基于Replication和LVS的MySQL分布式数据库研究
2015-11-02谈书才刘青青
谈书才 刘青青
基于Replication和LVS的MySQL分布式数据库研究
谈书才 刘青青
本文在对分布式数据库研究的基础上,提出了一种基于Replication和LVS的MySQL分布式数据库实现方案。该方案采用Replication技术实现两个数据库之间的双向数据同步,通过LVS和heartbeat实现负载均衡和故障切换,利用数据库合并技术实现故障恢复,从而构建出一个跨网段、可用性高、可自动恢复常见故障的分布式数据库系统。
随着互联网的高速发展,人们对计算机网络的依赖性也越来越高,小到日常生活,大到企业运营,计算机网络已经无处不在。与此同时,数据库技术日趋成熟,数据库应用已经普遍建立在计算机网络之上。因此,各种应用的需求对数据库的可用性和分布性提出了更高地要求。传统的集中式数据库因为通信开销大,单点故障导致可靠性不高,所以逐渐被地理上分布,不因单台数据库服务器而全部瘫痪的分布式数据库所代替。而在各类分布式数据库中MySQL由于其低成本及开源等特性被广大网站开发者所热爱。在TechTarget发起的2012年中国数据管理优先度调查中显示,有45.5% 的用户表示愿意迁至MySQL数据库平台。
基于Amoeba中间件的分布式数据库,集中地响应应用的请求,并将SQL请求发送到特定的数据库服务器上执行,从而实现了负载均衡、读写分离等功能。但是它只能实现同网段内的数据库服务器的分布式部署,无法跨越互联网的不同网段,并且它在下属数据库节点异常时,无法自动恢复,需要人工进行处理。
为了解决上述问题,本文提出一种基于Replication和LVS的MySQL分布式数据库实现方案。该方案采用Replication技术实现两个跨网段数据库之间的双向数据同步,通过LVS和heartbeat实现负载均衡和故障切换,利用数据库合并技术实现故障恢复,从而构建出一个跨网段、可用性高、可自动恢复常见故障的分布式数据库系统。
Replication技术
MySQL的复制(Replication)技术是一种能够让运行在不同计算机上的两个或者更多个MySQL服务器保持同步变化的机制,目前支持“主-从”复制关系,只有一台主控系统(可读/可写),所有的数据修改操作都要在这台系统上进行;有一台或多台从属系统(只读),它们有着与主控系统完全一样的数据,主控系统上的数据变化在经过一个短暂的延时后也将发生在它们身上,并且不要求主控和从属系统使用同一种操作系统。
Replication是一种异步的复制,从一个MySQL instace(称之为Master)复制到另一个MySQL instance(称之Slave)。实现整个复制操作主要是由三个线程完成的,其中两个线程在Slave(SQL线程和I/0线程),另外一个线程(I/0线程)在Master上。
MySQL数据库系统采用异步复制来保持数据的一致性,其复制过程可简述如下:主服务器(Master)数据更新之后,通知从服务器(Slave),从服务器的I/O进程连接到主服务器(Master),并请求指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;主服务器接收到从服务器I/O进程的请求后,其I/O进程根据请求信息读取指定日志的指定位置之后的日志信息,并将其返回给从服务器的I/O进程。返回信息中除了日志所包含的信息之外,还包括Master端的bin-log文件的名称以及binlog的位置;从服务器的I/O进程接收到信息后,将接收到的日志内容添加到Slave端的relay-log文件的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中;从服务器的sql进程检测到reday-log中新增加了内容后,会马上解析relay-log的内容并执行,从而达到服务器之间的数据同步。
LVS
LVS的英文全称是Linux Virtual Server,即Linux虚拟服务器。它是章文嵩博士主持的一个开源项目。
LVS主要用于多服务器的负载均衡。它可以实现高性能,高可用的服务器集群技术。它廉价,可把许多低性能的服务器组合在一起形成一个超级服务器。它易用,配置非常简单,且有多种负载均衡的算法。它稳定可靠,即使在集群的服务器中某台服务器无法正常工作,也不影响整体效果。另外可扩展性也非常好。
LVS工作在网络层,相对于其它负载均衡的解决办法,比如应用层负载的调度等,它的效率更高。LVS的通过控制IP来实现负载均衡。IPVS是其具体的实现模块。IPVS的主要作用:安装在Director Server上面,在Director Server虚拟一个对外访问的IP(VIP)。用户访问VIP,到达Director Server,Director Server根据一定的规则选择一个Real Server,处理完成后然后返回给客户端数据。这些步骤产生了一些具体的实现问题,比如如何选择具体的Real Server,Real Server如何返回给客户端数据等等。IPVS为此有三种机制:VS/NAT(Virtual Server via Network Address Translation),即网络地址转换技术实现虚拟服务器;VS/TUN(Virtual Server via IP Tunneling),即IP隧道技术实现虚拟服务器;VS/DR(Virtual Server via Direct Routing),即用直接路由技术实现虚拟服务器。
基于Replication和LVS的MySQL分布式数据库实现
本文基于上述Replication和LVS技术提出了一种MySQL分布式数据库系统的实现方案,如图1所示。
数据节点1(DB1)和数据节点2(DB2)分别部署在两个不同网段,通过广域网相连。DB1和DB2之间通过Replication技术实现双向复制。虚拟服务器1(LVS1)和虚拟服务器2(LVS2)同样部署在两个不同网段,通过广域网相连。每个虚拟服务器通过IP隧道技术与两个数据节点建立虚拟连接,当一个数据节点故障时,自动切换到另一个数据节点,从而提高数据的可用性。用户1(USER1)部署在DB1所属网络NETWORK1,通过LVS1优先访问DB1;用户2(USER2)部署在DB2所属网络NETWORK2,通过LVS2优先访问DB2,就近使用本地数据节点,从而提高响应速度。
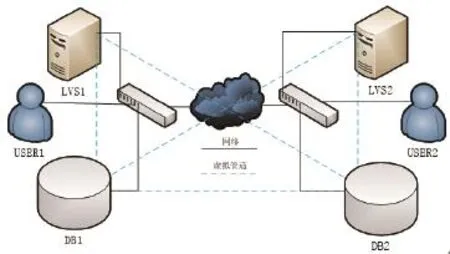
图1 分布式数据库系统示意图
Replication技术实现
首先配置DB1为Master,DB2为Slave,DB2复制DB1的数据。然后配置DB2为Master,DB1为Slave,DB1复制DB2的数据。DB1配置为只写入奇数行数据,DB2配置为只写入偶数行数据。配置完成后,无论DB1还是DB2,任意一侧数据发生变动,都能通过Replication技术复制到对方,从而保证数据的一致性,实现两个跨网段数据库之间的双向数据同步。
LVS技术实现
本方案为达到负载均衡和故障切换的目的,采用了LVS中的IP隧道技术(VS/TUN)方式来实现虚拟服务器。
DB1设置两个IP地址(DB1IP1/NETWORK1和DB1IP2/NETWORK1),创建两个隧道(TUN1/ NETWORK1和TUN2/NETWORK2)分别为两个虚拟服务器对外隧道IP地址。DB2设置两个IP地址(DB2IP1/ NETWORK2和DB2IP2/NETWORK2),创建两个隧道(TUN1/NETWORK1和TUN2/NETWORK2)分别为两个虚拟服务器对外隧道IP地址。
LVS1创建一个隧道(TUN1/NETWORK1),通过加权负载均衡算法与DB1IP1和DB2IP1相连,给予同网段DB1IP1较高的权重值,保证优先使用同网段的数据库,提高响应速度。LVS2创建一个隧道(TUN2/ NETWORK2),通过加权负载均衡算法与DB1IP1和DB2IP1相连,给予同网段DB2IP1较高的权重值,保证优先使用同网段的数据库,提高响应速度。LVS1和LVS2中都通过heartbeat检测与两个数据库之间的数据访问连接状态,当一个数据库出现异常时,就会自动切换到另一个隧道连接的数据库,从而实现负载均衡和故障切换。
数据库合并技术实现
本方案采用基于SHELL脚本的数据库合并技术实现对两个数据库的监控及故障恢复。脚本处理流程如下:
(1)启动数据库后台故障检测守护脚本进程;
(2)设置两个数据库的控制IP地址分别为DB1IP2和DB2IP2,设置两个数据库的LVS访问IP地址为DB1IP1和DB2IP1;
(3)根据预先设置的故障检测时间点(一般设置为用户对数据库访问较少的时间点),对两个数据库的连接状态进行检测,未到检测时间点守护脚本置于休眠状态,到达检测时间点唤醒;
(4)检测守护脚本所在网络和两个数据库的可通性,如果不通,写日志报警,守护脚本置于休眠状态,等待下一个检测时间点唤醒(这种情况下物理网络不通,需要人工干预,保证网络畅通,否则无法获取数据库状态);
(5)检测守护脚本所在网络和两个数据库的数据库可访问性,如果不可访问,写日志报警,守护脚本置于休眠状态,等待下一个检测时间点唤醒(这种情况下数据库不可访问,需要人工干预,保证单个节点数据库运行正常,否则无法获取数据库的同步状态);
(6)检测两个数据库系统之间的同步状态,如果正常同步,写入正常同步日志,守护脚本置于休眠状态,等待下一个检测时间点唤醒;如果同步故障,写入同步故障日志并执行后续步骤;
(7)通过控制IP地址DB1IP2和DB2IP2分别关闭两个数据库对LVS的访问IP地址DB1IP1和DB2IP1,停止两个数据库之间的同步线程;
(8)通过控制IP地址DB1IP2和DB2IP2将数据库DB2中的数据合并到数据库DB1中,然后把数据库DB1中合并后的数据复制到数据库DB2中;
(9)重新配置数据库DB1和数据库DB2之间的双向同步关系;
(10)重新设置两个数据库对外访问的IP地址DB1IP1和DB2IP1;
(11)写入同步成功日志,守护脚本置于休眠状态,等待下一个检测时间点唤醒。
结语
近年来,数据库技术已成为广大学者和专家的研究热点之一,特别是分布式数据库技术。在国外,该领域已被研究多年,提出了各种成熟的实现方案,但在国内还处于研究阶段。本文以应用广泛的Replication技术实现两个跨网段数据库之间的双向数据同步,采用LVS和heartbeat实现负载均衡和故障切换,利用数据库合并技术实现故障恢复。但在研究过程中,也发现了一些新的问题:比如在网络通畅但数据库崩溃情况下,如何自动恢复数据库。这将是将来有待解决的问题。
10.3969/j.issn.1001-8972.2015.10.021