从汉语看音系区别特征值的不对称
2015-09-10胡公博
胡公博



摘 要: 根据标记理论,同一语法参数(parameter)内不同选值(value)之间的关系并不是均等的,这种不对称不仅体现在语言结构中,而且见于语言使用频率上。Clements (2005)在跨语言对比音系的基础上提出了十四对区别特征值的标记关系,得到了全球部分语言的语料统计数据支持,然而其信度需要更多的语种验证。本文在分析汉语语音系统结构的基础上,利用汉语口语语料库,对Clements提出的每一对标记关系予以检验。研究表明,汉语的音位构成及语料中汉语音位的频率分布支持Clements标记关系中的十三对,区别特征值的不对等性在汉语中得到充分体现。
关键词: 标记理论 区别特征 语料库
1.引言
作为语言类型学的核心理论,标记理论指出,同一语法参数内的不同选值间存在系统性的不对称,也就是说,选值的标记性(markedness)有强弱之分。标记性的强弱有三个指标:蕴含共性、行为潜势和使用频率。比如在元音的鼻音性这个参数上有两个选值:一个元音要么是鼻腔音(即[+鼻音性]),要么是口腔音(即[-鼻音性])。跨语言对比发现一个语言普遍性:一个语言若有鼻腔元音,那么就有口腔元音;但是一个语言若有口腔元音,却不一定有鼻腔元音(Croft,2003:57)。这一语言共性(称“蕴含共性”)表明口腔音和鼻腔音地位是不对等的,我们说口腔音的标记性弱于鼻腔音,这一标记关系记作:口腔音<鼻腔音。同时,在世界语言的音位系统中,口腔元音数目几乎总是大于鼻腔元音,即口腔元音行为潜势大于鼻腔元音。此外,经统计,在一个含1000个元音的法语文本样本中,口腔元音频率高于鼻腔元音,达83.7% (Greenberg,1966)。以上两点进一步表明口腔音的标记性较弱。
之所以蕴含共性、行为潜势、使用频率被称为标记性的指标,是因为人们提出的标记关系不一定能满足所有指标。一个被提出的标记关系满足的指标越多,就越可靠。Clements (2005)在蕴含共性基础上,根据跨语音位系统对比而提出14个区别特征的标记关系,它们的信度需要接受行为潜势和使用频率的检验。部分标记关系已得到Greenberg (2005)考察诸种世界语言语料给出的频率方面的实证支持,然而涉及的语种数目有限,统计方法亦有不足。因此,本研究旨在透过分析汉语音位系统和汉语语料,检验Clements的标记关系,并对统计分析频率的方法作出改善。以类型学视角审视汉语音系的研究多数局限于汉语方言音系系统的结构对比,以得出方言共性(Zee & Lee,2007;时秀娟,2007;叶晓锋,2011),笔者则结合语料库进行实证研究。
2.文献综述
2.1语言结构中的标记性
判断14个区别特征的标记关系时,Clements采用的标准是:如果不是所有语言都有A值音位而所有语言都有B值音位,那么B标记性弱于A。事实上,如果两个值满足这一指标,那么必然满足蕴含共性的指标:当所有语言都有B值音位时,有A值音位的语言当然都会有B值音位。根据上述标准,Clements提出如下14个强标记性特征值:
来源: Clements 2005
Greenberg (2005:21) 指出,在世界语言音位系统中,弱标记值音位数目不会少于强标记值音位,即前者行为潜势不会小于后者。如Ferguson (1963)发现,在各语言中,口腔元音数几乎总是大于鼻腔元音数,也就是说口腔元音内部对音位有更多的区分,这表明:口腔音<鼻腔音。Clements根据行为潜势方面的跨语共性提出三个强标记性特征值:
2.2语言使用中的标记性
判定标记性的标准——蕴含共性、行为潜势——都是语言结构方面的标准。Greenberg (2005:15)提出了一个语言使用方面的标准:弱标记值音位在语言真实使用中有更高的使用频率。因为频率是语言使用的重要方面,Greenberg的频率标准使语言结构与语言使用两者桥接起来,使标记理论与语言学中的使用模型兼容。使用模型认为,语言使用决定语言结构(Bybee,2006;Bybee & Hopper,2001)。
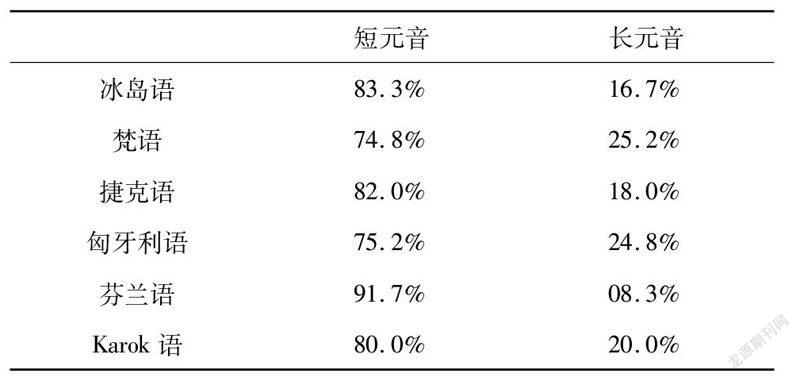
为支持他的论断,Greenberg以世界诸种语言的语料为实证证据。比如验证元音长和短的标记关系时,他搜集了冰岛语、梵语、捷克语、匈牙利语、芬兰语、Karok语六种语言的书面语语料,各语料含1000个元音音位;然后他亲自人手统计长元音和短元音在语料中的出现频次,再转成百分率。所得结果如下:
来源: Greenberg 2005:20
Greenberg的论证方法不无欠缺。一是语料不够大,只含1000个音位。二是语料都是书面语而非口语。两种语体有多方面差异(Brown & Yule,1983:15-17),而口语更能反映语言的使用情况(Croft,2003:112)。三是统计所得频率差异的显著性并未进行统计学检验。四是考察的语言太少,在地理距离和谱系亲疏上不够离散,难以代表世界上的所有语言。Haspelmath (2005)指,分析更多世界语言样本的实证研究要有待开展。因此,笔者承继这样的实证研究,考察汉语语料,验证Clements提出的14个标记关系 ,并试图改良数据统计和分析的方法。
3.研究方法
3.1汉语音位
在对汉语各个音位进行频率统计前需要确定汉语音位包括哪些。笔者大体上认同Duanmu(2007:24)提出的汉语音位系统,视以下为汉语辅音和元音音位:
汉语辅音音位
汉语单元音音位(不考虑/?鬢/)
3.2数据收集
Da (2004)采用一个包含193,504,018汉字频次的汉语语料编制了汉语字频表。该语料虽然足够大,涵盖主题多样,虚构类和非虚构类文本比例较均衡,但全为书面语,所以本研究不予以使用。笔者使用的是Tseng (2004,参见本文附录1) 根据台湾普通话口语词频表所编制的汉语音节频率表(不考虑音调)。口语词频表技术细节如下:
[……]根据中央研究院现代汉语对话语音语料库内容所计算出的词集及词频统计。词频表包含词项、词类、词频以及音节频率等相关统计数据,可以作为在台湾使用的现代汉语口语常用词的参考依据。现代汉语对话语音语料库[……]总计有85个对话,170名发音人,共约42个小时的对话内容。录制时间为2001至2003年,发音人当时年龄为14至 63岁。声档内容经过文字转写后,先以中央研究院词库小组的自动断词系统进行断词与词类标记,最后结果再经过人工检查词类,破音字与拼音转写,总共有 16,683个词项,405,435个词次,607,016个音节。
(Tseng,2004)
3.3 数据处理
Tseng的数据是以电子形式储存在一个Excel文件中的,笔者以微软Excel为工具对数据加以操作。因数据中的音节原以拼音形式记写,首先将拼音转写成音位形式,转写法则参考Duanmu (2002:319-329)。然后,频率统计的目标音位所在的音节用Excel的数据分割功能进行筛选、合并。这个过程需要十分细致,确保包含目标音位的音节都被筛选到,不包含目标音位的音节都被筛掉。最后,筛选出来的音节的总数用Excel的求和功能计算,得出的总值即为目标音位的频率。由于数据由机器而非人手处理,效率和准确度更高。
除/n/和/?耷/外,所有汉语音位只出现在节首:/n/在节首和韵尾都有出现,/?耷/只在韵尾出现。笔者认为统计音位频率时要区分节首音位和韵尾音位,因为同一音位在不同位置有不同的音系特性,如节首/n/不带音拍,韵尾/n/却带。Bybee (2001:88)指出,传统认为两个不同位置上的同一音位可视为两个不同的音位。因此,为确保所得频率的可比性,研究只统计节首音位,不统计韵尾/n/和韵尾/?耷/。元音方面,只考虑单元音,因为双元音音质不守恒。高元音/i,u,y/的统计既包括底层结构中后跟另一元音前的音位,又包括后不跟另一元音的音位,如统计/u/时,/tu/中的/u/和/tuo/中的/u/都考虑在内。
4.结果与讨论
先看[±响音性]这个参数上两个特征值的标记关系。如下表所示,[-响音性]的辅音在Tseng的语料中使用频率为336,164,占辅音总频率的65.03%,而[+响音性]的辅音使用频率为180,787,仅占总频率34.97%。卡方检验表明两者频率的差异是极其显著的(p<.0001)。[-响音性]频率与[+响音性]频率的比率为1.86。行为潜势方面,汉语有14个音位是[-响音性],而只有七个音位是[+响音性],所以[-响音性]行为潜势大于[+响音性]。并且如果逐一细看每个发音部位上两种音的音位数对比,则[-响音性]行为潜势总是大于[+响音性]。[-响音性]音位数与[+响音性]音位数的比率为2.00。结论是,在使用频率和行为潜势两个标记性指标上,汉语的数据都表明[-响音性]标记性弱于[+响音性],这与Clements的判断吻合。
[-响音性]音位与[+响音性]音位的频率比较
再看[±展喉性]的标记关系。[+展喉性]有两种解读:呼气声和送气。呼气声可与常态声对立,区分出两类元音。送气和不送气的区分只与阻音尤其是塞音有关。汉语音位系统没有任何呼气声元音,只有常态声元音,这说明常态声,即[-展喉性]标记性较弱。塞音方面,汉语中送气塞音和不送气塞音数量等同:
因此,单凭行为潜势无法判断送气与不送气的标记关系。然而,比较两者的使用频率却能清楚地看出来:
不送气塞音频率显著高于送气塞音(p<.0001),这表明不送气,即[-展喉性]标记性较弱。此标记关系贯穿上表中每一对音位:/p/高频于/p■/,/t/高频于/t■/,等等。
以下为14对区别特征值频率(百分比)与音位数的比较:
从上表可看出,除尖音一行外,其余数据都与Clements的标记关系一致。各行频率差异都是显著的,标记性更弱的特征所占频率基本上都超过60%。每对特征值中频率较大的几乎都是负值,这与Greenberg (2005:15)的观点一致。
5.结语
Clements单凭音位系统跨语对比提出了14个区别特征标记关系,笔者给出的汉语结构方面和语料方面的证据,有力支持其中的13个。除[±前部性]和[±后]这两个特征外,得到确认的标记性较弱的特征值都是负值。唯一不被汉语数据支持的标记关系是[-尖音性] < [+尖音性],这有待进一步考察世界其他语言的音系结构和语料。跨语言验证是一项大工程,需前赴后继,逐步拼凑出世界语言的总体面貌;笔者研究汉语,是这工程的其中一环,未来需要以类型学视野分析世界上更多语言的样本。
参考文献:
[1]Brown,Gillian & Yule,George.Discourse Analysis [M].Cambridge: Cambridge University Press,1983.
[2]Bybee,Joan L.& Hopper,Paul.Introduction to frequency and the emergence of linguistic structure[A]. In Joan Bybee,Paul Hopper (eds.),Frequency and The Emergence of Linguistic Structure[C]. Amsterdam/Philadelphia: John Benjamins Publishing Company,2001.
[3]Bybee,Joan L.Frequency of Use and the Organization of Language[M]. Oxford: Oxford University Press,2006.
[4]Clements,George N.The role of features in speech sound inventories[A]. In Eric Raimy & Charles Cairns (eds.),Contemporary Views on Architecture and Representations in Phonological Theory[C]. Cambridge MA: MIT Press,2005.
[5]Croft,William.Typology and Universals,2nd edition [M].Cambridge: Cambridge University Press,2003.
[6]Crothers,John.Typology and universals of vowel systems [A]. In Joseph H. Greenberg, Charles A. Ferguson & Edith Moravcsik (eds.), Universals of Human Language, Vol.2 [C].Stanford: Stanford University Press,1978: 93-152.
[7]Da,Jun.(2004) A corpus-based study of character and bigram frequencies in Chinese e-texts and its implications for Chinese language instruction[A]. In Zhang Pu,Tianwei Xie and Juan Xu (eds.),The Studies on the Theory and Methodology of the Digitized Chinese Teaching to Foreigners: Proceedings of the 4th International Conference on New Technologies in Teaching and Learning Chinese[C]. Beijing: The Tsinghua University Press,501-511.
[8]Duanmu, San. The Phonology of Standard Modern Chinese,2nd edition[M]. Oxford: Oxford University Press,2007.
[9]Ferguson,Charles A. Assumptions about nasals: a sample study in phonological universals[A]. In J.H.Greenberg (ed.),Universals of Language[C]. Cambridge MA: MIT Press, 1963:53-60.
[10]Greenberg,Joseph H. Synchronic and diachronic universals in phonology[J]. Language ,1966,42:508-17.
[11]Greenberg,Joseph H.Language Universals: with Special Reference to Feature Hierarchies,reprinted edition[M]. Berlin: Mouton de Gruyter,2005.
[12]Haspelmath,Martin.Preface to the reprinted edition [A].Language Universals:with Special Reference to Feature Hierarchies,reprinted edition[M]. By Joseph H.Greenberg.Berlin: Mouton de Gruyter.vii-xvii ,2005.
[13]Tseng,Shu-Chuan.Processing Spoken Mandarin Corpora[J]. Traitement automatique des langues.Special issue: Spoken corpus processing ,2004:45,89-108.
[14]Zee,Eric & Lee,Wai-Sum.Vowel typology in Chinese [J]. Saarbrücken: ICPhS XVI,2007:1429-1432.
[15]时秀娟.现代汉语方言元音格局的类型分析[J].南开语言学,2007(1): 70-77.
[16]叶晓锋.汉语方言语音的类型学研究.博士学位论文[D].复旦大学,2011.
