并行环境下基于图着色理论的空间数据部署
2015-08-16殷君茹唐小明李惺颖卜祥亮
殷君茹,唐小明,李惺颖,卜祥亮
(1.中国林业科学研究院 资源信息研究所,北京100091;2.广西林业勘测设计院 3S技术研究与开发中心,南宁 530011;3.北京林业大学 水土保持学院,北京 100083)
并行环境下基于图着色理论的空间数据部署
殷君茹1,唐小明1,李惺颖2,卜祥亮3
(1.中国林业科学研究院 资源信息研究所,北京100091;2.广西林业勘测设计院 3S技术研究与开发中心,南宁 530011;3.北京林业大学 水土保持学院,北京 100083)
在面向计算部署到数据节点端执行的分布式并行环境下,提出一种基于图着色理论的适用于矢量空间数据的部署方法,将空间数据粒度的部署问题转化为图顶点着色的过程,提高了任意空间区域的信息查询效率.给出基于图着色理论的数据部署方法,并通过节点的任务量进一步改进算法,使得该算法可实现海量空间数据粒度的离散化部署,提高了空间数据检索和查询的并行化程度,充分利用了并行计算资源.
空间数据部署;数据粒度;并行环境;图着色理论;负载均衡
并行计算环境下的空间数据部署一般都采用“分而治之”的思想,按照一定的规则将海量空间数据均衡分配存放在多个节点中,从而达到多节点、多处理器协同工作,提高空间数据的快速查询响应和并行分析能力[1-3].
空间数据部署(用于任务划分和负载均衡控制)是影响并行地理信息系统(GIS)的关键因素,目前研究多集中在海量事务性数据上,采用主流的分布式文件系统(如GFS,Hadoop,Cassandra,Dynamo和Apache Spark)进行管理,按照一致性Hash策略将数据均分为大小相同的数据块,并对每个块进行随机部署,实现了海量数据的均衡分布,却忽略了数据间的关联关系,导致大量不必要的数据传输任务[4].文献[5-6]基于Hadoop的分布式文件系统HBase实现了对空间数据的部署管理,提升了查询海量空间数据的效率,但不能满足空间数据的复杂查询;目前高性能并行GIS多采用对象关系型数据库管理海量空间数据[7-10],文献[11-12]在Oracle Spatial基于空间位置范围划分策略的基础上,分别采用基于Hilbert空间填充曲线和K-平均聚类算法,实现了对原子空间数据项的均衡分配,但未考虑特定的多个相邻区域空间查询的并行效率.
在实际应用中,通常在特定比例尺下,当多用户并发访问或涉及多区域间的空间信息且这些区域集中在同一个节点时,就会导致该节点过载,同时其他节点的计算资源空闲,形成对某个节点较长时间的依赖性,影响系统的整体性能.因此,为提高该场景下的并行计算效率,本文采用基于图着色理论的空间数据部署策略和方法,通过将空间数据粒度部署转化为顶点着色模型,利用各节点的任务量作为约束条件对算法进行修正,使得各节点数据负载达到均衡的同时,相邻空间区域尽量离散化分布,从而提高查询的并行化程度,并以辽宁省林地数据为例,验证了该方法的有效性.
1 基于图着色的空间数据部署模型构建
由于采用的并行计算策略是在进行一次空间查询时,将任务调度至相关节点进行运算,因而系统的响应时间由参与计算的节点数、各节点参与计算的数据量和节点之间的数据传输决定.
定义1系统响应时间定义为

其中:T(pi)表示各节点处理任务的时间;Tcomm(i)表示由于数据传输耗费的通讯时间;m表示节点数量.由式(1)可知,要提高系统的响应数间,数据部署时应使各节点的任务量分布均衡,以减少各节点处理任务的时间差异;数据部署后使各节点的子任务联系尽量少,以减少数据传输的时间消耗.
采用数据粒度表示空间数据对象经一定的划分规则得到数据表的度量,它直接影响数据表的扫描时间和数据命中率.对于空间数据粒度查询过程,若所涉及查询的数据粒度尽可能分布在多个节点上,且相邻的数据粒度不在同一个节点上,则能充分利用并行资源,提高并行度,并极大降低各节点子任务之间的通讯.因此,基于该思想可将数据粒度的部署转化为图着色过程.
1.1基于图着色的数据部署模型构建
图着色是指对图的每个顶点(边或面)指定一种颜色,使相邻的顶点(边或面)不同色.主要包括顶点着色、边着色和图的全着色.经过一定的变换,图的边着色和全着色都可以等价转化为图的顶点着色.该问题可描述为:给定无向图G(V,E),V={v1,v2,…,vn},建立映射C:V→{c1,c2,…,ck},使得对任意的(vi,vj)∈E,C(vi)≠C(vj).因此,本文采用顶点着色为V中的顶点进行着色,即在满足一定条件下,使得任意两个相邻顶点的颜色不相同[13].
在分布式存储的并行体系中,任务计算和数据交换通过节点和网络进行,本文仅考虑同构网络,即节点间的参数相同,用点集P={p1,p2,…,pm}表示m个节点.
定义2(数据粒度分布图) 数据粒度及其空间相邻关系可用一个无向图G=(V,E)表示,其中:V中的顶点表示数据粒度,即V={vi|待分配的所有数据粒度i};E中的边表示数据粒度之间的空间相邻性,即E={(vi,vj)|数据粒度的空间相邻性}.每个顶点v(v∈V)有一个w表示v所表达的数据粒度大小.
定义3(数据粒度映射) 用一个映射函数表示数据粒度到计算机的映射M:V→P,如果顶点l(l∈V)表示的数据粒度被部署到节点p(p∈P)上,则M(l)=p.
定义4(顶点着色的数据部署模型) 设颜色集合C={c1,c2,…,cm},给定数据粒度分布图G(V,E),V={v1,v2,…,vn},建立映射M:V→C,使得对任意的(vi,vj)∈E,C(vi)∩C(vj)=Ø,且C=P,则M定义的映射关系由空间拓扑邻接矩阵En×n确定,并有
且当E(i,j)=1时,vi与vj不可分配在同一个节点上.
在数据粒度部署中,节点对应于颜色集合C={cm|1≤m≤M}.数据部署过程如图1所示.
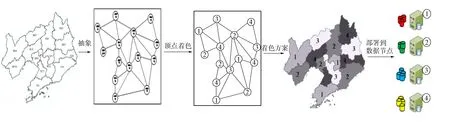
图1 空间数据部署过程Fig.1 Spatial data placement
1.2评价指标
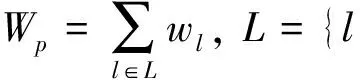
2 基于图着色模型的数据部署求解方法
本文提出的基于图着色模型的数据部署求解方法过程分为两个阶段:Ⅰ.基于顶点着色算法求得任一相邻的空间数据粒度都不在同一节点;Ⅱ.动态统计各节点的任务量,并以此修正第Ⅰ阶段的分配行为,确定最终的数据部署方案.
2.1数据部署求解第Ⅰ阶段
对于无向图G(V,E),顶点序列V={v1,v2,…,vn}(n为待分配数据粒度总数),颜色集C={c1,c2,…,cm}, 通过E(i,j)的取值判断顶点间的空间位置关系,将其作为一个约束条件,以实现数据粒度的离散化分布,算法可描述为:
1)给v1着色,在颜色集C中选择第1个颜色c1给v1着色,将v1移至已着色顶点集V(k)中,且c1标记为已使用颜色;
2)给v2着色,判断v2与v1的空间位置关系,如果E(1,2)=0,则用c1为v2着色;否则,从C中去除c1,选择可着色集中的一个元素c2为v2着色,将v2移至已着色顶点V(k)中,且c2标记为已使用颜色;
3)给vi(i≥3)着色,依次判断vi与V(k)中顶点的空间位置关系.如果都不相邻,则从已使用颜色中任选一种颜色ct为vi着色,否则,从C中去除相邻顶点所着色的颜色,并在剩余可着颜色中选择一种颜色cm为vi着色,将vi移至已着色的顶点集合中,为顶点vi+1着色,图2为给顶点vi着色的算法流程;
4)当V-V(k)≠Ø时,转3);否则,着色完成,生成着色方案C;
5)将每种颜色ck对应一个数据节点pk,找出所有着ck颜色的顶点,即所代表的数据粒度,部署给该数据节点pk,直到每个数据节点部署完成为止.
该算法的特点是优先使用已分配数据的节点,但随着数据粒度逐渐增多,会出现节点间数据分布不均衡的情况,将加重个别节点的计算负载,延长系统总体的响应时间.
2.2数据部署求解第Ⅱ阶段
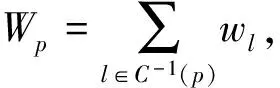
3 实验分析
3.1实验数据
实验数据为辽宁省2005年度林地数据,包含小班数据共有1 535 720条(小班在行政级别上低于村的林业管理单元).小班数据类型为面状矢量数据,共有50个属性字段,既包括反映森林资源现状和变化的属性信息,如权属、地类、优势树种、面积等,也包括反映空间特征的信息,如空间数据类型、空间位置坐标等.其中县级行政单位共有124个,经实验分析和数据管理的综合考虑,本文采用县级单位作为数据节点存储的数据粒度单元,并经过一定的拆分和合并,形成以县为单位的105个数据粒度.
3.2实验环境
实验环境由4台服务器组成服务器集群,服务器为IBM X3650M4服务器,CPU为英特至强E5-2609 2.4 GHz,24 GB内存,8×600 GB硬盘.主节点为其中一台的服务器,同时该4台服务器也充当数据节点,每个数据节点由Oracle Spatial提供存储支持.
3.3辽宁省县级数据粒度部署实例
首先按空间拓扑关系生成105×105的空间关系矩阵,并采用数据部署求解第Ⅰ阶段中基于顶点着色模型的数据粒度部署算法,结果如图4所示;采用数据部署求解第Ⅱ阶段中通过负载均衡改进的算法生成数据分布图,结果如图5所示.
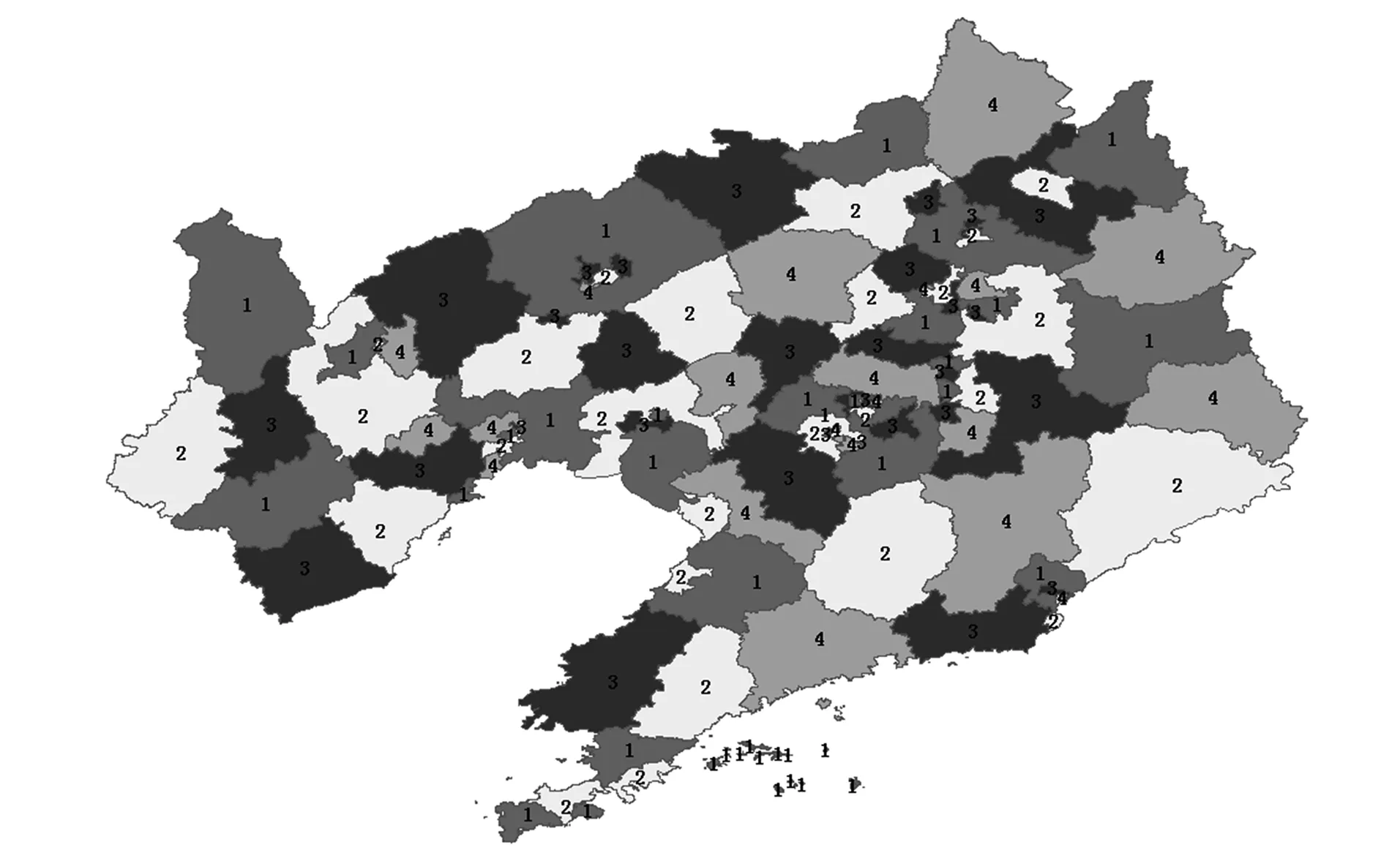
1,2,3,4分别表示数据节点1,2,3,4.
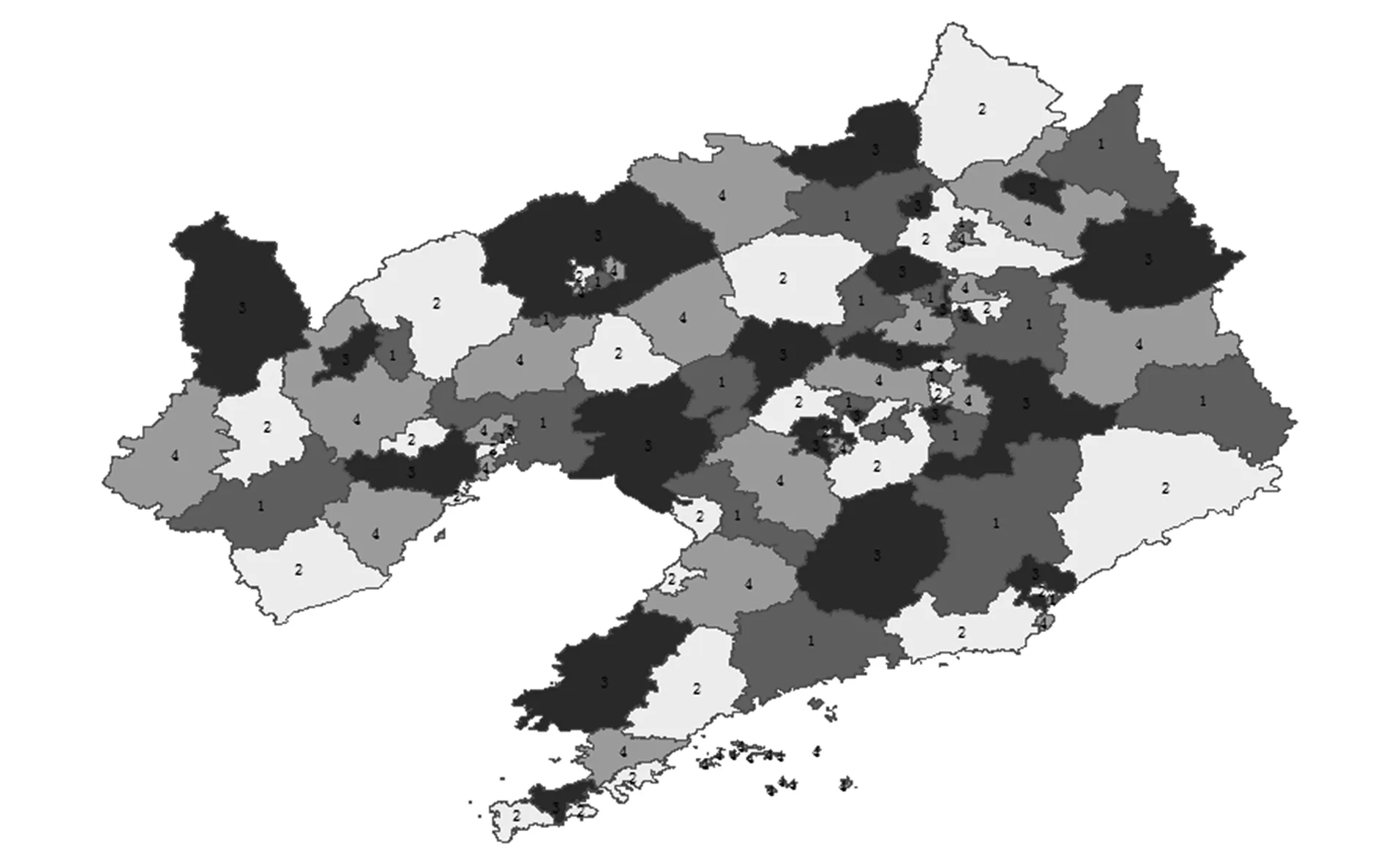
1,2,3,4分别表示数据节点1,2,3,4.
由图4和图5可见,随着算法约束条件的增加,空间数据在各数据节点上的部署也随之发生改变.分别根据图4和图5中统计数据节点的数据粒度分布情况,结果列于表1和表2.

表1 基于顶点着色模型的数据节点记录数分布情况Table 1 Vertex coloring based records distribution of data nodes

表2 改进算法的数据节点记录数分布情况Table 2 Records distribution of data nodes after algorithm improvement

1,2,3,4分别表示数据节点1,2,3,4.
由表1可见:通过每个数据节点的表总数对比,发现4个数据节点的表数量分布不均衡;各数据节点的记录数差别较大,存储量变异系数 C.V1=17.34%.由表2可见:通过每个数据节点的表总数对比,4个数据节点存储的表总数非常均匀;存储量变异系数C.V2=4.55%,明显小于C.V1的值.
实验结果表明,通过改进算法各数据节点表的数据分布更均衡,各数据节点存储的记录数离散程度显著减少,使得数据负载更趋于均衡.
如图6所示,当进行任意区域的空间数据查询时,数据节点1涉及2个数据粒度,数据节点2为3个,数据节点3为3个,数据节点4为3个,这些数据粒度不仅离散地分布在4个数据节点上,且各节点的任务量趋于均衡.
综上所述,本文描述了在并行计算环境下,面对任意空间区域的信息快速查询,提出了一种基于图着色理论的空间矢量数据部署方法,将数据粒度的部署转化为基于顶点着色模型的图着色过程,将数据粒度间的空间拓扑关系和数据节点的存储量作为约束条件,修正了基于顶点着色模型的数据部署算法,并通过实验证明该方法实现了数据节点间存储负载均衡,以及空间位置相邻数据粒度的离散分布,为海量空间矢量数据在多数据节点上的均匀部署提供了一种思路,从而能在并行计算时更有效地利用并行计算资源,减少数据节点间的通信,提高了空间数据的快速响应和并行分析效率.但本文由于在算法中将数据节点间的存储量和空间拓扑关系同时作为约束条件,使得当数据节点的个数选择不合适时,会出现个别数据粒度与所有数据节点冲突,导致无法分配的问题,这需要根据实际需求进行适当修正,以优先保证存储负载均衡.
[1] 王结臣,王豹,胡玮,等.并行空间分析算法研究进展及评述 [J].地理与地理信息科学,2011,27(6):1-5.(WANG Jiechen,WANG Bao,HU Wei,et al.Review on Parallel Spatial Analysis Algorithms [J].Geography and Geo-Information Science,2011,27(6):1-5.)
[2] 李峙,陈朝晖.空间叠加分析中的分而治之算法研究与应用 [J].计算机工程与应用,2009,45(34):230-232.(LI Zhi,CHEN Chaohui.Study and Applications of Divide and Conquer Algorithm in Spatial Overlay Analysis [J].Computer Engineering and Applications,2009,45(34):230-232.)
[3] 宋杰,李甜甜,闫振兴,等.数据密集型计算中负载均衡的数据布局方法 [J].北京邮电大学学报,2013,36(4):76-80.(SONG Jie,LI Tiantian,YAN Zhenxing,et al.Load-Balanced Data Layout Approach in Data-Intensive Computing [J].Journal of Beijing University of Posts and Telecommunications,2013,36(4):76-80.)
[4] 王艺文,苏森,谢琛甫,等.跨数据中心的关联云数据部署策略 [J].华中科技大学学报:自然科学版,2013,41(增刊2):48-51.(WANG Yiwen,SU Sen,XIE Chenfu,et al.Dependent Cloud Data Placement on Geo-Datacenters [J].Huazhong University of Science and Technology:Natural Science Edition,2013,41(Suppl 2):48-51.)
[5] 崔鑫.海量空间数据的分布式存储管理及并行处理技术研究 [D].长沙:国防科学技术大学,2010.(CUI Xin.Research on Massive Spatial Data Distributed Storage and Parallel Processing Technology [D].Changsha:National University of Defense Technology,2010.)
[6] 范建永,龙明,熊伟.基于HBase的矢量空间数据分布式存储研究 [J].地理与地理信息科学,2012,28(5):39-42.(FAN Jianyong,LONG Ming,XIONG Wei.Research of Vector Spatial Data Distributed Storage Based on HBase [J].Geography and Geo-Information Science,2012,28(5):39-42.)
[7] 赵春宇.高性能并行GIS中矢量数据存取与处理关键技术研究 [D].武汉:武汉大学,2006.(ZHAO Chunyu.Studying on the Technolgies of Storage and Processing of Spatial Vector Data in High-Performance Parallel GIS [D].Wuhan:Wuhan University,2006.)
[8] 宋效东,窦万峰,汤国安,等.分布式并行地形分析中数据划分机制研究 [J].国防科技大学学报,2013,35(1):130-135.(SONG Xiaodong,DOU Wanfeng,TANG Guo’an,et al.Research on Data Partitioning of Distributed Parallel Terrain Analysis [J].Journal of National University of Defense Technology,2013,35(1):130-135.)
[9] Jean-Marie A,Lefebvre-Barbaroux S,LIU Zhen.An Analytical Approach to the Performance Evaluation of Master-Slave Computational Model [J].Parallel Computing,1998,24(5/6):841-862.
[10] SUN Xianhe,Gustafsom J L.Towards a Better Parallel Performance Metric [J].Parallel Computing,1991,17(10/11):1093-1109.
[11] 贾婷,魏祖宽,唐曙光,等.一种面向并行空间查询的数据划分方法 [J].计算机科学,2010,37(8):198-200.(JIA Ting,WEI Zukuan,TANG Shuguang,et al.New Spatial Data Partition Approach for Spatial Data Query [J].Computer Science,2010,37(8):198-200.)[12] 赵春宇,孟令奎,林志勇.一种面向并行空间数据库的数据划分算法研究 [J].武汉大学学报:信息科学版,2006,31(11):962-965.(ZHAO Chunyu,MENG Lingkui,LIN Zhiyong.Spatial Data Partitioning towards Parallel Spatial Database System [J].Geomatics and Information Science of Wuhan University,2006,31(11):962-965.)
[13] 朱虎,宋恩民,路志宏.求解图着色问题的最大最小蚁群搜索算法 [J].计算机仿真,2010,27(3):190-192.(ZHU Hu,SONG Enmin,LU Zhihong.Max-Min Ant Search Algorithm for Solving Graph Coloring Problem [J].Computer Simulation,2010,27(3):190-192.)
(责任编辑:韩 啸)
GraphColoringBasedSpatialDataPlacementtowardsParallelComputingSystem
YIN Junru1,TANG Xiaoming1,LI Xingying2,BU Xiangliang3
(1.ResearchInstituteofResourceInformationTechniques,ChineseAcademyofForestry,Beijing100091,China;2.RS,GIS,GPSTechnologyResearch&DevelopmentCenter,GuangxiForestInventory&PlanningInstitute,Nanning530011,China;3.CollegeofSoilandWaterConservation,BeijingForestryUniversity,Beijing100083,China)
An algorithm suitable for spatial vector data placement based on graph coloring theory was presented in the parallel system of computing distributed to data nodes.The deployment problem was transferred into graph vertex coloring problem,and the information query efficiency of any spatial area was thus improved.Moreover,the algorithm based on graph vertex coloring problem was proposed and improved by the task of nodes.This algorithm can achieve discrete deployment of massive spatial data granularity and storage load balance of the nodes,improve the degree of parallelism spatial data retrieval and query,and make full use of parallel computing resources.
spatial data placement;data granularity;parallel computing system;graph coloring theory;load balancing
10.13413/j.cnki.jdxblxb.2015.03.33
2014-10-28.
殷君茹(1986—),女,汉族,博士研究生,从事GIS开发与应用的研究,E-mail:yinjr1986@163.com.通信作者:唐小明(1959—),男,汉族,博士,研究员,博士生导师,从事GIS开发与应用的研究,E-mail:tangxm@caf.ac.cn.
国家高技术研究发展计划863项目基金(批准号:2012AA102001)和国家林业公益性行业科研专项基金(批准号:201304215).
TP391
:A
:1671-5489(2015)03-0525-06
