基于分布式的关联规则算法在医疗数据挖掘中的应用
2015-09-28李晓楠马元吉肖川
李晓楠,马元吉,肖川
(1.四川大学计算机学院,成都 610065;2.四川大学华西医院,成都 610041;3.四川大学华西公共卫生学院,成都 610041)
基于分布式的关联规则算法在医疗数据挖掘中的应用
李晓楠1,马元吉2,肖川3
(1.四川大学计算机学院,成都610065;2.四川大学华西医院,成都610041;3.四川大学华西公共卫生学院,成都610041)
0 引言
随着大数据时代的到来,医院的信息化建设逐步完善,电子病历大量积累、医疗设备和仪器的信息逐渐增多,病人病史、诊断、检验和治疗的信息等大量医疗信息已经积累在医院数据库中,并且数据信息的结构呈现多样化的特征。当数据量急速增长时,利用计算机对医疗数据做信息挖掘,提取恰当的数据进行处理,利用聚类、分类等各种数据挖掘方法构建医疗数据分析模型,对病人资料库中的大量数据进行分析,提炼出其中有价值的信息,发现不同疾病之间的关联,寻找传染病的传染特征,预测疾病发展趋势,已成为医疗信息化中进一步研究的课题。其中,对影响我国居民健康的三大传染病:乙肝、结核、艾滋的相关研究也是医学科学研究中一个重要的方向。文中依托“十二五”科技重大专项——国家重大传染病综合防治绵阳示范区项目中获取的体检信息数据,对信息系统中获取到的医疗数据的乙肝部分进行挖掘研究,对乙肝的并发症、乙肝发病情况和生活习惯之间的关联关系进行了探索。
1 Apriori算法及其分布式化
1.1Apriori算法
Apriori算法是一种挖掘关联规则的频繁项集算法,最早由R.Agrawal等人提出,目的是从大量数据中发现事物的相关联系,Apriori算法应用广泛,可用于消费市场价格分析、网络安全中的入侵检测、获取顾客的购物习惯等。Apriori算法逐层搜索,迭代多次从k项集中寻找(k+1)项集,即先找出所有的频繁1项集L1,随后利用L1找到频繁2项集的集合L2,再用频繁2项集L2找L3,反复进行,直到找不到频繁k项集。所有的频繁集中找出符合一定置信度的规则,即产生用户感兴趣的关联规则。将Ck设为候选k项集,算法的具体过程描述如下:
(1)以集合I作为候选集C1,通过对数据集扫描,得到候选集C1的支持度,将大于设置的最小支持度的元素提出,即频繁1项集L1;
(2)扫描数据集,计算候选集Ck的支持度,找出大于最小支持度min_sup的元素作为频繁k项集Lk;
(3)通过频繁k(k大于1)项集Lk产生k+1项候选集Ck+1;
(4)迭代执行步骤(2)、(3),不能找出k+1项候选集时算法结束。
Apriori算法每次迭代都要对全部数据做一次读取,并做一些复杂的逻辑运算,是相当耗费时间的,如果将算法并行处理,在多节点同时执行,将会大大地减少算法过程中的资源消耗。
1.2Hadoop的MapReduce编程模型
MapReduce是一种处理大量数据的并行编程模型和计算框架,将一个复杂的计算过程划分到多个节点上执行,将大任务分而治之,汇总每个节点上的运算结果得到最后的计算结果。主要包括Map和Reduce两个过程:Map过程,数据被分成M个独立的数据块,M个mapper函数,每个map得到一个数据块,按照一定的计算过程进行计算,将计算结果以Key-Value的形式输出,中间结果中的Key-Value按照Key的值分组排序,形成N个Key-ValueList。Reduce过程,将中间结果Key-ValueList作为输入,分配给N个Reduce函数,计算并输出最终结果。MapReduce工作流程如图1所示。
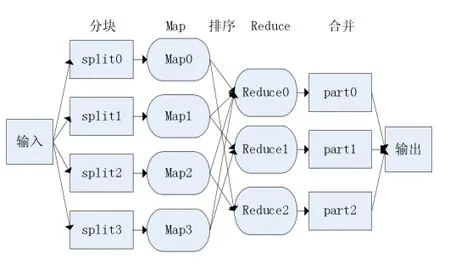
图1
在这一过程中,Map函数和Reduce函数的具体执行过程都可以由用户编程实现。
1.3Apriori算法的分布式化
将Apriori算法应用到Hadoop中,主要目标是对算法中每一次迭代求频繁项集的过程执行一次mapreduce过程。计算过程设计如下:
(1)数据分块。首先将数据提交到分布式文件系统,Map-Reduce将数据划分为n个大小相同的数据块,发送到集群中的m个节点。
(2)数据格式化。n个数据块被格式化为键值对<key,value>。以num为每个属性的标识,list为每个属性对应的列表值,格式化为<num,list>。
(3)Map过程。Map函数对输入的数据记录进行扫描,处理后生成<key,value>对,先产生该数据块的频繁1项集,然后找出该数据块的频繁k项集。频繁1项集的产生过程与词频统计方法类似,局部频繁k项集的计算过程与传统的Apriori算法一致。
(4)Combine函数。Combine函数起一个协助Reduce函数的功能,在Map函数完成后,将Map函数本地输出做一个合并,并生成局部的频繁项集,然后再将合并后的键值对散列划分到几个不同的分区,每个分区对应Reduce函数进行执行。因为当原始数据量很大时,每个Map函数产生成千上万条记录,数据通过网络发送到Reduce函数,将消耗相当大的网络资源,产生数据延迟。
(5)Reduce函数。将Map函数的输出作为Reduce的输入,合并所有的局部频繁项集,生成全部数据的候选频繁项集。
(6)扫描原始数据。对原始数据中的每条记录进行扫描,如果该记录在全局候选频繁项集中存在,则类似统计过程,将其写入上下文对象Context中,传递给Reduce函数汇总。
(7)合并输出结果。对Reduce函数的输出进行合并计算,将所有大于用户设置的最小支持度的值输出,写入分布式文件系统的输出文件,即得到所求的频繁项集。根据置信度对频繁项集进行筛选,即可找到相应的关联规则。
流程如图2所示。
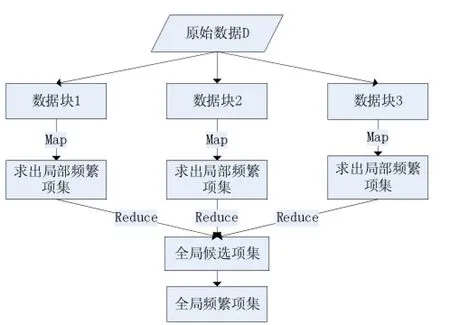
图2
相比传统单机模式下的数据挖掘,分布式化后的数据挖掘算法有如下几个特点:
(1)扫描原始数据的次数减少,频繁项集计算过程只需要对原始数据进行两次扫描,降低了时间消耗和计算开销。
(2)频繁项集的查找可以在多节点并行执行,并且,Map过程的执行时间仅与输入文件的大小成正比。
2 乙肝数据的挖掘实现
2.1数据预处理
利用项目中获取的30万居民的体检数据,筛选出乙肝抗原hbsag为阳性的患者15000条,即乙肝患者数据,进行尝试性的数据挖掘。提取了病人年龄(age)、性别(gender)、职业(career)、是否高血压(hypertension)、是否糖尿病(diabetes)、乙肝家族史(family_history_hb)、乙肝疫苗接种史(hb_vaccination)、吸烟史(smoke_habit)、饮酒史(drink_habit)、BMI指数(bmi)、肝部B超情况(bultrasound_liver)等30个字段作为每条数据的属性,对这些数据做结构化的统一,然后上传到Hadoop集群,通过已完成的数据挖掘算法对数据进行分析,建立乙肝抗原阳性这一属性值与其他属性间的关系。具体实现步骤如下:
(1)搭建Hadoop集群,设置完全分布式模式,4个节点的配置如下:运行环境:Ubuntu、Hadoop版本:Hadoop0.20.2,JDK版本:JDK1.6.,处理器:Core duo e6700双核处理器,主频:3.2GHz,内存:2GB。
(2)对数据进行预处理,如字符串格式的替换,属性值的统一等,将预处理后的数据上传到Hadoop集群的分布式文件系统中。
(3)将预先完成的分布式化后的Apriori算法移植到到Hadoop集群中的一个客户端,指定要处理的数据路径,运行客户端数据挖掘程序,将任务提交到Hadoop集群。
(4)生成挖掘结果。
2.2挖掘结果分析
使用Hadoop集群结合分布式化的关联规则算法,本例中处理数据条数约15000,设置最低支持为1000,置信度0.7,这两项值可根据实际情况进行调整,挖掘算法挖掘出来的结果选取了代表性部分,如下所示:
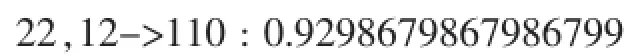

其中,不同的整数值代表不同的属性的不同值域,如22代表职业是农民、96代表年龄段46~50等。根据关联的重要度和概率强度,结合实际中的情况我们选取了以下几条规则:
本次居民健康体检范围内,乙肝患者职业多为农民,且有吸烟的生活习惯,有饮酒史生活习惯的患病概率更高。乙肝患者年龄多集中在41~60岁,且BMI指数显示体重超重的人患乙肝的概率更高;乙肝患者有一定概率出现肝硬化、脂肪肝;乙肝与心率、血压无明显联系。
由于项目中得到的数据具有一定的地域局限性,因此得到的结果仅作为一个参考,当数据量规模足够大,各个年龄段、各种职业类别的样本足够多时,挖掘结果将更加具有医学研究价值。
分布式化后的关联规则运行在集群上和运行在单机上的传统情况相比,执行效率有明显提升,随着集群节点的增加,针对相同数据量的计算,分布式系统中实现的算法加速比显著上升,如图3所示:
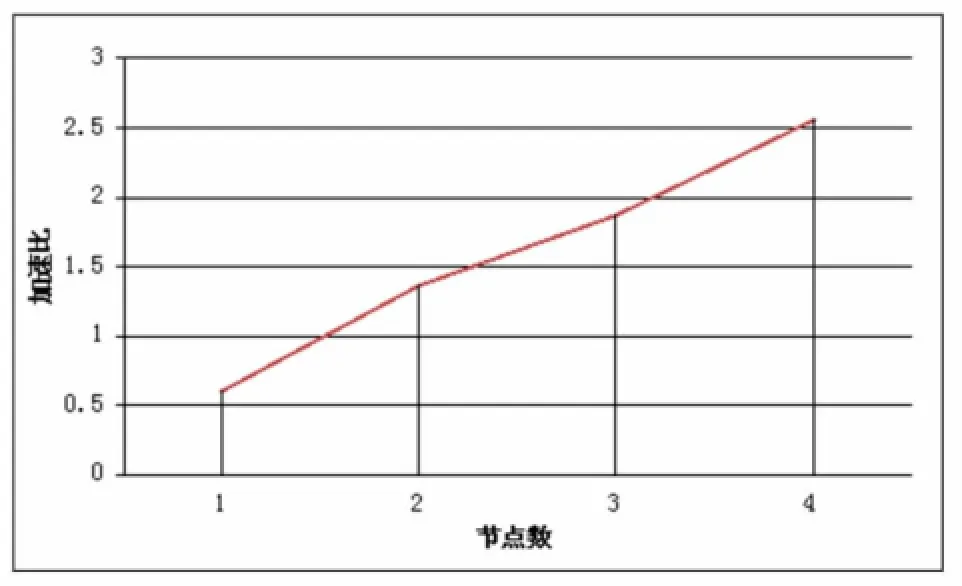
图3
同时,针对不同的数据量大小,也在分布式Apriori算法下进行了测试,4个节点环境下执行时间对比如表1所示:
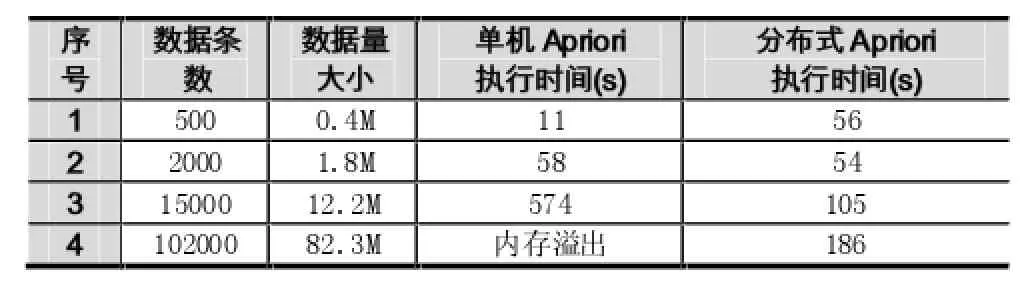
表1
传统模式下,运行在单机上的Apriori算法瓶颈在于候选集的生成,需要占用很大的空间和时间,当算法移植到分布式平台中,算法执行上的开销会大大减少,并且集群中每个节点中的挖掘过程是不依赖的,减少节点间通信,使算法的效率得到了提高。当数据量庞大时,传统单机模式的执行效率只能依赖于硬件的提升,且效果不显著,此时,分布式平台的高效性将更加明显。
3 结语
通过研究Hadoop分布式平台的技术特点,结合数据挖掘技术,给出了基于分布式的Apriori算法设计思想,并将算法实现运用在居民体检中的乙肝患者数据,对乙肝的并发症等进行了数据分析。实验表明,基于分布式的数据挖掘技术在医疗数据分析领域的应用是有价值的。随着医院医疗数据的增加,居民对医疗健康的关注,基于分布式的数据分析能够更大地发挥其高效性,分布式数据挖掘技术在医疗信息中的疾病诊断、治疗、预测等诸多方面的研究将会被更加广泛地应用。
[1]赵虎.云计算环境下的关联数据挖掘算法实现[D].成都:电子科技大学,2011
[2]朱安柱.基于Hadoop的Apriori算法改进与移植的研究[D].武汉:华中科技大学,2012
[3]郑丹青.基于数据挖掘的临床医疗数据分析系统[J].长春工业大学学报(自然科学版),2011
[4]周云辉,王娇.数据挖掘技术在医疗领域中的应用研究[J].机械工程与自动化,2013
[5]郑启龙,房明,汪胜,王向前,吴晓伟.基于MapReduce模型的并行科学计算[J].微电子学与计算机
Distributed;Apriori Algorithm;Medical Data;Data Mining
Application of Association Rules Algorithm Based on Distributed in Medical Data Mining
LI Xiao-nan1,MA Yuan-ji2,XIAO Chuan3
(1.College of Computer Science,Sichuan University,Chengdu 610065;2.West China Hospital of Sichuan University,Chengdu 610041;3.West China School of Public Health,Sichuan University,Chengdu 610041)
1007-1423(2015)08-0047-04
10.3969/j.issn.1007-1423.2015.08.011
李晓楠(1989-),女,山西应县人,在读硕士研究生,研究方向这计算机网络与信息系统、医疗信息化
马元吉(1981-),男,四川新都人,硕士研究生,讲师,研究方向为病毒性肝病的基础与临床
肖川(1990-),女,湖南长沙人,在读硕士研究生,研究方向为流行病学
2015-01-20
通过研究基于Hadoop平台的map/reduce思想,针对关联规则算法Apriori算法提出其在分布式平台下的改进算法,利用分布式化的Apriori算法对居民体检中发现的乙肝患者疾病数据进行分析挖掘,主要建立乙肝阳性和其他健康指标间的关联规则。实验结果证明关联规则算法Apriori在医疗数据挖掘中的有效性和高效性。
分布式;Apriori算法;医疗数据;数据挖掘
国家重大科技专项(No.2012ZX10004-901)、四川省科技支撑计划项目(No.2013SZ0002、No.2014SZ0109)
By researching on the map/reduce theory based on Hadoop distributed system,for Apriori algorithm,which is a kind of association rules algorithm,puts forward the improved algorithm in a distributed platform.Uses distributed data Apriori algorithm to analyze data of disease patients with hepatitis B which is found in healthy examination.The purpose is to establish association rules between HBV-positive and other health indicators.The results prove that the association rule mining algorithms on medical data is effectiveness and efficiency.
