基于主成分回归的区域物流需求预测研究
——以云南省为例
2015-09-13彭湖何民嘉兴市规划设计研究院有限公司浙江嘉兴34050昆明理工大学交通工程学院云南昆明650500
彭湖,何民(.嘉兴市规划设计研究院有限公司,浙江嘉兴34050;.昆明理工大学交通工程学院,云南昆明650500)
基于主成分回归的区域物流需求预测研究
——以云南省为例
彭湖1,何民2
(1.嘉兴市规划设计研究院有限公司,浙江嘉兴314050;2.昆明理工大学交通工程学院,云南昆明650500)
为了能够给区域物流发展政策的制定、物流基础设施建设规模的确定、物流市场态势的分析等提供定量的物流需求规模数据,建立科学合理的预测模型显得尤为重要。首先,研究区域物流与区域经济的关系;其次,从货运量、货运周转量两个指标中选取货运周转量来表征区域物流需求规模;最后,从区域经济指标中选取第一产业总产值、第二产业总产值、第三产业总产值、社会消费品零售总额、固定资产投资额、进出口额等指标作为影响因素,借助SPSS统计分析软件,以云南省统计数据为基础,建立基于主成分回归方法的区域物流需求预测模型。研究结果表明,该模型在对云南省物流需求规模进行预测时,模型平均相对误差小于4%,预测精度高,可以作为中短期物流需求预测的工具。
区域物流;物流需求;货运周转量;主成分回归;中短期
0 引言
区域物流需求预测不但是区域物流系统规划的主要依据,而且是物流企业定位、发展方向及相关基础设施建设规模等规划的条件和前提,因此,对区域物流系统的需求规模进行预测意义重大。目前,国内学者建立的预测模型主要有时间序列模型[1-3]和因果模型[4-6](回归模型)。时间序列模型仅把时间当作预测目标的影响因素,无法揭示区域物流与区域经济各因素之间的内在联系。许多文章中只是采用简单的一元回归建立预测模型[7],解释力度有限。部分学者虽然考虑到区域经济中一些因素对区域物流需求的影响,但是最终的多元回归模型中因变量与自变量之间存在负相关,不符合常理;或是各个自变量之间存在严重的多重共线性[8-10],造成解释信息的重叠。本文在充分吸取前人各类模型优点的基础上,采用主成分回归[11-13]预测方法,从区域经济指标体系中提取尽可能多且与区域物流需求总量相关性较强的经济指标作为模型自变量,这样一方面避免了时间序列模型不能揭示区域物流需求总量与区域经济的内在关系的问题,另一方面避免了一元回归模型在解释区域物流需求总量与区域经济关系上力度不足的问题,最后通过检验的主成分回归模型还剔除了各经济指标间的信息重叠以及区域物流需求总量与各经济指标间存在的不合理的负相关等。由于模型所选取的指标均来自统计年鉴,具有较好的历史传承性和可持续性,只要从区域层面能够搜集到相关的统计数据,本文所采用构建模型的方法就能够适用该区域的物流需求预测。
1 区域物流需求的经济影响因素分析
影响区域物流需求的因素很多,但从宏观上考虑包括三大部分:一是区域经济总量水平,二是区域产业结构因素,三是区域经济分布状况。这些因素在宏观上共同决定着区域物流需求总量、物流需求层次、物流需求功能以及物流需求结构等方面。
(1)从根本上说,区域经济发展的整体水平和规模是区域物流需求的决定性因素,也是区域物流需求的源动力。从系统理论角度看,区域物流系统作为整个社会系统的子系统,它必然受到来自于区域内外部经济环境的影响和制约,区域物流需求量的多寡与区域内部及其周边地区经济的景气与衰退也紧密相关。
(2)区域产业结构是另一个影响区域物流需求的重要因素。产业结构的差异将对物流需求功能、物流层次以及物流需求结构等方面产生重大影响。产业结构不仅在量上影响物流需求,还在更高层次上对其施加影响。产业结构的调整和转变不仅意味着粗放型社会经济的增长方式的终结和集约型社会经济增长方式的诞生,更重要的是它带动了物流需求向着更高层次、结构和高附加值的方向发展。
(3)资源分布不均、区域经济发展不平衡而导致的区域经济空间布局,是客观上产生物流需求的最直接原因。由于资源和区域经济空间分布不均匀而造成的物流需求现象是普遍存在的,而且随着这种不均衡的程度增加,对区域内和区域间的物流需求的压力也越大。
2 区域物流需求指标选取
2.1 需求规模指标选取
目前,度量区域物流需求的指标体系主要有数量形态体系(货物周转量、货运量、社会物流总额等)和质量形态体系(物流成本、物流效率等)。由于在我国还没有完整物流方面的统计数据,质量形态体系的预测只能依靠专家的经验,这必然在很大程度上造成了误差。考虑到数据的可获得性和预测结果的准确性,有必要对物流需求进行量化研究,因此本文初步采用数量形态指标体系中的货运量或货运周转量来表征物流需求,具体选取二者中的哪一个作为最终的指标,还需下一步讨论。
一般来说,区域经济总量越大、发展越快,其物流产业发展也越迅速。因此,本文对货运量、货运周转量与GDP进行相关性分析,哪个指标与GDP的相关系数越大,证明该指标与区域经济的关系越密切,则最终被选取作为区域物流需求规模的指标[14]。
2.2 区域经济指标选取
选取区域经济指标要遵循以下三大原则:①强相关性原则:选取的经济指标要与区域物流之间存在较强的相关性;②全面性原则:在条件许可的情况下,应该尽可能多和全面地选取体现区域经济发展水平的指标;③实用性原则:指标的选取应该考虑实施过程中的可操作性,其中包括指标数据的可获得性和数据的准确性。
本文从以下几个方面来进行经济预测指标的选取:①区域经济总量指标:国内生产总值(GDP);②区域产业结构指标:第一产业总产值、第二产业总产值、第三产业总产值;③区域贸易指标:区域内零售总额、区域进出口总额、固定资产投资额;④区域消费:居民消费、政府消费。
3 主成分回归数学模型
主成分回归就是建立在主成分分析的基础之上,利用原自变量的主成分代替原自变量与标准化的因变量做回归分析。
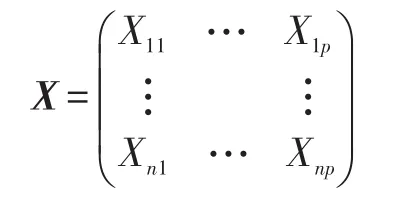
设观测样本矩阵为:
(1)对原始数据进行标准化处理,即:
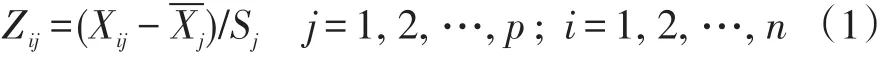
(2)计算样本矩阵的相关系数矩阵R:

(3)对应于相关系数矩阵R,用雅克比方法求特征方程||R-λI=0的p个非负的特征值,λ1≥λ2≥…≥λp≥0对应于特征值λi的相应特征向量为并且满足
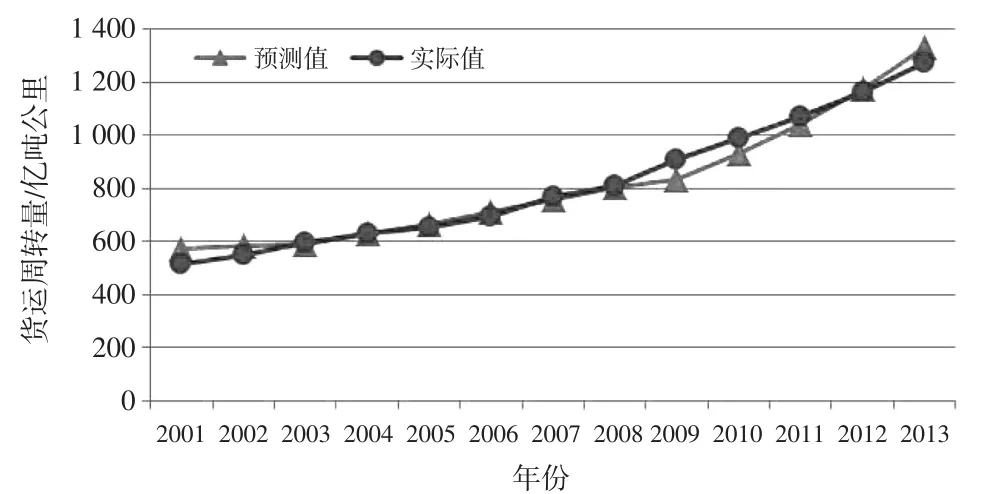
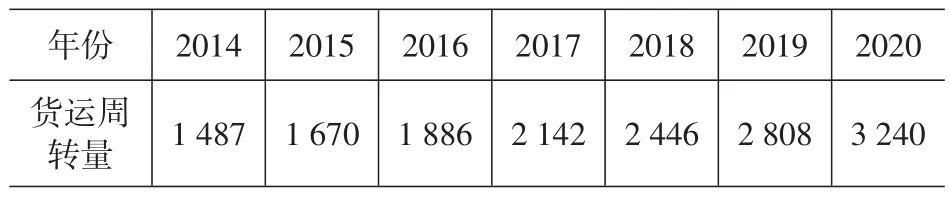
(4)选择m(m (5)利用标准化的因变量Zy同m个主分量Z1,Z2,…,Zm(m 式中:a′为常量为常系数。 (6)将回归方程进行逆标准化处理,即: 得出最终的回归模型: 式中:a为常量;b1,b2,…,bp为常系数。 (7)进行模型检验,常用的方法是利用多重决定系数R2检验拟合优度。 多重决定系数的定义为: 由于R2与回归方程中解释变量的数目有关,当回归方程中的解释变量增加时,R2不可能减少,因此,人们通常用修正的决定系数Rˉ2来拟定优度: 式中:n为样本容量;k为模型中回归系数的个数。 4.1 模型指标的确立 本例选取了2001—2013年云南省的GDP、货运量、货运周转量统计数据[15]进行相关性分析,借助SPSS软件计算得到货运周转量与GDP的相关系数为0.995,大于货运量与GDP的相关系数,根据1.1节中的分析,最终确定货运周转量作为物流需求规模指标。 按照1、2节中选取区域经济指标的原则,本文选取了9个区域经济指标作为模型的自变量,分别是第一产业总产值(X1)、第二产业总产值(X2)、第三产业总产值(X3)、社会消费品零售总额(X4)、固定资产投资额(X5)、进口额(X6)、出口额(X7)、居民消费(X8)、政府消费(X9),具体数据如表1所示。区域经济发展的整体水平和规模是区域物流需求的决定性因素,产业结构不仅在量上影响物流需求,还在更高层次上对其施加影响。为了避免区域经济总量(GDP)和三大产业各产值在解释区域物流需求与区域经济的关系上存在的信息重叠,且三大产业各产值亦能组合成区域经济总量,因此本次模型构建舍弃了区域经济总量指标。三大产业产值充分考虑了云南省产业结构以及经济规模大小对物流需求规模的影响;由于商业流通物流也是区域物流需求的重要组成部分,因此将社会消费品零售总额、进出口总额、居民消费、政府消费4个指标选入模型;另外固定资产投资的不断增加,不但能够促进经济社会的发展,同时也大大加快了区域物流产值的增加,因此本文也将固定资产投资额选入模型。 4.2 物流需求预测 4.2.1 多重共线性诊断 以表1中数据为例,利用SPSS统计软件并采用向后(Backward)回归法选择自变量,结果只有X5被选入模型,其他变量均被排除,因此模型的经济解释力度明显不足。被排除变量的方差膨胀因子(VIF)值均大于10,为了将影响物流需求规模的其他变量加入模型,又可以消除自变量间信息的相互重叠,特引入主成分回归方法进行预测[14]。 表1 云南省2001—2013年货运周转量及相关因素数据 4.2.2 模型求解 (1)求主成分表达式 对以上9个自变量进行主成分分析,利用SPSS统计软件,得出主成分统计信息如表2所示,从表中可以看出,大于1的特征根仅有1个,因此得出主成分为Z1,它的方差累积贡献率为98.605%,可以看出该个主成分基本可以描述经济发展的水平。主成分表达式如下: 表2 特征根、贡献率及累积贡献率 (2)进行回归分析 将主成分Z1跟标准化变量Zy做回归分析,得出回归方程为: 将式(7)代入式(8),得出式(9): (3)模型还原 根据式(3)对式(9)中的自变量进行逆标准化,得出回归模型如下: (4)模型检验 根据式(6)得出模型的Rˉ2=0.972,说明模型具有极高的拟合优度,可以用来作为预测的工具。 利用主成分回归预测模型得出的云南省近13年货运周转量预测结果如表3所示,实际值与预测值对比曲线如图1所示。 表3 2001—2013年云南省货运周转量预测值(单位:亿吨公里) 表3 (续) 图1 实际值与预测值对比曲线 从表3和图1可以看出,近13年实际值与预测非常接近,平均相对误差仅为3.5%,最低为0%,充分说明模型的预测精度非常高。 (5)模型应用 由上文可知,模型已经满足自身建模数据的检验,可以作为区域物流需求规模预测的工具,预测的云南省近中期货运周转量如表4所示。 表4 云南省近中期货运周转量预测值(单位:亿吨公里) 本文以云南省数据为例,采用主成分回归方法构建了云南省物流需求预测模型。通过实例验证,模型平均相对误差小于4%,精度非常高。该模型不但充分体现了区域物流与区域经济间存在的内在联系,而且说明了模型指标选取的合理性。但是由于模型中经济指标相对较多,远期预测容易产生不稳定因素,模型可靠性难以保障,因此,该模型适用于中短期区域物流预测,并具有较高的应用价值。同时由于模型所选取的指标均来自统计年鉴,数据获取方便,一旦研究区域发生变化,该模型同样具有较好的移植性和适应性。但是如果研究范围扩大到国家地理分区层面,要对该级别区域的物流需求总量进行预测,就会面临缺乏统一的区域物流统计资料的情况,从而给预测带来困难。因此,如何对国家地理分区层面的物流需求总量进行科学合理的预测,有待下一步进行深入研究和探讨。 [1]李秀林,苏国强,兰月新.基于时间序列分析的节气性火灾分析与预测[J].廊坊师范学院学报:自然科学版,2012,12(6):5-6. [2]朱睿,张俊中,龙洋,等.时间序列模型在建筑物沉降监测中的应用[J].测绘与空间地理信息,2012,35(2):213-216. [3]刘寒冰,李国恒,谭国金,等.基于时间序列的边坡位移实时预测方法[J].吉林大学学报:工学版,2012,42(S1):193-197. [4]李磊,刘学,刘洁.江苏省生活废水排放量的多元非线性回归预测[J].经济数学,2012,29(1):90-93. [5]孙翔,王景成.基于回归模型的城市长期水量预测[J].微型电脑应用,2010,26(11):7-9. [6]张玉良.打括隧道监控量测结果的一元非线性回归分析[J].广西工学院学报,2007,18(2):54-57. [7]于忠霞,李家伟.组合预测法在成都公路物流需求预测中的应用[J].中国储运,2008(3):103-105. [8]王瑶华.中国农村居民旅游消费的多元线性回归分析[J].企业技术开发,2011,30(15):100-102. [9]宋树仁,李玲,韩景元.中国居民收入差距影响因素的计量分析——基于多元回归模型[J].河北科技大学学报:社会科学版,2010,10(1):1-5. [10]许国琼.多元线性回归模型预测重庆市用水量[J].供水技术,2010,4(4):27-29. [11]姜信君,佟瑞洲.大气污染主成分回归预报模型及试报分析[J].辽宁大学学报:自然科学版,2010,37(2):183-185. [12]邱红霞.基于主成分回归的阿克苏市城市需水量预测[J].地下水,2010,32(2):97-99. [13]李磊,肖光年.基于主成分回归的无锡碳排放量影响因素分析[J].城市发展研究,2011(5):9-12. [14]彭湖.基于组合预测的区域物流需求预测研究[D].昆明:昆明理工大学,2009. [15]云南省统计局.2014云南省统计年鉴[M].北京:中国统计出版社,2014. Regional Logistics Demand Forecasting Based on Principal Component Regression:Taking Yunnan Province as an Example PENG Hu1,HE Min2 In order to provide the quantitative scale data of the regional logistics demand for making the regional logistics development policies,determining the logistics infrastructure construction scale,analyzing logistics market situation and so on,the establishment of scientific and reasonable prediction mod⁃el is particularly important.Firstly,the relationship between regional logistics and regional economy was studied.Secondly,the freight turnover quantity was selected from the freight quantity and the freight turnover quantity to characterize the regional logistics demand scale.Finally,primary industry value, secondary industry value,tertiary industry value,total retail sales of consumer goods,fixed asset investment volume,value of export and import etc.,were selected from regional economy indexes to be as influencing factors.Based on statistical data of Yunnan Province,using SPSS statistical analysis software,the region logistics demand forecasting model based on principal component regression method was established.The research confirmed that the model for forecasting the logistics demand scale of Yunnan Province,the average relative error of the model is less than 4%,the model has higher prediction accuracy and can be used as medium and short term logistics demand forecasting tool. region logistics;logistics demand;freight turnover quantity;principal component regression;medium and short term U492.3 A 2095-9931(2015)03-0060-06 10.16503/j.cnki.2095-9931.2015.03.011 2015-03-18 国务院亚洲区域合作基金(0200802004) 彭湖(1982—),男,湖南衡阳人,工程师,硕士,研究方向为交通规划和交通仿真。 E-mail:123810414@qq.com。



4 云南省物流需求预测实例


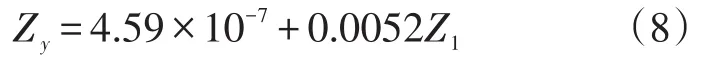

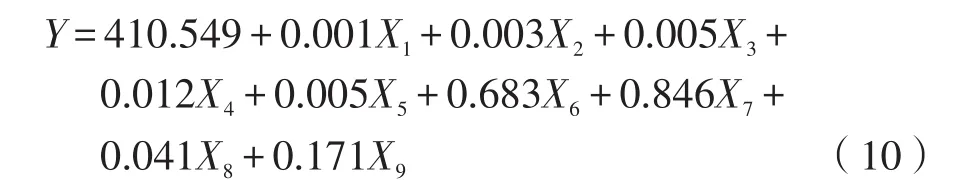


5 结语
(1.Jiaxing Planning&Research Institute Co.,Ltd.,Jiaxing 314050,China;2.Faculty of Transportation Engineering,Kunming University of Science&Technology,Kunming 650500,China)
