一种热点话题算法在微博舆情系统中的应用
2015-07-24李海生
李海生
(江南造船集团,上海 201913)
微博作为新时代的产物,在短短的几年时间已经得到了迅猛发展,目前已经成为了日常生活必不可少的沟通、分享工具。一般一条中文微博字数限制在140字左右,但仅仅就这140字的微博却能表达出一个人的观点、思想和情绪,大大方便了信息的传递、获取与共享,微博已经一跃成为时下最方便、最流行的互联网应用之一。微博作为互联网应用杰出的代表,在逐步地影响着人们的日常生活,微博每天大约会产生千万条数据,在这千万条数据中又会产生几万个话题,如果用户想要更深入的了解热点话题的话,就需要不断地去刷新动态,用自己独到的眼光去判断热点话题,分析微博传递的信息,这显然是不合理的,而且了解的信息不完全,得不到理想的结果。怎样从庞大的热点话题中检测出热门话题,快速让读者了解热门话题,这是时下里的一个热点研究方向。同时,微博发布方式便捷,使得热点话题得到快速传播,这些特点也会使得虚假信息和片面信息容易泛滥,成为社会的安定的隐患,而且对于某些部门,他们密切关注着这些话题的动向。所以本文提出一种热点话题检测算法,对时下最热门的微博系统之一的新浪微博做分析,来帮助相关人员自动检测热门话题,达到实时预警功能,形成一套微博舆情系统。
1 相关工作
目前提及话题检测通常都会提及 TDT,TDT的英文全称是 Topic Detection and Tracking[1],最早的研究主要是针对事件的检测,通常的话题检测是面向正式的新闻媒体信息流,其主要任务是识别当前话题,搜集相关话题和对已经检测的话题进行追踪。TDT中的话题识别与跟踪的基本思想源于1996年,来自 DARPA、卡内基⁃梅隆大学、Dragon系统公司以及麻萨诸塞大学的研究者开始定义话题识别与跟踪研究的内容,并开发用于解决问题的初步技术。目前国内也有一些类似的系统,例如北大方正技术研究院推出的方正智思舆情预警辅助决策支持系统,其成功地实现了针对互联网海量舆情自动实时的监测分析,有效地解决了政府部门以传统的人工方式对舆情监测的实施难题。
就目前来看,微博舆情热点发现的研究主要是在对中文信息的处理中和数据挖掘领域。在中文信息处理中,涉及到的技术有中文分词技术、多维向量空间技术。而在数据挖掘技术方面,有舆情信息采集、自动分类、自动聚类等。黄晓斌在分析文本挖掘技术的基础上提出网络舆情信息挖掘分析模型[2],并以实例说明文本挖掘在网络舆情分析中的应用;钱爱兵分析了网络舆情的基本情况,设计了一个基于主题的网络舆情分析模型[3];郭建永等结合划分聚类和凝聚聚类的优点提出了一种增量层次聚类算法应用于主题发现[4];于满泉等将自然语言处理与信息检索技术相结合,提出针对事件特点的切实有效的单粒度话题识别方法[5];刘星星等设计了一个热点事件发现系统,该系统面向互联网新闻报道流,能自动发现任意一段时间内网络上的热点事件[6];王伟根据对网络舆情分析的需求,构建了基于聚类的网络舆情热点问题发现及分析系统[7]。对于海量的网络舆情信息,如何提高分析处理的效果和效率,提高网络舆情热点分析的准确度和效率,仍然是目前研究热点。
2 系统总体设计
本文是针对目前主流三大微博之一的新浪微博做的一个分析和检测,旨在反映某个时间段内的热点话题,通过实时对热点话题的检测,达到一个舆情预警的功能。本文构建的微博舆情系统架构设计如图1所示。

图1 微博热点话题分析系统架构设计
2.1 微博数据采集
微博数据采集采用的是网络爬虫技术,主要是针对新浪微博获取数据源,他能够遍历新浪微博范围内整个Web空间的数据源,并采集数据,然后通过索引将网络爬虫的数据建立索引并保存到索引数据库,同时为了保证索引的实时更新,网络爬虫会不断的工作,对新浪微博中的数据源进行重新搜索。微博信息采集实现以下功能:
(1)对新浪微博全网的搜索,将有效信息保存,去除一些重复和无效数据;
(2)网页分析、信息存储,实现页面的去重、去噪,删除垃圾信息;
(3)多线程、分布式高速采集;
(4)增量更新,只采集上次更新数据,而不是全部一次采集一遍,从而保证了信息更新的效率。
2.2 微博数据处理模块
2.2.1 数据预处理
微博文本有其自身的特点,表达方式多样性,且包含网页链接、图片、英文字母等等,本文需要对其进行预处理,步骤如下:
(1)对微博数据进行去重、去噪、标签过滤等操作,例如此微博,“今天我非常开心,巴西首场如愿获得了胜利,恭喜巴西,巴西世界杯看球攻略http://t.cn/RvoEUxI”,针对此微博数据,需要对其进行预处理,去除链接、特殊符号、英文字母,得到纯净的微博数据,如“今天我非常开心,巴西首场如愿获得了胜利,恭喜巴西,巴西世界杯看球攻略”。
(2)去除表情符号,为后面的分词处理做准备。
(3)对微博进行分词处理,本文使用中科院ICT⁃CLAS系统[8]进行分词与词性标注。例如“今天我非常开心,巴西首场如愿获得了胜利,恭喜巴西,巴西世界杯看球攻略”,通过分词系统可得到{今天/t我/rr非常/d开心/a,/wd巴西/nz首场/d如愿/vi获得/v了 /rr胜利/n,/wd恭喜/v巴西/nz,/wd巴西/nz世界杯/nz看/v球/n攻略/n}。
(4)对分词后的文本进行粗降维,即将停用词,低频词从文档中去除。
2.2.2 特征选取
由于抽取样本网页正文的内容作为网页的特征向量待选集合,分词后的特征向量空间维度很大,导致算法效率会受到影响。 特征选取的目的就是进一步过滤掉信息量不大,对舆情热点发现影响不大的词,达到对网页特征向量降维的效果,从而提高处理的效率和降低计算复杂度。这里采用的降维方式是通过统计方法构造网页主题评价函数,对每个特征向量进行评估,选择那些符合预定阈值的词作为网页的特征项。
常见的特征选取方法有很多:信息增益法,互信息法,统计量法,交叉熵,优势率和文档频率法等。 其中文档频率是最简单,同时也是最有效的文本特征选取方法之一,在此采用它作为特征选取的方法。 在运用该方法时,首先计算各个征词的文档频率,然后通过网页主题评价函数进行评估(评估依据为文档频率低的特征不包含对分类(或聚类)有用的鉴别信息,因而对分类结果没有什么影响),高于预定阈值的那些特征词保留作为特征项。 特征词出现的频率 P(k)定义为:
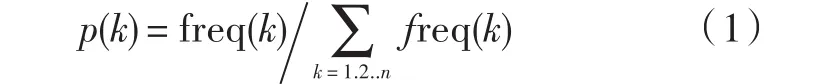
式中freq(k)为网页特征词语频率。
2.2.3 向量表示
特征提取之后,在此采用目前应用最广泛的向量空间模型VSM(Vector Space Module),该模型基本思想是:经过文本预处理后,将文本看作一系列无序词条的集合,继而表示为高维空间向量。将文本中每个词条Ti作为惟一特征用来表示,权值Wi表示一个文本中的第i个元素或特征的重要性,这样每条微博m就可以映射为此空间中的一个点,用向量表示为Vm=(T1W1,T2W2,…,TnWn)。再通过句子相似度计算获得文本之间的差距,然后我们就可以判断微博之间的相似性。用向量空间模型表示微博消息的优点:将文本内容用向量化表示,使得自然语言能够被计算机理解,具有可操作性和可计算性;模型概念容易理解,应用过程易于实现;通过对权值的计算能够体现不同词语在微博语句中的重要性;在计算文本相似度时有更大选择空间。该模型的缺点:将微博消息中的词条离散化,词的次序、词与词之间的关系等因素将不被考虑,因此当以词为向量基本单位时,可能造成空间维数较高,影响效率,所以需要进行降维处理。
2.3 热点话题发现模块
热点发现模块主要是将经过预处理的微博数据进行分析,获取在一定时间周期内发布信息流中,一组内容相同和相近的话题微博,当参与者超过一定的阈值H时则认定为热点话题MT。微博话题描述的形式为,MT=(MS,N,T,MF),其中 MS表示非空的微博信息集合;N表示参与者的个数;T表示微博消息发生的时间跨度;MF表示抽取时间的微博特征词汇表。根据热点话题的定义,每次热点话题提取和分析的对象,是时间跨度T内微博的集合,表示为CM,MS属于CM。因此微博的话题发现就是基于微博内容的归类处理,每一类微博就能说明用户群所关注的一个焦点,即热点话题。
在微博内容的划分上,由于微博数量巨大且内容复杂,并且在研究中没有先验学习语料,所以不能直接通过有监督的文本分类方法来获得归类后的微博子集合。因此类别特征能被视为话题的对应体,通过计算每个微博话题的特征词表就能够发现这段时间内微博中的热点话题。在无监督学习条件下直接获取每一个话题对应的特征词表是不现实的,可以通过词频统计[9]的方式发现整个微博流中的特征集合,根据内容关联度对这个特征集合进行划分就能得到每个微博话题对应的特征词表,每个特征词表对应一个话题,通过这样的方法完成微博的话题发现。
2.4 系统管理模块
任何一个系统都离不开系统管理模块,本系统管理模块主要是针对用户角色设定的,实现用户、访问权限、数据分离、数据安全控制等。主要由用户管理模块和角色权限管理模块两个模块组成。系统管理模块是系统的核心,同时也控制着数据访问权限。
2.5 测试指标
文本分类算法常用的评价指标有召回率R、准确率P和F值,计算公式如下:
召回率:
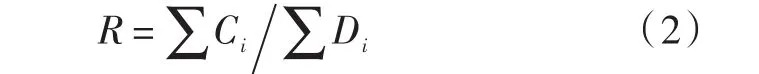
准确率:
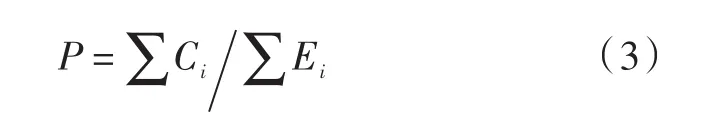
F值:

式中Ci为实验分类为C的微博数;Di为实验总的微博数;Ei为微博分类为C的微博条数,C表示微博类别。
3 实验分析
本文利用如上所述的方法采集新浪微博数据28 000条,经过预处理分析,筛选出19 830条数据,利用这近2万条数据进行分析计算,得到话题有{好声音,532},{爸爸去哪儿,453},{感动中国,344},{文明出行,298}等,其中的数字表示词频。微博话题检测词频如表1所示。

表1 微博话题检测词频
表1为系统经过分析后的数据,近期微博热点话题为#中国好声音#,虽然只有2万条数据,但是其占据了很大比例。对于这套分析系统采用第2节所示的测试指标,召回率为0.657 76,准确率为0.708 53,F值为0.582 35。召回率、准确率和F值都在0.6左右,所以对比往常的分析方法还算正常的结果范围。利用系统分析出的热点话题,与当下的热点话题相比确实差不多,中国好声音确实比较流行。
4 结 语
本文利用网络爬虫算法结合新浪微博的API获取新浪媒体的微博数据,然后对微博数据进行过滤,预处理得出比较纯净的微博数据,然后结合热点话题算法构建了一套微博舆情分析系统,此系统经过试验证明有一定的可行性,能获得当前的微博话题。但是该系统还存在很多问题,例如无法对热点话题进行实时的预警,对一些敏感词汇进行追踪,查询发布源头等,这些都是下一步系统所需要改进的地方。
[1]ALLAN James,PAPKA Ron,LAVRENKO Victor.On ⁃line new event detection and tracking[C]//Processing of 21st Annual International ACM SIGIR Conference on Research and Develop⁃ment in Information Retrieval.Amherst:University of Massa⁃chusetts,1998:37⁃45.
[2]黄晓斌,赵超.文本挖掘在网络舆情信息分析中的应用[J].情报科学,2009(1):94⁃99.
[3]钱爱兵.基于主题的网络舆情分析模型及其实现[J].情报分析与研究,2008(4):49⁃55.
[4]郭建永,蔡永,甑艳霞.基于文本聚类技术的主题发现[J].计算机工程与设计,2008(6):1426⁃1428.
[5]于满泉,骆卫华,许洪波,等.话题识别与跟踪中的层次化话题识别技术研究[J].计算机研究与发展,2006,43(3):489⁃495.
[6]刘星星,何婷婷,龚海军,等.网络热点事件发现系统的设计[J].中文信息学报,2008,22(6):80⁃85.
[7]王伟,许鑫.基于聚类的网络舆情热点问题发现及分析[J].情报分析与研究,2009(3):74⁃79.
[8]ICTCLAS Chinese Word Segmentation.Download ICTCLAS[EB/OL].[2012⁃07⁃02].http://ictclas.org/ictclas_download.aspx.
[9]张清亮,徐健.网络情感词自动识别方法研究[J].现代图书情报技术,2011(10):24⁃28.
