基于显著性检验和因子分析的企业财务危机预警研究
2015-09-17南京理工大学泰州科技学院江苏泰州225300
(南京理工大学泰州科技学院 江苏泰州225300)
一、引言
经济环境的复杂化和竞争的白热化,使得企业经营面临巨大风险和不确定性从而导致财务危机。财务危机预警可预知财务危机发生的征兆,其有效性和准确性的提高有助于企业及时发现导致财务状况恶化的原因,及早应对。准确有效的预警除了对企业管理层起到警示作用外,还能助投资者做出有利的投资决策,便于债权人控制信贷风险,利于证券等监督部门的监管。迄今,理论界已发展出诸如多元判别模型、多元逻辑回归模型和神经网络模型等多种模型来研究财务危机预警,但受制于多元判别模型和逻辑回归模型需要众多假设条件,神经网络模型建模复杂、其运作原理无法明确等问题,这些模型的适用性受到极大限制,鉴于此,本文选择无假设要求且原理简单的因子分析模型对财务危机预警进行研究。
二、文献回顾
20世纪30年代,国外已开始对财务危机预警进行研究,取得了一定的成果并广泛应用于实际。而国内学者对财务危机预警模型的研究起步较晚,始于20世纪80年代末。总体来说,国内外财务危机预警模型的研究进展可概括为:从单变量分析模型到多变量分析模型,从统计分析方法到基于人工智能的机器学习分析方法。
Beaver(1966)首建了单变量财务危机预警模型,使用30个财务比率进行了对比研究,结果表明,资产负债率、资产收益率和现金流量/负债总额这3个财务比率预测财务危机是有效的,其中现金流量/总负债这一财务比率预测财务失败效果最好。Altman(1968)首用多变量分析进行了财务危机预警研究,并提出了判断企业破产的临界值,这种方法用多个财务指标加权汇总后产生的总判断分值(称为Z值)来预测财务危机。周首华等(1996)对Altman的Z分数模型进行了改善,将现金流量指标加入预警机制中从而建立了F分数模型。吴世农和卢贤义分别采用判别分析和logistic回归方法建立和估计了预警模型,并比较了各种方法的预测效果。随着数据挖掘技术的日渐成熟,开始有学者使用神经网络研究财务危机预警,Odom和 Sharda(1990)将人工神经网络模型应用在破产预测模式中,用人工神经网络预测财务危机的新方法,他们选用Altman选取的5个财务比率,设置5个隐藏节点,建立了神经网络预警模型,发现使用神经网络的方法对公司财务危机的预测率高于基于统计的方法。我国学者杨淑娥、黄礼等通过改变隐含层个数等方式对模型的可靠性进行了验证。
三、样本与指标的选取
(一)样本确定及分组
国内学术界和实务界对财务危机的界定各不相同,概括起来主要分为两种:其一,认为企业破产是最严重的财务危机;其二,鉴于我国资本市场的特殊性,国内大多数学者将是否被“ST”作为判断企业发生财务危机与否的标准。考虑可行性,本文也以是否被ST作为判断企业财务危机的标准,选取了2011—2012年间被ST的A股上市公司作为发生财务危机的公司样本,同时按配对样本属于同类行业且总资产规模相差在10%以内的原则,对每一家ST公司进行配对选择非ST公司,共选定50家ST公司和与之配对的50家非ST公司作为研究样本。其中,50家ST公司中,20家在2011年被宣布为ST公司,30家在2012年被宣布为ST公司。研究时,笔者把50家被ST的公司随机分成两组,一组为建模样本组,一组为检验样本组。剩下的50家非ST公司根据与其配对的ST公司的分组情况,相应分配到检验数据组和建模数据组中。这样,100家企业中就有50家(25家ST公司和25家非ST公司)公司用来建模,50家(25家ST公司和25家非ST公司)用来检验模型预测的准确性。
(二)预警指标体系的确定
在总结了前人研究及企业经营特征的基础上,本文选取了23个指标,分别囊括了企业偿债能力、营运能力、盈利能力、成长能力、现金流量状况和表外其他信息6个方面。这些变量的类别如表1所示。
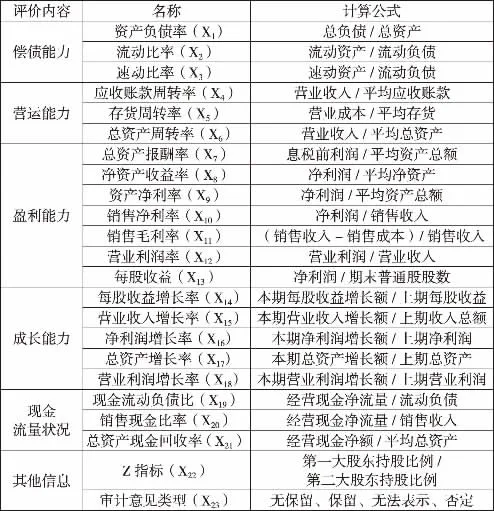
表1 财务危机预警指标体系表
(三)财务危机预警指标的筛选
为建立一个有效的财务预警模型,所选指标必须能够有效地判别财务危机企业和财务正常企业。因此,在构建模型之前,需要对所选指标进行显著性检验以剔除ST公司和非ST公司之间显著差别不高的指标。
显著性检验即事先对总体的参数或总体分布形式做出预先假设,然后利用样本信息判断该假设是否合理,即判断总体的真实情况与原假设是否有显著性差异。当样本总体符合正态分布时,一般会使用参数检验的方法;当样本总体不符合正态分布时,一般采用非参数的检验方法。在本文中,由于总体分布未知,故首先要对样本数据进行正态性检验。
1.样本数据的正态性检验——单样本K-S检验。通过SPSS 19.0对前面所选取的23个财务比率指标进行显著性水平为5%的K-S检验,结果如表2所示(其中T-1、T-2和T-3分别代表被宣布特别处理前1年、前2年和前3年)。
在显著性水平为0.05的水平下,当渐进显著性P值>0.05时,该指标符合正态分布。从表2中可以得出:T-1年只有 X6、X7、X9、X11、X15、X17、X21符合 正态分 布;T-2 年只 有X6、X7、X9、X13符合正态分布;T-3 年只有 X6符合正态分布。整体上看,三年内只有X6都符合正态分布,故指标变量整体来说并不符合正态分布。
2.样本数据的显著性检验——初次筛选。对样本数据进行显著性检验时,T检验和U检验均可用。实用时,只要检验样本含量较大(n>30)或检验样本含量较小(n〈30)但总体标准差σ已知时,即可应用u检验;当检验样本含量较小(n〈30),总体标准差σ未知时可应用T检验,但要求样本数据呈正态分布。由于所选取的指标变量在总体上不符合正态分布,且样本数较大,所以本文采用U检验来检验指标变量的显著性。

表2 K-S检验结果

表3 指标变量的U检验结果
利用收集的两组共100家上市公司的数据资料,使用SPSS 19.0统计分析软件中的两个独立样本显著性检验,对被宣布特别处理前1年、2年、3年的数据进行U检验,结果如上页表3所示。
据表3可得T-1年至T-3年指标变量显著性检验的结果:应收账款周转率(X4)、存货周转率(X5)、总资产周转率 (X6)、销售毛利率(X11)、Z 指标(X22)和审计意见类型(X23)这6个财务指标在0.05水平上没有通过显著性检验,说明该6个指标无法有效区分企业是财务失败还是财务正常,故剔除这6个指标。
3.因子分析——再次筛选。考虑中国证监会界定上市公司财务状况异常的标准一般是“连续两年亏损”,所以本文利用建模组公司T-2的数据,共50个样本,结合前文中通过显著性检验筛选出的17个指标进行因子分析,利用因子分析对这17个指标再次精简,去除重复信息。
(1)KMO检验。通常在因子分析之前,需要对原有变量之间是否存在相关关系进行研究。本文采用KMO和巴特利特检验对变量进行相关性检验。表4的检验结果显示KMO值为0.667大于0.6,表明可做因子分析;又因Bartlett球状检验的相伴概率为0.000,远小于显著性水平0.05,因此可以认为原始变量之间存在相关性,适合做因子分析。
(2)因子分析。统计方法中,可据因子载荷矩阵得出所选公因子的个数。为确定选取的公因子个数,需要计算各因子的特征值和累计贡献率。本文选取公因子时要求因子的特征值大于1。表5显示,选取5个公因子时,每个公因子的特征值都大于1,且累计贡献率达到76.74%,即这5个主成分因子包含了原来76.74%的信息量,变量信息丢失较少,因子分析的结果较为理想。为便于对这5个因子进行解释,本文使用了正交旋转法中最大方差法进行转换得到因子载荷矩阵表6。表6显示:因子Z1中,财务比率X10、X12的因子载荷量都大于90%,而这2个财务比率是反映企业盈利能力的指标,故将Z1命名为盈利能力因子;因子Z2中,财务比率X14、X18的因子载荷量远大于其他财务比率的因子载荷量,而X14、X18是反映企业成长能力的指标,故将Z2命名为成长能力因子;因子Z3中,财务比率X2、X3的因子载荷量都大于90%,远大于其他财务比率的因子载荷量,而X2、X3是反映企业偿债能力的指标,故将Z3命名为偿债能力因子;在因子Z4中,财务比率X19、X21的因子载荷量远大于其他财务比率的因子载荷量,而X19、X21分别反映企业现金流量的指标,故将Z4命名为现金能力因子;在因子Z5中,财务比率X7、X17的因子载荷量大于其他财务比率的因子载荷量,而X7、X17分别反映企业盈利和成长能力的指标,故将Z5命名为综合能力因子。

表4 KMO和Bartlett的检验
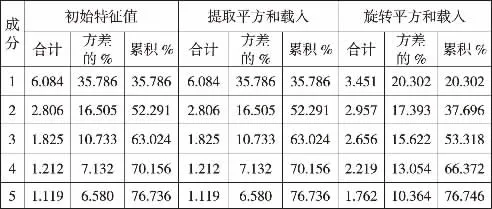
表5 解释的总方差
根据表6旋转平方和载入方差值和表7各公因子得分系数,确定财务危机预警函数为:
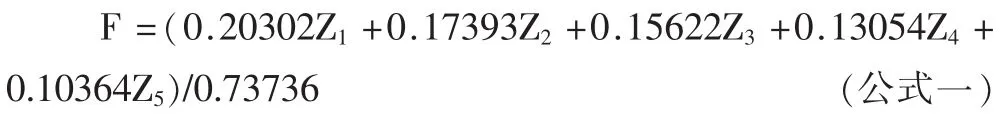
四、财务危机预测值的确定及预警模型的检验
(一)财务危机预测值的确定
将建模组共50个样本的数据带入公式一中,得到各企业综合财务风险预测值F,根据F值的高低排列企业,结果见表 8。

表6 旋转后的因子载荷矩阵
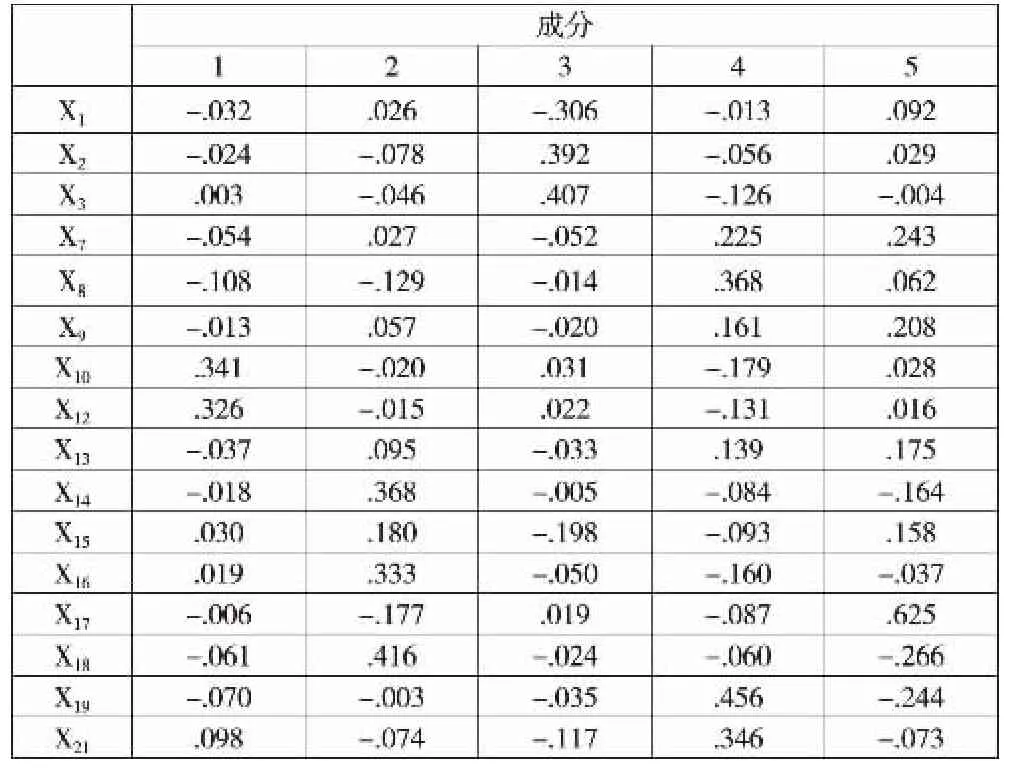
表7 成分得分系数矩阵
根据表8中各预测值F和确保最小错误率的原则,选定ST企业和非ST的最佳分割点,本文中称该分割点为风险临界值PS。通过分析可看出,这个分割点在-0.08和0.02之间时,误判率最小,故本文选择这两个数值的平均数作为风险临界值,即PS为-0.03。
据前文,距被宣布特别处理前两年财务预警的因子分析模型为:
F=(0.20302Z1+0.17393Z2+0.15622Z3+0.13054Z4+0.10364Z5)/0.76736
若 F≥PS,则2年后该企业为非 ST企业;若 F〈PS,则 2年后该企业为ST企业。

表8 建模数据的综合得分排序
(二)预警模型的检验
为检验PS临界值-0.03在预测财务危机方面的准确性,本文把距被宣布特别处理前两年(即T-2年)的检验组样本数据(共50个样本)带入因子分析模型,即公式一中,得到检验组样本各公司F值,根据F值的高低排列企业,结果见表9。
根据建模样本组确定的风险临界值PS=-0.03,被宣布特别处理前两年的检测组公司样本数据F值计算结果表明:50家企业里有45家预测正确,预测错误的为华电能源、莲花味精、金健米业、*ST新农、*ST南纺这五家,预测正确率达90%。因此,公司被宣布特别处理前两年,该财务风险预警模型具有较好的预测能力。

表9 检验数据的综合得分排序
五、结论
本文选取2011—2012年间A股上市公司中被ST的50家公司和与其配对的50家非ST的公司作为研究样本,以被ST前三年的数据作为样本数据,使用U检验严格筛选出17个财务指标作为指标变量,对上市公司前两年的数据运用因子分析对指标体系进行再次筛选,构建了财务危机预警模型。研究结果显示:公司被宣布特别处理前两年预测的正确率高达90%,达到了较好的预测效果。
