特征融合在微博数据挖掘中的应用研究
2015-08-17王和勇
王和勇 洪 明
(华南理工大学电子商务系 ,广东 广州510006)
特征融合在微博数据挖掘中的应用研究
王和勇洪明
(华南理工大学电子商务系 ,广东 广州510006)
针对传统的微博聚类分析中,只单独针对微博阅读数、评论数等数据 (下称微博结构化数据)进行分类或者单独针对由微博内容进行文本分词得到的分词数据 (下称微博分词)进行分类的问题,本文采用了Kohonen聚类,研究结合微博结构化数据和微博分词的融合数据聚类的效果是否比单独对微博结构化数据或对微博分词聚类有所提高。实证数据实验结果显示 ,微博结构化数据单独聚类会出现一个类的标准差特别大 (本文称为离群类),而对融合数据聚类 ,微博结构化数据则不会出现离群类;融合数据聚类结果对微博分词的影响不显著。
微博 ;聚类;融合数据
微博是当今流行的信息发布和交流的工具,微博蕴含着大量的信息资源,成为数据分析的重要数据来源。微博数据可以分为两类 ,一类是结构化数据,微博的用户名、阅读数、转播数、发表日期等微博相关的信息 (下称 “微博结构化数据”);另一类是非结构化数据即微博用户发表微博内容的文本数据 (下称 “微博内容”)。
在微博研究中,往往需要对微博数据进行分类以发现某些数据间有趣的规律和模式。而从微博中收集的现实数据往往没有预先定义的分类 ,由于微博数据庞大 ,无法进行手工分类,必须采用一些分类方法进行处理。由于微博非结构化数据都是经过文本分词转化为结构化数据进行有关分类研究,由微博内容转化成的结构化数据下文称为“微博分词”。
文献中,马彬、洪宇、陆剑江、姚建民和朱巧明(2012)利用线索树双层聚类过滤垃圾微博,进而实现微博话题检测 (微博分词聚类)[1];张国安和钟绍辉 (2012)分析用户数据,利用K均值聚类研究微博用户分类 (微博结构化数据聚类)[2];路荣、项亮、刘明荣和杨青 (2012)利用两层K均值和层次聚类的混和聚类方法对微博文本进行聚类从而检测出新闻话题 (微博分词聚类)[3];潘大庆(2012)利用层次聚类以敏感话题为单位对微博进行分类(微博分词聚类)[4];熊祖涛 (2013)基于文本稀疏性问题,描述了多种微博文本聚类的方法 (微博分词聚类)[5];英文文献中,Yang C,Ding H,Yang J等 (2012)利用K-均值聚类算法发现微博中的用户社区 (微博分词聚类)[6];Olariu A.(2013)利用层次聚类对Twitter的文本进行分类从而提高微博流汇总算法的有效性(微博分词聚类)[7];Muhammad Atif Qureshi,Colm O'Riordan,Gabriella Pasi(2013)利用聚类分析来检测Twitter上公司的声望 (微博分词聚类)[8];Huang B、Yang Y、Mahmood A等 (2013)利用单遍聚类方法来发现微博话题 (微博分词聚类)[9];Elena Baralis、Tania Cerquitelli、Silvia Chiusano等 (2013)对Twitter同一话题发表内容的用户进行聚类以发现相似的群组 (微博分词聚类)[10]。目前的文献都只是单独针对微博结构化数据或者单独针对微博分词进行聚类分析,得到一个分类,本文将微博结构化数据和微博分词结合起来形成融合数据,研究对融合数据进行聚类的分类效果是否比单独对微博结构化数据或微博分词聚类的分类效果有所优化。
通过软件抓取腾讯微博 “房价”话题的数据 ,首先提取出用户名,阅读数等微博结构化数据和微博内容的文本 ,对微博内容的文本进行文本分词形成微博分词,然后将微博结构化数据和微博分词结合形成包含微博结构化数据和微博分词的融合数据。聚类实验部分分别进行对微博结构化数据、微博分词和融合数据所有字段的Kohonen神经网络聚类分析,通过字段聚类后的标准差比较聚类结果的相对好坏,验证融合了微博结构化数据和微博分词的数据是否比单独的微博结构化数据和单独的微博分词聚类效果有所提高。
1 数据收集与整理
1.1数据搜集
本文利用软件搜集腾讯微博2011年11月8日 -2014年2月15日话题为 “房价”的数据共2 000条。搜集来的数据是HTML形式,需要进一步的处理提取出结构化字段和微博的文本内容,原始数据具体的情况如表1所示。

表1 R微博原始数据
1.2数据整理
采集的数据是HTML的形式,为半结构化的数据,因此需要提取出结构化的字段微博结构化数据和微博的内容。经过阅读THML代码,代码中可以提取的结构化字段名称,含义及格式如表2所示。

表2 R微博结构化数据
本文使用R语言提取HTML文件中的微博结构化数据和微博内容。提取的过程如图1所示。

图1 RR提取微博结构化数据和微博内容
用R语言提取出的结构化数据存储在EXCEL表格中,去掉重复的数据。在过程中发现有些微博的时间是 “今天10∶10”这样没有确切时间的数据,将其作为缺失处理,用NULL补全数据,因为不清楚发表日期,所以发表时间意义不大,因此发表日期为 NULL的条目发表时刻也设为NULL。微博内容的文本数据存储在文本文件中。去掉了重复的数据后,现存的数据有1 672条,如果去掉发表时间和发表时刻为NULL的数据,则剩余1 399条。
微博内容数据存放在TXT文本文件中,每一条微博为一行。
2 非结构化化数据处理与数据融合
2.1文本分词
文本属于非结构化数据,非结构化数据利用现有的技术无法直接处理,因此需要将文本转化为结构化数据。根据一个文本中词语的意义将文本划分为一个一系列的有意义的词的向量并统计每个有意义词在一个文本中出现的次数即词频,这样就将一个文本有非结构化数据转化为结构化数据。有意义的词是字段,词频是字段的值。非结构化文本数据转化为结构化数据的转化过程如图2所示。

图2 RR文本数据转化为结构化数据过程
语料库是汇总非结构化文本 ,一个文档就是一个独立的文本,本文把每一条微博内容作为一个文档,文本库是在语料库的基础上去掉了停用词,数字等无用信息的非结构化纯文本,而且初始的非结构化文本可能是HTML,XML等文件,因此由语料库转化为文本库是必要的。文档词条矩阵是将每一个文档分词 ,然后统计每个文档中词条 (即前文说的有意义的词)的词频,形成的一个以文档为行,词条为列的矩阵。文档词条矩阵是非结构化文本的结构化表现形式。
本文以R语言的tm包为基础,构建语料库和文本库以及文档词条矩阵,使用Rwordseg包分词。
2.2文本分词实验
利用本文数据和R语言进行文本分词的过程如图3所示。

图3 RRR语言文本分词过程
在建立结构化数据的过程中,对分词进行了两次筛选,第一次是筛选出分词中的名词,因为名词的意义比较大 ,含义比较丰富。第二次是根据文档词条矩阵筛选出了词频大于200的词,因为建立的矩阵稀疏,而且有些词的词频很小,很难有代表性,因此人为选择词频大于200的分词。实验过程中提取出词频100以上,200以上,300以上,400以上和500以上的词。
实验中发现,词频大于100的词太多,会导致文档词条矩阵过于稀疏,不利于进一步实验,词频大于200的词数量比较适中,而选择词频大于300的词数量稀少,因此选择词频大于200的词。在词频大于200的词中,有些词跟房价的关联性不大,因此进一步人为筛选,人工去掉“价”,“房价”,“钱”,“人”,“问题”,“新闻”和 “中国”去掉,这些词语跟房价没有太大的关联性。因此 ,整理后的微博文本结构化数据的字段即微博分词如表3所示。
2.3数据融合
在原来的结构化数据的基础上 ,把微博分词融合到微博结构化数据当中,形成一个新的数据表,该数据表的字段汇总如表4所示。

表3 R微博分词字段

表4 R融合数据字段
3 Kohonen神经网络聚类实验
3.1Kohonen神经网络聚类简介
Kohonen神经网络聚类的原理大致是:当一条数据输入到输入层,输入层将数据项的变量特征作为刺激信号传递给输出层,输出层中对该信号最为敏感的节点 “获胜”,作为最能解释该数据项的节点。对每条数据进行相同的操作,最后输出层形成一个二维的结构,即是聚类的输出结果。
Kohonen神经网络聚类的过程如下:
3.1.1确定聚类的初始中心
设有p个输入节点,则在时刻 t第j个输出节点和p个输入节点的中心Wj(t)为:

其中,w1j(t)(i=1,2,3,…,p)是连接的权值。刚开始时权值是随机的,因此,刚开始的聚类中心也是随机的。
3.1.2确定获胜节点
在时刻 t,一条数据X(t)到达输入层,根据X(t)属性计算其与类中心的欧氏距离 d(t),最后选出d(t)最小的类中心Wc(t),Wc(t)便是获胜节点。
3.1.3调整获胜节点及其邻居节点的类中心位置
当Wc(t)对一条数据 X(t)胜出时,Wc(t)及其邻居节点对输入层节点的权值需要调整 ,也就调整了类中心。调整Wc(t)类中心的方法如下:

其中,η(t)表示时刻 t的学习率。
Wc(t)邻居节点指的是以Wc(t)为圆心 ,指定半径内的节点,邻居节点Wj(t)的调整方法如下:

其中,hjc(t)是时刻Wj(t)和Wc(t)的距离的度量。hjc(t)的一种形式是切比雪夫距离:

3.1.4判断是否迭代终止
迭代终止的条件一般是权值基本稳定或者到达预定义的迭代次数,如果满足条件,终止,否则回到第二步。
3.2Kohonen神经网络聚类实验
本文使用SPSSClementine软件作为实验环境,以6种比例的训练集来进行实验,分别使用50% ,60% ,70% ,80% ,90%和100%的数据进行聚类实验。利用融合数据随机筛选出上述比例的数据,实验时分别提取出融合数据的结构化数据,文本结构化数据分别进行聚类实验,最后再进行融合数据聚类实验。实验中剔除 “用户名”、“发表日期”和 “发表时刻”以确保所有字段都是数字类型,使得微博结构化数据的字段和文微博分词的字段具有可比性。具体的实验步骤如图4所示。
3.3实验结果对比分析
按照实验步骤对各个比例的融合数据分别进行微博结构化数据聚类,微博分词聚类以及融合数据聚类。聚类结果显示,在6个不同比例的训练集实验数据下,微博结构化数据聚类,微博分词聚类,融合数据聚类都分为12类。
评判聚类效果的方法很多,本文使用标准差来评价聚类的相对好坏,1个类中相同字段的标准差越小,说明该字段的值相差越小,也就越相似。用函数 std(字段)表示在聚类结果中1个字段的12个类的标准差的汇总折线,如std(阅读数)表示一个聚类结果中阅读数的12个类的标准差的汇总折线。比较两组结果:微博结构化数据聚类和融合数据聚类 ,微博分词聚类和融合数据聚类,通过汇总折线的比较,评价聚类的效果的相对好坏,两组比较具体的比较内容如表所示。对于微博结构化数据聚类,只需要把3个结构化字段的12个类的标准差折线和融合数据聚类中对应的字段的标准差折线分别比较,对于微博分词数据,则要比较9个字段。具体如表5所示。

图4 RR聚类实验过程

表5 R实验结果比较方法
3.3.1微博结构化数据聚类和融合数据聚类比较
将微博结构化数据聚类结果和融合数据聚类结果中微博结构化数据和融合数据共有的3个字段——阅读数,评论数和转播数的12个类的标准差绘制成折线图,选择80%训练集的实验结果展示如下 ,其他比例下的训练集实验结果类似 (fusion表示融合数据,structured表示微博结构化数据数据)。
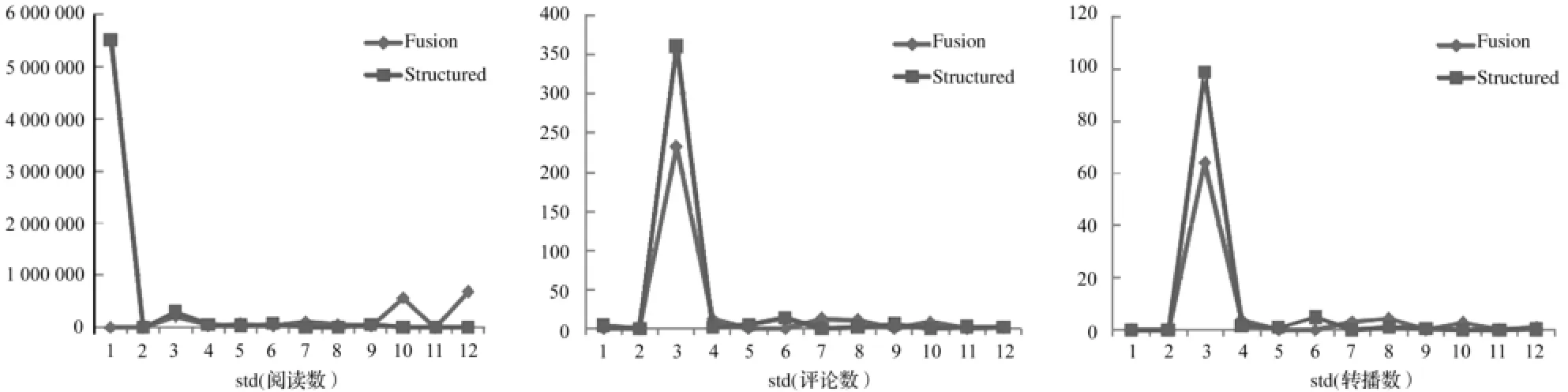
图5 RR80%实验数据3个字段的比较
从图5可以看出,微博结构化数据聚类的结果往往出现一个这样一个类,类中3个字段的标准差都很大,偏离平均水平很多,本文称为 “离群类”。而融合数据的结果则能够缩小离群类和其他类的差异性。微博结构化数据的字段融入微博分词聚类以后,能够把 “离群类”的标准差的差异分摊到其他类,从而把 “离群类”拉回平均水平附近 ,这样的代价是其他类的标准差会有所增加,但是整体的聚类效果得到提升,因为聚类中 “离群类”的与其他类的差异性变小,其他类的标准差影响不大。
3.3.2微博分词聚类和融合数据聚类比较
将微博分词聚类结果和融合数据聚类结果中共有的9个字段的12个类的标准差绘制成折线图 ,选择80%训练集的实验结果展示如下,其他比例下的训练集实验结果一致(Fusion表示融合数据,Non-structured表微博分词)。
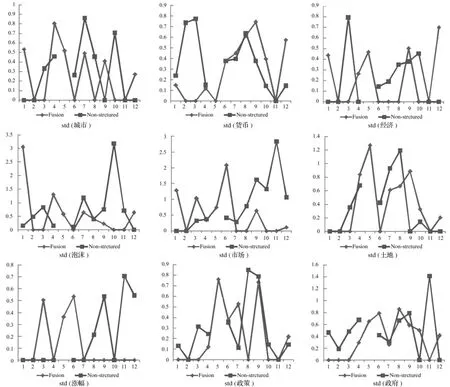
图6 RR80%实验数据9个字段的比较
从图6可以看出,融入微博结构化数据的字段聚类后,微博分词字段的标准差没有明显下降,跟微博分词单独聚类没有明显差异,因此,融合数据对微博分词聚类没有明显帮助。
4 结 论
传统的微博聚类分析针对微博结构化数据 (结构化字段)分类或者微博分词 (通过某种方法转化为结构化字段)分类。本文采用Kohonen神经网络聚类,研究对结合了微博结构化数据和微博分词 (通过某种方法转化为结构化字段)的融合数据聚类的效果是否比单独对结构化字段或文本结构化字段聚类有所提高。从数据中提取实证数据实验结果显示,结构化字段单独聚类会出现一个类的标准差特别大的 “离群类”,而对融合数据聚类,结构化字段则不会出现 “离群类”,融合了微博分词一起分类后,结构化字段的 “离群类”的标准差变小,被拉近标准
差的平均水平。另一方面,融合数据聚类对微博分词的效果不太明显,融合了微博结构化数据再聚类和微博分词单独聚类,结果不太显著。
[1]马彬 ,洪宇 ,陆剑江 ,等 .基于线索树双层聚类的微博话题检测 [J].中文信息学报 ,2012,26(6):121-128.
[2]张国安,钟绍辉.基于K均值聚类的微博用户分类的研究[J].电脑知识与技术,2012,8(26):6273-6275.
[3]路荣,项亮 ,刘明荣,等.基于隐主题分析和文本聚类的微博客中新闻话题的发现 [J].模式识别与人工智能,2012,25 (3):382-387.
[4]潘大庆 .基于层次聚类的微博敏感话题检测算法研究 [J].广西民族大学学报 ,2012,18(4):56-59.
[5]熊祖涛.基于稀疏特征的中文微博短文本聚类方法研究 [J].软件导刊,2014,13(1):133-134.
[6]Changchun Yang,Hong Ding,Jing Yang,Hengxin Xue.Mining Microblog Community Based on Clustering Analysis[C]∥Proceedings of the International Conference on Information Engineering and Applications(IEA)2012.Springer London,2013:825-832.
[7]Olariu A.Hierarchical clustering in improvingmicroblog stream summarization[M]∥Computational Linguistics and Intelligent Text Processing.Springer Berlin Heidelberg,2013:424-435.
[8]Muhammad Atif Qureshi,Colm O'Riordan,Gabriella Pasi.Clustering with Error-Estimation forMonitoring Reputation of Companieson Twitter[M]∥Information Retrieval Technology Lecture Notes in Computer Science,2013:170-180.
[9]Bo Huang,Yan Yang,Amjad Mahmood,Hongjun Wang.Microblog topic detection based on LDA model and single-pass clustering[C]∥Rough Sets and Current Trends in Computing.Springer Berlin Heidelberg,2012:166-171.
[10]Elena Baralis,Tania Cerquitelli,Silvia Chiusano,Luigi Grimaudo,Xin Xiao.Analysis of Twitter Data Using a Multiple-level Clustering Strategy[C]∥Model and Data Engineering Lecture Notes in Computer Science,2013:13-24.
[11]Jiawei Han,M icheline Kamber.数据挖掘概念与技术 [M].北京 :机械工业出版社,2008:283-284.
(本文责任编辑:郭沫含)
The Study of M icroblog Data M ining Using Feature Fusion
Wang Heyong Hong Ming
(Departmentof E-Business,South China University of Technology,Guangzhou 510006,China)
This paper focused the problem that traditional clustering analysis have focused on only structured data such as microblog reading numbers andmicroblog commentnumbers(microblog segmentation)oronlymicroblog text.In thispaper,microblogmetadata are combinedwithmicroblog text to form fusion data and Kohonen Network Clustering is applied to test if fusion data clustering is better thanmicroblogmetadata clustering and thanmicroblog text clustering.Experiments indicates thatmicroblog metadata clusteringmay causea classwith large standard deviation(outlier class)and on the contrary,fusion data clustering does not.Microblog text clustering performs aswell as fusion clustering.
microblog;clustering;fusion data
王和勇 (1973-),男,提前上岗教授,研究方向:数据挖掘、文本挖掘和大数据挖掘。
10.3969/j.issn.1008-0821.2015.05.013
G250.78
A
1008-0821(2015)05-0068-05
2015-03-05
