大数据处理模型Apache Spark研究
2015-09-28黎文阳
黎文阳
(四川大学计算机学院,成都 610065)
大数据处理模型Apache Spark研究
黎文阳
(四川大学计算机学院,成都610065)
0 引言
MapReduce计算模型在大规模数据分析领域已取得很大成绩,并被很多公司广泛采用。这些系统都是基于非循环的数据流模型,有很好的容错性,同时为开发人员提供了高级接口以便于编写并行程序。目前这些系统能很容易地访问集群中的计算资源,但是不能充分地利用分布式内存,导致了对那些重用中间结果的应用不是很有效。这些应用的特点是在多个并行操作之间重用数据,例如机器学习中的PageRank算法、K-means聚类算法、逻辑回归算法等迭代式算法。交互式的数据挖掘算法中也经常重用数据。Spark计算模型刚好解决了这些问题,并且能在Hadoop集群下部署,访问HDFS文件系统。Spark将分布式内存抽象成弹性分布式数据集(Resilient Distributed Datasets,RDD)[1]。RDD支持基于工作集的应用,同时具有数据流模型的特点:自动容错、位置感知调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,以便后续的查询能够重用,这极大地提升了查询速度。
1 Spark简介
Spark是UC Berkeley AMPLab于2009年发起的,然后被Apache软件基金会接管的类Hadoop MapReduce通用性并行计算框架,是当前大数据领域最活跃的开源项目之一。Spark是基于MapReduce计算框架实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark更适用于数据挖掘与机器学习等需要迭代的算法。如图1所示,逻辑回归算法在Hadoop和Spark上的运行时间对比图,可以看出Spark的效率有很大的提升[3]。
Spark由Scala[4]语言实现的,Scala是一种基于JVM的函数式编程语言,提供了类似DryadLINQ[5]的编程接口。而且Spark还提供了一个修改的Scala语言解释器,能方便地用于交互式编程,用户可以定义变量、函数、类以及RDD。
Spark集成了丰富的编程工具,其中Spark SQL用于SQL语言和结构化数据处理,Spark Streaming用于流处理,MLlib用于机器学习算法,GraphX用于图处理。Spark不但能够访问多种数据源,例如 HDFS、Cassandra、HBase、Amazon S3,还提供了Scala、Java和Python三种语言的API接口,以便于编写并行程序。而且Spark还能部署在已有的Hadoop系统上,由YARN进行集群调度,极大地利用了Hadoop系统。
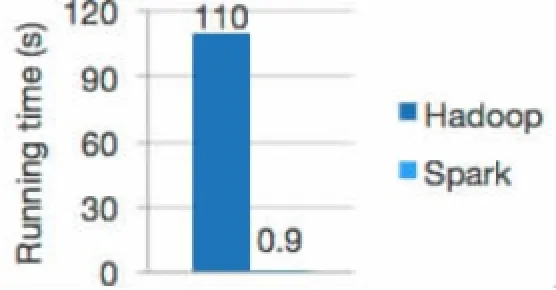
图1 逻辑回归算法在Hadoop和Spark上的运行时间
1.1适用场景
Spark适用于那些在多个并行操作之间重用数据的应用,而MapReduce在这方面效率并不高,因为MapReduce和DAG引擎是基于非循环数据流的,即一个应用被分成一些不同的作业(job),每个作业从磁盘中读数据,然后再写到磁盘[2]。Spark不太适合那些异步更新共享状态的应用,例如并行Web爬行器。Spark的适用场景有:
●迭代式算法:许多机器学习算法都用一个函数对相同的数据进行重复的计算,从而得到最优解。MapReduce计算框架把每次迭代看成是一个MapReduce作业 (job),而每个作业都要从磁盘重新加载数据,这就导致了效率不高,而Spark可以把中间数据缓存到内存中加快计算效率。
●交互式数据分析:用户经常会用SQL对大数据集合做临时查询(Ad-Hoc Query)。Hive把每次查询都当作一个独立的MapReduce作业,并且从磁盘加载数据,有很大的延迟,而Spark可以把数据加载到内存中,然后重复的查询。
●流应用:即需要实时处理的应用,这类应用往往需要低延迟,高效率。
1.2组成部分
目前 Spark由四部分构成:Spark SQL、MLlib、GraphX、Spark Streaming,如图2所示。
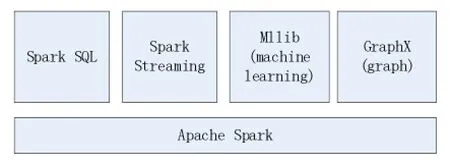
图2 Spark组成部分
(1)Spark SQL:是Spark处理SQL和结构化数据工具,Spark引入了SchemaRDD的数据抽象,使其能以统一地、高效地访问和查询各种不同的数据源,例如Apache Hive表、parquet文件、JSON文件。Spark SQL兼容Apache Hive,能重用Hive的前端和元存储。Spark SQL API能像查询RDD一样查询结构化的数据,并且Spark SQL还提供了JDBC/ODBC的服务端模式,以便建立JDBC/ODBC数据连接。
(2)MLlib(Machine Learning):是Spark提供的机器学习库,包含了常见的机器学习算法。Spark擅长于迭代式计算,所以与MapReduce相比,MLlib中的算法效率更高,性能更好。常见的算法有:
①SVM、逻辑回归(logistic regression)、线性回归(linear regression)、朴素贝叶斯(naive Bayes)
②K均值算法(K-means)
③奇异值分解(singular value decomposition)
④特征提取与转换(feature extraction and transformation)
(3)GraphX(Graph Processing):是Spark处理图(graph)的框架,利用Pregel API可以用RDD有效地转换(transform)和连接(join)图,实现图算法。GraphX在速度上可与最快的专用图处理系统相媲美。
(4)Spark Streaming:是Spark处理流应用的库。其结合了批处理查询与交互式查询,方便重用批处理的代码和历史数据。基本原理是Spark将流数据分成小的时间片断(几秒),以类似批处理的方式来处理这小部分数据。Spark Streaming API能像编写批处理作业一样构建可扩展的流应用。Spark Streaming也能访问各种不同的数据源,例如能够从HDFS、Flume、Kafka、Twitter和ZeroMQ中读取数据。
1.3部署模式
Spark集群如图3划分,主要有驱动程序、集群管理程序,以及各worker节点上的执行程序[3]。
Spark应用的主程序称为驱动程序 (driver program),其中包含SparkContext对象,用于连接集群管理程序(cluster manager)。集群管理程序用于分配集群中的资源,目前有三种:Spark独自的集群管理程序、Mesos[6]和 YARN[7]。Spark应用的运行过程是,Spark-Context对象首先连接集群管理程序,然后Spark获取集群中各个节点上的执行程序(executor),执行程序是用于计算和存储数据的进程,然后Spark把代码发送到执行程序,最后运行执行程序上的任务。所以Spark目前支持3种集群部署模式:Standalone模式、Apache Mesos模式、Hadoop YARN模式。
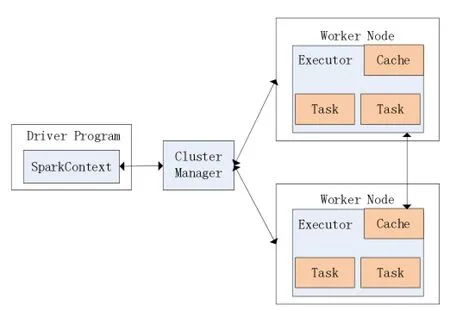
图3 Spark集群组成部分
(1)Standalone模式:即独立模式,使用Spark自带的集群管理程序,好处是不需要额外的软件就能运行,配置简单。
(2)Apache Mesos模式:需要安装Mesos资源管理程序,Spark的集群管理就交给Mesos处理了。使用Mesos的好处是,可以在Spark与其他框架之间或多个Spark实例之间动态地划分。
(3)Hadoop YARN模式:利用已有的Hadoop集群,让Spark在Hadoop集群中运行,访问HDFS文件系统,使用YARN资源调度程序。Spark on YARN是Spark 0.6.0版本加入的,该模式需要额外的配置参数。
Spark既可以在单机上运行,也可以在Amazon EC2上运行。Spark提供了相应的配置文件、启动脚本、结束脚本用于配置、启动、结束Spark集群中的master 和slave。也提供了相应的Web监控系统与日志系统,方便地监控与调试程序。而且还可以配置Zookeeper以保证高可用性。
2 Spark编程模型
Spark最主要的抽象就是弹性分布式数据集(Resilient Distributed Datasets,RDD)以及对RDD的并行操作(例如map、filter、groupBy、join)。而且,Spark还支持两种受限的共享变量 (shared variables):广播变量(broadcast variables)和累加变量(accumulators)。
2.1RDD
RDD是只读的对象集合,RDD分区分布在集群的节点中。如果某个节点失效,或者某部分数据丢失,RDD都能重新构建。Spark将创建RDD的一系列转换记录下来,以便恢复丢失的分区,这称为血系(lineage)。每次对RDD数据集的操作之后的结果,都可以缓存到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘操作。RDD只支持粗粒度转换,即在大量记录上执行的单个操作。虽然只支持粗粒度转换限制了编程模型,但RDD仍然可以很好地适用于很多应用,特别是支持数据并行的批量分析应用,包括数据挖掘、机器学习、图算法等,因为这些程序通常都会在很多记录上执行相同的操作。
使用RDD的好处有:
●RDD只能从持久存储或通过转换(transformation)操作产生,相比于分布式共享内存(DSM)可以更高效地实现容错,对于丢失部分数据分区只需根据它的血系就可重新计算出来,而不需要做特定的检查点(checkpoint)。
●RDD的不变性,可以实现类MapReduce的预测式执行。
●RDD的数据分区特性,可以通过数据的本地性来提高性能,这与MapReduce是一样的。
●RDD是可序列化的,当内存不足时可自动改为磁盘存储,把RDD存储于磁盘上,此时性能会有大的下降但不会差于现有的MapReduce。
在Spark中,RDD是一个Scala对象,对RDD的并行操作即是调用对象上的方法。有四种方法创建一个RDD:
(1)通过一个文件系统中的文件创建,例如常见的HDFS文件。
(2)通过并行化Scala集合,即把一个集合切分成很多片,然后发送到各种节点。
(3)通过对已有的RDD执行转换操作,可以得到一个新的RDD。例如通过flatMap可以把类型1的RDD转换成类型2的RDD。
(4)通过把RDD持久化。RDD默认是惰性的,即只有当RDD在执行并行操作时,RDD才被物化,执行完后即被释放。用户可以通过显式的cache或save操作使RDD持久化。
2.2并行操作
作用在RDD上的并行操作有两种:转换(transformation)和动作(action),转换返回一个新的RDD,动作返回一个值或把RDD写到文件系统中。转换是惰性的,即从一个RDD转换成另一个RDD不是马上执行的,Spark只是记录这样的操作,并不执行,等到有动作操作时才会启动计算过程。常见的转换(transformation)如表1所示,常见的动作(action)如表2所示。
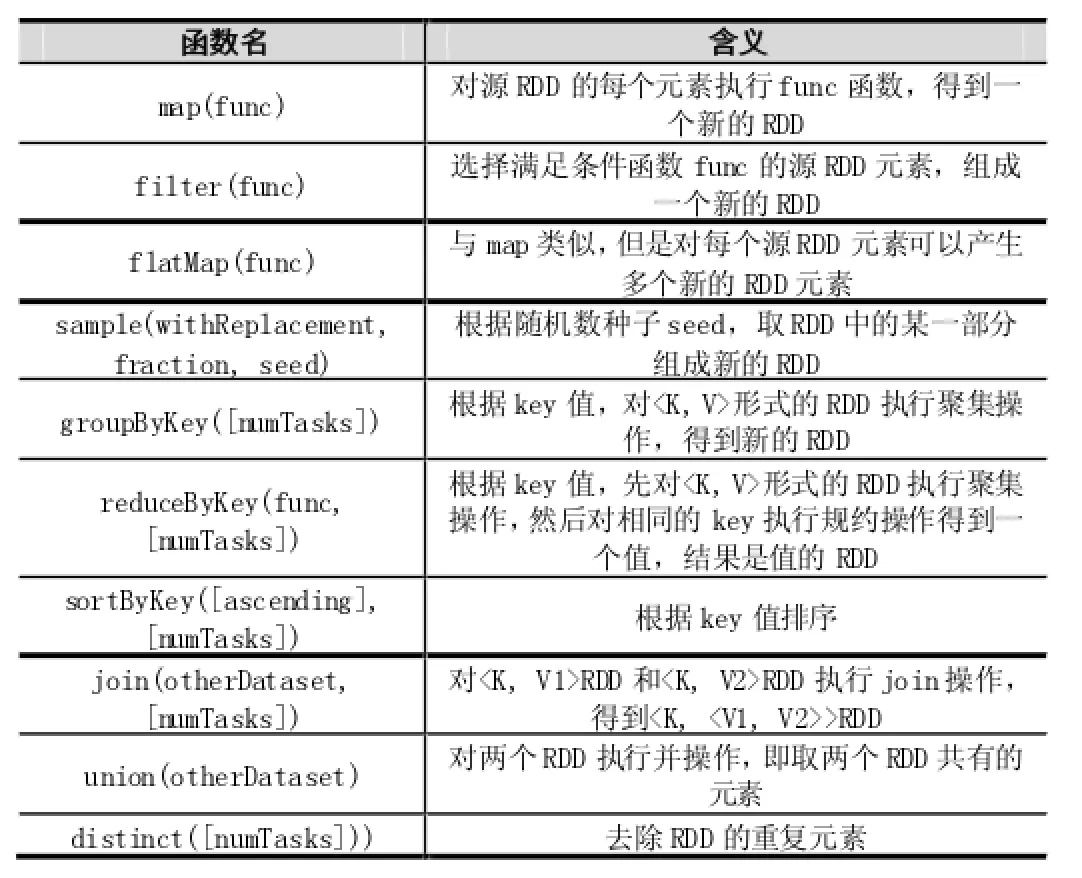
表1 常见的转换(transformation)操作
注:有些操作只对key有效,例如join、groupByKey, reduceByKey。除了这些操作以外,用户还可以请求将RDD缓存起来。而且,用户还可以通过Partitioner类获取RDD的分区顺序,然后将另一个RDD按照同样的方式分区。
2.3共享变量
通常情况下,Spark中的map、filter、reduce等函数的参数是一个函数(闭包),运行时这些函数参数被复制到各个worker节点上,互不干扰。Spark还提供了共享变量用于其他用途,常见的有两种:
(1)广播变量(broadcast variables):对于大量的只读数据,当有多个并行操作时,最好只复制一次而不是每执行一次函数就复制一次到各个worker节点。广播变量就是用于这种情况,它只是包装了一下原有的数据,然后只复制一次到各worker节点。
(2)累加变量(accumulators):累加变量只能用于关联操作,并且只有驱动程序才能读取。只要某个类型有“add”操作和“0”值都可以是累加变量。累加变量经常用于实现MapReduce的计数器,而且由于是只加性的,所以很容易实现容错性。
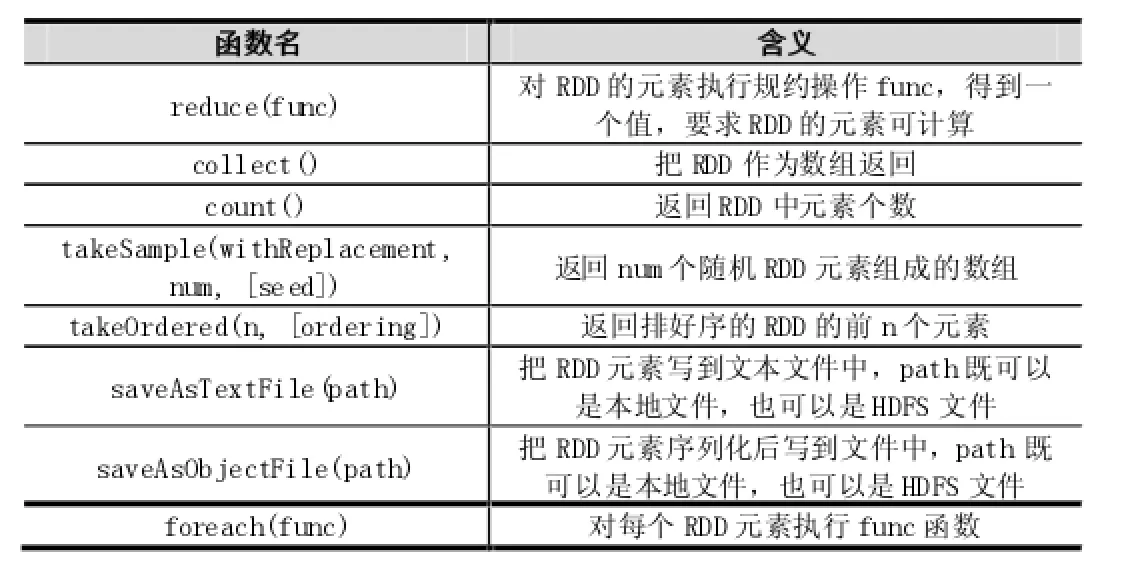
表2 常见的动作(action)操作
3 编程示例
Spark提供了 Scala、Java和 Python三种语言的API。而且Spark程序既可以通过交互式Spark shell运行 (Scala或Python语言),又能以独立的程序运行(Scala、Java或Python语言)。下面这些编程示例使用Scala语言,在Spark shell下执行[8]。Scala是一种基于JVM的函数式编程语言。
Spark的首要抽象便是弹性分布式数据集RDD,所以编程的主要任务就是编写驱动程序,创建RDD,然后对RDD执行并行操作。RDD既能从外部文件中创建(例如HDFS文件),又能从对其他RDD执行转换操作(transformation)得到。对RDD有两种操作:一种是转换操作,产生新的RDD;另一种是动作操作(action),开始一个作业并返回值。首先配置好Spark运行环境,然后启动Spark集群,在此不再细述。
3.1文本搜索
本示例搜索某个HDFS日志文件的ERROR信息:


Spark还能显示的缓存RDD,只需执行cache操作:
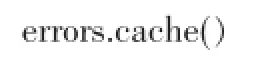
3.2单词统计
本示例统计某个HDFS文件的各个单词出现的次数,并将结果保存到HDFS文件:

3.3估算PI值
Spark也用于计算密集型任务,本示例使用“扔飞镖法”估算PI值,在(0,0)-(1,1)的正方形中,随机生成坐标(x,y),统计落在圆内的点数,那么落在圆内的点数/总点数等于PI/4:

4 结语
本文大致介绍了Spark系统的基本概念与核心思想,并给出了编程示例。Spark最重要的抽象就是RDD,一种有效的、通用的分布式内存抽象,它解决了集群环境下并行处理大数据的效率问题,比Hadoop MapReduce的效率高,特别适用于机器学习中的迭代式算法和交互式数据分析等特殊的应用场景。目前,Spark是非常流行的内存计算框架,一直在发布新版本,还处于比较活跃的开发阶段。当前遇到的技术挑战有:①资源调度程序如何为Spark作业确定合适的资源需求;②Spark如何更好地与YARN集群管理程序配合,使系统最优;③提供更多的编程API供用户使用。
[1]Zaharia M,Chowdhury M,Das T,et al.Resilient Distributed Datasets:A Fault-Tolerant Abstraction for in-Memory Cluster Computing [C].Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation.USENIX Association,2012:2-2
[2]Zaharia M,Chowdhury M,Franklin M J,et al.Spark:Cluster Computing with Working Sets[C].Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing,2010:10~10
[3]Spark[EB/OL].http://spark.apache.org
[4]Scala[EB/OL].https://www.scala-lang.org
[5]Yu Y,Isard M,Fetterly D,et al.DryadLINQ:A System for General-Purpose Distributed Data-Parallel Computing Using a High-Level Language[C].OSDI.2008,8:1·14
[6]Hadoop MapReduce Tutorial[EB/OL].http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
[7]Apache Mesos.http://mesos.apache.org
[8]Spark Programming Guides[EB/OL].http://spark.apache.org/docs/1.1.0/quick-start.html
Spark;Hadoop;MapReduce;Big Data;Data Analysis
Research on Apache Spark for Big Data Processing
LI Wen-yang
(College of Computer Science,Sichuan University,Chengdu 610065)
1007-1423(2015)08-0055-06
10.3969/j.issn.1007-1423.2015.08.013
黎文阳(1990-),男,河南信阳人,硕士研究生,研究方向为分布式与数据库
2015-02-10
2015-02-28
Apache Spark是当前流行的大数据处理模型,具有快速、通用、简单等特点。Spark是针对MapReduce在迭代式机器学习算法和交互式数据挖掘等应用方面的低效率,而提出的新的内存计算框架,既保留了MapReduce的可扩展性、容错性、兼容性,又弥补了MapReduce在这些应用上的不足。由于采用基于内存的集群计算,所以Spark在这些应用上比MapReduce快100倍。介绍Spark的基本概念、组成部分、部署模式,分析Spark的核心内容与编程模型,给出相关的编程示例。
Spark;Hadoop;MapReduce;大数据;数据分析
Apache Spark is a popular model for large scale data processing at present,which is fast,general and easy.Compared with the MapReduce computing framework,Spark is efficient in iterative machine learning algorithms and interactive data mining applications while retaining the compatibility,scalability and fault-tolerance of MapReduce.With its in-memory computing,Spark is up to 100x faster than Hadoop MapReduce in memory.Presents the basic conception,component and the deploying mode of Spark,introduces the internal abstraction and the programming model,gives the programming examples.
