基于XML路径表达式优化及其查询和过滤计算方法研究
2015-08-09楼树美
黄 硕,楼树美
(1. 华中师范大学 信息技术系,湖北 武汉430079;2. 信阳职业技术学院 数学与计算机科学学院,河南 信阳 464000;3. 南京理工大学 计算机科学与技术学院,江苏 南京 210094)
0 引言
在Web技术中,为了分享公共资源,人们需要用信息载体来传递信息.目前,主要的信息载体用的是超文本(hypertext),但是超文本的缺点是只能依赖浏览器,不能被其他的应用程序所利用,HTML具有局限性.针对HTML存在的问题,产生了XML[1](eXtensible Markup Language).XML作为互联网上共享数据的新标准是可扩展的置标语言,可与HTML兼容,应用范围不受限制,是半结构化数据特殊的表现方式.XML以其较高的灵活性、扩展性和格式很快占据了商业市场.多数企业已经采用XML进行数据共享和交流.大部分XML中,路径表达式都是重要的组成部分之一,所以对路径表达式进行优化,提高性能非常有必要.本文中提到了补路径和路径缩短法两种优化路径表达式的方法.而如何提高查询XML数据的效率是现在的一个热门话题.网络上现在已经有非常多的XML数据,提取这些数据,需要一个文档查询工具,本论文中提到了最常用的查询语言——XQuery[2].过滤技术是在过程中将有害信息过滤掉,在面对数据量比较大,对处理速度的要求比较高的情况下,需要对传统的过滤技术进行改造,本文最后详细阐述了XML过滤算法的实现.
1 XML路径表达式的优化
中国人民大学孟小峰[3]教授将XML描述为表现半结构化数据的形式.它有结构不规则、不进行类型约束、模式信息模糊等特点.与传统关系的结构数据相比,半结构化数据模式没有明确定义,模式产生在数据后面,且它规模会不断变化.由于半结构化数据的特点,所以它的灵活性很大,能够适应网络数据的复杂要求.
1.1 优化目的
目前,正规路径表达式被广泛地应用于包括XML在内的许多半结构化数据查询语言中.首先,要对XML文档进行简化,简化成DTD,也就是扩展正则表达式.对正则表达式DTD进行优化是XML路径表达式优化的重要问题.下面,我们通过一个实例来说明正则表达式优化的问题.如图1,需要查询Q1:select×Where(college.persons.person.name)×.

图1 XML文档树结构Fig. 1 XML document tree structure
对于Q1,我们需要查询出学院中所有工作人员的名字.如果文档中没有索引,对Q1进行查询要按照路径“学院工作人员个人姓名”来对文档中的每个元素进行搜索,符合要求的元素将会被返回.在对XML进行整理的时候,通过DTD可以得到查询Q1的有用信息,但是,姓名到学院的路径只有一条.所以,在查询的时候,“学院工作人员个人姓名”通常被作为一个整体进行操作.
DTD能够提供文档模式的有用信息,利用这一点,能够对查询实现优化.对查询进行优化的重点就是对路径表达式进行优化.优化查询有三步:一、根据扩展正则表达式的含义对DTD进行缩减;二、对交结点进行定义;三、根据交结点提出路径缩短和补路径两种路径表达式优化策略.
1.2 路径表达式及其优化策略
将XML文档看成是若干路径实例的组合[4],每一个路径实例都有相应数据节点,所以将路径表达式查询和XML文档路径实例结合起来,就可得到所需要的元素实例.
定义1(交结点)D(E,A,P,R,r)是XML的文档模式,假设结点n1,n2,n3∈A∪E,每一条初始结点为n2终结点为n3的路径都经过n1,在XML模式中,就把n1叫作n2和n3的交结点,表示为:Ent(n2,n3)=n1.
基于Lore的系统,关于SPE的查询方法有以下三种:混合查询(hybrid)、从底到顶(bottom-up)、从顶到底(top-down).而外延链接算法则是混合查询方法的一个完善.对于外延算法,下面提出了两种对路径表达式进行优化的策略,同时,这两种方法也同样可以用到另外的路径表达式的优化中.这两种方法分别是:路径缩短(path shorten)和补路径(path complementing).
1.2.1 路径缩短
我们把下面提到的3个定理叫作关于路径表达式查询的路径缩短策略,它们的原理相同,都是利用XML文档模式信息,基于用户查询的本质,对路径表达式查询进行缩短.
定理1 假设XML文档Td符合XML模式Gt,那么Td中除了被rootd用到的元素之外所有的都是它的后代,可以表示为,rootd的后代为(∀n)n∈{Vd-rootd}→n.
定理2 假设Gt中只有通过绝对路径表达式查询Q={Gt,Td,roott,PE,RS}能够访问最终目标,同时,路径PE最后元素的类型用End(PE)来表示,可以得到RS=EXT(End(P,E)).
定义2 设Q={Gt,Td,roott,PE,RS}是一个查询,同时End(roott+PE)=En,并且(∀e)(e∈EXT(En)→e∈RS),则元素类型En只有PE这么一条访问路径(unique accessing path),我们将它写成UAP(En)=PE.

定义4 对于Gt和Td,并且E1,E2∈Vt,假设(∀e2∈Vd)(e2∈EXT(E2)→(∃e1)(e1∈EXT(E1)∧e1),那么我们称E2的关键祖先(key ancestor)是E1,它代表的含义是元素实例在对E2进行访问的时候一定要经过E1,写作KA(E2)=E1.
定理3n步绝对路径表达式E1C1E2C2E3,…,Cn-1En中路径连接符用Ei(1≤i≤n)和Ci(1≤i≤n-1)表示,对于Q1={Gt,Td,E1,C1E2C2E3,…,Cn-1En,RS1},并且UAP(E2)=C1E2,也就是说相对路径查询方式Q2={Gt,Td,E2,C2E3,…,Cn-1En,RS2}可来替换掉Q1,假设E3的关键祖先或者仅有的父元素为E2(C2可用‘/’,‘//’表示),那么Q1可以用Q3={Gt,Td,E3,C3E4,…,Cn-1En,RS3}来替换,也就是说UAP(E3)=C1E2C2E3.
由定理3可以知道,在某种条件下,对Q2进行优化可以得到Q3,证明我们可以对相对路径查询进行优化.上面所提到的定理推论,它们的性质是一样的,都是在基于用户需要查询的内容基础上,用XML文档的相关模式简化并缩短路径表达式,进而减少了查询的成本,它们共同构成了简化路径表达式的路径缩短策略.
1.2.2 补路径
通过对路径表达式进行优化来提高查询速度的方法称为路径缩短策略.而补路径,是用简单的路径表达式来代替用户所建立的复杂度表达式,这样也能提高查询速度.同路径缩短一样都要用到XML文档模式信息.
定义5(互补路径) 对于XML数据Td={Vd,Ed,δd,∑d,rootd,oid,typed,oidd}和XML模式Gt={Vt,Et,δt,∑t,roott},若E2∈V1,KA(E2)=E1,所有的n条路径P1,P2,…,Pn都存在于E1和E2中,同时End(Pi)=E2(1≤i≤n),我们可以将路径Pi相对于E1和E2之间的互补路径(complementary paths)定义为
可以写成

运用补路径方法对路径表达式进行优化之后,仍然需要运用路径缩短方法来对路径表达式进行更深一步的简化.在使用补路径简化方法中,最重要的问题就是找出查询路径所对应的互补路径,然后估算补路径的成本,选择相关的查询方法.
在这个方法中,通过反向路径法来对关键祖先和互补路径进行确定,而确定互补路径的经过使用函数getCP(E1,E2,P)来代表.接下来,估算所有出现的查询策略,并筛选出其中代价最少的执行策略.在估算代价之前,运用函数PS(P)和Cost(P)对路径表达式P进行缩短优化,从路径终端实行补路径的方法,只要出现比之前代价小的方法就马上结束.如此,对路径比较长的表达式该策略的效益比较高.
2 XML查询语言及查询处理
2.1 XML查询语言
XML已经逐渐成为Web上数据交换的新标准,基于XML数据的半结构化,传统数据库所适用的查询语言不能再用,需要重新创建合适的查询语言.XQuery[5.6]拥有多种XML查询语言的长处,是目前公认的XML查询语言标准.而Xpath是XQuery语言的核心部分.
2.2 Xpath查询处理
2.2.1 Xpath表达式
下面介绍ISBaXI-I对涉及上面所提到的XPE路径查询方法[7].XPE中有多个约束谓词,ISBaXI-I的方法是把XPE划分成若干个仅包含一个谓词约束的XPE.将划分之后得到的XPE查询结果,作为下一个XPE计算的输入.在查询中经常碰到一阶谓词XPE,它可以映射为XPE-Tree.
定义6(XPE-Tree) 将XPE映射为XPE-Tree,而XPE最开始的结点是XPE-Tree的根结点,写作r.将XPE中的结点定位标志作为树节点u的前缀,谓词作为后缀,n(u)∈E∪A.而根据u的子结点在XPE中出现的先后顺序定义它们的长幼关系.
我们将条件节点c定义为具有谓词匹配条件的叶节点;将目标节点t定义为待求叶节点.
定义7 (XPE-Tree分支节点) 在XPE-Tree中,如果节点b∈Ance(c)nAnce(t),同时∀d,d∈Ance(c)nAnce(t),且level(b)≥level(d),那么将b称作XPE-Tree的分支节点.
用Irb来表示从节点r到节点b的路径,同理,Ibc表示节点b到节点c的路径,Ibt表示结点b到结点t的路径.
2.2.2 查询处理
查询处理[8]的方法如下:
(1)为了降低XML在结构上匹配的复杂程度,先将XPE-Tree进行模式的匹配;
(2)对XPE-Tree中的b,c,t的解锁对应的节点集进行谓词匹配和两次路径连接运算,就可以确定在XML中XPE-Tree结点b,c,t的解.
对一阶谓词XPE查询过程如下:
首先,对XPE-Tree进行路径匹配(在模式索引TSM中),对VSM进行判断.若VSM为空,那么查询结束;若VSM不为空,那么令i=1.对i与|VSM|的大小进行比较,如果i>|VSM|,那么结束查询过程;如果i<|VSM|,对vdi对应的(TXML)xn结点进行路径连接运算和谓词匹配.然后,对WXML为空进行判断,如果不为空,在模式索引中寻找vdi在TSM中所对应的路径结构,输出满足XPE的xn,XML路径结构和待求节点values,之后进行运算i++;如果WXML为空,那么直接令i++.此时再重新将i与|VSM|的大小进行比较,直至VSM为空,或者i>|VSM|,最后结束查询.
3 XML过滤算法
过滤引擎通过下面的过程实现过滤功能:首先,为了能够过滤带分支路径的路径表达式,将路径表达式用不确定性的自动机NFA代替,在这个自动机中,需要用特殊的标记来区分分支路径,接着,通过XML Schema将NFA转化成DFA,最终,将若干个DFA合并成巨大的过滤引擎DFA.
我们用路径表达式来表示自动机,如图2和图3.图2表示开始状态1经过任意元素转移到结束状态2.而我们用//来代表子孙关系,与(/*)*含义相同,其中,第一个*表示通配符,而第二个*表示kleene闭包,表示0或者几个/*相连.
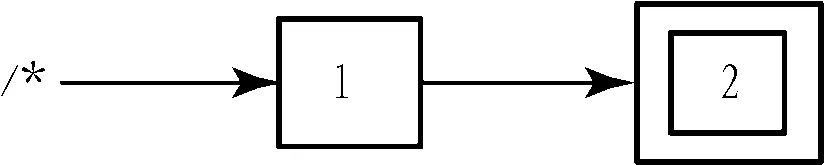
图2 /*的表达方式
Fig. 2Theexpressionof/*
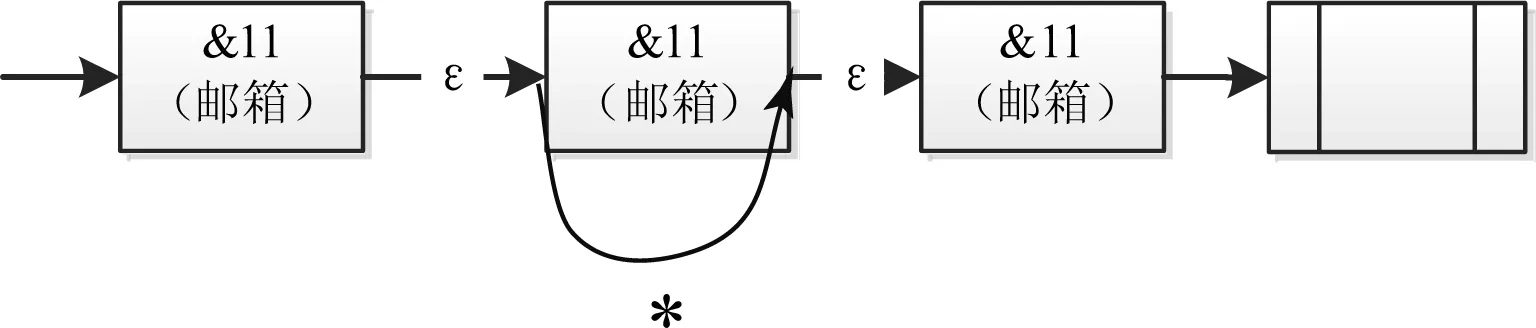
图3 //*的表达方式Fig. 3 The expression of //*
当对路径表达式进行简化之后,将它们形成的DFA集合生成一个大的DFA,这个过程类似于在Trie树中多加一个串.如果路径表达式为p,我们最终合并得到的自动机为A,那么要将p合入到A中生成A’的步骤如下:
如果自动机A开始的状态为q,并且它的第一个step是p;那么基于A的状态q和step的名称e来对下一个状态r进行查询.如果r里面是空的,那么形成一个新的r,此时q指向r,e为传递符号,当前的状态变为r.假设step有
分支,那么当前状态r会用递归法来对这个过程进行调用,这个过程结束之后会开始下一个step,属性指针会记录下属性谓词.当p没有分支点时候,在到达最终step的时候,节点会呈接受状态.如果有分支,那么在p的第一个分支节点,保证该节点的状态是接受状态,将p的id值添加到该节点的接受路径表达式列表.
需要注意,要将XML分析完毕同时找出来所有满足条件的接受状态,此时才能终止DFA.而查询过程仅仅能够输出一次,最终,给满足条件的用户传输整个XML文档.
4 结论
相比于传统的HMTL,XML的灵活性和扩展性都非常好,得到了广泛的应用,成为互联网数据共享的新标准.在XML查询语言中,最重要的部分就是路径表达式.本文提出了两种优化策略:路径缩短策略和补路径,极大地缩短了查询所需的时间,提高了查询效率.对于查询语言Xpath,它的查询处理是通过对XPE-Tree进行匹配以及两次路径连接运算来实现查询处理的.XML的过滤系统通过路径表达式来进行模式和内容匹配,在用户信息输入系统之后,生成过滤引擎,过滤引擎与数据流进行匹配,输出用户感兴趣的信息,以此来完成过滤过程.
