基于Hadoop 的水利元数据语义搜索方法
2015-11-25李宗祥唐志贤
冯 钧,李宗祥,唐志贤,姜 康
(河海大学计算机与信息学院,江苏 南京 211100)
0 引言
随着物联网、云计算、移动互联网以及RS 技术在水利行业的广泛应用,水利行业迅速积累了海量、分布、异构的水利业务数据。构建水利信息资源目录服务系统是整合水利业务数据、实现数据共享以及深度利用分散存储数据的有效途径[1]。元数据搜索是资源目录服务系统的关键技术之一[2],目前对于元数据的检索,大多是基于关键词的简单匹配,忽略了水利数据之间的关联关系,形成“语义漂移”、“机械匹配”、“语义不一致”等问题,影响了搜索结果的查全率与查准率。此外,水利元数据多由XML 描述,在对元数据建立索引时,需要解析元数据,提取其中关键信息来建立索引,由于结构化元数据上下文存在关联性,解析过程需要获取元数据的整体结构,导致解析效率低下。针对上述问题,本文首先结合本体与查询扩展技术,提出一种基于本体的语义搜索方法,在元数据搜索中考虑水利数据之间的语义关联,使搜索结果更加符合用户意图;其次,针对XML 形式水利元数据建立索引效率低下的问题,引入Hadoop 平台中的MapReduce 并行处理模型,由于XML 的解析需要一个完整的XML 文件,如果直接采用Hadoop 的划分机制,将会把一个完整的XML 文件分到不同的分片中去,造成元数据解析错误,所以本文改进Hadoop 中SequenceFile 的结构,使水利元数据及相关文件能够合并存储在HDFS 中以及被MapReduce 切割为独立、完整的文件,接着利用MapReduce 并行地解析完整的水利元数据文件并建立索引,并在此基础上提出一种分布式环境下基于本体的扩展查询方法。
1 相关研究
语义搜索是语义技术与信息检索结合的产物,目的是利用语义技术来提高信息检索的搜索效果[3]。Yu Xuejun 等人[4]利用关键词扩展技术构建搜索引擎,在对相关词汇进行扩展时,考虑词语之间的相似性;Marcelo G.Armentano 等人[5]利用NLP 技术解决了搜索引擎中对实体自动命名与识别的问题。T.Tran 等人[6]设计开发了语义搜索引擎SemSearch,通过关键词扩展的方式来解析用户的查询表达式,该方法提供了语义扩展的思路,但是没有考虑扩展词的选择情况;Qiu Yonggang 等人[7]通过构建词汇相似性表的方式来扩展查询词,在查询时比较检索词与查询的相似度,选择相似度较高的关键词添加到查询中。文献[8]提出把首次搜索结果中最相关的若干篇文档作为查询扩展的来源,由于扩展效果依赖首次查询结果的数量与质量,使得局部分析法扩展的准确率难以保证;而文献[9]提出一种基于语义的查询扩展是利用本体中概念之间的语义关系来扩展查询词,增加对用户搜索意图的理解,消除了语义歧义。
在分布式搜索引擎的相关研究工作中,文献[10]提出在MapReduce 模型中对Xquery 的语法、特征、语义进行扩展,建立了ChuQL 查询语言;Bhavik Shah 等人[11]从XML DOM 节点的树形结构出发,提出了ParDOM 解析方法,ParDOM 在解析XML 时考虑了标签的分割,把分割后的数据块使用MapReduce的并行处理后,再对处理后的结果进行合并;魏永山等人[12]针对大型XML 文件,使用XPath 投影的方法对文件进行划分,只保留对查询结果有贡献的数据段,把切割后的数据块放入MapReduce 进行并行查询,提高了查询的性能。
2 基于本体的语义搜索方法
2.1 本体的建立与推理规则
本文的领域背景设定在水利领域,所以笔者利用《水利公文主题词表》限定了本体构建的范围,确定水利领域本体中概念的范围,并使用Jena 对水利领域本体进行推理。Jena 包含一个默认支持OWL 的推理机制,但Jena 原生支持的推理规则集中不支持水利领域中的隐含关系,例如:淮河与河流之间存在相关关系,支流作为河流的子类,淮河与河流之间也应该存在相关关系,因此将扩展现有的推理规则,来发现水利领域本体中隐含的语义关系。
针对水利领域本体扩展中所遇到的实际问题描述,构造推理规则:

Rule1 说明如果x 与y 存在相关关系,而z 是y的子集,则认为x 与z 也存在相关关系。
Rule2 说明如果x 与y 等价,而y 与z 等价,则认为x 与z 也等价。
Rule3 说明如果x 与y 存在等价关系,而x 与z是相关的,那么认为y 与z 也存在相关关系。
2.2 语义相似度计算
语义相似度对于扩展查询中选择扩展词有重要作用。语义相似度越高就说明扩展词越符合用户的需求,查询结果就具有越高的查全率;文献[13-17]中提到了语义距离、节点深度、信息论等多个影响语义相似度的因素;为了解决水利领域本体的相似度计算的问题,本文综合考虑影响语义相似度的各个因素,提出水利领域语义相似度计算公式:
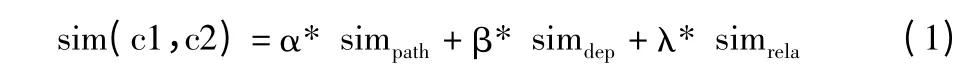
1)语义距离:语义距离是2 个概念在本体中路径的最短距离。定义概念c1 与c2 的最近公共祖先为lca(c1,c2),语义距离可表示为:
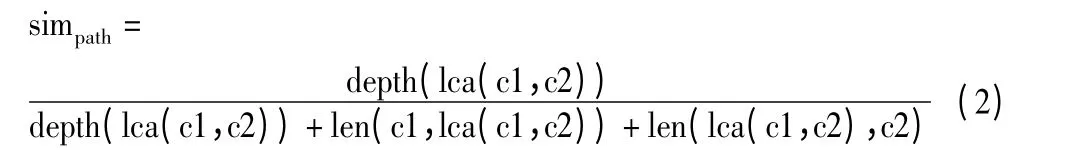
其中,depth(lca(c1,c2))表示最近公共祖先节点在本体中的层次,len(c1,c2)表示2 个概念在本体中的距离。
2)节点深度:概念与本体的根节点的最短路径称作概念的深度,由于本体中上层概念的含义相比于底层概念更为抽象,所以概念的相似度随着概念的深度差变大而变小。

其中lca(c1,c2)代表概念c1 与c2 与公共祖先距离的平均值。
3)语义相关度:表示概念之间的相关程度。概念具有子类越多,那么从信息论的角度来看,这个概念则表现得更为抽象,本文认为抽象的概念蕴含的信息与具体的概念相比更少,因此相似度计算时需要考虑概念的抽象程度。此外,根据水利领域本体的特征可知如果概念之间共享的信息越多那么概念越相似,概念之间共同的祖先节点可以认为是概念间共享信息的一种表现,因此概念的语义相关度可以表示为:
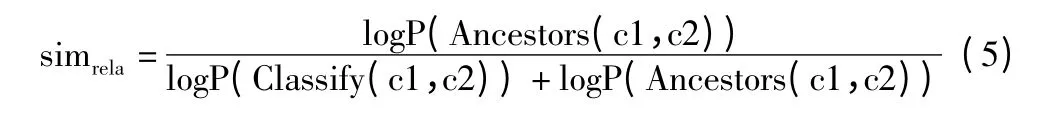
其中,Classify(c1,c2)描述概念c1 与c2 共享子类的信息量,Ancestors(c1,c2)用于描述概念c1 与c2 共享公共祖先的信息量。sim(c1,c2)中α +β +λ=1,α、β 与λ 等值设置具有一定的主观性,为了确保相似度计算的准确性,后续章节将采用专家经验与实验结合的方式进行参数设置,通常情况下语义相关度对语义相似度的影响最大,其次为语义距离,最后才是节点深度,即λ >α >β,相似度的值域为sim(c1,c2)∈(0,1)。
2.3 扩展词选择
本体推理能够发现隐含的语义关系,可以推出更多的关键词,提高查全率。但是本体推理单纯地对扩展词增加权值的方式,无法合理地对扩展词范围进行限制,导致推出的扩展词之间区分度不够,无法保证最终查询结果的准确性。本文结合本体推理与基于本体相似性计算2 种方式进行关键词的扩展,通过本体推理和相似性计算分别得到2 个扩展关键词的集合,如果简单地组合2 组扩展词作为查询表达式,会导致与查询词相关性比较低的词汇出现在查询表示中,导致相关不高的结果出现,降低查准率,因此需要设置一个扩展阈值,当扩展词的权值高于阈值时,则加入查询词列表中,关键词扩展流程如图1 所示。
2.4 搜索结果排序
对搜索关键词的扩展数量加以限制,可以保证较好的查准率与查全率。然而,在搜索结果中排名靠前的记录不一定就是最相关的记录,因为随着查询扩展词的增多,搜索结果中会出现很多噪音,如果把关键词的语义信息加入排序算法中,那么搜索结果将会按照语义相关性排序,从而使查询结果更符合用户的需求,提高查准率。

图1 关键词扩展流程
本文将改进Lucene 的搜索排序算法,把扩展关键词的语义信息加入排序中去,改进后的排序算法SimRank 可以表示为:
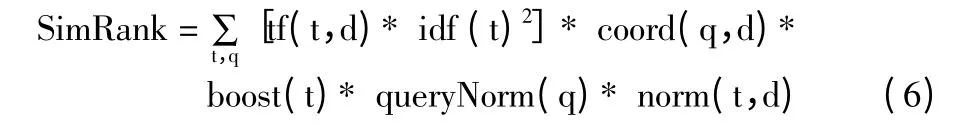
其中,t 表示Term(即所要查询的关键词),coord(q,d)表示文档中包含的检索关键词数量,queryNorm(q)表示每个查询的方差和,boost(t)表示添加了语义信息的词汇权值,tf(t,d)表示词频,idf(t)2表示逆向文件频率,norm(t,d)表示标准化因子。
boost(t)表示关键词权重,如果当前词是扩展而来的,赋予扩展词的权重值,否则赋值为默认的权重:

3 水利元数据分布式搜索
本文利用Hadoop 平台实现水利元数据的分布式语义检索。由于水利元数通常采用XML 文件进行定义与描述,需要在建立索引时解析整个XML 文件获取相应数据,但是如果在建立索引时直接采用Hadoop 的文件划分机制,将会把一个完整的XML 文件划分到不同的分片中,造成元数据解析错误,而且水利元数据的大小通常在几十kB 到几百kB 之间,是通常意义上的小文件,会产生HDFS 小文件问题,增加Namenode 负载降低处理效率,所以对Hadoop 中SequenceFile 的结构进行改进,利用SequenceFile 可以将多个小文件合并为一个大文件的功能,使水利元数据及相关文件能够合并存储在HDFS 中以及被MapReduce 切割为独立、完整的文件,然后利用MapReduce 并行地解析完整的水利元数据文件并建立索引,在此基础上提出一种分布式环境下基于本体的扩展查询方法。
3.1 元数据索引的并行创建算法
1)数据预处理。
首先使用Xpath 来标识这些关键数据项,利用XML 的解析工具,如SAX、dom4j、XQuery 等,可以获取Xpath 对应的数据信息。通过对异构类型的元数据,使用Xpath 配置文件标识出元数据中共性的内容,那么在建立索引过程中,可以利用配置文件来屏蔽异构数据之间的差异性。
其次是海量的水利元数据小文件的处理。在建立索引过程中,需要构建多个配置文件来屏蔽不同类型元数据之间的差异性,为保证MapReduce 对水利元数据相关文件切割后,能够形成一个个独立的文件,改进了SequenceFile 文件的key/value 结构,称为XSequenceFile,如图2 所示。
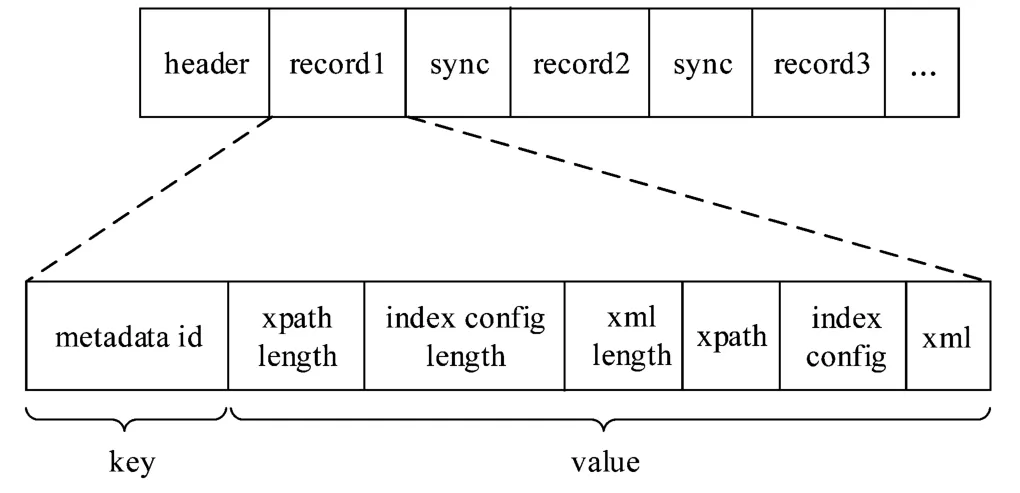
图2 处理元数据的XSequenceFile 结构
XSequenceFile 将水利元数据文件组合到一起,作为HDFS 存储的格式。对于海量、异构、小文件的水利元数据的解析需求,首先需要将用于屏蔽异构元数据差异性的Xpath、索引配置项(index config)存入XSequenceFile 中,且需要保证解析元数据之前,Xpath以及index config 文件就已经存在,因此把Xpath、XML、index config 合并为一个文件组合,放置于同一个record 中。metadata id 作为key 来标识当前处理的元数据,value 中分别记录数据与长度,通过长度可以计算出Xpath、index config 与XML 在record 中的偏移量,从而在读取XSequenceFile 可以还原出相应的文件。header 用于标识XSequenceFile 的文件信息,包括是否压缩、压缩方式、key/value 信息、以及sync的相关信息。sync 用于校验record 中的记录,如偏移量,当读取过程中发生错误时,sync 可以用于恢复数据。
2)索引的并行建立。
图3 展示了并行建立索引的过程:将HDFS 中的元数据及其相关的索引结果配置文件和xpath 以指定的结构写入XSequenceFile,Map 函数按照XSequecnceFile 中的key-value 格式取出数据,并且按照value 中定义的偏移量把xpath、索引配置项、XML 元数据读取出来,通过并行地运行SAX 算法提取出Xpath 对应的信息,建立倒排索引,并把索引记录对应的元数据类型index_type 作为key,把索引记录作为value 交由Reduce 函数进行处理,Reduce 函数通过统计相同的index_type,执行索引合并程序,并将合并后的索引写入HDFS 中。
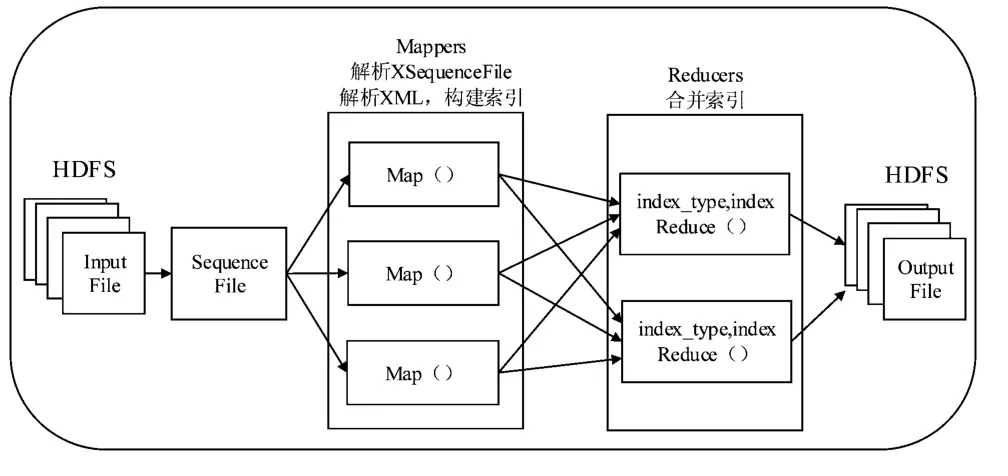
图3 水利元数据并行建立索引过程
3.2 分布式语义扩展查询
由于用户在向分布式集群发送查询请求时,系统无法事先知道索引文件存在哪个节点上,因此查询请求分发过程不能是随机分发或者指定节点进行查询请求的分发,所以在查询模型中设计了查询请求分发策略,从集群中遴选出一个节点,向该节点发送查询请求,并由该节点向其他节点转发查询请求,其他节点在本地处理查询请求后,将查询结果返回给遴选节点。遴选节点是出于并发访问下,保持各个节点之间的负载均衡,设计使用hash 函数来平衡各个节点的访问负载:
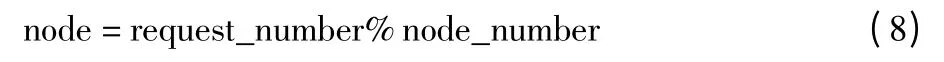
其中,request_number 是并发访问请求的数量,node_number 是分布式集群中节点的数量,通过hash 函数进行取模运算后,可以将查询请求平均地分发给不同的节点处理。
分布式环境下的语义扩展查询方法的详细步骤如算法1 所示,首先利用语义查询扩展算法计算出扩展关键词,将扩展关键词加入查询表达式中。随后利用哈希函数得出遴选节点,系统向遴选节点中发送查询请求,遴选节点负责向其他节点转发查询请求,如果其他节点中的数据块与遴选节点中的不同,则对当前节点中的索引文件进行搜索,并将搜索结果返回给遴选节点。遴选节点在接收到所有的搜索结果后,对搜索结果合并和去重,使用SimRank 排序算法对搜索结果排序,返回搜索结果给用户。
4 实验与分析
4.1 实验环境
实验中,对比集中式与分布式环境下的系统处理能力,实验环境配置如下:
1)集中式环境:CPU:AMD A8-7100 Raadeon R5四核1.80 GHz;内存:4.00 GB;硬盘:HGST HTS 725050A7E630,7200 转/min,500 GB;操作系统:Windows8。
算法1 并行语义查询算法

2)分布式环境:选择1 台Namenode 节点,3 台Datanode 节点:主节点CPU:英特尔单核2.60 GHz,主节点内存:1 G,从节点CPU:英特尔双核3.20 GHz,从节点内存:2 G;操作系统:Ubuntu 12.04,Hadoop:Hadoop 2.1.0,JDK 环境:jdk 1.7,开发IDE:My-Eclipse10。
4.2 实验数据设置
《水利公文主题词表》的主表中收录主题词1 994条,分为18 个范畴编排,附表收录了主题词570 条。通过运行自动化构建算法,将《水利公文主题词表》转译为OWL 语言描述的本体。
本实验采用调整权值模拟与10 位领域专家经验判断的相似性进行比较,通过选择实验得到最优组作为相似度计算模型的参数。从过往的实验结果可以得出,当α=0.45,β=0.35,λ=0.2 时,基于本体的相似度计算值与领域专家估算的值的误差值最小。因此可以设置相似度计算公式中的参数值为α=0.45,β=0.35,λ=0.2,所以基于本体的相似度计算公式可以描述为:

4.3 分布式语义搜索
本实验采用的元数据数据集,按照规模可以分为:10 万、30 万、50 万、100 万、300 万和500 万,数据集取自水利卫星数据共享平台流域机构、典型省级信息资源目录集成与服务系统开发项目的数据集以及第一次全国水利数据普查数据库。
1)索引的创建。
本实验设置1 个Namenode 节点,3 个Datanode节点,3 个map 任务与3 个reduce 任务的情况下,验证随着数据量的增加,对本地和并行方式下建立索引的效率影响,以及随着节点数量的增多,对并行方式下建立索引的效率影响。本地构建索引与并行方式构建索引性能对比实验结果如图4 所示。
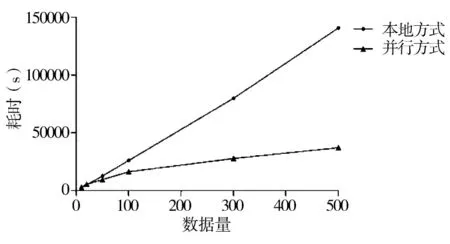
图4 本地与并行方式建立索引效率对比图
从图4 中可以发现,当数据量小的时候,本地方式的处理效率更高些,因为运行MapReduce 程序时会有一定开销,但当数据量到达5 000 时,并行处理方式的效率则开始高于本地的方式,而随着数据量增大,并行处理方式的优势更为明显。因此可以得知并行处理的效率在处理大数据量时具有一定的优势。
2)分布式语义扩展查询。
本实验模拟用户并发访问请求,对总的数据量在20 G 的总索引文件进行分布式搜索实验,实验设置1个Namenode 节点,3 个Datanode 节点,3 个map 任务与3 个reduce 任务的情况下,并发请求数分别设置为1 万、5 万、10 万、20 万、50 万、100 万,测试高并发访问请求,分析传统单机环境下与本文提出的查询模型下的查询效果对比,实验结果如图5 所示。

图5 查询效率对比图
从图5 可以看出,本文提出的方法在并发访问量增加的过程中,查询时间增加得不是很明显,能够应对较大的访问并发量。而在传统的集中式环境下,随着并发访问量的增加,查询时间也随之增大。实验对比表明了本文提出的方法,在应对大规模访问请求时,系统整体的处理时间没有出现特别大的波动。因为采用了hash 方法将访问请求平均分发到不同节点,使得系统能够保持负载均衡。
5 结束语
本文采用基于水利领域本体进行关键词扩展的方式来构建语义搜索,结合推理与计算本体间相似度的方式来扩展查询关键词,修改了Lucene 中的排序公式,将词汇的权值作为语义信息加入到搜索结果的排序中,使得搜索排序结构更符合用户的搜索意图,提高了查全率与查准率。与此同时,通过修改SequenceFile 的结构,将元数据的相关信息合并到SequenceFile 中,作为MapReduce 的输入,并行地解析XML 元数据与建立索引。解决了传统集中式环境下对水利元数据建立索引存在的性能瓶颈,并提出分布式环境下语义扩展查询的处理模型,解决了分布式环境下语义搜索的问题。但是本文主要考虑了关键词或者关键词的组合查询,而针对更复杂的查询,如范围查询等,考虑得并不是很充分,这也是下一步要解决的问题。
[1]水利部水利信息化工作领导小组办公室.2012 年度中国水利信息化发展报告[M].北京:中国水利水电出版社,2013.
[2]冯钧,唐志贤,朱跃龙,等.水利信息资源目录服务元数据定义研究[J].水利信息化,2011(S1):19-22.
[3]Guha R,McCool R,Miller E.Semantic search[C]// Proceedings of the 12th International Conference on WorldWide Web.ACM,2003:700-709.
[4]Yu Xuejun,Lv Jing.Keywords semantic extension in semantic search model[C]// International Conference on Computer,Networks and Communication Engineering (ICCNCE 2013).Atlantis Press,2013.
[5]Armentano M G,Godoy D,Campo M,et al.NLP-based faceted search:Experience in the development of a science and technology search engine[J].Expert Systems with Applications,2014,41(6):2886-2896.
[6]Tran T,Cimiano P,Rudolph S,et al.Ontology-based interpretation of keywords for semantic search[M]// The Semantic Web.Springer Berlin Heidelberg,2007:523-536.
[7]Qiu Yonggang,Frei H P.Concept based query expansion[C]// Proceedings of the 16th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,1993:160-169.
[8]Attar R,Fraenkel A S.Local feedback in full-text retrieval systems[J].Journal of the ACM (JACM),1977,24(3):397-417.
[9]Mena E,Illarramendi A,Kashyap V,et al.OBSERVER:An approach for query processing in global information systems based on interoperation across pre-existing ontologies[J].Distributed and Parallel Databases,2000,8(2):223-271.
[10]Khatchadourian S,Consens M P,Siméon J.Having a Chu-QL at XML on the Cloud[C]// A.Mendelzon International Workshop(AMW).2011.
[11]Shah B,Rao P R,Moon B,et al.A data parallel algorithm for XML DOM parsing[M]// Database and XML Technologies.Springer Berlin Heidelberg,2009:75-90.
[12]魏永山,张峰,陈欣,等.一种云计算环境下的XML 查询数据服务的优化方法[J].计算机工程与科学,2013,35(6):30-36.
[13]Rada R,Mili H,Bichnell E,et al.Development and application of a metricon semantic nets[J].IEEE Transactions on Systems,Man and Cybernetics,1989,9(1):17-30.
[14]Wu Zhibiao,Palmer M.Verb semantics and lexical selection[C]// Proceedings of the 32nd Annual Meeting of the Association for Computational Linguistics.1994:133-138.
[15]韩欣,樊永生,马春森,等.基于树状结构的语义相似度计算方法分析[J].微电子学与计算机,2012,29(5):38-41.
[16]Choi I,Kim M.Topic distillation using hierarchy concept tree[C]// Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.2003:371-372.
[17]曹叡,吴玲达.一种改进的领域本体语义相似度计算方法[J].微电子学与计算机,2014,31(8):109-114.
