基于MapReduce的频繁闭项集挖掘算法改进
2015-10-18付婷婷杨世平贵州大学计算机科学与技术学院贵州贵阳550025贵州大学明德学院贵州贵阳550004
付婷婷,杨世平,2(.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州大学 明德学院,贵州 贵阳 550004)
基于MapReduce的频繁闭项集挖掘算法改进
付婷婷1,杨世平1,2
(1.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州大学 明德学院,贵州 贵阳 550004)
挖掘频繁闭项集(CFI)在许多实际应用中起着重要的作用。传统的数据挖掘算法中常用FP增长算法和Apriori算法来挖掘频繁项集。然而,内存需求和计算成本成为CFI挖掘算法的瓶颈,尤其是在从大型数据集中挖掘频繁闭项集时,是一个重要和具有挑战性的问题。针对上述问题,提出一种基于云计算的MapReduce框架的并行AFOPT-close算法,使MapReduce可广泛地用于处理大型数据。此外,用于检查频繁项集是否为完全闭的有效并行算法也要求MapReduce平台进一步完善其性能。
MapReduce;频繁闭项集;FP增长算法
0 引言
频繁闭项集挖掘(Closed Frequent Itemset,CFI)在1999年由 Pasquier等人提出[1]。作为一种代替传统频繁项集挖掘(Frequent Itemset Mining,FIM)的新算法,CFI挖掘的优点在于在相同的频繁项集挖掘效率下大大降低了冗余规则并且增加了挖掘的效率和有效性。自CFI出现以来一直被广泛地研究,现有的CFI挖掘算法可分为两类:候选项集生成和检测方法[1]和模式增长方式[2-4]。
这些算法在处理小数据集或者支持度阈值较高时有良好的性能,但是当处理大数据集或者支持度阈值变小时内存运行开销将大幅度增加。一些早期的工作重点在于使用PC集群运行算法来加快挖掘速度,这样可以提高挖掘性能,但是也对诸如负载平衡、数据分区、通信成本最小化、因通信节点失效引起的错误等问题提出了新的挑战。
为了克服上述缺点,设计了MapReduce框架来支持云计算分布式计算的计算模式,对于大型数据集而言这是一个进行并行数据挖掘的有效平台。为了能更好地利用MapReduce在CFI挖掘中的优势,本文基于 MapReduce设计并实现了一个并行算法[4],这种算法是一种类似于FP增长算法的分治算法,能够有效地挖掘频繁闭项集。此外,也提出了一种检查一个频繁项集是否是完全闭的有效并行化方法,该方法能够过滤掉冗余的频繁项集。
1 频繁项集挖掘改进算法
在现有的研究中[3,5]已经设计出能够在内存共享情况下的多线程的FP增长算法,但当面临大规模数据集时这些方法将遇到内存需求严重不足的问题。一些研究工作也致力于解决更多细节问题,如通信开销最小化,内存的利用率最大化等[6-8]。例如WHANG K Y等人提出了一种在无共享环境下FP增长算法并行执行的方法,该算法可以实现良好的可扩展性,但是也存在同样的问题。随着云计算的发展,MapReduce平台能够对存储在大型计算机集群上的庞大数据进行分布式处理,具有良好的可扩展性和鲁棒容错性。因此提出了许多基于MapReduce的频繁项集挖掘改进算法。例如李浩源等人基于 MapReduce提出了一种并行的FP增长算法 PFP[9],该算法将整个挖掘任务分割成若干独立的并行子任务,并实现了拟线性加速比。除了可扩展性,PFP还让设计基于MapReduce的模式增长方式成为可能。在以前的研究中,也有对基于MapReduce的闭频繁项集算法的相关讨论和实现[10],主要通过以下 4个步骤来完成该算法,其中3个步骤是MapReduce操作。
(1)并行计算。统计数据库中每个项目的支持度。
(2)构建全局的F-List(链式数据结构)。把项目按出现频率递减的顺序分类并排除支持度小于最小支持度阈值的项目(用ξ表示)。
(3)并行挖掘频繁闭项集。并行挖掘局部频繁闭项集。
(4)并行过滤冗余项集。过滤局部闭而非全局闭的频繁项集。
通过上面4个步骤,能够准确地挖掘频繁闭项集。如图1中的一个简单例子,左边部分是原始事务表,右边部分给出通过步骤(1)~(4)挖掘得到的CFI,其中 ξ= 3。右边部分每个项集的最后一项为支持度阈值。显然,这存在一些局部闭而非全局闭的冗余项集,例如 {fm 4},{f p c 3},{f p 3}。
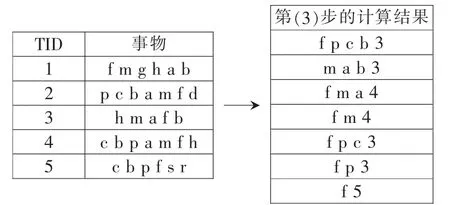
图1 源数据表和对其挖掘得到的CFI
在第(4)步中使用了并行的方法来过滤冗余项集。如图2所示,首先,每个 mapper函数从 CFI中读入一个项集,然后输出n次,n为项集的长度,Key为在项集中出现的项目。然后,每个reducer函数接收相应的值并且将项集按他们的长度递减分类,这样做是为了避免超集的检测,接下来并行地过滤冗余项集。最后,该项集的Key为最终保存的项。这种方法虽然可行,但是也导致了严重的通信开销和计算成本。以频繁项集{f p c b 3}为例,3为该项集的支持度阈值。该方法需要发送这个项集4次:分别是{f:f p c b 3}、{p:f p c b 3}、{c:f p c b 3}、{b:f p c b 3}。显然,这4个项集将会按不同的Key值被发送到reducer函数4次。如果ξ足够小,将可能有许多很长的频繁项集被反复地发送到 reducer函数。因此,这种方法的总体开销会非常高。为了解决这个问题,本文提出了一种高效的并行CFI挖掘算法,该算法也采用了一种新颖的冗余项集过滤方法来降低通信开销和计算成本。
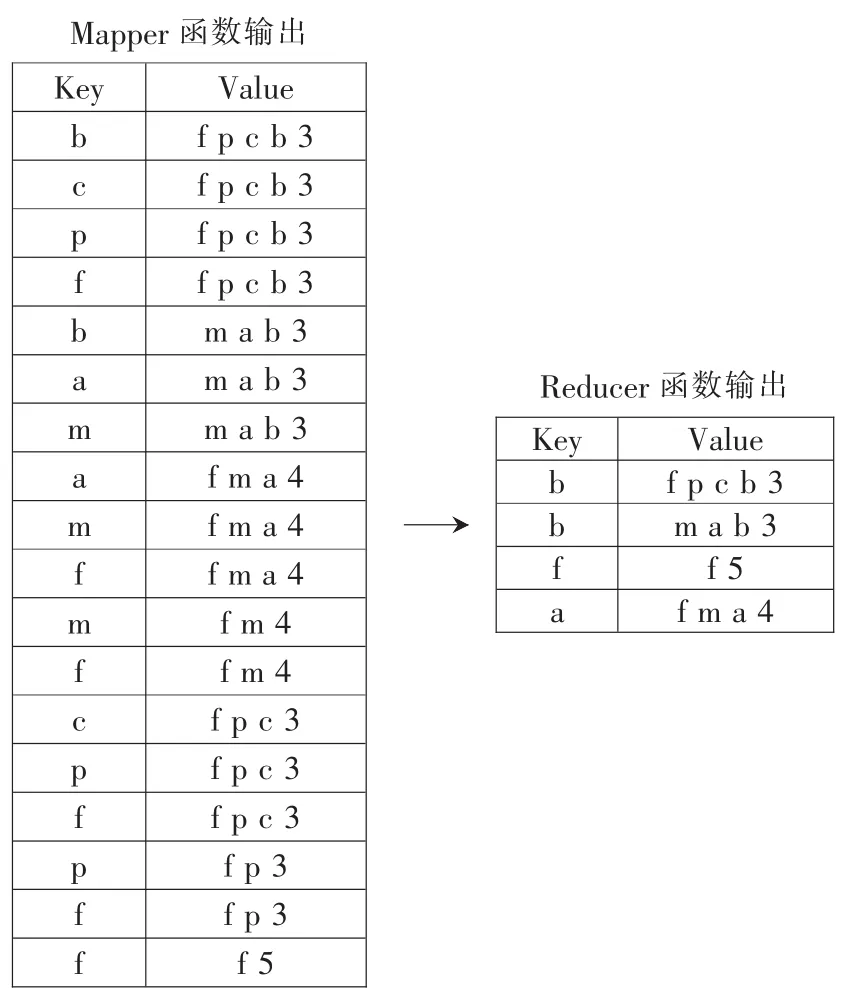
图2 冗余项集过滤
2 并行AFOPT-c l o s e算法
2.1 算法的定义
在本节中,提出了一种有效的冗余项集过滤方法,即并行AFOPT-close算法。如上所述,直接基于MapReduce采用并行化的方法挖掘频繁闭项集会导致一些项集可能局部闭而非全局闭的问题。在本节中,将对局部频繁闭项集和全局频繁闭项集分别进行定义。
定义1局部频繁闭项集
如果频繁项集X在步骤(3)中的 reducer中是闭的,那么频繁项集X为局部频繁闭项集,用L表示局部项集。
定义2全局频繁闭项集
如果频繁项集X对于所有局部频繁闭项集都是闭的,那么频繁项集X为全局频繁闭项集。用G表示全局项集。
性质:假设存在 X∈L,如果 X对于所有的项集{Y| Y∈L and supp(X)=supp(Y)}都是闭的,那么X∈G。
定义3冗余项集
当且仅当频繁项集X∈L且X∉G,那么频繁项集X为冗余项集,用R表示冗余。
2.2 高效冗余项集过滤
在现有的研究中,提出了一种基本方法来过滤冗余项集,该方法因计算成本和通信开销太高而很费时。本文基于2.1节中的定义提出了一种新的方法来解决这个问题。当然,可以通过选出具有相同支持度的全局闭频繁项集而轻松地实现一个高效冗余过滤算法。因此,把一个项集的支持度作为一个项集的关键,具有相同支持度的项集会被发送到同一个reducer函数。将在下面的算法1中给出这种方法的简要代码,该方法的开始3步与参考文献[10]中提出的算法描述的一样(Suppose X∈L)。
算法 1的处理过程如下:首先,每个 mapper函数一行一行地从第(3)步中读取输出结果并且输出<key,value>对和<supp(X),X>。这样,具有相同支持度的项集会被发送到相同的 reducer函数中并压缩成一棵树。然后,冗余项集会被并行地过滤掉。如图1所示,只需要把每个项集发送到局部频繁闭项集中一次(如图1的左半部分),而已有的方法[10]需要发送每个项集至少 3次,如图3所示。对于具有n个项集的数据库,每个项集的长度是{m1,m2,…,mn}。在传统方法[10]中,项集需要发送m1+m2+…+mn次,也就是说,该方法约节约了(m1+m2+…+mn)/n(即项集的平均长度)倍的通信成本。
for each itemset in r do
output(key,itemset);
end for
end Procedure
3 性能仿真与结果分析
为了验证该方法的效率和有效性,将在两个下载的真实的数据库connect和webdocs中做实验。实验在6台装有Hadoop0.21.0的计算机组成的计算机群上进行,计算机配置为 Intel 4核处理器,4 GB内存和 500 GB硬盘,装有 Ubuntu10.10。其中一个节点被设为主节点,负责安排执行不同节点之间的任务;其他节点负责运行。算法用Java实现,JDK版本为openjdk-6-jdk。
图4显示了在webdocs数据库上实验的结果。当ξ= 650 000时,该算法拥有最大的斜率值。因为当 ξ越大,对于在第(3)步中的每个reducer函数而言,本地数据库越小,所以在第(3)步和第(4)步中耗费的时间越短,而在第(1)步和第(2)步中消耗的时间依然保持不变。
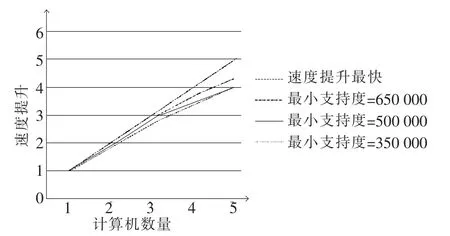
图4 数据库webdocs上的实验结果

图3 高效冗余过滤
算法1高效冗余项集过滤
Procedure:Map(key,value=supp(X)+X)
for each value do
output(supp(X),X);
end for
end Procedure
Procedure:Reduce(key,Iterable values)
Define and initialize a tree:r;
Sort the itemsets by their lengths in descending order;
for each itemset in values do
if itemset is closed in r then
Insert the itemset into r;
end if
end for
图5显示了在connect数据库上实验的结果。由于该数据库比较小,速度上的提高不如图4的明显。从图5可以看出,用4台电脑比用5台电脑更能提高速度。原因在于对于每个节点而言,数据集太小,导致通信成本远高于计算成本。实验结果表明,该算法对于大规模的数据集拥有良好的可扩展性,对于小规模数据集则不然。
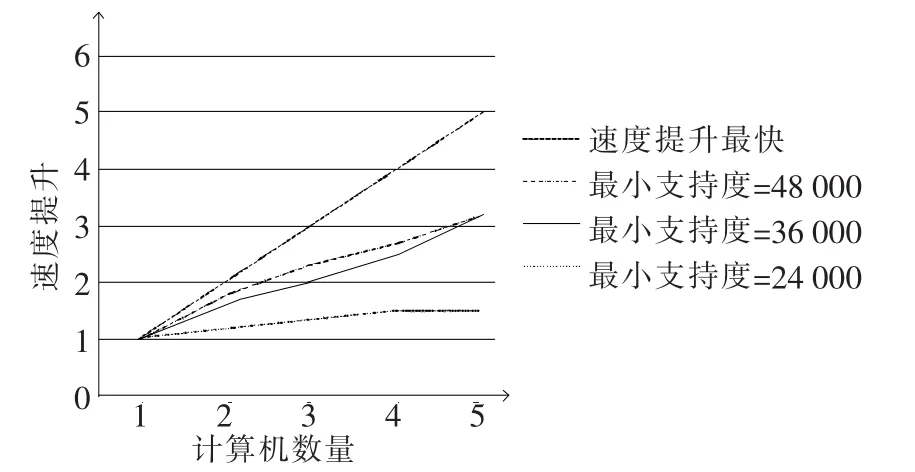
图5 数据库connect上的实验结果
对上述新冗余过滤算法和传统算法[10]在项集发送次数上作对比,结果如表1所示。例如数据集connect,如果不适用新的冗余过滤算法,如果数据集过大势必使计算成本和通信开销变得很高。根据表1,显然当ξ=24 000时,传统算法[10]与上述算法在项集发送次数的对比中可以看出新的冗余过滤算法的优越性。但是,该方法在webdocs数据库上却没有明显优势,原因在于在第(3)步中产生的项集的平均长度过短。由此可见,新算法对于长项集而言比短项集具有更高的效率。
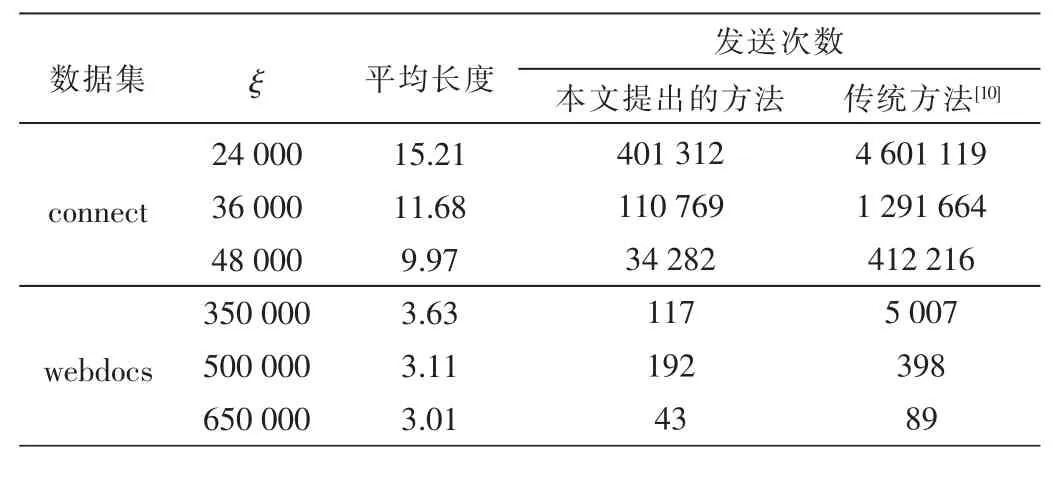
表1 项集发送次数对比表
对上述算法与传统算法[10]作运行时间上的对比,如表2所示。实验在5台负责运行的计算机组成的计算机群上进行,用两个相同的数据集但是阈值不同。从表2可以看出,由于局部闭频繁项集比源数据集要大而且项集自身的平均长度也很长,因此上述算法对于 connect数据库而言更高效。综上所述,该算法的运行速度更快。但是对于 webdocs,当 ξ取 350 000、500 000和 650 000时该算法没有优势,主要是由于第(3)步输出的结果太小。然而当ξ=200 000时,该算法比传统算法快得多,这是因为第(3)步的输出结果足够大并且具有更多长项集。
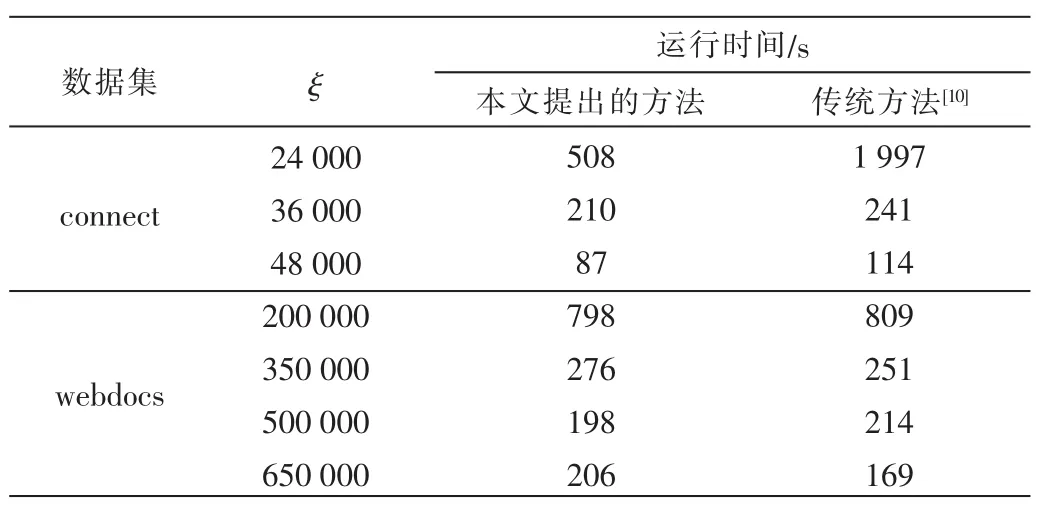
表2 运行时间对比表
4 结论
本文回顾了频繁闭项集挖掘现存的问题,并且提出了一种新的过滤局部闭而非全局闭频繁项集的方法。实验结果显示,该算法在面对大规模数据集时拥有很高的可扩展性。当局部闭频繁项集很大,尤其是对于一些阈值非常小或者项集过长的挖掘中,通信开销将严重影响算法性能。而本文所提方法能很好地解决这个问题。今后,将继续改进该算法,使之有更高的效率和更广的使用面。
[1]廖宝魁,孙隽枫.基于MapReduce的增量数据挖掘研究[J].微型机与应用,2014,33(1):67-70.
[2]Wang Jianyong,Han Jiawei,Pei Jian.CLOSET+:searching for the best strategies for mining frequent closed itemsets[C].Proceedings of the ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2003:236-245.
[3]FELDMAN R,DAGAN I.Knowledge discovery in textual databases(KDT)[C].Proceedings of 1stInternational Conference on Knowledge Discovery and Data Mining,Montreal,Canada,1995:112-117.
[4]ZANE O,EL-HAJJ M,LU P.Fast parallel association rule mining without candidacy generation[C].Proceedings of IEEE International Conference on Data Mining,ICDM 2001,2001:665-668.
[5]Liu Li,Li E,Zhang Yimin,et al.Optimization of frequent itemset mining on multiple-core processor[C].Proceedings of the 33rd International Conference on Very Large Data Bases,VLDB Endowment,2007:1275-1285.
[6]MADRIA K,BHOWMICK S.Research issue in web data mining[C].First International Proceedings of Data Warehousing and Knowledge Discovery,1999:303-312.
[7]PRAMUDIONO I,KITSUREGAWA M.Parallel fp-growth on pc cluster[J].Advances in Knowledge Discovery and Data Mining,2003,2637:467-473.
[8]BUEHRER G,PARTHASARATHY S,TATIKONDA S,et al.Toward terabyte pattern mining:an architecture conscious solution[C].Proceedings of the 12th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming,ACM,2007:2-12.
[9]蒋翠清,胡俊妍.基于 FP-tree的最大频繁项集挖掘算法[J].合肥工业大学学报(自然科学版),2010,33(9):1387-1391.
[10]陈光鹏,杨育彬,高阳,等.一种基于 MapReduce的频繁闭项集挖掘算法[J].模式识别与人工智能,2012,25(2):220-224.
杨世平(1955.2-),男,博士,教授,主要研究方向:计算机网络与信息安全。
Improvement of closed frequent item set m ining algorithm based on MapReduce
Fu Tingting1,Yang Shiping1,2
(1.College of Computer Science and Technology,Guizhou University,Guiyang 550025,China;2.College of Mingde,Guizhou University,Guiyang 550004,China)
Closed frequent itemset(CFI)mining is very crucial in many data mining works.In traditional data mining algorithms,FP-tree and Apriori are often applied to mine frequent itemsets.But memory requirement and computational cost become the vital problems.Especially,while mining closed frequent itemsets from large datasets,the problem will become significant and fill of challenge.To solve the problem,a parallelized algorithm based on MapReduce is presented,and it makes MapReduce extensively be used to compute big data.Besides,the algorithm goes to check whether the frequent itemstes are closed also needs MapReduce do further improvement.
MapReduce;closed frequent itemset;FP-tree algorithm
TP3-0
A
1674-7720(2015)24-0066-04
付婷婷,杨世平.基于MapReduce的频繁闭项集挖掘算法改进[J].微型机与应用,2015,34(24):66-69.
2015-08-28)
付婷婷(1990-),女,硕士研究生,主要研究方向:网络系统与信息安全。
