基于多属性决策理论的品牌排序方法实证研究
——以中国女装行业20个品牌的排名为例
2015-09-18朱明侠何继伟
周 云 朱明侠 何继伟
一、前言
品牌排序,在实务中称为品牌排行或品牌排名,意指按照一定的规则比较品牌之间的优劣或大小,并按照由大至小或由优至劣的顺序进行位次排列。由权威的机构所颁布的排行榜或品牌排名一般会具有广泛的示范作用,对其他企业的发展有深刻的影响,所以品牌排行备受关注。但遗憾的是品牌排名的现状却是丛林式的,在网络上进行简单搜索即可获知数以百计的机构从事着各行各业的品牌排名业务,大约有30家国际机构每年都进行全世界范围内的品牌排行,并定期发布。国内也有众多的机构按照各自的排序方法对国内品牌进行排行。至今,无论是学术界还是企业界,对品牌如何排名仍没有统一的认识,这些机构的排名操作方法基本是不公开或半公开,半公开的部分也仅仅局限在评估思路和评估指标的选择上,对于最为核心的排序方法,经常以核心机密为由而一笔带过,没有机构完全将其品牌排名的方法和算法公之于众,各个排行机构各执一词,没有形成一个真正意义上的、令人信服的权威。
国际品牌排名方法中较有影响力的是Interbrand排行、金融世界排行和福布斯排行,经过对这些排名的比较和分析,可以看出它们对品牌的理解不同,表现出对品牌评价的侧重也有所不同,但他们的评估思路和步骤却基本一致。符国群(1999)[1]曾撰文整理过Interbrand排序方法,该方法非核心部分基本公开,是从品牌的财务和市场角度选择与之相关的因素,并对这些因素赋以权重,建立一个模型用于预测品牌未来收益,然后将预期的收益进行贴现计算出品牌价值,品牌排行就是对品牌价值的排序,Interbrand评价法实际上是一种改进的收益现值法(夏娟,2012)[2];金融世界的排序方法是典型的财务方法,数据完全来自历史公开信息,完全独立于企业,而且不考虑企业未来发展趋势。用品牌净利润乘以品牌强度乘数的算式作为评价模型,算式计算的最后结果就是品牌的综合值,是品牌排序的唯一依据。胡智(2012)[3]对金融世界品牌评价方法进行了深入研究,认为品牌强度综合指标没有理论基础,加权计算品牌强度乘数随意性大,造成准确度偏差大;福布斯排行评价法是综合了众多因素进行的一种典型的加权方法,它以品牌声誉、管理、革新、人力资源四项基本内容对公司品牌进行综合评价,然后设置一个权重,根据这个权重为每个品牌计算一个综合值,综合值的排序就是品牌的排名,裴飞(2010)[4]认为福布斯品牌排行在某种程度上代表了品牌价值评估的软化趋势,整个方法对品牌实力和现实竞争力的关注不够。
国内品牌排名机构对品牌评价基本依据中评协发布的《资产评估准则——评估报告》,也有少数发展较早的机构开发出了自己的方法,比较有代表性的有北京名牌资产评估公司在1995年至2005年公布的“中国最有价值的品牌排行榜”,世界品牌实验室从2004年起每年公布的“中国500最具价值品牌”。北京名牌资产评估公司评估方法的基本框架和内容是不公开的,其次是品牌入选的数量在标准受到质疑后逐年减少,很多著名品牌没有入榜,而且实施的缴费评价措施都使其失去了公允性(李海,2004)[5]。世界品牌实验室排行榜的评价方法是着重于销售收入和利润等财务数据分析,运用了经济附加值法,计算品牌的现值。这一方法与Interbrand的评估思想基本雷同,不同之处就是确定的与品牌有关的因素归纳成了8个易得的财务指标,但这些指标间的独立性等问题依然存在(王成荣、李亚,2005)[6]。
其他品牌排名机构的评价方法与上述方法都是大同小异,这些排名出炉都有三个标准步骤:首先,是选择一些看起来与品牌活动有关的因素,作为评价的基本指标。其二,再设计一套权重,将这些基本指标合并在一起,形成一个综合值。其三,按照各个品牌的综合值排序,对这个排序进行评估,没有太意外的问题,就可以作为最后的排行榜公布了。
从形式上分析,品牌排名的标准步骤中若干环节存在质疑,第一个步骤是选择与品牌活动有关的因素,作为评价指标来使用。在经营中,往往不是一个工具就能形成一个结果,往往是多重原因造成一个结果。一方面与品牌有关的因素很复杂,很难理清品牌和某个因素之间的确切关系,于是评估机构都会尽可能全地找到所有与品牌有关的因素;而另一方面,这些因素之间相互重叠、并不独立,往往是因素越多,重叠就越严重,统计中称其为多重共线性,这样的变量与品牌表现的结果之间是无法建立起有效的模型。如果尽可能撇清变量间的关系,剩下的指标又非常少,使得这些因素根本就不足以描述一个品牌的表现,这就形成了一个在选择因素时,增减因素都会降低评价有效性的悖论。第二个步骤中的硬伤更是难以克服,即使按照既定的想法选取了有效的因素作为指标对品牌进行多角度的描述,但如何将这些指标合并在一起成为一个客观的综合值是非常困难的。现在的排名都是进行了一个权重的设计,且不必说权重本身是否科学的问题,只要权重稍加改变,排名即刻发生变化。而权重的设计就成为一个最受争议的环节,许多排名方法将其权威性归结为专家法,或是干脆不公开其中的加权算法细节,其实这是所有排名都无法逾越的,也是这些排名机构最不愿意提及的部分。最后一个环节,按照设计好的指标和加权方法获取了综合值,然后对综合值进行排名——这个综合值是个横截面数据,只能表示某一个时刻的数值。而品牌是个具有时效性的事物,品牌无论是价值还是影响力,都是动态的,而排序中的终值是个静态的综合值,它不能反映品牌综合值的趋势,也就无法准确计算出现值。试想,假如两个品牌在某时刻的知名度等基础指标完全相等,而变动方向正好相反,一个正在下降,而另一个正在上升,如果没有定量的趋势分析与预测,这两个品牌是无法比较的,只能勉强地认为相等。为此,第三个步骤的比较过程是非常勉强的,预设了根本无法实现的假设。
二、多属性决策理论与品牌排序的决策矩阵
针对上述品牌排名使用的评价方法中存在的问题,本论文选择多属性决策理论中对有量纲的变量进行标准化的方法予以解决。
多属性决策(Multi-attribute Decision-making),是指为了达到一定目标,在两个或两个以上的具有多个属性的可行方案中选择一个较佳方案的分析判断过程(赵建中,1985)[7]。品牌是由多个指标来描述的复杂事物,对两个品牌之间的优劣进行比较,就是对这两个品牌的多个指标进行比较。品牌排序是两个以上的品牌进行比较,相当于是进行多轮多指标的决策问题。可以说,品牌排序的制定过程是典型的多属性决策问题。
品牌的多指标是复杂的多属性表现。属性的类型也很复杂,在现有的多属性决策的属性理论中,有五类属性,即效益型、成本型、固定型、区间型和偏离型属性。为方便研究要进行简化属性,本文选择描述品牌最基本的三个基础指标知名度、认知度和美誉度为属性对象,这三个属性都属于效益型属性,越大越好(刘树林、邱菀华,1998)[8]。品牌的知名度、认知度和美誉度,是对若干个品牌进行比较时最常用的技术指标,本论文以这三个指标为主要评价指标来探析品牌排序方法。
从多属性决策的角度对品牌排序问题的理解思路可表现为如下过程。
第一步,品牌排序问题的提出。
将品牌排序问题简化为n个品牌的比较决策,表示为:
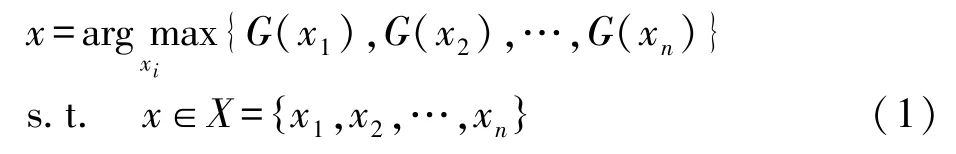
第二步,简化属性(指标)。
按照Aaker(1996)[9]对品牌的分析框架,可以将品牌的多重属性简化为对品牌的知名度、认知度和美誉度三个指标的比较决策,表示为:

式(2)中的G=(f1,f2,f3)是属性目标集,f1代表知名度,f2代表认知度,f3代表美誉度,这样j的取值仅为1,2,3。
第三步,建立决策矩阵。
令yij=fj(xi),建立品牌排序问题的多属性决策矩阵:

构建yij=fj(xi)(i=1,2,…,n;j=1,2,3),其中,j为属性编号,yij的含义是品牌xi在目标fj下的属性值,如f2(x6)表示编号为6的品牌的认知度的值。矩阵Y=(yij)n×3表示备选方案(品牌)集X关于属性目标集G的决策矩阵。
第四步,传统标准化过程。
传统方法解决这一决策问题,有两个步骤,首先需要运用极变差法(式3和式4),以及向量规范化法(式5),对矩阵Y=(yij)n×3,进行变换。
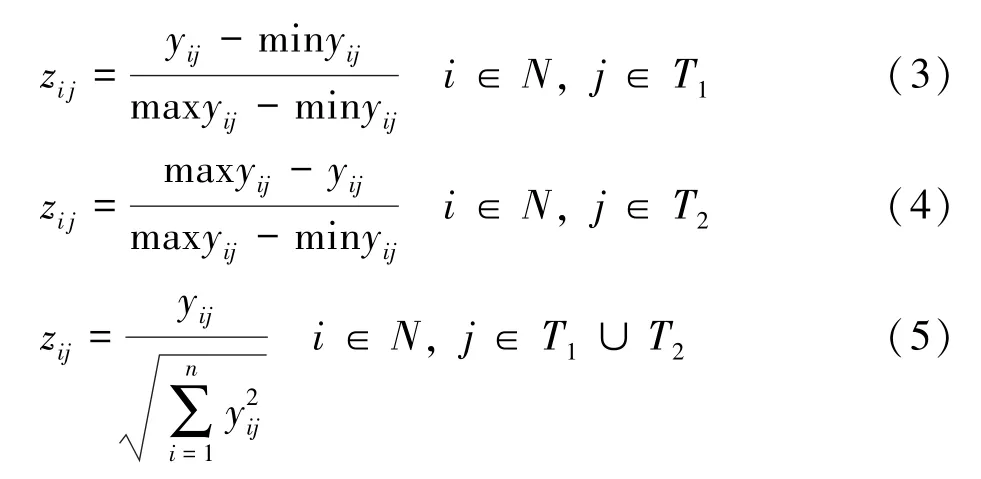
经过变换后,所有属性 (指标)都转化为无量纲的量,且各个属性的度量值在0和1之间变化,且最好结果的属性值Zij=1,最坏结果的属性值Zij=0。
第五步,构建权重集合并属性。
对目标集G=(f1,f2,f3)构建一个权重集合,Q=q(q1,q2,q3)′,构成决策矩阵为:
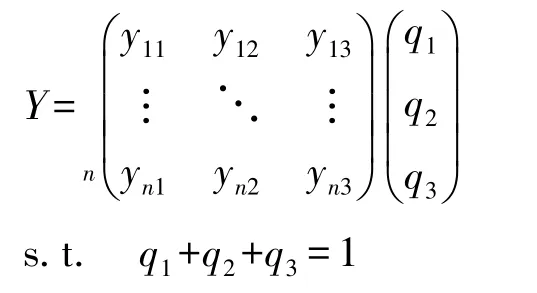
第六步,得出综合值进行比较、排序。
再通过G(xi)=q1f1(xi)+q2f2(xi)+q3f3(xi)对属性值进行合并,计算出每个G(xi)后,对各个品牌的综合值进行比较、排序。
按照多属性决策的规范化方法,对品牌排序问题的多属性规范化至此结束。然而Q=q(q1,q2,q3)′权重集合难以科学地确定,是品牌排序方法中争议最大的环节。这也是本论文所要解决的核心问题。
三、品牌排序的关键指标的标准化过程
若要回避权重集合难以科学确定的问题,唯一可行的办法就是在属性目标组中插入一个变量,能够与原属性目标组中的指标结合,转化成为有量纲的数组,使得f(xi)的关键指标合并不需要权重集合,而是按照一个科学的合并方法将数组进行合并即可,本部分就是寻找这一变量对关键指标进行转化的探索。
“今天的品牌不仅仅是一种识别标记,而且是一种现成的信息来源”(刘强,2011)[10]。依据周云(2008)[11]品牌信息本论的基本认识:品牌本质是信息,品牌的作用就是降低不确定性,品牌包含的信息量大小就是品牌能够降低交易风险的多少。周建波(2009)[12]把品牌定义为信息形态的东西,从市场信息角度解构,品牌竞争首先体现为品牌信息的竞争。消费者的购买决策取决于他对品牌信息的理解,是基于理性的决策行为 (庄爱玲,2010)[13]。使品牌努力获得知名度、认知度和美誉度,目的就是使品牌具有信息的功能,起到让消费者降低交易风险和交易成本的作用。品牌的知名度、认知度和美誉度分别代表消费者对品牌的知晓程度、认识程度和认可程度的指标,可以通过一个品牌的知名度、认知度和美誉度等指标来精确地计算其包含的品牌信息量的大小。
如能将品牌信息的基本单位变量插入算式当中,与决策矩阵的每个yij结合,可以使得这三个关键指标能够转化成一组对基本单位进行作用的变量组,只要理清其中的作用关系,即可找出合并方法和各个变量的位置,就能够得出一个品牌信息总量的求解方法,然后再计算每个品牌的信息总量大小,最终通过比较形成科学的排序。以下是按照这一逻辑对每一个阶段进行分析及转化处理,将每个维度中的关键指标换算成信息量的度量系数。
(一)品牌知名度指标向品牌信息量的转化过程
由知名度向品牌信息量的转化是使用信息量概念度量品牌的关键一步,在这一步中,品牌信息的基本单位将与品牌知名度相结合,共同组成一个公式,该公式表达了品牌获取一定的知名度相当于获取多少信息量的定量计算。
品牌知名度指受众对某品牌的知晓程度,即消费者当中有多少人知晓该品牌。它是一个总体概念,是用百分比来表达的指标。将该指标转换为信息单位的度量是将这一指标转换为某品牌信息量有效到达消费者的多少。
有关知名度的测量方式很简单,也就是品牌的公众知晓度的测算方法,通常采用问卷方式对受访者询问是否知道某品牌的名称即可。依据公式:

知名度是整个品牌度量的起点,求法也很简单可靠,只是要求在调研时一定要确保样本数据的真实有效,否则将影响整个度量的有效性。
品牌信息是一种典型的自信息,其度量公式适用自信息的度量公式,下式是信息度量的基本公式:
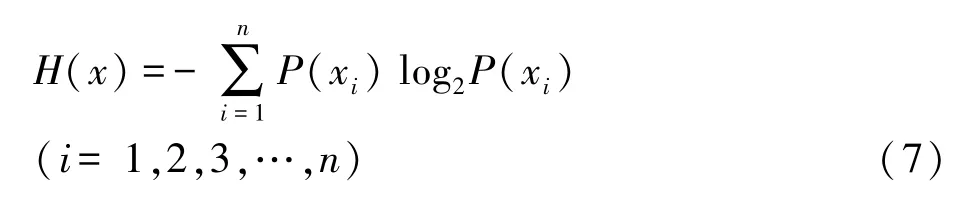
式 (7)中xi表示第i个可能出现的结果或状态 (共有n个结果或状态),P(xi)表示出现第i个结果或状态的概率,H(x)函数就是用以消除该系统不确定性所需的信息总量 (克劳德·香农,1948)[14]。
这个算式最典型的例子就是 “抛起硬币落下时是正面朝上还是反面朝上”,计算这个不确定的问题所包含的信息量,只需要知道可能出现的两种结果的概率都是0.5,即可算知H(x)=1比特,比特是信息量的单位。
品牌知名度的测算结果是无量纲的百分率,即受访者有百分之多少的人知道该品牌,品牌知名度带给消费者的信息量可以使用信息度量的公式进行计算,由式(7)可以推导出计算品牌知名度的信息量公式。
一个消费者对一个品牌的知晓与否就是一个包含1比特信息量的决策问题。犹如“抛起硬币落下时是正面朝上还是反面朝上”的结果一样,“知道和不知道”的概率相等,各占0.5,因而使用最基本的信息度量公式即可算知一个消费者对一个品牌知晓与否的信息量。按照信息量的度量公式,一个消费者对某品牌的知晓与否的信息量度量过程如下:
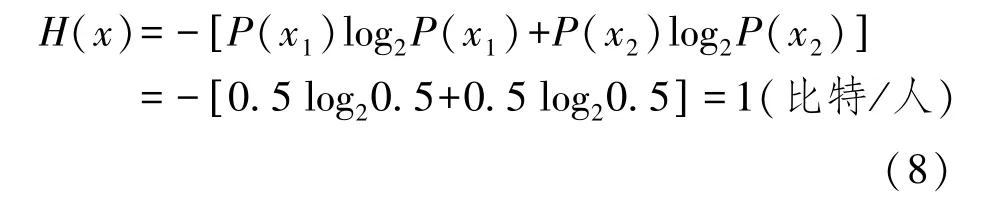
品牌信息的发出者称为品牌信息源,消费者是品牌信息接收者,信息源发出的信息量多少取决于信息的强弱、通道的干扰、信息衰减等因素。能够被消费者接收到的信息被称之为有效的信息,如下某品牌传播的信息量是从消费者角度计算有效到达接收者的信息量。这样,知名度就通过一个消费者对该品牌的选择决策信息量和调研对象总数而转化成为品牌信息量,见下式:

m1表示某品牌传播的有效信息量,单位为比特;S表示调研对象总数,单位为人;f1表示品牌知名度,无单位;H(x)表示一个消费者对该品牌的选择决策信息量,单位为比特/人。
三者的积即为该品牌信息传播有效到达消费者的总信息量。其中每位消费者包含的信息量是H(x)=1,所以,该公式可以简化为:

此时,品牌属性f1转化成了属性m1,由无量纲的百分比变成了单位比特,这一步最为关键,至此,知名度向信息量的转化过程完成。
(二)品牌认知度指标向品牌信息量的转化过程
认知度向品牌信息量的转化是第二个关键步骤。品牌认知度可以被视为受众对品牌的深度认识,在知晓的基础上,对知道某品牌名称的受众进行认知度调查,主要考察受众对品牌的深度认知情况,其考察次序为该品牌的主要产品、行销行业、logo辨识和企业价值观等。也就是说,仅仅是知道某品牌这是不够的,消费者对品牌的知道程度是不同的,比如说一个消费者只是听说过该品牌,而另一个消费者不仅知道品名,而且记得住该品牌的广告、甚至能够辨识品牌的logo,知道品牌的个性和价值观,虽然在知名度的范围内这二人的信息量是一样的,但认知程度的不同决定了他们对该品牌的信息量差异很大。
1.品牌认知度(f2)的概念。
品牌认知度的概念意指在一定知名度的情况下,消费者对品牌能够达到的认知程度。在较早的文献中也有被称作提示前提及知名度(unaided awareness)的情况,是指消费者在不借助任何提示情况下能够回忆起某品牌的比例。一般被认为:认知度是真正的知名度,受产品、广告、促销、渠道等的综合影响,可见认知度研究是知名度研究的深化。
每个知晓品牌的消费者对该品牌的认知程度存有差异,令Rmax为满信息的情况,指一个消费者对该品牌的所有信息都掌握,满信息对该消费者来说就是100%有效到达的信息量。从1到Rmax就是认知深度,将(Rmax-1)等分,用来表示其中任一消费者达到的有效认知程度,称为某消费者达到的品牌认知度,表示为r=xir%,并由此可以得到一个平均的品牌认知度。
2.品牌认知度的度量方法及公式。
认知度的调研采用复合测量法,复合测量法是运用多指标的综合结果来确定,多重指标的运用可以有效地排除干扰样本,以保证调研的有效性。在测量表的调研问卷中可以设置几个反方向的同类问题供选择,问题也不限于是否知道品牌中的产品,而是较为深入的问题,比如:“您知道某品牌的主要产品是什么?”或是“某品牌是做什么行业的企业?”是否能够辨识品牌徽标等深度不一的问题。并以此为依据将消费者对品牌的认识等额划分成段,称为品牌认知度分段问卷表。
将问题等分为由低至高的若干层次,表示消费者对该品牌认知逐次增加的过程,其中某消费者达到任意一个程度表示为r=xir%,即某消费者对一个品牌信息量的认知度(xir%),对ni个消费者所组成的目标市场进行抽样调查可以估算整个目标市场的平均认知度为Xr%,用表示。
即某品牌的品牌平均认知度的计算公式:

一般情况下,没有特别指出,品牌的平均认知度就是品牌认知度,用f2表示。
3.消费者完全知道一个品牌所传播的信息量的极值(Rmax)的求解。
每个品牌使得消费者的认知度能够达到的最大值就是一个消费者完全知道一个品牌所要传播的所有信息量,或者说一个消费者在一个具体的行业中,对其中一个品牌掌握的所有信息的量是个确定的值,它依据这个行业当中的品牌数目而定。
品牌数目确定的信息量极值是依据“在备选品牌发生概率相等时品牌信息量最大”的原则下,根据品牌所处行业中的品牌数目而确定的值。Rmax是一个消费者完全知道一个品牌所要传播的信息量的极值。依据备选品牌数目等概率发生时的信息公式而定,是认知度达到100%时的信息量。
计算公式如下:
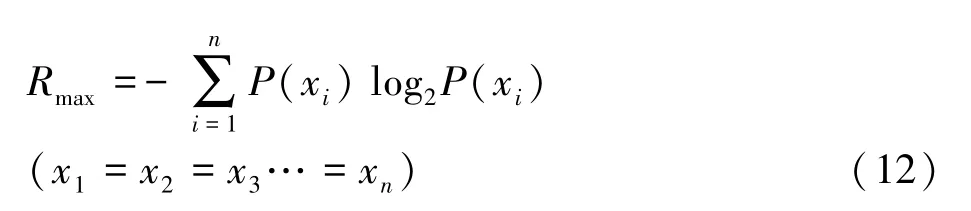
P(xi)表示消费者对第i个厂商品牌选择的概率n表示备选品牌个数。
一个消费者在一个市场上接收到的信息往往小于能够接受的最大信息量。平均认知度可以用每个消费者对品牌的选择概率来计算,也可以通过对消费者调研来获得。
4.品牌认知度向品牌信息量转化的步骤(f2→m2)。
第一步,确定认知度最大品牌信息量的极值Rmax;第二步,确定品牌认知度(f2);第三步,建立转化公式。
认知度对品牌信息量的提高作用表现在消费者对品牌信息的掌握程度上,这一部分的增量的程度用公式(Rmax-1)×品牌平均认知度来表示,其含义为在知晓品牌的消费者身上有的1比特的信息量,到他全部掌握信息时的Rmax比特的信息量,由品牌平均认知度决定了他们掌握品牌信息的现状,并由此决定了品牌信息量的多少。将该公式嵌入知名度和目标人群总数的积当中,即得到品牌的认知度转化为信息量的公式,见下式:
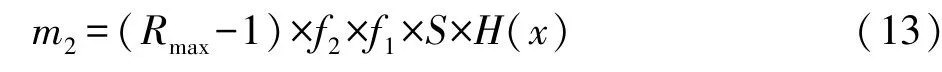
可见一个消费者所能够达到的品牌信息量的最大值,既取决于每个品牌自身的信息量大小,也取决于备选品牌的数目(或行业内竞争的状况和程度)。至此,品牌属性f2转化为m2,品牌认知度向品牌信息量的转化完成。
(三)由品牌美誉度向品牌信息量的转化过程
品牌美誉度(brand favorite):是消费者对一个品牌整体的好感和评价程度。品牌美誉度更多的是与产品自身质量和品牌形象相关,质量好、形象好的产品通常能够得到比较高的美誉度。品牌美誉度是品牌创建的关键,一个商标能否成为品牌关键就看它是否获得了相当程度的美誉度,美誉度简言之就是某品牌获得公众信任和赞许的程度。
尽管美誉度的定义是要表达一个有关消费者对某品牌的好感程度,但在对品牌的指标测算中美誉度的位置和作用却不是一个简单的百分比程度。美誉度的发生伴随的是品牌进行自我传播现象的出现,术语是品牌发生自我传播,或称自传播现象,俗称口碑。因而,品牌学界一直视品牌自传播现象的发生为品牌塑造成功的标志,这也将美誉度的度量和自传播的度量联系在一起。
在某品牌的专柜前调研准备购买的消费者,询问消费者购买此品牌产品的原因是什么,可以将可选答案设计成:受到广告的影响、价格便宜、正在搞活动、亲友推荐、自己觉着不错一直在用等,将其分为两类,去掉如广告、公关、价格等与厂商有关的影响之外,其他选项的消费者类型均可被认为是自传播动机,其所占的比率即为美誉度。

式(14)中,f3表示美誉度,[0,1];x表示发生真实购买行为的消费者样本中,购买原因与厂商无关的消费者数目;sx表示发生真实购买行为的消费者样本的消费者数目。
美誉度向品牌信息量的转化有个特殊的步骤,即美誉度通过一个系数转化而不是直接进行转化,美誉度是对品牌信息的质量进行度量的指标,具体说,它所改变的是对品牌均价的调整系数μ,该系数是个函数,用来调整品牌间的价格差异,也称品牌议价系数,等于议价能力β以Nz为底的指数,形式如下:

令P为某品牌的某产品的市场价格,表示该产品所在行业的同类产品的平均市场价格,换算成质量水平,令为该行业中同类产品的消费者让渡价值,1-γ为某品牌的消费者让渡价值,按照真实价格相等原理,整理β和μ公式得:

在某行业发生过真实购买行为的消费者(SZ)是可以通过调研确定的,对该行业消费者的较大规模样本调研可以得到消费者中受口碑影响进行消费决策的人数(Q)。二者的比例即为一个行业的平均美誉度。

消费者对品牌信息的复制并传播的量就是美誉度要表达的赞誉程度,美誉度越高的品牌这种自传播发生的量越大,而且信息源越多,信息源发出的信息量越大,复制的信息量则与之等大,该信息源对该品牌的美誉程度就越高。
首先确定的是系数μ的位置,在品牌度量基本公式中,μ代表品牌信息质量的值,在量价关系中,对价的部分起作用,不对量的部分起作用。
由此可以确定一个品牌的信息单位价格,公式如下:
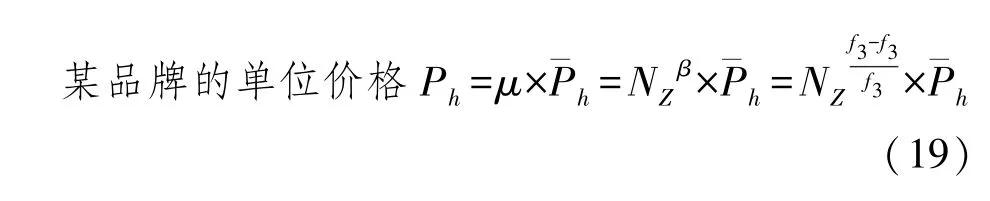
¯Ph表示一个特定行业的品牌信息的平均单位价格。
在仅仅是对品牌量进行的度量中,不会对一个行业的平均价格进行计算,因而,品牌量的度量框架里没有价的部分,但品牌量的度量是对品牌信息的度量,当然包括了信息量的度量和信息质的度量,尽管没有平均单价的问题,但平均单位价格的乘子应该在度量的框架中,因为它是品牌信息的质的反映,也是品牌度量的重要组成部分。
四、品牌关键指标的合并及计算实例
(一)知名度和认知度的合并
通过增加H(x)值,使得品牌知名度、认知度和美誉度之间有了一个共同的量纲,其中,品牌知名度转化为信息量的部分和认知度转化为信息量的部分是并列关系,二者之和成为品牌信息的基本量(J),公式如下:

要降低一个消费者对某品牌是否知晓的不确定性所需要的信息量是1比特,记作H(x)=1比特/人,因此,知名度和认知度的合并在形式上可以简化,但单位经过H(x)之后,无量纲的指标转化为信息量单位:比特。
(二)美誉度与知名度、认知度的合并
对品牌美誉度的研究中可以看出,由品牌美誉度决定的品牌信息的质量有效地表达了品牌信息的质的差异。增加系数μ后,即可进行美誉度指标与知名度、认知度指标的合并。在管理学中的美誉度一般是在知名度的基础上(丁润生,2002),[15]所以在原式和μ值位置确定的分析中可知,美誉度包含在系数μ中,与品牌信息基本量是积的关系,函数为下式:

至此,品牌最重要的三个指标:知名度、认知度、美誉度就合并在一个公式当中了。通过增加H(x)变量,将本无量纲单位的指标进行了标准化的转换,最终合并的结果是一个以比特为单位的品牌信息量。这个值表达出品牌对消费者影响力的大小,如有每个比特的单价,可以非常简单地计算出该品牌的价值或价格。
(三)构建新的属性目标集合QE=q(m1,m2,μ)′取代原属性目标集G= (f1,f2,f3)
原属性目标集G=(f1,f2,f3)在合并时必须构建一个权重集合Q=q(q1,q2,q3)′,s.t.q1+q2+q3=1,然后再通过f(xi)=q1f1(xi)+q2f2(xi)+q3f3(xi)式对属性进行合并。通过将关键指标向信息量的转化及合并步骤的研究,现在可以通过构建一个新的目标集QH(x)=q(m1,m2,μ)′取代原属性目标集G=(f1,f2,f3)′,合并时也不再需要权重集合,而是按照变量间的作用逻辑进行合并。
新的目标集为:

合并式为:

(四)案例试算
《中国连锁品牌质量发展报告》(2014)[16]安排了对国内178个连锁品牌的调研,针对7个典型城市的消费者进行了大规模的问卷调研活动,收回问卷2 553份,其中有效问卷1 775份,节选其中鄂尔多斯品牌的基础数据进行试算。
对各地的问卷进行统计,得到鄂尔多斯品牌在各地的知名度、认知度和美誉度,再通过各个调研城市所代表的各个城市级别的总人口比例换算出全国的知名度、认知度和美誉度水平。然后,再按照公式(22)将鄂尔多斯品牌的知名度、认知度和美誉度转化为信息量。统计与计算过程如下:
1.知名度计算。
调研表第一列(是否知道鄂尔多斯品牌)中选“是”的人数加总,再除以有效问卷总数,得某市的知名度;通过各城市的人口总数与全国人口数为该市知名度的比例,推算出全国的知名度。
鄂尔多斯在北京的知名度为117/170×100%=68.82%,同理在成都的知名度为:77/111×100%=69.37%,在深圳的知名度为412/775×100%=53.16%,在南昌的知名度为86.84%,在太原的知名度为74.53%等。
鄂尔多斯品牌的全国知名度为:
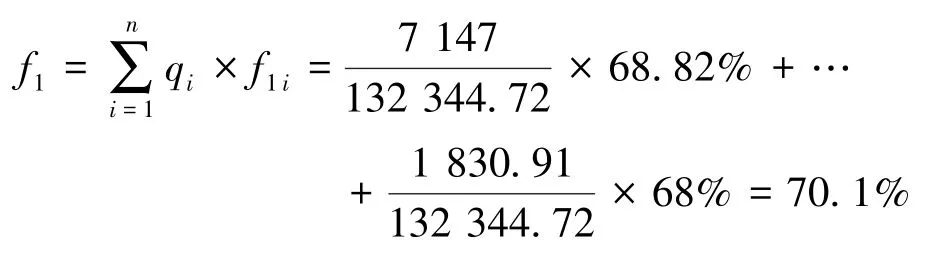
2.认知度计算。
通过(调研表第二列选择正确的人数×0.5+调研表第三列填写正确的人数×1)÷有效问卷总数,推算出某市的品牌认知度,再通过各城市的人口总数与全国人口数为该市知名度的比例,推算出全国的认知度。
鄂尔多斯品牌在北京的品牌认知度为(93×0.5+21×1)/170×100%=39.71%,在成都的品牌认知度为(75×0.5+6×1)/111×100%=39.19%,在深圳的品牌认知度为(344×0.5+7×1)/775×100%=23.10%,在南昌的认知度为28.95%,在太原的认知度为36.79%等。
鄂尔多斯品牌的全国认知度为:

3.美誉度计算。
调研表第五列有效人数的前提是第四列必选,第四列选择为0项或未选项,第五列选项无效。(调研表五列选择1项的有效人数×0.1+调研表第五列选择2项的有效人数×0.5+调研表第五列选择3项的有效人数×1)÷(调研表第四列选1和2的人数总和),得到鄂尔多斯品牌在某市的美誉度,再通过各城市的人口总数与全国人口数为该市知名度的比例,推算出全国的美誉度。
鄂尔多斯品牌在北京的美誉度为(19×0.1+13×0.5+2×1)/(31+19)×100%=20.8%,在成都的美誉度为(11×0.1+10×0.5+1×1)/(17+15)×100%=22.19%,在深圳的美誉度为(45×0.1+28×0.5+18×1)/122×100%=29.92%,以及南昌的美誉度为31.11%,太原的美誉度为14.57%等。
鄂尔多斯品牌的全国美誉度为:

4.议价系数β的计算。
参考《2014年度中国连锁品牌发展质量报告》的参数,中国女装行业的平均美誉度,鄂尔多斯品牌的全国议价系数
5.与美誉度有关的价格调整系数μ的计算。
参考《品牌信息本论》[17]附件C品牌价格调整系数底数Nz值表,参数N34=1.058 4,得到鄂尔多斯品牌全国的μ=1.058 40.2281=1.013 0。
6.合并计算鄂尔多斯品牌在全国的品牌信息总量。
Qe=(132 344.72×0.701+132 344.72×0.701×0.333 8×5.042)×1.013 0=252 149.393 61(万比特)
7.数据汇总。
汇总上述计算结果,各项基础指标和换算结果汇总在表1鄂尔多斯品牌的数据汇总表中。
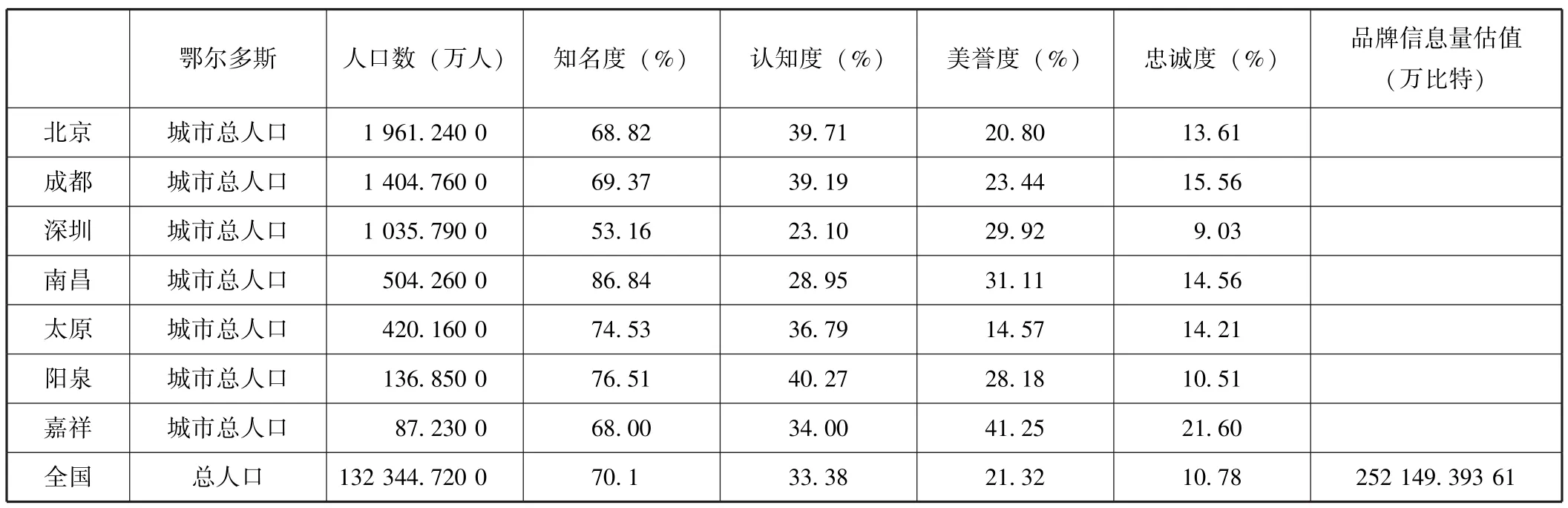
表1 鄂尔多斯品牌的数据汇总表
五、品牌排序应用范例
多属性决策理论对于属性标准化和统一量纲的要求是非常严格的,基于信息量纲的品牌排序方法与传统的排序方法最大的区别在于该方法没有使用权重的概念,将品牌知名度、认知度、美誉度等指标联系在一起的是品牌信息的量,即品牌所包含的信息量,成为品牌间进行比较的科学依据,这是使用加权等其他方式无法替代的。
这一评估体系是以品牌基础量为单位的评估,在以信息单位为换算基础的各个指标之间被放置在一个模型中,并按照自己的规律对基础量进行调整。最终各个品牌得到的是一个值,其中强弱优劣一目了然,整个过程中,没有人为进行干预和调整的,或者模糊的加权体系,使得这一方法更加可靠、易于操作。
如下以2014年中国女装行业20个品牌的数据为例,使用品牌信息量统一量纲的多属性决策方法对其进行的排序范例。
(一)参数取值说明
根据中华全国商业信息中心的统计(2014)[18],2013年1—12月份全国重点大型零售企业女装销售前十位品牌市场综合占有率合计达到25.3%。国内的女装市场的消费调查显示:73.1%的女装终端销售通过品牌进行。相对于众多没有品牌的企业,市场份额超过0.5%以上的品牌厂商有34家,总体看,该行业市场化程度高,发展阶段成熟,竞争非常激烈,处于垄断竞争市场格局。
1.Nz值按照品牌数目取值,全国市场销售占到0.5%以上的品牌为 34个,对照Nz取值表N34=1.058 4(参见《品牌信息本论》p.158)。
2.中国18—35岁女装消费者每年平均购买服装的次数约为7.5次。
3.女装行业品牌平均美誉度为0.173 6。
4.女装行业的Rmax为5.042。
(二)排序对象及其基础指标
本次排序所涉及的女装品牌:例外、红袖、歌力思、歌莉娅、江南布衣、Jessica、太平鸟、淑女屋、影儿、欧时力、雅莹、优美世界、秋水伊人、千百惠、玛丝菲尔、鄂尔多斯、娜尔斯、朗资、太和、白领,共计20个,基础指标见表2。

表2 中国女装行业品牌基础指标汇总表 (知名度降序排列)
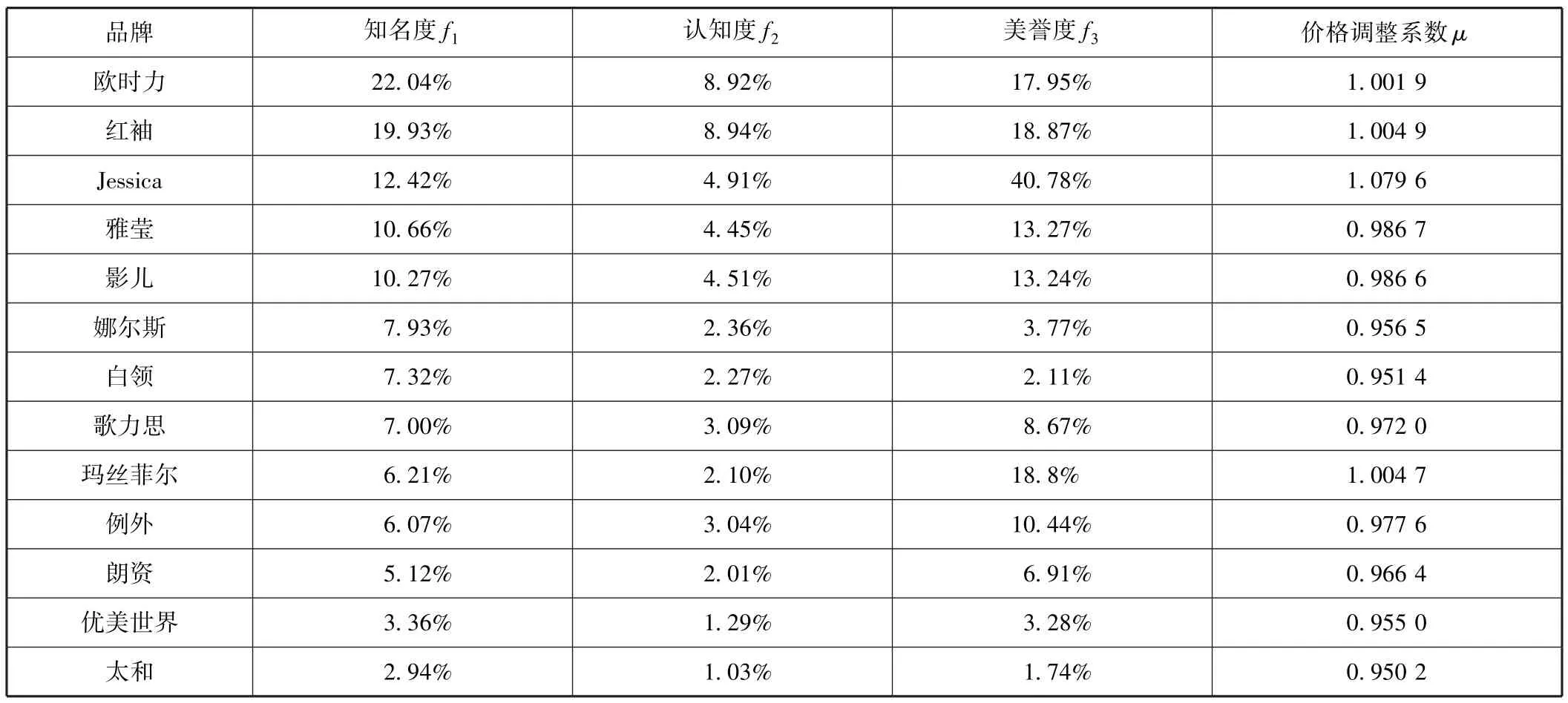
续前表
(三)基础指标的合并及品牌信息总量的计算过程
表3按照公式(22),对上表2中20个品牌的f1,f2,f3,μ指标进行的合并计算过程,计算过程的结果就是该品牌所包含的信息总量,单位是比特。
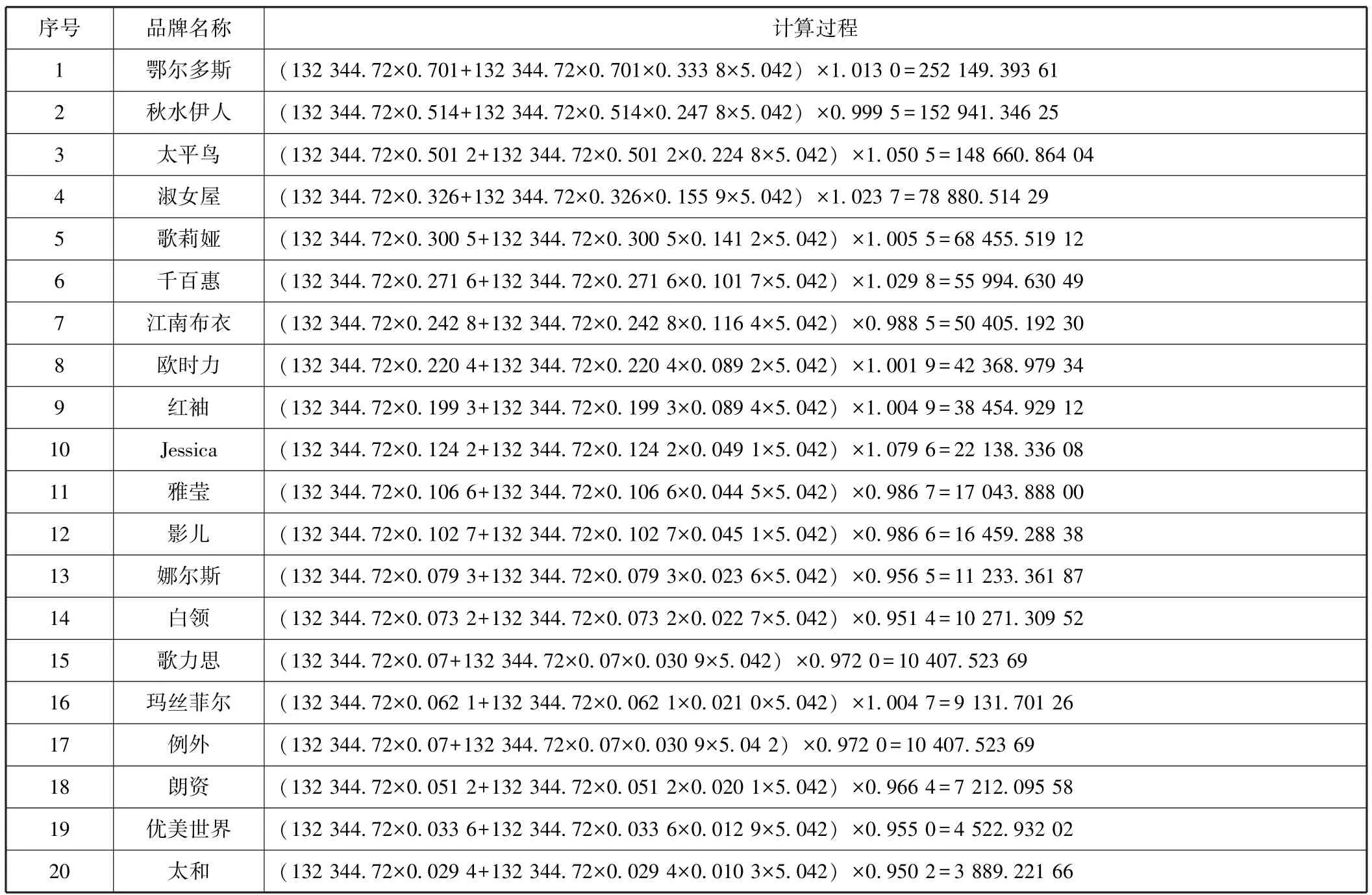
表3 中国女装行业品牌的信息量计算表
(四)排序结果
依据上述的计算结果,中国20个女装品牌的排序见下表4第一、二列,第三列是品牌信息总量。该品牌排序是依据品牌信息量的大小自上而下的顺序即品牌排序,既可以称为品牌影响力的排行,也可以称为品牌价值的排名。如下是排序结果的分析。
(五)对计算和排序结果的解释
1.排序方法的有效性。
运用多属性决策理论的品牌排序方法,能够确定鄂尔多斯品牌是这20个品牌当中影响力最大、价值最高的品牌。在其他机构的排名和评价中,鄂尔多斯也是中国纺织服装行业第一品牌,以303.26亿元的品牌价值连续十几年位居中国最有价值品牌前列。对照基于多属性决策的品牌信息量评估结果和企业自行评估的结果,二者是一致的,验证了这一排序方法是有效的。
2.其他排序结果(综合值排序和品牌价值排序)。
如以鄂尔多斯的品牌信息量为基数1.000 0,其他品牌的多属性决策综合值也能够形成,见表3第四列;如以鄂尔多斯303.26亿元的品牌价值[19]为基数,其他品牌的品牌价值排行也能形成,见表3第五列。品牌信息的价格是比较容易获得的,如在餐饮行业中高盛出资30亿元收购小肥羊品牌,30亿就是小肥羊品牌此时的品牌价格,如有小肥羊品牌的信息总量,二者之比即为餐饮行业品牌信息的单位价格,据此,即可对该行业所有品牌进行定价。
3.该排行精确比较了指标值非常接近的品牌间的差距。
如表5列示,秋水伊人和太平鸟品牌的基础指标相差很小,综合值分别是0.606 6和0.589 6。秋水伊人品牌的知名度和认知度略高于太平鸟品牌,而太平鸟品牌的美誉度又高于秋水伊人,很难通过权重方法或定性分析得出结论。而通过属性的转化,二者在品牌信息量上的细小差别就能够准确地计算出来,信息总量仅仅差2.9%,可以准确地做出秋水伊人品牌的价值略大于太平鸟品牌的结论。

表5 秋水伊人品牌与太平鸟品牌的比较表
4.指标不同的品牌可以达到价值相同。
如表6列示马尔菲斯品牌与例外品牌的比较,二者知名度几乎相当,例外品牌的认知度高于马尔菲斯44.76%,马尔菲斯的美誉度又高于例外80%,指标显著不同,说明这两个品牌追求的目标和发展路径也大不相同,例外品牌显然重视消费者对品牌的深度认知,属于小众发展路径(卞志刚,2013)[20]。而马尔菲斯更看重品牌的口碑,强调消费者对品牌和产品的赞誉(周姚,2014)[21]。但经过品牌信息量的推算,可知二者的品牌信息总量非常接近,决策综合值仅相差0.000 3。表现出在指标并不相同的情况下,两个品牌能够达到同样的效果。

表6 马尔菲斯品牌与例外品牌的比较表
这一例证说明:获得相同的品牌资产价值的品牌并不一定要相同的指标,通过不同途径形成的品牌状态对消费者的影响力可以是相同的。所以,品牌管理应该强调创新,而不是对标管理。
六、结束语
品牌排序对品牌管理有着重要的影响,一个排名在前的企业往往会成为一个行业其他企业模仿和学习的榜样,归纳起来至少有两个方面是非常重要的。其一,品牌排行对企业发展方向的影响很大。排名会引导一大批企业朝着一个方向发展,尤其是对一些采取对标管理方法的企业,排名的导向性非常明显。通过品牌排名可以清楚地告知其他企业,什么样的企业能够成为榜上有名的优秀企业,什么样的品牌算是数一数二的品牌。其二,对政府制定促进品牌发展的政策有影响。我国政府现阶段对企业品牌建设是非常重视的,相关部门制定了许多政策支持企业创建品牌。在制定这些扶持政策时,依靠的参考依据中,当然会包括国际排名和排名机构对品牌的评价方法,一个行业的评价标准对该行业的发展起着至关重要的作用。若品牌排序方法是有其他目的的,它的目的就会渗透在标准当中,使得该行业的发展按照既定的目的进行,这是非常危险的。一个科学的品牌排序,应该能够给品牌管理与决策提供最为可靠的参考依据。
品牌排序方法至今仍是个争议很大的研究领域,本论文通过增加信息量纲的方法解决了排序中多属性标准化难题,能够规避传统排序方法中最有争议的加权值问题,从实证的结果来看,这一方法是可行的。在没有品牌信息的单位价格时,品牌价值的确定只能参考交易的结果,获知的是品牌价格。然而品牌排序是不受价格影响的,品牌排行或品牌排名是可以运用信息量变量进行多属性比较的,而且数据易得,操作和计算都容易掌握。
