网络影响力预知模型:一种大数据下高校舆情监测与预警机制
2015-10-28柳向东曹雨婷李利梅
柳向东曹雨婷李利梅
(1.暨南大学经济学院统计学系,广东广州 510632;2.暨南大学外国语学院,广东广州 510632;3.深圳大学校长办公室,广东深圳 518060)
网络影响力预知模型:一种大数据下高校舆情监测与预警机制
柳向东1,曹雨婷2,李利梅3
(1.暨南大学经济学院统计学系,广东广州 510632;2.暨南大学外国语学院,广东广州 510632;3.深圳大学校长办公室,广东深圳 518060)
互联网对高校大学生的思想传播模式尤其对舆情的传播产生了巨大影响。对于这样的新形势,建立和健全高校大学生舆情监测与预警机制对于及时了解大学生的思想动态,分析和解决思想问题,为大学生树立正确“三观”具有重要的意义。本文建立了一种监测大学生网络舆情的模型——基于连续时间马尔科夫过程的用户影响力预知模型,通过该模型找到高校社交媒体中最具影响力的用户,锁定最具影响力的用户群(关键人物),采用基于机器学习的自动文本分类方法,对该群体进行分类,主要分为三类:积极型关键人物、中立型关键人物、消极型关键人物。最后针对不同类型的关键人物采取不同的措施以达到对高校大学生社交网络舆情发展的监测与预警。
大数据;大学生网络舆情;监测预警;马尔科夫过程;文本分类
18世纪法国首先提出了“公众意见”(opinion public)一词,直到20世纪初,舆情的概念逐步为多个国家使用,舆情理论、舆情调查学经历了萌芽期、成长期、成熟期的演变,成为针对社会当前运行状态和未来发展进行预测的重要依据,并据此适时地调整政策以确保社会持续的稳定运行。网络舆情是指在各种事件的刺激下,人们通过互联网手段表达的对该事件的所有认知、态度、情感和行为倾向的集合。网络舆情涉及的问题和事件包罗万象,表达和传播的途径更是千变万化。
现今网络世界越来越成为高校大学生精神生活中的一个重要方面。互联网带动了大学生人际交往方面发生巨大变化,产生了一种全新的人际关系模式。在社交网络(例如微博、微信、贴吧等)上发帖、转发、评论及参加网络调查、投票等方式已经成为高校大学生社会生活中极为常见并且相当重要的一部分。这种全新的模式对高校大学生的社会适应能力和人际交往能力的培养以及世界观、人生观、价值观、道德观的形成都产生了强烈的影响。在这种新的模式里,各种社会思潮、宗教文化不断涌入,不断影响着大学生的思想。大学生舆情是指在高校围绕某些事态的发生发展和变化,大学生在网络上表达和传播对国家管理者产生和持有的社会政治态度。由于舆情的本质是社会群体和政府管理者之间关系的反映,并且高校大学生是相对高素质、高文化并且思想活跃的群体,因此研究高校网络舆情,建立和健全高校大学生舆情监测和预警机制可以了解大学生的思想动态,分析和解决学生的思想问题,优化高校思想政治教育机制,进一步可以促进社会稳定和发展。
对高校网络舆情的监测与预警可以从挖掘网络舆情传播关键人物入手。挖掘关键人物的意义在于:(1)找出关键人物进行密切关注,便于快速及时发现问题苗头,有效控制负面虚假信息的大肆传播;(2)深入了解高校网络舆情的传播机制,便于有效传播健康正面的消息。此处的关键人物可以有以下两个定义:第一,可以简单将那些拥有最多朋友或者追随者的用户定义为最具影响力的用户。最典型的这一类用户就是高校的网络红人(贴吧)、知名博主(微博)或者热门公众号主编(微信),他们通常拥有极大比例的粉丝或者追随者。第二,也可以针对社交网络中的信息传播情况来找出最具有影响力的用户。例如,如果一个用户的信息经常被其他用户转发,就可以认为这个用户具有比较高的影响力。
一、最具影响力用户的挖掘方法
面对社交媒体在高校发展的新形势,建立大学生网络舆情的预警机制对于控制网络舆情在高校的传播有着非常重大的意义,而其中挖掘最具影响力用户是最关键的一个步骤。找到在高校社交媒体上最具影响力的关键人物,通过关键人物发表的一些言论来判断出该用户的思想倾向及其对周围人的倾向影响,从而能够及时针对舆情言论采取不同的应对措施,实现对高校社交舆情的控制。对于最具影响力的用户的挖掘方法被分为两种,一种是静态挖掘,另一种是动态挖掘。
静态方法将注意力集中在社交网络的静态属性和特征,通常假设当前的社交网络是稳定的,然后根据该社交网络的属性来定义用户的影响力,通过其影响力的大小来挖掘出最具影响力的用户。
度[1-2]是对于网络上的某一节点的邻接节点的数量。对于社交网络,度是最简单的定义静态影响力的方法。对于不同的社交网络,度的定义方式不同。对于人人网这类的社交媒体,根据朋友关系得到的社交网络上的度则是某个用户在网络中的好友数量;对于贴吧这类的社交网络,根据回复关系得到的度是某个用户在网络中回复其他用户的数量;对于微博这类的社交网络,根据传播关系得到的度是某个用户所转发的其他用户的总数,另一方面根据提及关系得到的度则是某个用户在网络所提及的用户的总数。
接近性核心性其定义的公示如下:
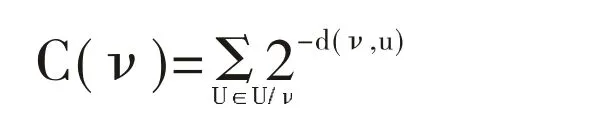
这里指的是网络中所有的节点,而d指的是两个节点之间的距离。接近性核心性描述了一个节点在网络中到其他所有节点的距离。离所有其他节点越近的节点,其影响力越大。
中介性核心性
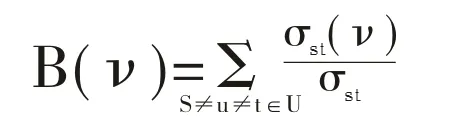
其中,σst表示从节点s到t的最短路径的数量,而σst(ν)表示从节点s到t并且经过ν的最短路径的数量。
PageRank算法[3]是Stanford大学研究人员开发的Google搜索引擎的页面质量评价算法,沿用此算法也可对社交网络中最具影响力用户进行挖掘。其定义如下:

其中,neighbor(ν)指代那些在网络中直接指向ν的用户,L(u)指的是从u指出的链接数量,而N指的是网络中的用户数。
以上四种静态挖掘方法都能够找出高校社交网络中最具影响力用户,但是考虑到现代网络的多变性,而静态挖掘的前提是假设社交网络的稳定性,所以通过静态方法找到的结果是基于某个时点的,是片面的。
动态挖掘方法不仅基于高校社交媒体本身的属性,而且考虑到网络的多变性,根据其实时变化来及时调整运算的目标,实现在时间轴上的动态变化。
二、基于连续时间马尔科夫过程的用户影响力预知模型
针对静态挖掘存在的种种不足,本文参考李涛教授提到的动态挖掘用户影响力的方法[4],探寻更加适合实际情况的研究方法。
为了挖掘高校社交媒体中最具影响力用户,首先要建立信息扩散模型。常用到的信息扩散模型主要包括独立级联模型及线性阈值模型。这两种传统的信息扩散模型都认为网络中的每一个节点都有一个属性标明它是否已经被激活,那些被激活的节点又会通过它们在社交网络上的边将信息扩散给其他的节点,这样信息就得到了传播与扩散。
以上两种模型存在自身的缺点,即假设社交媒体网络的稳定性,致力于计算静态的扩散概率,为了更贴切实际社交网络情况,基于连续时间马尔科夫过程的信息扩散模型被提出。该模型动态地展现了信息传播的概率,能更好地模拟现实世界中信息的扩散情况。
(一)马尔科夫过程
假设X(t)代表了一个t时间上针对某一信息的时间影响力社交网络的状态。它有在时间t上发表或提及该信息的所有用户。X=X(t),t≥0则构成了一个连续的马尔科夫过程[5]。在这个马尔科夫过程中,一个用户提及该信息的概率依赖于该信息在历史上传播的情况,而这个概率实际上仅仅依赖于在该用户提及之前其他提及该信息的用户。这种属性便是马尔科夫属性,其公式表示如下:

其中,Pij是时间t内从用户i到用户j的传递概率,即i为当前讨论该信息用户,j为下一个将要讨论该信息的用户。x(μ)表示先于时间点γ的主题传播的历史。假定传播概率Pij并不依赖于整个信息传播过程中时间的真正起始值,那基于连续时间的马尔科夫过程的影响力阈值模型就是时间其次的,其公式表示如下:

(二)基于马尔科夫过程的用户影响力定义
给定一个时间窗口t,为了描述用户i在该时间点上对于一则信息的扩散能力,需要估计该用户i到其他用户的传递概率(扩散概率),该概率能用于最终预测用户i的影响力。对于用户i,其在时间窗口t上的最终推广数量可以定义如下:

其中,ni表示用户在时间窗口t中可能出现的次数,该参数可以通过t线性递增估计的办法得到,同时可以根据用户i在历史上不同时间出现的次数使用回归模型计算得到。这里,本文选择首先计算传递速率矩阵Q,然后通过Q来间接得到P(t)。
传递速率矩阵Q又被称为连续时间马尔科夫过程的无穷小生成元。它的定义为时间t无限接近于0时P(t)的导数,其公式如下:
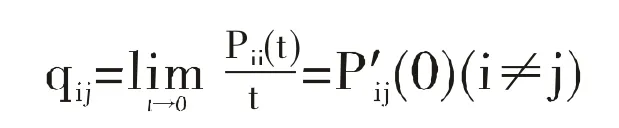
在Q中,每一个条目qij都指代将一个主题从用户传递到用户j的速率。Q的每一行的和都是0,每一行均满足以下条件:

其中,qij反映了从用户i传递到用户j的传递概率的变化。另一方面,qi指代了用户传递到任何其他用户的速率。可见,是计算其他参数的基础,为计算qi,假定用户i传播一则信息到其他用户的时间服从指数分布,该指数分布的速率参数正是qi[2]。故服从该指数分布的随机变量Ti的期望公式表示如下:

根据连续时间马尔科夫过程的理论,用户i传递到用户j的速率可以表示如下:

其中,m指代历史上从用户i传递到用户j的主题的数量,而tmij表示第m个主题从用户i传递到用户j所用时间。
(四)传递概率矩阵的计算
在计算到Q矩阵后,传递概率矩阵P(t)便可得到。根据柯尔莫高罗夫向后方程:

通过代数变换,以上的公式可以转化为如下的矩阵形式:
3.加强消毒。球虫卵(囊)对大部分消毒剂均有耐受性,对空鸡舍最好选用火焰消毒法,用具可用热水、热蒸汽烫或3%~5%的热碱水洗。
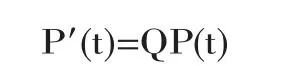
而这一方程的一般解法是由如下公式给出的:

由于是一个不可约的随机矩阵,我们可以使用泰勒扩展来近似它。所以可以用如下公式来估计:
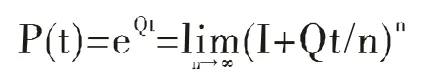
我们将(I+Qt/n)的指数升至一个足够大的n,得到P(t)矩阵后,我们便可用于计算所有用户的影响力了。根据他们影响力的排序,我们最终可获得最具影响力的用户,本文称之为关键人物。
三、最具影响力用户群分类
基于连续时间马尔科夫过程的用户影响力预知模型得出的关键人物,然后通过该群体在社交网络上发表的一些言论,对于信息或主题的一些评论来将其进行分类。本文采用基于机器学习的自动文本分类方法。
(一)基于机器学习的自动文本分类
基于机器学习[6]的自动文本分类是一种典型的有指导的机器学习问题,这可以定义为:根据一些已分配好类标签(这些类标签预先定义好)的训练文本集合来对新文本分配类标签。一般来说,文本分类主要由以下几个步骤完成:
1.建立数据集
这一步主要是搜集文本,并进行预处理,包括处理乱码、非文本内容等;机器内码转换;抽取词干及去停用词;删除无效文本;按类型集进行人工分类;按一定比例随机划分训练集和测试集。
2.建立文本表示模型
即选用什么样的语言要素(或者说文本特征)和用什么样的数学模型组织这些语言要素来表示文本。目前的文本分类方法和系统大多以词或词组作为表征文本语义的语言要素;表示模型主要有布尔模型和向量空间模型。
3.文本特征选择
即选择尽可能少而准确且与文本主题概念密切相关的文本特征进行文本分类。
4.机器学习
在训练集上进行机器学习,确定分类器的各个参数,建立分类器。机器学习主要依据文本的内容。
5.测试
用分类器对测试集进行分类,得到机器分类的结果。测试有封闭测试和开放测试。封闭测试时,测试集是训练集的一部分;开放测试时,测试集与训练集是服从同一分布、相互独立的两个数据集。封闭测试不具有可比性,文本分类中主要采用开放测试。
6.性能评价
采用一定的评价指标,对机器分类的结果进行评价。不符合要求时,需要返回到前面的某一步骤,调整参数,重新再做。目前使用较多的分类性能评价指标为查全率和查准率,这是来源于信息检索中的两个术语。目前最常使用的文本分类算法有:kNN分类算法、朴素贝叶斯分类算法、支持向量机、神经网络、最大熵等。
(二)用户群分类
根据以上的方法,将第二节所得到的关键人物进行分类,分类流程如图1
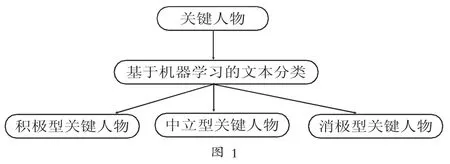
根据以上文本分类方法可以将最近一段时间内在高校大学生之间传播的舆情思想倾向进行定义和分类,分为“积极”、“中立”和“消极”三类。对于挖掘出的关键人物,对其最近一段时间内涉及到的相关舆情思想倾向类型进行统计,选择占比例最大的类型对其进行定义,可以分为“积极型关键人物”、“中立型关键人物”和“消极型关键人物”。例如,某个关键人物A近期参与发布和转发了100条舆情相关言论,若其中60条被定义为具有“积极”倾向,则该关键人物被定义为“积极型关键人物”。
对于“积极型关键人物”,高校思政教育者可对其进行鼓励,鼓励其继续对大学生积极舆论做出引导;对于“中立型关键人物”,则可以对其进行引导,引导其向“积极型关键人物”发展;而对于“消极型关键人物”,高校思政教育者则需要重点关注其行为,并在适当的时候与其沟通,尽量转变其思想。
四、结语
监测和预警不是目的,而是为了解决问题,防范危机或者风险的发生。大学生舆情是高校学生思想动态变化的晴雨表,通过互联网社交媒体表现得淋漓尽致。通过分析舆情,及时发现问题,解决矛盾,有利于促进高校和谐和社会和谐。高校德育工作者在采取上述监测和预警方法之外还应做到以下几点:(1)建立平等的对话机制。这对于融洽教育者与被教育者的关系,减少不必要的矛盾冲突,把问题消解在初级阶段具有不可低估的作用。(2)建立危机干预机制。大学生社会经验不足,生活阅历浅,缺乏全面深入辩证的思考能力,常常以偏概全,形成偏激的观点或思想。必须加强对网络舆情的监测,及时发现集群行为的苗头,及时进行危机干预。(3)解决思想问题与解决实际问题相结合。在网络舆情监测的过程中应当发现学生最关心、关系最密切的实际问题,急学生之所急,想学生之所想,把解决思想问题与实践问题结合在一起。
[1]K.Saito,M.Kimura,K.Ohara,and H.Motoda.Efficient estimation of cumulative influence for multiple activation information diffusion model with continuous time delay[J].In PRACAI 2010:Trends in Artificial Intelligence,Springer,2010,6230:244-255.
[2]肖宇,许炜,张晨,何丹丹.社交网络中用户区域影响力评估算法研究[J].微电子学与计算机,2012,29(7):58-63.
[3]X.Song,Y.Chi,K.Hino,and B.L.Tseng.Information flow modeling based on diffusion rate for prediction and ranking[J].In Procedings of the 16th international conference on World Wide Web,ACM,2007,25:191-200.
[4]李涛等.数据挖掘的应用与实践——大数据时代的案例分析[M].厦门:厦门大学出版社,2013.216-229.
[5]W.J.Anderson.Continuous-timeMarkovchains:An applications-oriented approach[M].Springer-Verlag New York,1991,volume 7.
[6]SebastianiF.Machinelearninginautomatedtext categorization[J].ACM Computing Survey,2002,34(1):1-47.
【责任编辑:周琍】
Predicting Model in Network Impact:a Monitoring and Warning System for Public Opinion in Universities under Big Data Framework
Liu Xiangdong1,Cao Yuting2,Li Limei3
(1.Department of Statistics,School of Economics,Jinan University,Guangzhou,Guangdong,510632;2.School of Foreign Languages,Jinan University,Guangzhou,Guangdong,510632;3.Office of the President,Shenzhen University,Shenzhen,Guangdong,518060)
The Internet has great impact on the dissemination of ideas,and in particular public opinion,among college students.Under these new circumstances,it is of great significance to build up and gradually improve a monitoring and warning system for public opinion in universities,which will enable us to know how the students think,and address relevant issues in order to help them to establish the correct"three-values".This paper proposes a monitoring system for college student online public opinion,a predicting model of user influence based on the continuous time Markov process,through which we will find the most influential users(key figures)the social network of college students.With an automatic text classification method based on machine learning,the key figures are mainly classified into three categories:positive key figures,neutral key figures,and negative key figures.Finally,the paper proposes some measures in accordance with different types of key figures to promote the development of social networking service for college students.
big data;Internet public opinion;monitoring and warning;Markov process;text categorization
G 647
A
1000-260X(2015)04
2015-03-23
教育部人文社会科学研究项目“基于市道轮换框架下带levy跳的高频数据的波动率研究”(14YJAZH052);中央高校基本科研业务费专项资金“PMCMC算法在市道轮换框架下利率结构模型中的应用”;深圳大学科研项目“大数据环境下社会舆情分析、监测与预警研究——基于特大城市深圳市的研究”(W201402)
柳向东,理学博士,暨南大学副教授,主要从事概率统计在经济金融领域的研究;曹雨婷,暨南大学外国语学院、经济学院双学位在读生;李利梅,深圳大学高级统计师,从事高校统计研究。
