基于模板的汉维商品命名实体翻译研究
2015-09-28王静雅袁保社
王静雅,袁保社
(新疆大学信息工程学院,乌鲁木齐 830046)
基于模板的汉维商品命名实体翻译研究
王静雅,袁保社
(新疆大学信息工程学院,乌鲁木齐830046)
0 引言
基于模板的翻译方法TBMT(Template Based Machine Translation)是基于规则的机器翻译(RBMT)方法和基于实例的机器翻译(EBMT)方法的结合与优化[1]。商品名是一种特殊的命名实体,如果直接使用现有的命名实体翻译技术,会出现很多问题。我们通过分析大量的产品命名实体,发现其结构通常为:品牌名+型号名+修饰词+核心词+规格说明。共同点如下:同品牌商品名中相同词语重复率大、同系列商品命名结构类似、形容词多等。结合商品命名实体自身结构,我们认为此方法十分适合商品名实体的翻译。
本文中,我们提出一种改进了的TTL机器翻译模板自动抽取算法。这种方法是首先将语料进行聚类操作,通过对相似实例一一进行比较,统计出现频率较高但并不是全部出现的词语或短语,添加作为候选部分。此方法使模板质量有明显提高,可大大减少翻译时模板匹配时的工作量,提高效率。
1 翻译模板的抽取
1.1TTL模板抽取算法
Ilyas Cicekli和H.Altay Guvenir于 2001年提出TTL(Translation Template Learner)启发式类比学习模板抽取算法,此方法不需要语法知识和句法结构。主要思想是从两对互译的实例中学习得到翻译模板;通过比较实例中的相同部分和不同部分,将相同部分作为固定项,不同部分作为可变项,然后加以归纳,将不同部分进行变量置换而得到翻译模板。最后建立源语言和目标语言变量之间的对应关系[2]。文献[3]也用过类似算法进行模板的抽取,但主要针对的是农业常用短语进行的模板抽取。
1.2改进的TTL模板抽取算法
由于TTL算法只能从结构相同或相近的实例对中取得好模板,若从结构差异大的实例对中,往往抽取出无用模板。并且只需比较两个实例就可抽取出一个模板,得到模板重复较多,质量和泛化能力不高。我们对TTL模板抽取算法进行改进,主要通过语料聚类和加入候选项两个方面。
(1)语料聚类
聚类操作是利用文献[4]提出的相似度计算方法,利用公式(1),(2),计算每个商品名的相似度,将相似度大于特定阈值的语料归为同类。
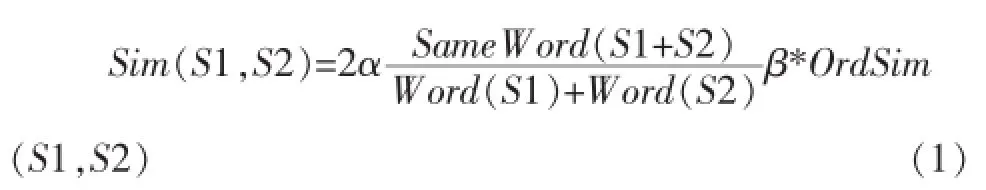
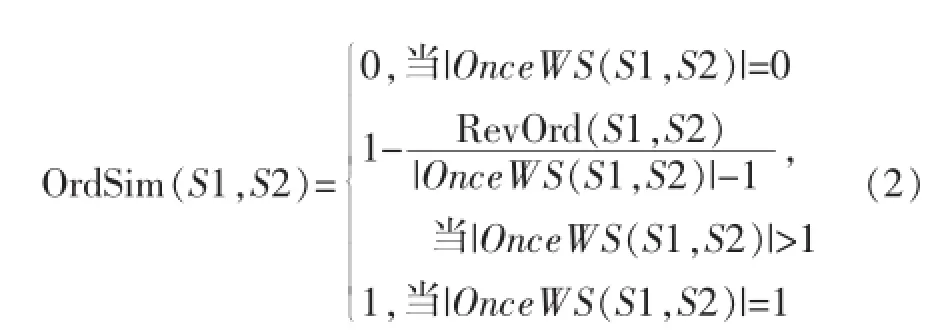
在公式(1)中,前一部分表示词形相似度,后一部分表示词序相似度。其中SameWord(S1+S2)表示两实例中相同词语的个数,Word表示实例中词语的个数。公式2中OnceWS(S1,S2)表示在S1,S2中都出现且都只出现一次的单词的集合。RevOrd(S1,S2)表示相同单词在S1中的排序后,将此单词序号对应放入S2中,得出S2中单词序号的各相邻分量的逆序数。由于词形相似度起主要作用,词序相似度起次要作用,所以要求α>>β,一般α取值为0.9,β取值为0.1。
(2)增加候选项
我们将聚类操作后的同类实例一一进行比较,得出一个模板。在比较后得出相同部分和不同部分,对于实例中出现频率较高,但并不是全部实例中都包含相同的部分,我们把它归结为候选项。将每个实例中都出现的部分归结为固定项,不重复出现的部分归结为可变项,即为模板槽。改进模板抽取的算法如下:
输入:源语言实例Si,目标语言实例Tj,与其分词结果和词对齐结果
输出:抽取出的模板对TemplateSet

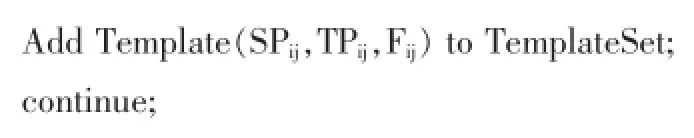
其中,函数Similarity找出两个实例中的相同单词;函数ExtractCommonPart提取两个实例的相同部分;CommonPartNumber表示词语重复次数,CompareTimes表示实例比较次数,FixedPortion和OptionalParts分别表示模板中固定项和候选项;GetSlotRelations函数获得汉语模板和维语模板之间的一一对应关系。在抽取算法中,我们规定相同项出现次数大于比较次数的1/2,但小于比较总次数时,将它们定义为候选项。据上述算法,以下面经过分词和词对齐处理后的实例对输入为例:
S1:乐事天然薯片
T1:lexi tEbi bErENgE yapriKi
词对齐:1-1 2-2 3-3 3-4
S2:乐事薯片
T2:lexi bErENgE yapriKi
词对齐:1-1 2-2 2-3
S3:乐事墨西哥 鸡汁 西红柿 味天然 薯片
T3:lexi miksika tohukiyami pEmidur tEmlik tEbi bErENgE yapriKi
词对齐:1-1 2-2 3-3 4-4 5-5 6-6 7-7 7-8
S4:乐事 忠于 原味 天然 薯片
T4:lexi Esli tEmlik tEbi bErENgE yapriKi
词对齐:1-1 2-0 3-2 3-3 4-4 5-5 5-6
首先进行汉语单语实例的比较,然后再选取对应译文部分,其中*表示变量部分,可以是单词或短语、<>内表示候选项,()内表示此单词出现次数。
1.S1与S2比较—>乐事(1)*薯片(1)
2.S1与S3比较—>乐事(2)*天然(1)薯片(2)
3.S1与S4比较—>乐事(3)*天然(2)薯片(3)
4.S2与S3比较—>乐事(4)*天然(3)薯片(4)
5.S2与S4比较—>乐事(5)*薯片(5)
6.S3与S4比较—>乐事(6)*天然(4)薯片(6)
对结果进行比较,“乐事”和“薯片”在6次比较中都重复出现6次,我们把它作为固定项。“天然”出现4次,小于比较次数6,而大于比较次数的一半,我们把它作为候选项。得出单语模板后,再去目标语言中选取对应部分,按照其语言规范,作为目标模板。
最终得出模板为:
SP=乐事 *<天然>薯片
TP=lexi*<tEbix>bErENgE yapriKi
2 模板的匹配
2.1建立模板索引
为提高模板匹配速度,解决模板冲突等问题[5],我们建立了模板索引。其中选取汉语商品类别作为关键字。在进行模板匹配之前,首先按照商品类别索引,查找模板大概位置,这样可以缩小模板查找范围。
2.2模板匹配
模板匹配算法主要由三个部分组成:第一部分是根据输入商品名的分词结果中的类别去筛选翻译模板,检索出和当前输入的商品类别相同的翻译模板;第二部分是判断翻译模板的框架同输入商品名结构是否能够匹配,并且将各个槽对应的片段保存,通过查字典翻译来完成;第三部分是根据翻译模板的其他参数选择最佳的翻译模板。
例:([乐事][u4e00-u9fa5]*[薯片])+$
对于同时存在多个模板可以匹配的情况,我们需要从中进行舍去。衡量翻译模板的优劣有以下几个指标:
●汉语模板框架上词语个数 WordCount
●汉语模板槽的个数 SoltCount
●模板匹配成功的实例个数 SuccessMatchCount
●模板翻译正确的实例个数 SuccessTransCount
如果汉语模板上的固定词语越多,越接近一个真实的例子,其翻译结果越可靠;汉语模板槽越多,越抽象,其翻译结果越不可靠;第三项与第四项的比值就是翻译正确率[6]。根据以上参数,我们规定模板的可信度为:
Credibility=(WordCount/SoltCount)×(SuccessTransCount/ SuccessMatchCount)
对于候选项的翻译,我们将其取一个初值为0布尔值,如果翻译实例中存在候选项,则将其置为1,显示候选项的翻译结果。模板匹配算法如下:
输入:待翻译的商品实体名Si输出:可信度最高的翻译模板


其中,Matched Template表示可匹配的模板集合,函数Seg对目标语言分词,函数GetLastWordSeg是得到分词结果中最后一个词语,按照商品结构特点,最后一个单词一般为商品类别,我们把它作为索引Index。函数Select Template按照索引Index去模板库中查找模板。Match对查找出的模板一一进行比较,返回匹配的模板;函数Sort是按照模板匹配可信度进行排序。对于无法与模板进行匹配的商品名,我们利用基于规则的方法进行翻译。
3 实验结果分析
本次实验所用的实验语料来源于本实验室加工处理的汉维平行语料库。语料库中,我们选取可以和老维语进行无歧义转换的拉丁维文和简体中文,这样可以加快处理速度,方便计算机进行存储处理的[7]。模板抽取试验中分别利用传统的TTL方法和我们改进的TTL方法进行抽取实验对比。实验结果表明,经过类聚操作后,改进的TTL方法抽取到的模板数量减少了。这是因为此种方法由于互相比较的实例数量较多,一个模板的抽取综合了多个实例的结构与特点,使得抽取出的模板概括能力和泛化能力有所增强,可减少下一步的模板匹配的工作量。
为验证模板质量,我们利用抽取到的模板进行翻译实验,对翻译的结果进行了人工测试,并统计了翻译的正确率。我们将本系统和一个基于规则的商品名翻译系统进行对比。实验中使用了2000个商品名对,用1600个商品名称对进行抽取模板和翻译训练,选取剩下400个商品名进行开放测试,再从训练使用的1600个商品名中随机抽取400个进行了封闭测试。实验结果如表1。

表1 实验结果
实验结果表明,本文的汉维翻译系统在正确率上已达到了中等水平,它所使用的模板数量还有待提高。
实验结果中错误产生的原因主要有两方面:其一是无法与模板库匹配的商品名的翻译词序结构不合理;其二是一些在数据库中不存在的新商标、新品牌等未登录词的翻译,结果不理想。
4 结语
本文提出了一种改进的基于模板的商品命名实体机器翻译方法,这种方法能够合理地综合基于规则和基于例子的翻译系统的优点。改进的TTL模板抽取方法,使得模板质量和模板匹配效率有所提高。初步的实验结果表明,虽然在提高模板组合翻译质量和对未登录词翻译方面还面临很多困难,但该系统还是取得了比较满意的效果。同时此方法还可应用到地名、机构名的翻译。
[1]林贤明,李堂秋,史晓东.基于模板的机器翻译系统中模板库的自动构建技术[J].计算机应用,2004,24(9):133~135
[2]胡日勒,宗成庆,徐波.基于统计学习的机器翻译模板自动获取方法[J].中文信息学,2005,19(6):0001~0006
[3]骆凯,李森,强静,乌达巴拉.基于统计和模板的双层汉蒙翻译研究[J].计算机应用,2009,29(7):2026~2031
[4]吕学强,任飞亮,黄志丹,姚天顺.句子相似模型和最相似句子查找算法[J].东北大学学报,2003,24(6):531~534
[5]李玉鉴.基于索引模板匹配替换通用算法的机器翻译[J].计算机应用研究,2004(5):54~57
[6]张健.基于实例的机器翻译的泛化方法研究[D].北京:中国科学院计算机技术研究所,2001
[7]吐尔根·依布拉音,袁保社.新疆少数民族语言文字信息处理研究与应用[J].中文信息学报,2011,25(6)149~156
Machine Translation;Template;Commodity Named Entity
Research on Chinese-Uighur Commodity Named Entity Translation Based on Template
WANG Jing-ya,YUAN Bao-she
(College of Information Science and Engineering,Xinjiang University,Urumqi 830046)
1007-1423(2015)08-0034-04
10.3969/j.issn.1007-1423.2015.08.008
王静雅(1990-),女,新疆乌鲁木齐人,硕士研究生,研究方向为少数民族语言处理
2014-12-11
2015-02-10
结合商品命名实体自身结构的特点,提出一种基于模板的产品名命名实体的翻译方法。该方法在传统模板中包含的固定项和可变项的基础上,添加候选项。首次把TTL模板抽取算法应用于“汉语-维吾尔语”,并加以改进。实验结果表明模板中候选部分的添加可大大减少模板的数量,提高模板的泛化能力和翻译质量。
机器翻译;模板;商品命名实体
袁保社(1955-),男,新疆库尔勒人,本科,教授,研究方向为中文信息处理
Combined with the structure characteristics of the commodity named entities,puts forward a kind of commodity named entity translation method based on template.The method in traditional template contains fixed and variable,on the basis of adding the candidate items.For the first time,puts the TTL template extraction algorithm applied in"Chinese-Uighur",and improves it.The experimental results express that adding a candidate in the template can greatly reduce the number of templates and improve the generalization ability and the quality of translation templates.
