应用多模型共识偏最小二乘法和FTIR/ATR光谱技术建立苯丙酮尿症的筛查模型
2015-10-16魏伟伟王伟伟宋向岗程雅婷王淑美梁生旺
魏伟伟, 王伟伟, 宋向岗, 程雅婷, 陈 超*, 王淑美*, 梁生旺
(1.广东药学院中药学院,广东广州 510006; 2.广州金域医学检验中心有限公司,广东广州 510330)
苯丙酮尿症(Phenyketonuria,PKU)为新生儿的一种常见染色体基因隐性遗传病,是由于苯丙氨酸(Phenylalanine,Phe)代谢途径中苯丙氨酸羟化酶活性减低,导致Phe及其代谢产物在体内积蓄,可损害脑及神经细胞,影响患儿智力发育,是目前国内新生儿疾病筛查的主要项目之一。现有的筛查方法主要是对新生儿足跟部采血,滴于903#滤纸上,自然晾干,制成干血片;然后利用细菌抑制法[1]、高效液相色谱法[2]、串联质谱法[3]和荧光分析法[4]等方法,检测Phe的浓度,一般大于120 μmol/L可视为阳性[5]。这些检测方法虽具有较好的准确度和特异性,但也普遍存在消耗试剂、步骤繁琐、耗时较长等缺点。
红外光谱分析技术利用物质在红外光谱区的光学特性快速测定物质组成及含量,具有样品处理简单、不破坏样品、不消耗试剂、不产生污染、分析速度快、可以同时测定多种成分等优点,适用于复杂样品(如生物制品)的原位、在线、实时定量分析。目前,红外光谱在石油化工、农林、医药等领域已有广泛应用[6,7],在肿瘤、地中海贫血症等疾病筛查方面也有不少报道[8 - 12]。本文应用傅里叶变换-衰减全反射红外光谱(FTIR/ATR)采集新生儿足底血干血片的红外光谱信息,利用多模型共识偏最小二乘法(cPLS)建立Phe浓度的定量校正模型,以探讨建立新生儿PKU筛查的新方法。
1 实验部分
1.1 仪器与材料
Tensor37型傅里叶变换红外光谱仪(德国BRUKER公司),附OPUS7.2红外光谱软件,DLATGS检测器,水平ATR附件,扫描谱区范围为600~4 000 cm-1,扫描间隔为2 cm-1。
样本材料:69例干血片样本由广州金域医学检验中心提供,采用串联质谱法测定Phe的浓度,其中35例阴性样本的平均浓度为47.2 μmol/L,标准差为9.1 μmol/L;34例阳性样本的平均浓度为292.8 μmol/L,标准差为258.9 μmol/L。
1.2 光谱采集与预处理
以空气作为空白背景,采用FTIR/ATR法对干血片进行光谱采集,对每个血斑各取5个不同位置扫描,计算夹角余弦剔除异常光谱后,取平均值作为该血片的红外光谱数据。用红外光谱仪自带的OPUS7.2软件对所得光谱进行一阶微分预处理。
2 多模型共识偏最小二乘法(cPLS)
本文用到的多模型共识偏最小二乘法[13,14]是基于传统的偏最小二乘法提出的,其基本原理是利用同一训练集中的不同子集,建立一系列的子模型同时预测,将多个预测结果取平均,形成一个共识的结果。多模型共识的突出优点是多次使用训练集中不同样本建模,降低了模型对某一样本的依赖性。
2.1 方法原理
cPLS方法基本步骤如下:(1)样本随机分组后,确定cPLS中成员模型的接纳标准、模型总数等相关参数;(2)将训练集样本随机分为训练子集与验证集,并以训练子集建立PLS回归模型;(3)用上述所建模型预测验证集,以预测值与标准值间的平均相对误差作为该模型是否被接受的依据;(4)重复(2)、(3)直至达到预设的模型总数;(5)以符合条件的所有成员模型共同预测独立测试集样本,结果取均值作为最终的预测结果。
2.2 模型建立与评价
将全部69例样本按3∶1随机分配训练集与独立测试集,训练集再按3∶1随机分配训练子集与验证集。对预处理后的光谱数据进行归一化,以作为模型输入;Phe的浓度尤其是阳性样本浓度,因为标准差较大,所以先采取了对数转换,再作为模型输出。偏最小二乘模型采用MATLAB自带统计工具箱下plsregress命令实现,其它接口程序自编。模型评价指标包括预测均方根误差(RMSEP)、平均相对误差(MRE)、预测准确率(Acc),计算方法如下:
预测均方根误差(Root Mean Square Error of Prediction,RMSEP):
(1)
平均相对误差(Mean Relative Error,MRE):
(2)
预测准确率(Predictive Accuracy,Acc):
(3)
公式(1)~(3)中,Yp、Yr和n分别表示模型预测值、实验值以及样本个数,TP和TN表示正确预测的阳性和阴性样本的数目。
3 结果与讨论
3.1 主成分数的确定
利用训练子集建立PLS模型,并对验证集进行预测,改变不同的主成分数,得到预测均方根误差(RMSEP)和平均相对误差(MRE)的变化曲线,如图1所示。主成分数大于15时两者基本趋于稳定,故最佳主成分数设为15。
3.2 确定cPLS中成员模型的接纳标准
用单模型PLS预测时发现验证集MRE多在0.2以内,所以分别采用0.08,0.1,0.12,0.15,0.18和0.2为成员模型接纳标准,各自运行40次。结果显示,当采用MRE小于0.15为标准时,独立测试集预测结果的MRE最小。因此,本文选用MRE小于0.15作为最终成员模型的接纳标准。
3.3 模型总数的确定
cPLS算法应该包括尽可能多的不同的成员模型,通过对不同成员模型的结果整合,才能表现出cPLS的优势。因此,模型总数的确定对预测结果的稳定性和准确性有着重要影响。本文统计了模型总数从1到200时的结果,多次运行均发现,独立测试集的RMSEP会随模型数的增加渐趋稳定,如图2所示。模型数<100时,RMSEP较大且不稳定;当模型数>100时,RMSEP逐渐趋于稳定。同时算法多次运行中,因随机分配数据集而对结果略有波动。经综合考虑,本文确定模型总数为120。
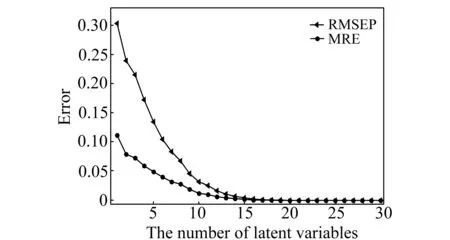
图1 不同主成分数时均方根误差和平均相对误差的变化Fig.1 Variation of RMSEP and MRE with the number of latent variables

图2 不同成员模型总数下独立测试集的RMSEP变化Fig.2 Variation of RMSEP with the number of member models in cPLS
3.4 对Phe浓度的定量分析
用cPLS和PLS模型分别对独立测试集进行预测,并对结果进行反对数转换,重复运算40次,计算各自评价指标。cPLS模型的RMSEP、MRE和Acc的均值分别为88.4,0.26和99.3,标准偏差分别为19.8,0.04和2.4;而PLS模型的RMSEP、MRE和Acc的均值分别为103.3,0.32和97.1,标准偏差分别为30.0,0.07和4.4。从图3和图4也可以看出,cPLS的预测误差低于PLS,结果更稳定,性能表现更好。

图3 PLS和cPLS对独立测试集预测的RMSEP的稳定性比较Fig.3 Comparison of the stability of the RMSEP by the PLS and cPLS on the independent datasets

图4 PLS和cPLS对独立测试集预测的MRE的稳定性比较Fig.4 Comparison of the stability of the MRE by the PLS and cPLS on the independent datasets
4 结论
多模型共识偏最小二乘法用同一训练集中不同子集建立多个模型,同时进行预测,将多个预测结果取均值作为最终结果,从而降低了预测结果对某一样本的依赖性,本质上较单模型稳健、预测精度高。
本文中cPLS模型较PLS单模型预测误差更低,结果更稳定。但是预测值的MRE仍然有待进一步提高(约为0.3),究其原因应该与数据集中阳性样本浓度范围宽泛、标准差较大有关。在今后的研究中,我们拟继续搜集样本,尤其是Phe浓度接近切值的样本,以进一步提高模型精度。尽管如此,cPLS方法将区分PKU的阴、阳性样本的准确率提高到平均值达到99.3%,一定程度上证实了本文基于cPLS和FTIR/ATR建立干血片中Phe含量校正模型的可行性,这将为新生儿PKU的筛查提供一种简便、绿色新技术。
