Hadoop集群部署实验的设计与实现
2015-07-31孟永伟黄建强曹腾飞王晓英
孟永伟,黄建强,曹腾飞,王晓英
(青海大学 计算机技术与应用系,青海 西宁 810016)
Hadoop集群部署实验的设计与实现
孟永伟,黄建强,曹腾飞,王晓英
(青海大学 计算机技术与应用系,青海 西宁 810016)
阐述了Hadoop软件框架中的两大核心技术——HDFS分布式文件系统架构和MapReduce分布式处理机制,设计了Hadoop集群部署实验的具体方案,主要包括实验目的、实验区域的划分、节点的规划等,并且以一组实验设备为例,详细说明了配置方法,给出了实现过程。通过该实验能够让学生从理论和实践上掌握Hadoop有关的技术知识。
Hadoop;集群部署;HDFS;MapReduce;NameNode;DataNode;JobTrack;TaskTrack
在大数据时代,如何存储和管理这些海量数据成为摆在人们面前亟待解决的问题。Hadoop采用分布式处理框架,充分利用计算机集群的强大处理能力,对海量数据进行存储和管理[1-4]。掌握Hadoop集群环境的部署过程,不仅让学生对Hadoop的关键技术有一个清晰的认识,而且为后续学习和研究大数据奠定了良好的实验基础。
1 Hadoop
Hadoop是一个能够对大数据进行分布式处理的软件框架,它以可靠、高效、可伸缩的方式对大数据进行处理[5]。Hadoop分布式的数据处理体系架构由许多元素构成,包括HDFS、MapReduce、Pig、Hive、HBase等。HDFS可以支持千万级的大型分布式文件系统;MapReduce用于超大型数据集的并行运算;Pig可执行加载数据、转换数据格式以及存储最终结果等一系列过程;Hive在Hadoop中扮演数据仓库的角色;HBase用于在Hadoop中支持大型稀疏表的列存储数据环境。Hadoop框架的核心部分是HDFS的分布式数据存储和MapReduce的数据并行处理机制[6-7]。
1.1 HDFS
HDFS处于Hadoop软件框架的最底层,主要存储集群中所有存储节点上的文件,具有高传输、高容错等特点,并且支持以流的形式访问文件系统中的数据,能够实现海量数据的管理。Hadoop集群主要由管理者(NameNode)和工作者(DataNode)两类节点组成,并且分别以NameNode和DataNode模式运行。NameNode主要负责管理文件系统名称空间和控制外部客户机的访问,DataNode响应来自HDFS客户机的读写请求和NameNode的创建、删除和复制块的命令。
在Hadoop集群中,NameNode是唯一的,然而却有大量的DataNode节点,当客户机向NameNode节点发送请求时,它都会将DataNode节点信息返回给客户机。实际的I/O事务并不经过NameNode,NameNode只是将文件的操作映射给DataNode。
HDFS中的文件被分成很多的块,每个文件块都会被复制多份,分别放到不同的DataNode节点中。最常用的策略是采用3个复制块:2个数据块复制存储在同一机架的不同节点,1个复制块存储在另一机架的某个节点[8-9]。DataNode节点定时给NameNode节点发送心跳信息,NameNode根据这些信息确定DataNode节点中的文件块是否正常。如果出现异常,NameNode就会重新复制进行修复,保证了数据的安全性。
1.2 MapReduce
MapReduce的分布式处理机制是Hadoop的另一种核心技术[10]。它位于HDFS之上,由JobTracker和TaskTracker组成。
JobTracker是在单个主系统上启动的MapReduce应用程序,它在Hadoop集群中是唯一的,主要负责控制MapReduce应用程序的对象,在应用程序提交之后,它将提供包含在HDFS中的输入和输出目录。TaskTracker可以有若干个,它主要是执行JobTracker的各种命令,并且将本地节点的状态传送给JobTracker[11-12]。
MapReduce客户机程序启动一个作业并将其进行分片,同时向JobTracker发送作业请求。客户机程序会将运行作业所需要的资源复制到HDFS上,JobTracker接收到作业后,将其放到一个作业队列中,等待作业调度器对其进行调度。TaskTracker会定时地向JobTracker发心跳信息,如果TaskTracker已经准备好运行一个新任务,JobTracker根据输入分片信息为每一个分片创建一个Map任务,并将该任务分配给TaskTracker去执行。对于一个Map任务,JobTracker会选择一个距离输入分片文件最近的TaskTracker去执行,这样节省了网络数据的传输时间;而对于一个Reduce任务,JobTracker简单地从Reduce任务列表中选择一个去执行。Hadoop通过这样的移动计算程序而不是移动数据的方式,避免了集群内和系统间大量数据的频繁移动,提高了机器的处理速度。
2 实验拓扑结构设计
Hadoop集群部署实验的实验目的是:(1)了解Hadoop的关键技术知识;(2)掌握Hadoop集群环境部署过程。实验所需的硬件设备包括PC机、服务器、交换机和网线;软件包括Redhat Enterprise Linux 5、hadoop1.0.3、jdk-6u21-linux-i586-rpm.bin、SecureCRT 5.5和Windows 7。
本实验室分为学生区和实验区。实验区放置供学生做实验使用的服务器以及连接服务器的以太网交换机各若干台,通过Vlan将每3台服务器划分为一组,提供学生部署Hadoop集群环境的基本硬件,每台服务器安装了Redhat Enterprise Linux 5操作系统。学生区有PC机和交换机各若干台,PC机上面安装Windows 7操作系统和SecureCRT 5.5软件。每2个学生一组,通过以太网进行远程管理与配置。为了方便说明问题,选取一组实验设备进行详细配置,其拓扑结构如图1所示。
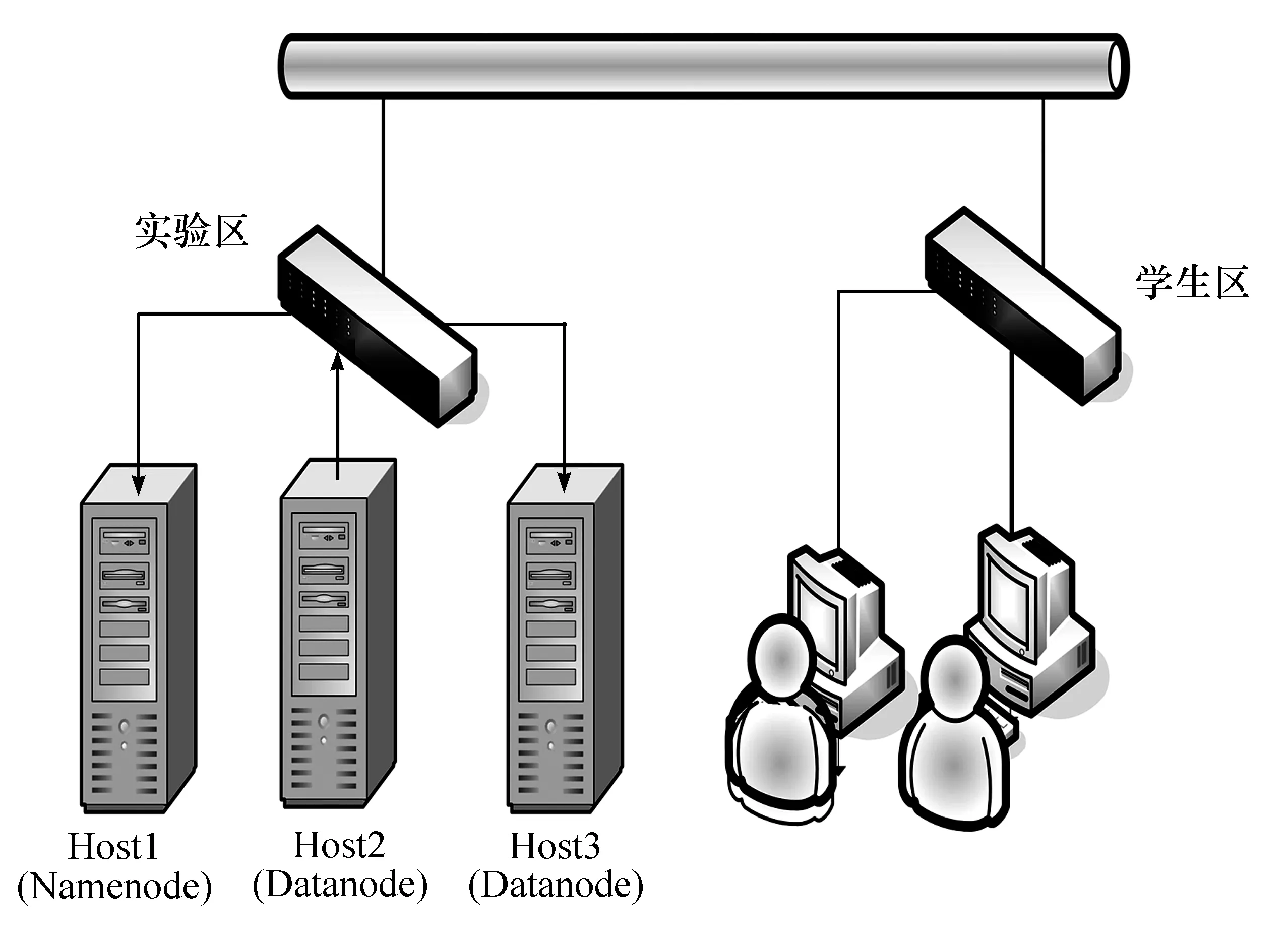
图1 Hadoop集群拓扑结构
3台服务器中的一台服务器作为Hadoop分布式文件系统(HDFS)的NameNode及MapReduce运行过程中的JobTracker,这台机器称为主节点(Host1),其他2台服务器作为HDFS的DataNode以及MapReduce运行过程中的TaskTracker,称为从节点(Host2和Host3)。节点部署情况见表1。
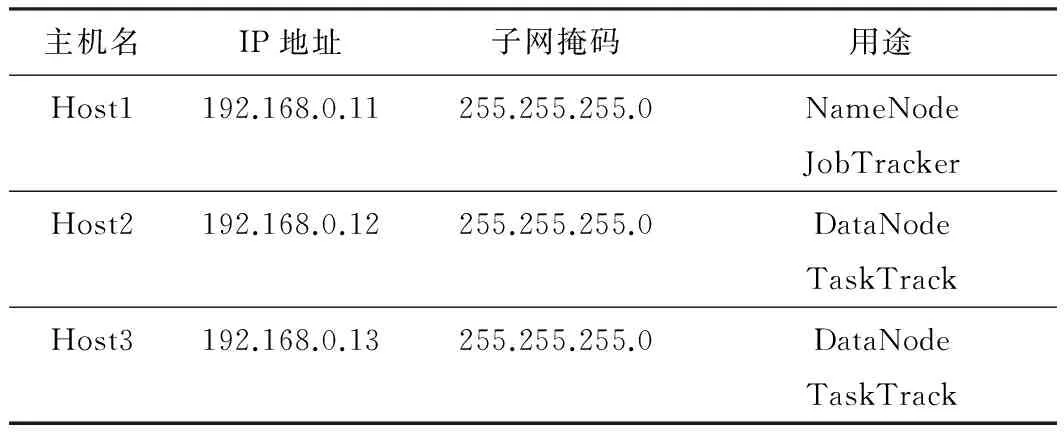
表1 节点部署情况
3 实验过程及实现
3.1 安装基础工具
(1) 在Host1节点上配置/etc/hosts文件并且安装JDK(假设jdk-6u21-linux-i586-rpm.bin安装包在/usr/local目录下)。
[root@Host1~]vi /etc/hosts 192.168.0.11 Host1 192.168.0.12 Host2 192.168.0.13 Host3 [root@Host1~]cd /usr/local [root@Host1local]sh -ivh jdk-6u21-linux-i586-rpm.bin
(2) 配置环境变量并使之生效。
[root@Host1local]vi /etc/profile JAVA_HOME=/usr/java/jdk1.6.0_21 CLASSPATH=.:$JAVA_HOME/lib/tools.jar PATH=$JAVA_HOME/bin:$PATH export JAVA_HOME CLASSPATH PATH [root@Host1 conf]# source /etc/profile
(3) 验证是否安装成功。
[root@Host1~]# java -version java version ″1.6.0_21″ Java(TM)SE Runtime Environment(build 1.6.0_21-b06) Java HotSpot(TM)Client VM(build 17.0-b16,mixed mode,sharing) [root@Host1 ~]
(4) 按上述方法配置其余2个节点。
3.2 配置3台节点的SSH无密码登录
(1) 在Host1节点上生成密码对。
[root@ Host1 local]# ssh-keygen -t rsa [root@ Host1 local]#cat root/.ssh/id_rsa.pub>>/root/.ssh/authorized_keys
(2) 将公钥拷贝到Host2和Host3的/root/.ssh目录下并安装。
[root@ Host2.ssh]# mkdir /root/.ssh/ [root@ Host3.ssh]# mkdir /root/.ssh [root@ Host1 local]# scp /root/.ssh/id_rsa.pub root@ Host2:/root/.ssh [root@ Host1 local]# scp /root/.ssh/id_rsa.pub root@ Host3:/root/.ssh [root@ Host2 .ssh]#cat id_rsa.pub >> authorized_keys [root@ Host3 .ssh]#cat id_rsa.pub >> authorized_keys
(3) 验证SSH无密码登录(出现如下提示而无需输入密码,表明上一步设置成功)。
[root@Host1 ~]#ssh host1 Last Login:Wed May 14 05:02:37 2014 from host1 [root@Host1 ~] [root@Host1 ~]#ssh host2 Last Login:Wed May 14 05:03:30 2014 from host1 [root@Host2 ~] [root@Host1 ~]#ssh host3 Last Login:Wed May 14 04:48:24 2014 from host1 [root@Host3 ~]
3.3 安装并配置Hadoop
(1) 将Hadoop-1.0.3.tar.gz解压到/opt目录下。
[root@ Host1 /opt]tar -zxvf hadoop-1.0.3.tar.gz
(2) 修改Hadoop-env.sh 配置。
[root@Host1 opt]# cd hadoop-1.0.3/conf [root@Host1 conf]# vi hadoop-env.sh export JAVA_HOME=/usr/java//jdk1.6.0_21
(3) 配置环境变量并使之生效。
[root@Host1 conf]# vi /etc/profile JAVA_HOME=/usr/java/jdk1.6.0_21 HADOOP_HOME=/opt/hadoop-1.0.3 CLASSPATH=.:$JAVA_HOME/lib/tools.jar PATH=$JAVA_HOME/bin:$ANT_HOME/bin:$HADOOP_HOME/bin:$PATH export JAVA_HOME HADOOP_HOME CLASSPATH PATH [root@Host1 conf]# source /etc/profile
(4) 配置masters和slaves文件。
[root@Host1 conf]#vi masters 192.168.0.11 [root@Host1 conf]# vi slaves 192.168.0.12 192.168.0.13
(5) 配置文件hdfs-site.xml。
[root@Host1 conf]vi hdfs-site.xml
(6) 配置文件mapred-site.xml。
[root@Host1 conf]vi mapred-site.xml
(7) 配置文件core-site.xml。
[root@Host1 conf]vi core-site.xml
(8) 发布部署。
[root@Host1 conf]scp -r/opt/hadoop-1.0.3 root@ Host2:/opt/hadoop-1.0.3 [root@Host1 conf]scp -r/opt/hadoop-1.0.3 root@ Host3:/opt/hadoop-1.0.3
3.4 启动Hadoop
(1) 格式化分布式文件系统。
[root@Host1 hadoop-1.0.3]# bin/hadoop namenode -format
(2) 启动hdfs守护进程。
[root@Host1 hadoop-1.0.3]# bin/start-dfs.sh
(3) 启动mapreduce守护进程。
[root@Host1 hadoop-1.0.3]# bin/start-mapred.sh
3.5 验证安装是否成功
(1) 使用jps命令查看启动的守护进程。
[root@Host1 hadoop-1.0.3]#jps 28609 SecondaryNameNode 28703 JobTracker 30120 Jps 28438 NameNode [root@Host1 hadoop-1.0.3]# [root@Host1 hadoop-1.0.3]#ssh host2 Last Login:Wed May 14 05:04:54 2014 from host1 [root@Host2 ~]#jps 27758 DataNode 27879 TaskTracker 29360 Jps [root@Host2 ~]# [root@Host1 hadoop-1.0.3]#ssh host3 Last login:Wed May 14 05:05:52 2014 from host1 [root@Host3 ~]#jps 29937 Jps 28391 TaskTracker 28266 DataNode [root@Host3 ~]#
(2) 通过浏览器访问。
输入地址:http://192.168.0.11:50070 输入地址:http://192.168.0.11:50030
(3) 在NameNode节点上查看集群状态。
[root@Host1 hadoop-1.0.3]#bin/hadoop dfsadmin -report Configured Capacity:18149834752(16.9 GB) Present Capacity:10894651392(10.15 GB) DFS Remaining:10894479360(10.15 GB) DFS Used:172032(168 KB) DFS Used%:0% Under replicated blocks:0 Blocks With corrupt replicas:0 Missing blocks:0 Datanodes available:2(2 total,0 dead) Name:192.168.0.12:50010 Decommission Status:Normal Configured Capacity:9074917376(8.45 GB) DFS Used:86016(84 KB) Non DFS Used:3626475520(3.38 GB) DFS Remaining:5448355840(5.07 GB) DFS Used%:0% DFS Remaining%:60.04% Last contact:Wed May 14 05:34:14 PDT 2014 Name:192.168.0.13:50010 Decommission Status:Normal Configured Capacity:9074917376(8.45 GB) DFS Used:86016(84 KB) Non DFS Used:3628707840(3.38 GB) DFS Remaining:5446123520(5.07 GB) DFS Used%:0% DFS Remaining%:60.01% Last contact:Wed May 14 05:34:12 PDT 2014
4 结束语
Hadoop是一种新兴的技术,越来越多的学者加入到该项技术的学习和研究之中。本文阐述的Hadoop的两个关键技术HDFS分布式文件系统架构和MapReduce分布式处理机制,以及给出的Hadoop集群部署实验的方案及实现过程,可以帮助学生从理论和实践方面更好地了解Hadoop技术。通过Hadoop集群部署实验,能够让学生从理论和实践上更好地掌握Hadoop有关的技术知识,充分利用计算机集群的强大处理能力,对海量大数据进行管理和研究。
References)
[1] White T.Hadoop权威指南[M].周敏奇,钱卫宁,金澈清,等译.2版.北京:清华大学出版社,2011.
[2] 陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2011.
[3] 王鹏.云计算的关键技术与应用实例[M].北京:人民邮电出版社,2010.
[4] 王彦明,奉国和,薛云.近年来Hadoop国外研究综述[J].计算机系统应用,2013,22(6):1-5.
[5] 百度百科.Hadoop[EB/OL].[2014-04-30].http://baike.baidu.com/view/908354.htm?fr=aladdin#refIndex_7_908354.
[6] 郝树魁.Hadoop HDFS和MapReduce架构浅析[J].邮电设计技术,2012(7):37-42.
[7] 彭仁通.Hadoop的核心技术研究或概述[J].科技广场,2012(5):39-41.
[8] 朱颂.分布式文件系统HdFS的分析[J].福建电脑,2012(4):63-65.
[9] 许春玲,张广泉.分布式文件系统Hadoop HDFS与传统文件系统Linux FS的比较与分析[J].苏州大学学报,2010,30(4):5-9.
[10] Dean J, Chemawat S. MapReduce:simplified data processing on large clusters[J].Communication of the ACM,2008,51(1):107-113.
[11] 谢桂兰,罗省贤.基于Hadoop MapReduce模型的应用研究[J].微型机与应用,2010(8):4-7.
[12] 李玉林,董晶.基于Hadoop的MapReduce模型的研究与改进[J].计算机工程与设计,2012,33(8):3110-3116.
Design and implementation of deploying Hadoop cluster experiments
Meng Yongwei,Huang Jianqiang,Cao Tengfei,Wang Xiaoying
(Department of Computer Technology and Applications,Qihai University,Xining 810016,China)
This article elaborate on two core technologies of Hadoop software framework, i.e., the architecture of Hadoop distributed file system and distributed processing mechanism of MapReduce. The concrete plan about the experiment of deploying Hadoop clusters is designed,which mainly includes the purpose of experiment,the division of experimental area,the planning of nodes.And by the case of experimental equipment, the configuration methods and implementation procedure are illustrated in detail. Through the experiment the students can master the technical knowledge related to Hadoop from theory and practice.
Hadoop; cluster; HDFS; MapReduce; NameNode; DataNode; JobTrack; TaskTrack
2014- 05- 27
清华携手Google助力西部教育-科研培育项目“在线社会网络模型研究及鲁棒性分析”;国家自然科学基金项目(61363019);青海省科技创新能力促进计划项目(2014-ZJ-718;2014-ZJ-941Q)
孟永伟(1983—),男,河南商丘,硕士,讲师,主要研究方向为复杂网络、无线传感器网络、系统结构.
E-mail:ywmeng@aliyun.com
TP311.52
A
1002-4956(2015)1- 0145- 5
