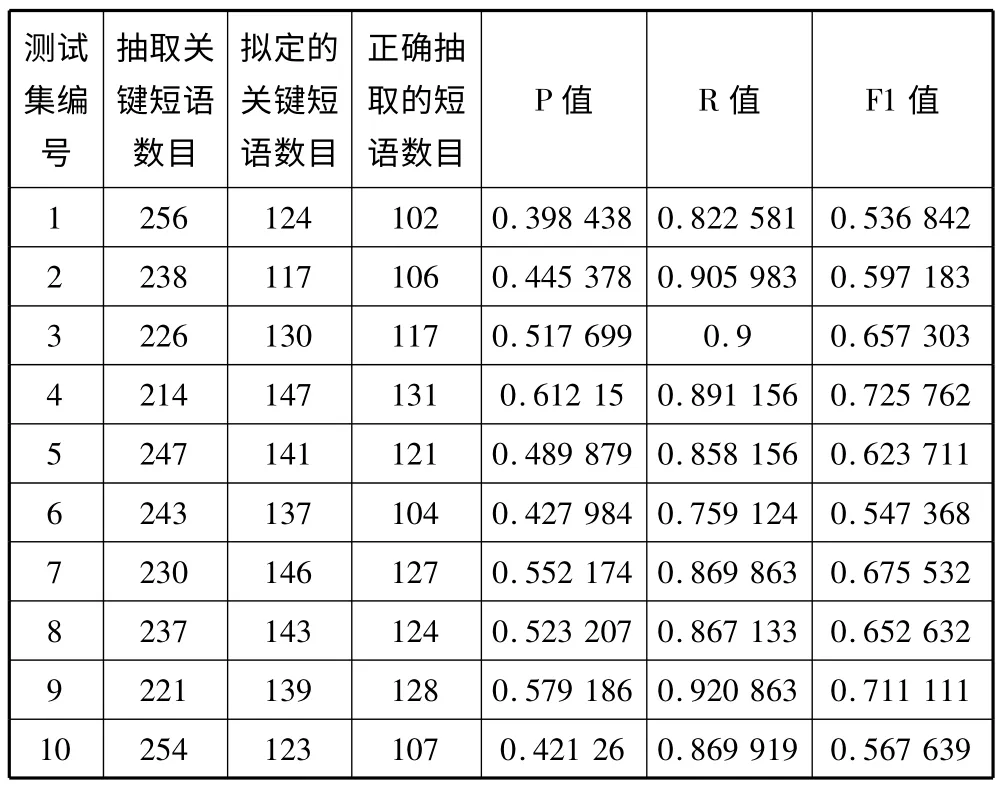
表2 基于10 个结果测试集的P 值、R 值、F1 值
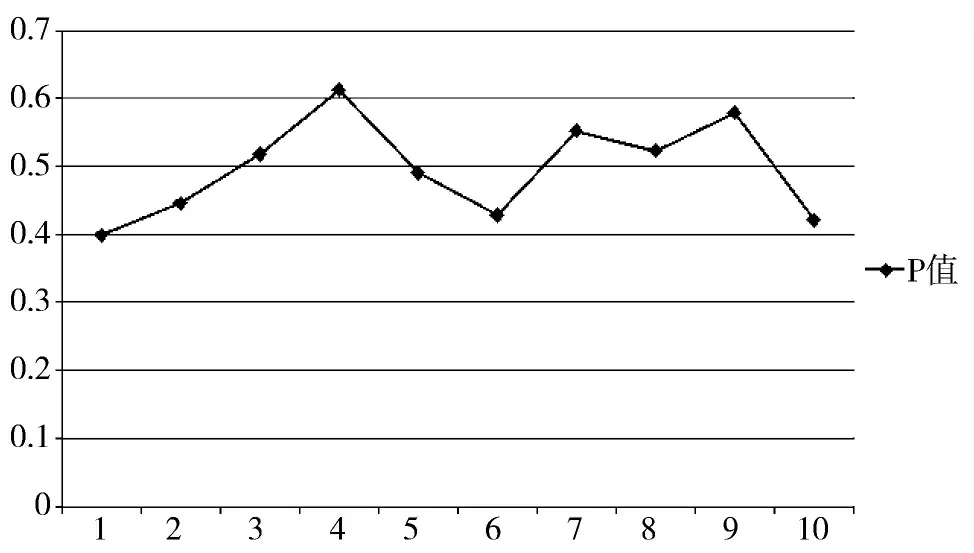
图9 基于10 组结果测试集的P 值曲线图
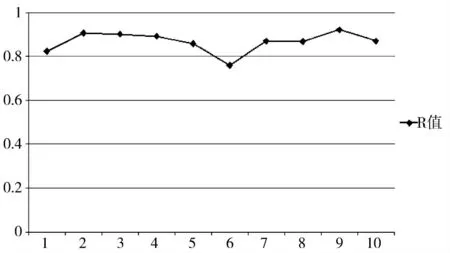
图10 基于10 组结果测试集的R 值曲线图
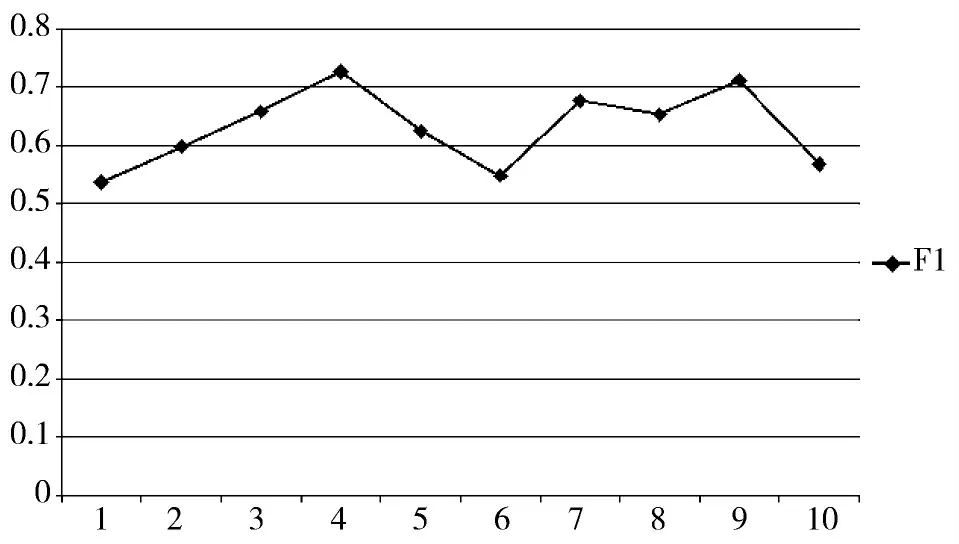
图11 基于10 组结果测试集的F1 值曲线图
从实验结果来看,双层语料过滤器在查全率的效果比较优异,R 值基本上都位于0.8 以上(除了第6组测试数据比较低),这说明抽取出来的短语集合里包含了大多数预期中的短语。
P 值基本在0.4~0.6 之间波动,主要原因是在文本中会出现一些修饰意义比较高的短语成分,这些成分对于文本的表达起着补充的作用,但并非文本的主旨意思。然而双层语料过滤器也会把这些修饰的短语提取出来,如何进一步通过语义的方法把这些噪声信息剔除出去是值得研究的改进之处。
双层语料过滤器目前只考虑了4 种词性的规则关系,具有较强的扩展性。对于不同的文档数据集,通过分析文本数据词性规则还能够加入其他词性的词语进行规则重构,进一步提高P 值以及F1 值。
6 结束语
本文首先对目前在文本信息抽取研究领域进行了介绍和分析,梳理了目前技术发展的主流趋势以及遇到的瓶颈问题,并基于中文短语串在文本主题语义表达上的优势,论证了短语串在细粒度主题抽取方面的重要性,为下一步对文本片段的信息抽取奠定了一定的基础。从语料知识的通用性和专有性2 方面出发,设计了双层的语料过滤器。第一层语料过滤器是从通用的语料词性规则组成出发,研究了最为常见的短语搭配形式,枚举所有可能的词性组成规则,通过分词后对文本片段进行词性分析处理,过滤掉规则以外的冗余信息。第二层语料过滤器是从语料知识的统计出发,研究了某一专有语料知识在短语构成中特有的短语规则组成形式,在第一层语料过滤器的结果的基础上选取候选词进行短语扩展,直至满足扩展终止条件,最终完成短语抽取。双层语料过滤器不需要对语料样本进行先行的知识库输入或者词性语义的模型建立,通用性较强。随着语料样本的规模扩大,语料过滤器的短语抽取效果会更好。
[1]中国互联网络信息中心.第35 次中国互联网络发展状况统计报告[DB/OL].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/201502/P020150203551802054676.pdf,2015-03-26.
[2]鲁明羽,姚晓娜,魏善岭.基于模糊聚类的网络论坛热点话题挖掘[J].大连海事大学学报(自然科学版),2008,34(4):52-54.
[3]Sahami Mehran,Heilman Timothy D.A Web-based kernel function for measuring the similarity of short text snippets[C]// Proceedings of ACM the 15th International Conference on World Wide Web.2006:377-386.
[4]Metaler D,Dumais S,Meek C.Similarity measures for short segments of text[C]// European Colloquium on IR Research-ECIR.2007:16-27.
[5]Yih W,Meek C.Improving similarity measures for short segments of text[C]// National Conference on Artificial Intelligence-AAAI.2007:1489-1494.
[6]Phan Xuan-Hieu,Nguyen Le-Minh,Horiguchi Susumu.Learning to classify short and sparse Text&Web with hidden topics from large-scale data collections[C]// World Wide Web Conference Series-WWW.2008:91-100.
[7]Tantanasiriwong Supaporn,Haruechaiyasak Choochart,Guha Sumanta.A comparative study of key phrase extraction for cross-domain document collections[C]// The 16th International Conference on Asia-Pacific Digital Libraries.2014:393-398.
[8]Liu Dacheng,Peng Zhiyong,Liu Bin,et al.Technology effect phrase extraction in Chinese patent abstracts[C]//Web Technologies and Applications,Lecture Notes in Computer Science.2014,8709:141-152.
[9]Bharti Kusum Kumari,Singh Pramod Kumar.Hybrid dimension reduction by integrating feature selection with feature extraction method for text clustering[J].Expert Systems with Applications,2015,42(6):3105-3114.
[10]吴薇.大规模短文本的分类过滤方法研究[D].北京:北京邮电大学,2007.
[11]王鹏.文本分类中利用依存关系的实验研究[J].计算机工程,2010,46(3):131-133.
[12]王细薇.基于特征扩展的中文短文本分类方法[J].计算机应用,2009,29(3):843-845.
[13]胡吉祥.基于频繁模式的消息文本聚类研究[D].北京:中科院研究生院,2006.
[14]宁亚辉.基于领域词语本体的短文本分类[J].计算机科学,2009,36(3):142-145.
[15]盛宇利.自然语言理解心理学在短文本分类中的实证研究[J].现代情报,2009,29(8):4-7.
[16]桂卓民.基于事件的多文档自动文摘系统的研究[D].武汉:华中师范大学,2010.
[17]冯琴荣,苗夺谦,程昳.决策表属性约简的相对划分粒度表示[J].小型微型计算机系统,2008,29(12):2305-2308.
