加权聚类算法在图书馆中的应用研究
2015-08-02王盛明卢秉亮
王盛明,卢秉亮
(1.沈阳航空职业技术学院,沈阳110034;2.沈阳航空航天大学计算机学院,沈阳110136)
加权聚类算法在图书馆中的应用研究
王盛明1,卢秉亮2
(1.沈阳航空职业技术学院,沈阳110034;2.沈阳航空航天大学计算机学院,沈阳110136)
应用加权聚类算法对本校图书馆的图书借阅数据进行数据挖掘,分析研究读者的借阅行为,通过分析聚类挖掘结果,寻找到读者借阅图书的潜在规律,并对各类图书的借阅状况进行判断,获得对图书馆管理有用的信息,提高图书馆管理工作效率和资源利用率,进一步优化馆藏。
数据挖掘;加权聚类算法;借阅行为;借阅数量;个性化服务;聚类结果分析
1 引 言
随着信息技术的迅猛发展,传统手工模式的图书馆管理逐渐被智能化的图书馆所取代,智能化的图书馆正从基于简单数据的查询逐步向基于知识的处理发展。数据挖掘技术[1]是信息采集和数据处理技术的典型代表,它已经成功应用于金融、工程与科学等众多领域,并且在现代图书馆得到广泛应用[1]。
应用数据挖掘的聚类算法中加权聚类算法对本校图书馆的借阅数据进行研究。首先,收集数字图书馆中的借阅数据,应用数据清理、归约等方法对数据进行预处理,并计算各类图书的借阅次数。然后应用加权聚类算法对借阅次数进行数据挖掘,最后,对数据挖掘结果进行分析并论证挖掘过程的有效性。
2 聚类算法
2.1 聚类算法进行聚类的原理
聚类算法[2]可以描述为:给定m维空间R中的n个向量,把每个向量归属到k个聚类中的某一个,使得每一个向量与其聚类中心的距离最小。聚类可以理解为:类内的相关性尽量大,类间相关性尽量小[2]。在这里对学生读书量和读书种类进行聚类。
2.2 聚类算法原理
聚类算法主要有基于层次、基于划分和基于密度的算法等,其中最常用和最有效的是基于划分的K-means算法。K-means算法把n个向量xi(i=1,2,…,n)分成k个类Gi(i=1,2,…,k)并求每类的聚类中心,使得非相似性(或距离)指标的目标函数达到最小。当选择第i个类Gi中向量xl与相应的聚类中心Ci间的度量为欧几里德距离时,目标函数可以定义为:

这里Ji是Gi内的目标函数,显然J的大小取决于聚类中心Ci和Gi的形状,J越小,表明聚类的效果越好。
K-means算法:
(1)首先随机选取k个向量作为每类的中心;
(2)设U是一个c×n的二维隶属矩阵,如果第j个向量xj属于类i,则矩阵U中的元素uij为1,否则为0。即对于每个k≠j且‖Xj-Ci‖≤‖Xj-Ck‖时,uij=1,否则uij=0;
(3)根据uij计算目标函数J(公式1)的值,如果它小于一个阈值或连续两次之差小于一个阈值则停止;
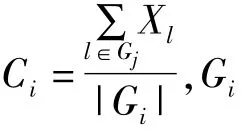
2.3 加权的聚类算法
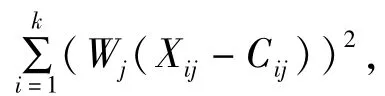
3 加权聚类分析算法在图书馆中应用
3.1 数据挖掘过程中的聚类分析算法分析
聚类分析读者借阅量,可以得到读者借书频率的高低[3]。根据图书管理信息系统的实际数据,应用加权聚类算法,进行数据挖掘过程分析[4]。随机地从读者借阅量表中抽取200名学生的记录,针对2010级按系和专业的学生对各类图书的借阅数量形成表1。这里省略学号。
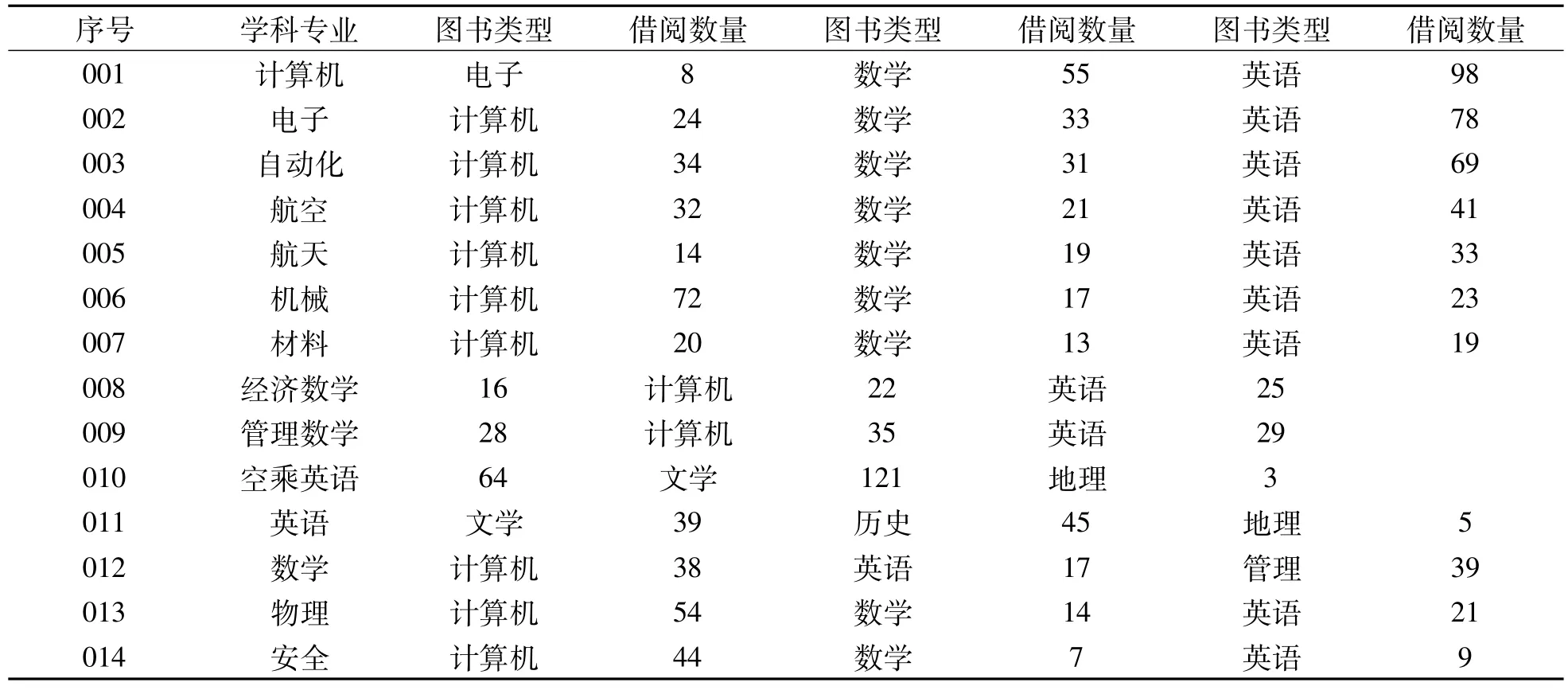
表1 读者借阅数量表
根据各专业的特点,对各类图书的需要程度进行加权。例如理工类对计算机图书的权值高,人文图书的权值低;外语、经管对人文图书的权值高,理工图书的权值低。生成U,行为学科专业,列为图书类型。将每个学科专业学生对借阅图书最少的值作为每个类的中心。把聚类的个数设置为3。一类为很少去图书馆借书的学生即惰性学生,第二类为一般学生,第三类为经常去图书馆借书的学生即活跃学生。应用加权聚类算法对表1里的数据进行挖掘,根据uij计算目标函数J,‖Xj-Ci‖≤‖Xj-Ck‖时,uij=1,否则uij=0,生成U;根据uij计算每个簇团Gi的中心Ci。
将借阅量作为挖掘对象,从表1的借阅量中得到{3,5,7,9,13,14,17,19,19,21,22,23,25,29,31,33,33,39,41,45,55,69,78,98,121},设置前三个数据作为三个类中心,即为ml=3,m2=5,m3=7。迭代聚类得到最终结果如表2所示,中间结果略。

表2 部分读者借阅本数聚类结果
3.2 聚类结果分析
如表2,得到k1、k2、k3这三列数据,每列数据是一个元组,代表着具有相同借阅习惯的一组数据。kl为{3,5,7,9,13,14,17,19,19}表示借阅量很少的学生,对应于表1中相应读者就是不活跃的学生,m1为这类读者的平均借阅本数,惰性学生的学号是{2010040101003,2010040202054,2010040303014,2010040501077,2010040604099,2010040802040},他们平均每年去图书馆借书的数量为9.8本。有59%的学生平常很少去图书馆借阅图书。k2为{21,22,23,25,29,31,33,33,39,41,45}表示借阅量一般学生,学号是{2010040102009,2010040302033,2010040402119,2010040501022,2010040703100,201004080105,2010041005229,2010041102123,2010041206010,2010041302001,2010041401050},他们平均每年去图书馆借书23.2本。此类学生占26%。k2为{55,69,78,98,121}表示借阅量活跃学生,学号是{2010040101002,2010040502032,2010040802359},他们平均每年借书量为108.6本,此类学生占15%。由此可得出结论,挖掘是有效的。
4 结束语
应用加权聚类算法分析了本校图书馆的学生借阅信息,根据读者的借阅信息将其划分为活跃学生、一般学生、惰性学生。针对上述分析结果图书馆可采取相应措施,制定书籍管理的下一步措施,实现图书馆的个性化服务[5]。
下一步将对图书馆各类图书全部借阅数据应用数据挖掘[6],进行加权聚类分析,判断各类图书的质量,得出非常受欢迎的高质量图书类别,验证各类图书的借阅趋势在一段时间内基本保持不变[7],从而为图书馆的馆藏布局以及图书采购提供理论支持[8]。
[1] Portnoy L,Eskin E,Stolfo S J.Intrusion Detection with Unlabeled Data Using Clustering[C].Proceedings of ACM CSSWorkshop on Data Mining Applied to Security(DMSA-2001),2001.New York:ACM Press 123-130.
[2] 贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究,2007(1):10-13.
LingHe,lingda Wu,Yichao Cai.Survey of Clustering Algorithms in Data Mining[J].Application Research of Computers,2007(1):10-13.
[3] 王路漫.FCM聚类算法在数字图书馆中的应用研究[J].内蒙古大学学报(自然科学版),2010(7):8773-8775.
Luman Wang.Application Based on FCM Clustering Algorithm in Digital library[J].Journal of Inner Mongolia University,2010(7):8773-8775.
[4] 章婷,姚万辉.关联规则和事务集分组技术在图书馆个性化推荐系统中的应用研究[J].电脑知识与技术,2009(11):431-434.
ZHANG Ting,YAOWan-hui.The Application Research of Association Rules and Affairs Grouping Technique in Library Individualized Recommendation System[J].Computer Knowledge and Technology,2009(11):431-434.
[5] 茹蓓,赵芳.聚类算法在图书馆中的应用[J].新乡学院学报(自然科学版),2011(2):41-42.
Pei Ru,FangZhao.The Application of Clustering Algorithm in the Library[J].Journal of Xinxiang University:Natural Science Edition,2011(2):41-42.
[6] 蔡会霞,朱洁,蔡瑞英.关联规则的数据挖掘在高校图书馆中的应[J].南京工业大学学报,2005,27(1):85-88.
Huixia Cai,Ji Zhu,Ruiying Cai.Application of data mining based association rule in the system of library[J].Jonunal of Nan Jing University of Technology,2005,27(1):85-88.
[7] 张付志,姜志英.一种基于聚类技术的数字图书个性化推荐算法[J].计算机应用与软件,2008,25(7):84-85.
ZhiFu Zhang,Zhiying Jiang.A personalized recommendation algorithm for digital library based on clustering technology[J].Computer Application and Software,2008,25(7):84-85.
[8] 黄兰,郭志敏,习万球.利用聚类技术对图书馆读者群的研究分析[J].计算机工程与设计,2007,28(22):5552-5555.
LanHuang,Zhimin Guo,Wanqiu Xi.Utilizing clustering to analysis readers in libary[J].Computer Engineering and Design,2007,28(22):5552-5555.
Research ofWeighted Clustering Algorithm in the Library
Wang Shengming1,Lu Bingliang2
(1.Shenyang Aeronautical Vocational College,Shenyang 110034,China;2.Computer Department,Shenyang Aerospace University,Shenyang 110136,China)
In order to analyze the reader's borrow behavior,the weighted clustering algorithm is used tomine the user's borrowing data in the school library.By analyzing the results of the clusteringmining,we find potential borrowing laws of readers,judge the state of all kinds of books borrowed by readers,and obtain some useful information for librarymanagementwhich can be used to improve the librarymanagement efficiency and resource utilization.Itwill be a good way to optimize collections in the school library.
Data mining;Weighted clustering algorithm;Borrow behaviors;Borrow amount;Personalized service;Analysis of clustering results
10.3969/j.issn.1002-2279.2015.06.013
TP312
A
1002-2279(2015)06-0047-03
王盛明(1973-),男,辽宁省海城市人,副教授,高级工程师,硕士研究生,主研方向:计算机网络与数据库。
2015-02-13
