基于Mahout的新用户推荐算法的设计与实现*
2015-09-22高献卫师智斌
高献卫,师智斌
(中北大学计算机与控制工程学院,山西 太原 030051)
基于Mahout的新用户推荐算法的设计与实现*
高献卫,师智斌
(中北大学计算机与控制工程学院,山西 太原 030051)
为了解决大数据背景下新用户因没有历史数据而导致推荐难和推荐效率低等问题,提出将基于Mahout的协同过滤算法与基于Map Reduce的Top N算法相结合的技术方法,来实现新用户推荐算法,从而构建新用户推荐系统的架构,并对Hadoop Top N算法以及Mahout中协同过滤算法进行设计与实现。理论分析和实验验证表明,该新用户推荐算法在推荐效率、对大规模数据处理的伸缩性以及推荐质量上都明显优于单独使用协同过滤算法的新用户推荐。
新用户推荐;Mahout;推荐系统;Hadoop;大数据
1 引言
随着Internet和IT(Information Technology),特别是社交网络SNS(Social Networking Services)、电子商务E-commerce和基于位置的服务LBS(Location Based Services)的快速发展,以及云物移大智(云计算、物联网、移动互联网和智慧城市)等新概念和新技术的出现,数据增长的速度很快。用户获取信息很困难,从而引起“信息过载”问题。有许多网络应用(如门户网站,百度、谷歌等搜索引擎),追根究底是帮助用户过滤无用信息。然而,这些所谓的工具,只能满足非个性化的需求,对于个性化需求却无法满足。所以,作为“个性化服务”[1,2]的一个分支——推荐系统[3~6],通 过分析“用户-项目”之间的二元关系,帮助用户找到感兴趣的项目。目前,推荐系统有了巨大的进步,应用在电子商务、信息检索、移动应用、电子旅游、网络广告等方面。
同时,由于数据来源的多样性(互联网日志、传感器数据和移动互联网等)和数据种类的繁多(结构化、半结构化和非结构化等),推荐系统数据的存储和并行计算经受了严重的考验。困扰人们多年的大数据存储和并行计算问题,在Hadoop分布式计算框架出现后,得到了有效的解决。
然而,实现推荐系统算法是一件很费力的事情,Mahout的出现解决了这个问题。Mahout是Apache Software Foundation旗下的顶级开源项目,它由Lucene衍生而来,同时也是基于Hadoop框架的,主要包含数据挖掘、机器学习、推荐系统等若干算法库,旨在帮助开发人员更加方便快捷地开发智能应用程序。
国内外主要的传统推荐系统的算法都是基于历史数据进行推荐,国内外主要采用的方法有三种:一是协同过滤推荐方法[5],发现新异兴趣,不依赖于领域知识,但是却依赖于历史数据。二是新用户标签推荐方法[7],个性化标签间接地反映用户的兴趣,然而却存在伸缩性、稀疏性和冷启动等典型的问题。三是协同过滤和小世界模型新用户推荐方法[8],使得新用户能够找到与自己更类似的群组,然而在算法的融合上,推荐质量和效果不是很明显。而且很少推荐系统是基于Mahout实现的。
本文创新地结合了Top N算法和协同过滤算法,推出了基于大数据量的新用户推荐算法,从而解决了新用户推荐难、效率不高、推荐不匹配等问题。并通过约会对象推荐系统来验证了其有效性和伸缩性。
2 相关技术介绍
2.1 主要推荐算法
推荐算法主要包括[9]:协同过滤推荐(Collaborative Filtering Recommendation)、基于内容的推荐(Content-Based Recommendation)、基于知识的推荐(Knowledge-based Recommendation)和混合推荐(Hybrid Recommendation)。其优缺点综合比较[10]见表1。
2.2 分布式与存储技术——Hadoop
Google发布的关于分布式基础设施的论文对业界产生了巨大的影响,其中的Map Reduce和GFS(Google File System)等思想为分布式计算与存储提供了关键参考,Hadoop是其开源实现。
Hadoop[11]平台具有高可伸缩、低成本、高可靠、方便易用等特点、其核心是HDFS(Hadoop Distribute File System)分布式文件系统和Map Reduce框架。前者使得在成本可控的情况下处理海量数据成为可能;后者则是一种采用分治策略、专为大规模分布式并行数据处理设计的简化编程模型,它借鉴了函数式编程的思想,将针对大规模数据的处理任务统一地抽象为 Map(映射)和Reduce(规约)两种操作。由于Hadoop集群可以按需横向动态扩展,利用Hadoop平台可以突破数据规模给推荐系统带来的大数据分析的瓶颈,满足高性能、高伸缩性计算的需求。

Table 1 Comparison of main recommendation algorithms表1 主要推荐算法的比较
2.3 机器学习算法——Mahout
Apache Mahout[12]是ASF(Apache Software Foundation)开发的一个全新的开源项目,其主要目标是创建一些可伸缩的机器学习算法,供开发人员在Apache的许可下免费使用。Mahout包含许多实现,包括集群、分类、CF(Collaborative Filtering)和进化程序。此外,通过使用Apache Hadoop库,Mahout可以有效地扩展到云中。
用Mahout来构建推荐系统,是一件既简单又困难的事情。简单是因为 Mahout完整地封装了“协同过滤”算法,并实现了并行化,提供非常简单的API接口;困难是因为我们不了解算法细节,很难根据业务的场景进行算法配置和调优。常用的使用Mahout实现的算法有:基于用户的协同过滤
算法UserCF、基于物品的协同过滤算法ItemCF、SlopeOne算法、KNN Linear interpolation itembased推荐算法、SVD推荐算法和Tree Clusterbased推荐算法等。
3 协同过滤算法与Top N算法相结合的新用户推荐系统
新用户推荐必须具备的三元素是:新用户A、推荐对象B和评价模式C。
3.1 名称解释
名称1(Top N算法)使用直接排序法或者Hash Table法找出最高(低)的集合。
名称2(新用户A)作为推荐的受益者,是被推荐对象。
名称3(推荐对象B)是推荐的对象,该对象被推荐给新用户A。
名称4(评价模式C)是新用户A对推荐对象B的评分。
3.2 新用户推荐算法思想
综合使用Top N和协同过滤算法来对新用户做推荐。其算法思想如下:
分析原始数据,使用Top N算法求出N个推荐对象B的ID,得到基础数据“Top基础数据D”;分析原始数据,使用协同过滤算法,计算出推荐对象B的信息,得到基础数据“推荐基础数据E”;新用户A对“Top基础数据D”进行相关评价,并记录该评价模式“评价模式C”;利用该“评价模式C”对“推荐基础数据E”进行筛选,找出“推荐基础数据E”中的评价模式和“评价模式C”相似的数据“筛选数据E”;对“筛选数据E”,使用Top N算法得到的结果即为新用户推荐算法的结果。
其算法过程如图1所示。

Figure 1 Process chart of the recommendation algorithm for new users图1 新用户推荐算法过程图
3.3 系统设计与实现
如图2所示,系统采用JSP+Spring MVC+ MyBatis+Spring框架开发,采用Hadoop云平台的HDFS文件系统和MySQL数据库来存储数据。原始数据直接存入 HDFS中,计算出来的用户档案推荐基础数据存入MySQL数据库。
3.3.1系统流程图
如图3所示,在登录的时候设置进入门槛,这样只有系统管理人员才能进入监控界面。只有进入监控界面才能正常地调用新用户推荐算法的执行。

Figure 2 System development framework图2 系统开发架构图
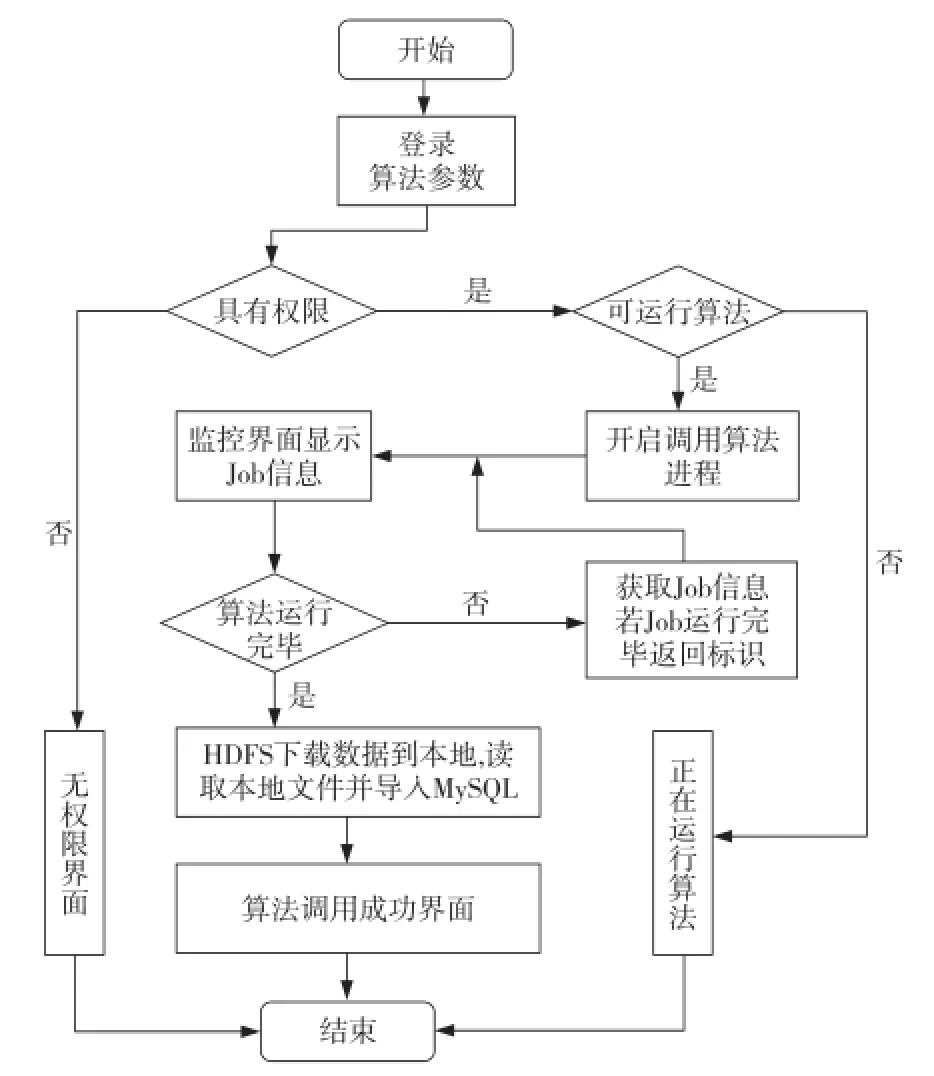
Figure 3 System flowchart图3 系统流程图
3.3.2 算法设计与实现
(1)Top N算法设计。
Hadoop top N算法是统计所有档案中的平均用户评分最大的前N个项目,也就是说,需要针对原始用户数据,求得每个项目的平均用户评分,然后把这些项目按照用户评分从大到小的顺序排列,取前N个项目。
首先分析一下Top N算法的Map Reduce流程。输入数据的格式是:[userId,profileId,pref Value],其中user Id是不需要的,需要的只是profile Id和与之对应的pref Value,同时需要记录每个项目已经被多少个用户评价过,这样方便项目的平均评分。Mapper的输入输出数据格式见表2。

Table 2 Input and output format of Mapper表2 Mapper输入输出格式
①Mapper阶段。
Mapper把[user Id,profile Id,pref Value]这样的数据经过转换,输出
接着是Combiner。Combiner主要是在Map端工作,可以先整合一部分数据,这样传输到reduce端的数据就会减少,提高效率。Combiner把所有key相同也就是profile Id是同一个的评分、次数都分别加起来,输出的
②Reduce阶段。
Reduce的主要工作就是计算每个档案的平均评分,然后对所有的项目按照评分从大到小进行排序,最后取前N(N取10)个档案ID即可。
(2)Mahout中协同过滤算法设计。
Mahout中协同过滤推荐实现的组件图如图4所示。

Figure 4 Component diagram implemented by the collaborative filtering recommendation in Mahout图4 Mahout中协同过滤推荐实现的组件图
Mahout最经典的三种协同过滤的推荐策略:User CF、Item CF和Slope One。本文中约会对象推荐系统中使用Mahout的Item CF算法来获取推荐的基础数据。
基于Mahout实现Item CF:
Data Model model=new Eile Data Model(new Eile(“preferences.dat“));
ItemSimilarity similarity=new PearsonCorrelation-Similarity(model);
Recommender recommender=new Generic ItemBased Recommender(model,similarity);
(3)新用户推荐算法设计。
算法最开始运行的是Mapper,在Mapper的初始化中也就是setup函数中,需要先读出用户对Top 10档案的评分,把这些数据读入到一个向量userPrefs中。接着在map函数中针对每一条记录数据求其与向量userPrefs的相似度similarity,然后输出用户ID和相似度similarity即可。相似度的计算公式如下:
similarity=(1/(1+sqrt(v1,v2)))(1)
其中,sqrt(v1,v2)表示向量v1和向量v2的均方差。
考虑到后面Reduce中需要对所有的数据都进行统一处理,这里Mapper输出的key必须保持一致,这里设置输出的key是new IntWritable(1)。
Mapper输出数据后,Reduce把key相同的值都整合起来,统一处理(由于Mapper输出的key都是一样的,因此这里的数据是全部数据)。在Mapper中输出的value格式是自定义的Writable类型。
在Reduce端的过程其实和前面Top10算法维护的一个10个元素的堆栈类似,只是堆栈中Map元素的key是用户ID而已。在算法结束后,在HDFS文件系统上就可以得到和新用户推荐的约会对象档案ID信息。
4 实验与分析
通过实现推荐约会的系统来验证新用户推荐系统的有效性和面对大数据的伸缩性。系统中使用的数据在http:∥w ww.occamslab.com/petricek/data/中下载。这份数据是135 359个匿名用户对168 791个其他用户档案信息的评分数据。数据格式:[1,133,8],表示用户1对133档案的评分是8分(10分满分)。
环境配置如表3和表4所示。

Table 3 Hardware configuration表3 硬件配置
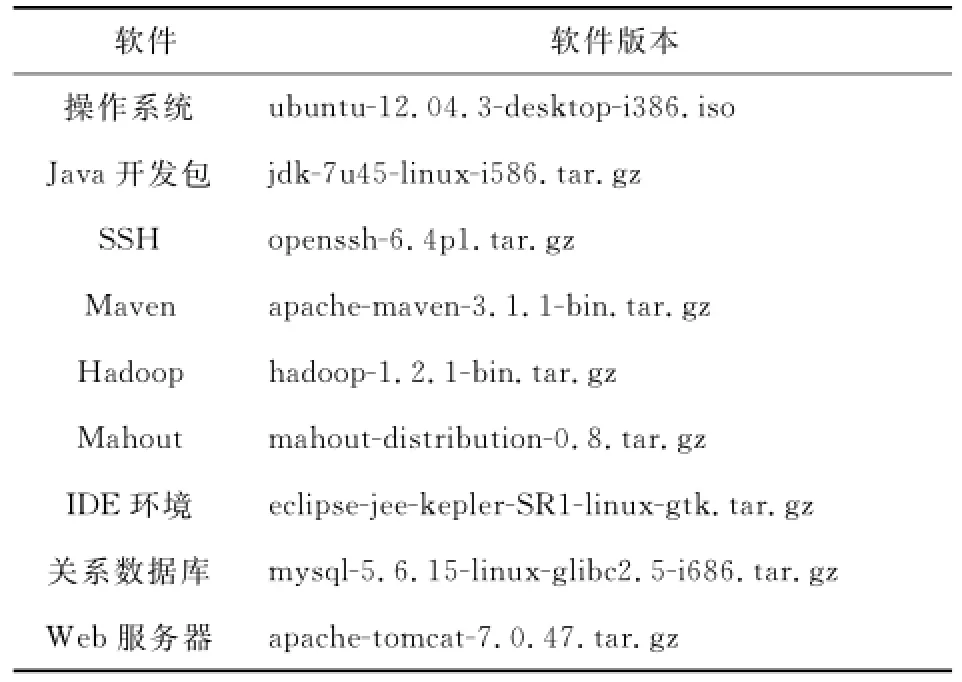
Table 4 Software configuration表4 软件配置
5 推荐效果评估
本文对新用户推荐算法进行性能分析和实验测试。分别从性能评估和推荐质量评估两个方面进 行 分 析[13]。
首先性能评估主要从执行效率方面考虑。采用参数f=T1/Tn作比较。T1是Task Tracker节点为1时算法的执行时间,Tn是Task Tracker节点为n时算法的执行时间。通过比较f参数可以得出 Hadoop节点数量对算法执行效率的影响状况。
从实验结果图5和图6可以看出,对于同一数据集,增加Task Tracker节点数量,新用户推荐算法明显比只使用协同过滤推荐算法推荐效率要高。而且计算数据集越大,Hadoop集群的大小影响越明显。

Figure 5 10 MB data图5 10 MB数据
一般地,推荐质量评估方法是采用平均绝对误差MAE(Mean Absolute Error)来评价,MAE越小,推荐的质量就越高。MAE计算公式为:
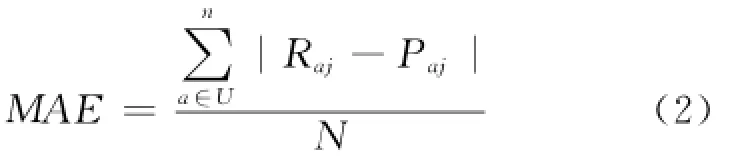
其中,N是用户所获得的推荐项目的数量,j为第1,…,N个推荐项目,a为待推荐的用户。Raj为预测值,Paj为真实值,|Raj—Paj|为绝对误差,U表示集合的全集,n为自然数。

Figure 6 100 MB data图6 100 MB数据
Mahout算法库中Recommender Evaluator就是利用MAE来评价“推荐的项目”是否与“实际情况”相符合的。但是,上面的推荐都是通过用户历史数据进行推荐的,由于新用户推荐缺乏历史数据,所以定量地进行推荐质量评估有一定困难。因此,本文主要从定性的角度分析推荐质量评估问题。
同时,还对新用户推荐算法Map Reduce前后做“加速比”的对比。其加速比S=Tm/T1,其中Tm表示“新用户推荐算法”在不同节点数量的集群上所需要运行的时间;T1表示不需要Map Reduce化的“新用户推荐算法”运行所需的时间。我们测试了集群数量为一个节点、二个节点、四个节点和八个节点的情况,如图7所示。
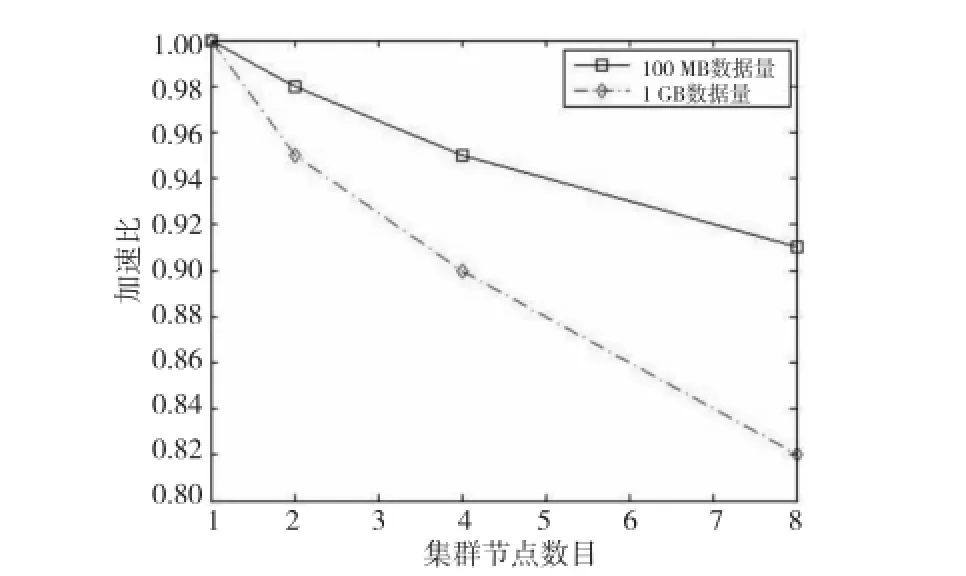
Figure 7 Performance comparison of the speedup图7 加速比性能比较结果
由图7可知,利用Hadoop集群,可以很好地提高算法的执行效率。尤其是数据量大的时候,加速比减小的幅度比较大。所以,在数据量比较大的时候,使用Map Reduce实现新用户推荐算法性能比较好。
单独使用协同过滤推荐算法对新用户进行推荐。从结果看出,可以发现潜在的但自己尚未发现的兴趣偏好,也可以被推荐和自己类似的兴趣爱好。但是,毕竟是类似的兴趣爱好,有的时候推荐数量过多,从而推荐质量跟不上去。而新用户推荐算法,以自己的兴趣爱好为导向,加上整合协同过滤的相似度概念,从而推荐出的兴趣爱好都是自己喜欢的兴趣爱好,而且在数量上得到了精选。这就是新用户推荐算法的魅力所在。
6 结束语
本文利用 Mahout中内置的协同过滤算法和基于Map Reduce实现的Top N算法进行“混合”来实现新用户推荐算法。构建了一个新用户推荐模型,并通过开发推荐约会对象系统来验证新用户推荐系统的有效性和面对大规模数据的伸缩性。由于Mahout是一个可伸缩的机器学习算法库,而Hadoop可以通过Map Reduce实现对大数据集的分布式并行计算处理,使Hadoop和Mahout可以快速开发出,数据处理能力强、功能全的企业级推荐系统。通过推荐约会对象系统,能很好地为新用户推荐,有一定的准确度和可行性。将来,会对算法进行优化,使得准确度更高。
[1] Zeng Chun,Xing Chun-xiao,Zhou Li-zhu.A survey of personalization technology[J].Journal of Software,2002,13 (10):1952-1961.(in Chinese)
[2] Adomavicius G,Tuzhilin A.Personalization technologies:A process-oriented perspective[J].Communications of the ACM,2005,48(10):83-90.
[3] Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:A survey of the state-of-the-art and possible extensions[J].IEEE Transactions on Knowledge and Data Engineering(TKDE),2005,17(6):734-749.
[4] Ricci F,Rokach L,Shapira B,et al.Recommender systems Handbook[M].Berlin:Springer-Verlag,2011.
[5] Xu Hai-ling,Wu Xiao,Li Xiao-dong,et al.Comparison study of Internet recommendation system[J].Journal of Software,2009,20(2):350-362.(in Chinese)
[6] Liu Jian-guo,Zhou Tao,Wang Bing-hong.Personalized recommender systems:A survey of the state-of-the-art[J].Chinese Journal of Progress in Natural Science,2009,19(1):1-15.(in Chinese)
[7] Liao Zhi-fang,Wang Chao-qun,Li Xiao-qing,et al.Recommendation algorithm of label recommendation of tensor decomposition and new user label[J].Journal of Chinese Computer Systems,2013,34(11):2472-2476.(in Chinese)
[8] Hu Zhu-qing,Liu Si-si,Liu Chen-guang,et al.Exploration on the combination of new user issues with small world network of collaborative filtering system[J].Silicon Valley,2012(8):191.(in Chinese)
[9] Wang Li-cai,Meng Xiang-wu,Zhang Yu-jie.Context-aware recommender system[J].Journal of Software,2012,23(1):1-20.(in Chinese)
[10] Li Wen-hai,Xu Shu-ren.Design and implementation of E-commerce recommender system based on Hadoop[J].Computer Engineering and Design,2014,35(1):130-143.(in Chinese)
[11] Yang Zhi-wen,Liu Bo.Collaborative filtering recommendation algorithm based on Hadoop platform[J].Computer System Application,2013,22(7):108-112.(in Chinese)
[12] Zhu Qian,Qian Li.Analysis and design of mahout-based recommender system[J].Bulletin of Science and Technology,2013,29(6):35-36.(in Chinese)
[13] Feng Guo-he,Huang Jia-xing.Research on collaborative filtering book recommendation based on Hadoop and Mahout [J].Library and Information Service,2013,57(18):116-121.(in Chinese)
附中文参考文献:
[1] 曾春,邢春晓,周立柱.个性化服务技术综述[J].软件学报,2002,13(10):1952-1961.
[5] 许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[6] 刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[7] 廖志芳,王超群,李小庆,等.张量分解的标签推荐及新用户标签推荐算法[J].小型微型计算机系统,2013,34(11):2472-2476.
[8] 胡竹青,刘丝丝,刘晨光,等.对协同过滤系统的新用户问题与小世界网络结合的探索[J].硅谷,2012(8):191.
[9] 王立才,孟祥武,张玉洁.上下文感知推荐系统[J].软件学报,2012,23(1):1-20.
[10] 李文海,许舒人.基于Hadoop的电子商务推荐系统的设计与实现[J].计算机工程与设计,2014,35(1):130-143.
[11] 杨志文,刘波.基于Hadoop平台协同过滤推荐算法[J].计算机系统应用,2013,22(7):108-112.
[12] 朱倩,钱立.基于Mahout的推荐系统的分析与设计[J].科技通报,2013,29(6):35-36.
[13] 奉国和,黄家兴.基于Hadoop与Mahout的协同过滤图书推荐研究[J].图书情报工作,2013,51(18):116-121.

高献卫(1985),男,江苏睢宁人,硕士生,CCF会员(E200032998G),研究方向为大数据和数据挖掘。E-mail:gaoxianwei@ 126.com
GAO Xian-wei,born in 1985,MS candidate,CCF member(E200032998G),his research interests include big data,and data mining.

师智斌(1971 ),女,山西太原人,博士,副教授,研究方向为人工智能和数据挖掘。E-mail:shizb@nuc.edu.cn
SHI Zhi-bin,born in 1971,PhD,associate professor,her research interests include artificial intelligence,and data mining.
Design and implementation of a new user recommendation algorithm based on Mahout
GAO Xian-wei,SHI Zhi-bin
(School of Computer Science and Control Engineering Technology,North University of China,Taiyuan 030051,China)
Recommendation for new users in big data era is difficult and the efficiency is very low due to the lack of historical data.In order to solve these problems,we propose a new user recommendation algorithm,which combines the collaborative filtering algorithm based on the Mahout and the Top N algorithm based on the Map Reduce.We build a new user recommendation system architecture,design and implement the Hadoop Top N algorithm and the collaborative filtering algorithm in the Mahout.Theoretical analysis and experimental results show that the proposed recommendation algorithm for big data processing has better recommended efficiency,scalability and quality than the collaborative filtering algorithm.
new user recommendation;Mahout;recommendation system;Hadoop;big data
TP311
A
10.3969/j.issn.1007-130X.2015.08.005
1007-130X(2015)08-1444-06
2014-11-24;
2015-05-15
通信地址:223400江苏省淮安市涟水县翰林苑小区28号楼202室
Address:Room 202,28 Building,Hanlinyuan Community,Lianshui,Huai'an 223400,Jiangsu,P.R.China
