澳大利亚国家图书馆网页存档项目研究
2015-07-22颜运梅广州图书馆广东广州510623
颜运梅(广州图书馆 广东广州 510623)
澳大利亚国家图书馆网页存档项目研究
颜运梅
(广州图书馆广东广州510623)
〔摘要〕澳大利亚国家图书馆网页存档项目简称PANDORA,是选择性网页存档的代表项目之一。文章介绍了PANDORA项目的整体情况,论述了选择性存档和全域收割这两种不同采集方法的优劣,指出PANDORA项目的持续发展在具体实施上面临的问题,包括电子出版物的版权、资金支持以及如何跟上网络技术发展等。
〔关键词〕NLA网页存档选择性采集全域收割PANDORAPANDAS G250.73
1 网页存档的意义
网络资源具有更新快、易逝性、价值性的特点,留存网页信息的目的在于更好地保存关于重大事件的记录以及时代文化与思想性作品。而现在的图书馆主要是为保存纸制印刷品而设置的,电子出版物和其他非印刷产品很容易被遗漏。网络信息和在线出版网作为图书馆物理馆藏的有效补充,已经引起诸多图书馆的重视。
2 现状
网页存档从20世纪90年代中期开始发端,欧美一些经济较为发达的国家已纷纷建立起网页存档项目。至2003年,一共有12个国家图书馆联合建立了国家互联网保护同盟,共同商讨保护互联网信息资源实践中的国际合作问题。至20世纪初期,已有近20个国家都建立了自己的网页存档项目。
近些年,网络信息资源又重新引起了一些国家图书馆的重视。大英图书馆曾在2005年启动UKWAC网页存档项目,2013年4月9日又宣布启动一项存档计划——以大英图书馆为首的六所图书馆对网页上的海量电子信息进行存档,逾五百万个英国网站上超过十亿网页的内容,以及Twitter上的推文和Facebook条目都被纳入存档范围,涵盖电子书、报纸的IPad版本以及其他电子格式的出版品,甚至包括网页上内嵌的视频与音频材料,但暂不包括YouTube和Spotify等视频和音频网站上的内容,“计划十年内存诸一千万亿字节的内容,所有这些信息都将免费提供给公众使用。”[1]
美国国会图书馆在20世纪90年代中期曾建设MINERVA专题性存档项目,2013年初,宣布已完成对Twitter现有全部推文的收集,并已开始对多达1700亿条以上的推文进行存档和整理。国会图书馆将Twitter推文称为一种重要的新型馆藏资料,“对信件、日记、期刊以及其他馆藏资源形成了补充,有时甚至可以替代后者。”[2]
国内对网页存档项目的研究发端于2009年,之后陆续有相关文章发表。但对澳大利亚国家图书馆(下文称NLA)的网页存档项目——PANDORA项目暂未有相关学术文章发表。PANDORA项目是选择性存档网页的代表项目,NLA作为最早参与IIPC项目的机构之一,其技术、经验都有可供借鉴之处。
3 项目概述
3.1概况
PANDORA(Preserving and Accessing Networked Documentary Resources of Australia),即保存和访问澳大利亚的网络文献资源。PANDORA项目始于1996年,NLA是首批建立网页存档项目的国家图书馆之一。2006年12月,为了更加紧密地将国家图书馆网页存档计划和数字化保存活动结合起来,在NLA的馆藏管理部内部成立了一个新的分部门——网页存档和数字化保存部门,其战略目标就在于更好地结合网页资源描述和搜集功能,并在存档数据中发展和应用数字化保存管理。
NLA开发出一套PANDORA数字化存档系统Digital Archiving System(简称为PANDAS),这个基于网络的应用系统允许各参与馆的负责人通过由NLA负责维护的一些设施开展网页资源的存档工作。存档文件元数据的管理、创建并保存在PANDAS,包括详细的出版者信息、允许存档的日期、收割的频率、存档的元数据等都被自动收集到PANDAS。PANDAS最初是作为一项研究成果于2001年6月份投入应用,2002年发布了第二代增强版本,2007年6月推出了经过重新设计和功能加强的第三代系统。目前,NLA计划增强PANDAS软件的功能,包括增加存档的元数据,收集并提供一个用户界面,使管理人员能够更轻松地访问元数据的范围。[3]
3.2合作共建
NLA始终坚持在PANDORA存档建设中采取合作共建的方法,并积极促成澳大利亚国立图书馆、各州图书馆以及其他文化机构的参与,包括如何选择、存档和分类存档等。合作的图书馆包括:澳大利亚各州立图书馆、北方图书馆、国家声像档案馆、澳大利亚战争纪念馆、澳大利亚国家美术馆,以及澳大利亚原住民及托雷斯海峡居民研究所。[4]
PANDORA采集目标不是澳大利亚所有的在线出版物和网站,而是保存那些被认为有长期研究价值的网上出版物和网站。国家图书馆旨在存档那些具有国家意义的内容;州立图书馆负责存档有关州或者区域性的资源;国家声像档案馆负责网站相关的音乐和电影;战争纪念馆存档有关澳大利亚军事历史的相关网站;原住民及托雷斯海峡居民研究所负责存档原住民的出版物和网站。
3.3捕获频率
捕获网站的频率取决于网站和出版物的性质,特别是出版物的出版计划、内容的价值、网站的生命周期和稳定性。电子专著出版物只需要拍摄一次;某些重要的事件必须每天存档,如悉尼奥运会。PANDAS基本上会根据存档的实际情况决定,对特定目标内容的收割每天不会超过一次。
3.4动态站点、深层网页采集
澳大利亚采集在线出版物的主要方法是通过收割软件收集副本并将它们添加到存档文件。若要访问目标站点,收割软件需要能够导航的HTML链接。深层网页是对应表层网页的概念,指的是那些通过搜索引擎及采集程序无法访问的页面,一般由后台数据库动态生成。越来越多的出版物和网站结构数据库有其他互动或动态内容,收割软件不能处理,通常站点需要在搜索文本框输入条款,或从下拉框选项中选择。
PANDORA是否收割网站所有层次的网页,这取决于网站的性质,但通常会收割整个网站。大型网站仅选择某个特定的倡议或程序有关的信息站点的一部分,例如,政府部门的网站;大型综合性的网站只选取其中某种出版物,例如,电子出版物、通讯、科学或技术报告。一般只存档属于该网站本身目录的链接,不存档引向其他站点的链接,主要是因为没有存档其他站点的权限。
受开放内容运动的影响,网页存档的软件工具都是开源的,经过一定的开发整合就可以很好的嵌入到项目中。在国家互联网保护同盟的合作框架下,成员开发出来的技术工具是可以共享的,所以在软件技术方面是趋于成熟和稳定的,并已走出实验性的阶段。NLA开发了Xinq工具,可将出版商提供的数据存放到一个通用的接口上。Xinq已通过Source Forge(开源软件分享网站)成为可分享的开放源码[5]。
3.5电子出版物的呈缴
在网络存档的实践早期,法律问题是关注的焦点,国家级的图书馆作为主办方和版权所有者都需要法律的保障。在法律条文没有明确规定在线资源呈缴的情况下,一般多采取与版权所有者协商的做法,取得授权后才能采集。
澳大利亚呈缴法依旧遵循《呈缴本制度》和《1968年版权法》,法案中还没有规定电子出版物的呈缴。对于电子出版物(网络出版物),NLA必须经过出版社许可,使用收割软件在出版商的网站上下载或者拷贝出版物。在某些情况下,出版商只需将出版物的标题通过邮件发给图书馆,如果是很大型或者特别复杂的出版物的网站,则将要求出版商将磁盘寄送给图书馆。
澳大利亚PANDORA计划中对网络出版物的自愿呈缴范围进行了限定,以下网络信息都没有纳入缴送范围:聊天室、公告板、新闻组、游戏、个人文章、有印刷版的在线日报、在线图书、在线期刊、以组织因特网信息为唯一目的的门户网站、推销和广告网站、对其他来源信息进行编辑不具有原创性内容的站点等。
3.6存档资源范围
PANDORA选择的内容很大一部分是关于澳大利亚或是社会、政治、文化、宗教、科学、经济等关联到澳大利亚及澳大利亚作家写的,构成了对国际知识的贡献。它的服务器可能位于澳大利亚或者海外,资源的内容是存档首要的选择因素。PANDORA存档项目包含广泛的出版物和网站,优先收集政府刊物及学术电子期刊,此外还有许多其他类型的网站。
3.7商业出版物的访问
PANDORA存档的大部分资源都可以公开访问,但具有一定保密性的商业出版物必须与出版商协商,以确定适当的限制期限,通常在允许访问的期限内,该项目在商业上是可以公开的。存档时,PANDAS可以设置存档文件的访问权限,可以限制在一段时间内访问,比如从存档日期计一年内;或者设置一组到期日期,到期后则不能再访问;还可以控制访问密码,必须收到密码后方可访问。在NLA或其他参与者的电子阅览室里可以访问这些资源,可以打印副本,但是禁止复制和发送电子邮件。
3.8持久标识符
NLA致力于提供PANDORA项目存档和其他数字集合的长期访问。因此,在电子出版物和 Web 站点存档时,PANDAS会自动为其分配唯一的持久标识符,并且标识符被记录在该标题条目页面的底部,方便用户的引用。[6]
持久标识符指对数字对象(例如文章、数据集、图像或数据流)进行持续标识,可以使这些数字资源的定位和范围具有唯一性,把它们与相关的作者及其它实体(如机构、项目或研究团体)相关联,使其得到持续、可靠的发现、引用和重用。
除了在标题级别提供一个持久的标识符,系统也可以给所有的组件部件创建一个持久标识符,例如,为某一期的电子杂志上的一篇文章,或一个网站上的一张图像、一个表。持久标识符将始终指向它所标识的资源,它可以被引用而且确保该链接永远不会断开。唯一的持久标识符不能在其他网页存档资源中提供,这是PANDORA项目的特色之一。
3.9资源发现途径
NLA建立了PANDORA的专题网页,可以从项目的主页上访问到这些存档文件。可用的访问路径有:PANDORA主页上的存档标题的字母列表;PANDORA主页上存档标题的主题列表,分为文化、艺术、科学等18个大类;国家书目数据库和其他参与者的在线目录的热链接;商业搜索引擎(如Yahoo和Google等)可以搜索到存档文献的标题。PANDORA在收割采集时已将存档文献编目、存档资源作为国家图书馆的有效馆藏资源的一部分,通过NLA的一站式搜索引擎(Trove)可以直接检索,可输入任意词检索。[7]
为了增加资源被发现的机会,PANDORA还允许添加搜索框至用户或者个人网页,帮助更多的访问者访问PANDORA资源。用户只需要将搜索框的HTML代码复制并粘贴到用户的网站上即可将一个PANDORA的搜索框添加至用户的网页,以增加PANDORA资源被发现途径。
3.10存档数据格式
PANDORA存档格式包含多媒体、各种动态格式以及文本文件,采集了许多在原来的网站上已经无法获取的多媒体、视频资源。部分动态生成的数据库网站,在存档中被存储为静态页面,插件和其他软件不在PANDORA存档的范围。截至2013年5月,PANDORA项目共采集了约56%的政府出版物,存档总大小约8.52万亿字节,2011-2012年存档主页的页面浏览数约为680万次。PANDORA存档的网页记录和数据格式可以通过以下几张图来了解。
新存档的文件,以时间为序在网页上显示,以月为单位统计存档的文件数量。见图1[8]:

图1 PANDORA按时间顺序列表的新存档网页记录

图2 存档文件大小统计(统计于2014年9月26的数据)
从图2[9]中可以看出2014年9月份采集到文件数、实例数和数据大小,与8月份收集数据的比较情况。

图3 存档网页集合的详细目录数据
从图3[10]可以看出,存档网页集合的详细目录数据包括文件名、URI、存档日期,点击所抓取网页对应的URI即可直接进入相关网页。
在NLA的一键式搜索引擎Trove中选择“Archived websites”项,以“Parallel”为关键词检索,结果有528项与“Parallel”相关的存档网页,同时显示了网址链接和存档日期,点击“VIEW528”则相关网页是以存档时间为序呈现。见图4[11]:

图4 存档网页集合的搜索结果显示
PANDORA重视网页资源的利用,而不仅仅是保存。对资源使用情况,NLA做了详细的记录。见图5[12]:
从图5中可以看出,PANDORA网页的使用报告衡量指标包含网页访问人次、页面访问数、页面点击数、带宽。从2014年1月至10月,PANDORA的使用率均保持在一个比较稳定的数量,前10个月的访问人数总和超过835万,页面浏览数超过7468万,点击率超过8854万人次,带宽1073.32GB。
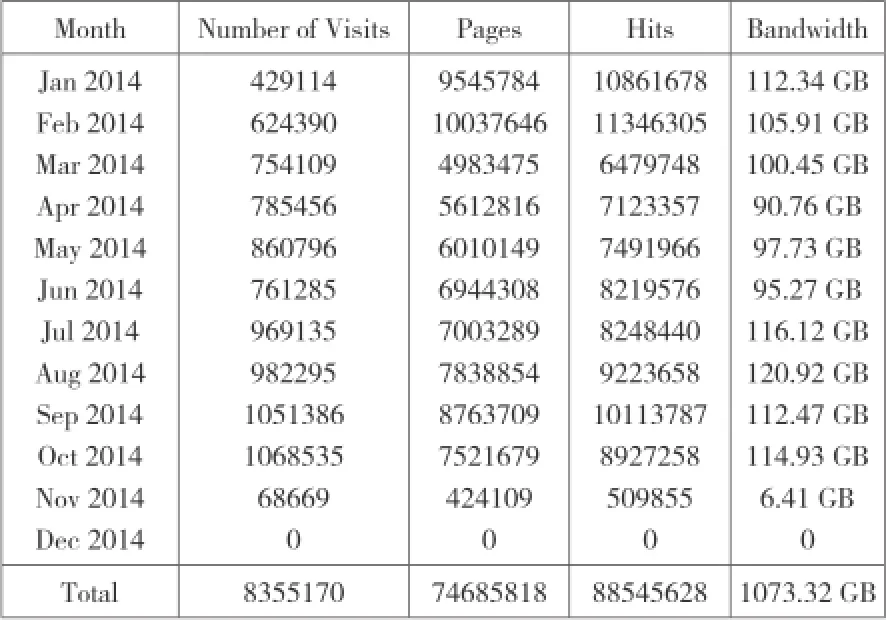
图5 PANDORA 的使用报告
4 网页存档项目的主要采集方法
目前,众多的网页存档项目按采集方法可以分为三类:选择性采集、全域收割、混合式采集[13]。选择性采集是指在圈定采集对象后以一定频率进行持续性的采集。NLA的PANDORA项目和加拿大、日本国家图书档案馆网页存档项目采用这种方法。全域收割是基于收割软件自动在一定范围内采集资源。瑞典、挪威、芬兰、冰岛和奥地利的国家图书馆采用此种方法。混合式采集是将几种采集方法同时使用。如美国国会图书馆的MINERVA项目包含选择性存档和全域快照的收集方法;丹麦皇家图书馆采取多管齐下的方法,包含三种不同类型的采集方法:对域名为“.DK”的一年四次的全域收割;对约80%的网站高质量的选择性收割,和每年两三个事件的专题性收割。[14]
5 选择性采集方法的优势与不足
5.1优势
关注质量:存档文件中的每一项都必须先做质量和功能的评估,并且在当前技术水平允许的最大程度。
开放获取:征得出版商或所有者的许可,以确保对出版物尽可能的免费公共获取。
自行定义采集频率:考虑电子出版物的出版进度或网页站点更改的频率,可以单独针对每个选定的标题安排收集日程,并使相关内容聚集在一起,内容尽可能全面。
充分编目:能充分编目存档文件中的每一项,使之可以成为国家书目的一部分,以保证存档资源被充分利用。
分门别类:可以分析并确定个别资源的重要属性和存档资源的类型,以确保未来可实施长久保存策略。
协议采集:对没有获取版权、无法访问的网站,通过与出版商商议存档,收割软件可以重新识别或者使用其他方法采集。
5.2不足
迎合需求:采集方必须判断在未来,研究人员需要什么样的信息资源去迎合用户需求。有所选择必然有所放弃,将不可避免地错过重要资源。
成本较高:选择性采集存档是劳动密集型项目,成本较高,需要一定的人力物力。
断章取义:选择性采集的资源将完整的或原本是一体的、相关联的资源断章取义地分离开来。
还有,诸如采集的资源是否对研究人员有价值?价值如何去证实?这些都是选择性采集必须要考量的问题。
6 全域收割的优劣
全域性收割是尽可能收集所有的网络信息资源的一种方式,是自动收割快照后生成存档,它试图一遍又一遍地收割整个网络,为后人留下尽可能多的Web记录。IA项目采取全域性收割网页保存了许多重要的网络资源,但是它缺乏选择性档案的优势。
6.1没有质量控制
利用收割软件收割的资源缺乏人工干预,没有质量保证,导致有些资源不完整或者缺失功能而不可用。IA每两个月试图将整个Web收割存档,它倾向于收割顶级域名下的资源,而不会收集所有有价值的一切资源。
6.2错过重要资源
IA的收割未经出版商版权许可,这意味着收割机器人必须遵循robot.txt 规则。如果有些网站或者在线出版网没有经过许可和协商,那么收割软件就无法采集,这意味着将会错过一些重要的网络资源。而PANDORA存档中采集重要的出版物和网站会与出版社协商,并且在将其添加到存档文件之前,PANDORA参与者会评估每个标题收割的质量,而且尽可能地维持它原有的外观、功能及内容。从出版商的网站上收集后,每个标题都会被检查以确保其内容和功能的完整。
6.3混合采集
选择性存档和全域快照收割的方式都有其优缺点。最理想的情况是选择性存档辅以全域收割方式采集资源。NLA于2005年与IA展开协作,进行了大规模的全域收割活动作为PANDORA选择性存档计划的补充。迄今为止,已经完成了两次大规模的资源“爬行”,第一次是在2005年的6-7月,收割了共1.85亿份6.69TB的原始数据;第二次则是在2006年的8-9月份[15]。这两次大规模的资源“爬行”过程中采用了自动的GeoIP查询识别机制,其目标是在澳大利亚境内主机中广泛深入地抓取尽可能多的采用.au顶级域名以及那些非.au域名的网页资源。
7 网页存档项目存在的问题
2003 年,NLA加入国际互联网保护联盟和Web工作组领导的一个研究项目。NLA致力于对其所有数字馆藏包括PANDORA项目的长期访问。NLA已经制定了《数字保存政策》;进行数字集合风险评估,特别把重点放在PANDORA项目;并在研究中继续积极参与机构内部及与其他机构合作。PANDORA项目建立了一套完整、成熟的体制,包括制定了系列网页的保存、管理、存取的程序和相关的手册、指南指导工作。
7.1版权问题
在NLA投资数字内容和在线服务的同时,也面临着较大的资源限制。澳大利亚呈缴本的范围现在包括印刷型出版物和录音录像制品,对电子出版物和网络出版物以协商自愿缴送为原则。版权法规定图书馆在每一次试图收集网页信息之前都需要获得版权持有者的许可[16], PANDORA在对电子(网络)出版物存档之前必须与出版商协商才能存档,所以,目前仅能保存一部分网络上的信息。因此,必须改变1968年《版权法案》中的法定送存规则,寻求授权以收集和保存澳大利亚人创造的数字资料。
7.2财政资金
网页存档是一个复杂且人力、物力耗费巨大的项目,不仅要考虑采集成本,还需要考虑后续的存储、维护、开拓及维护技术基础设施的费用。目前,PANDORA存档资金都是从参与者现有持续运营的业务预算中抽取出来的,尽管这个项目花费昂贵,却没有额外的来自政府的资金支持。因此,需要扩大资金来源以支持PANDORA向所有澳大利亚公民传递资源与服务,同时通过有效的财政管理,使政府和私营部门的投资回报达到最大化。
7.3持续存取
由于出版界从印本形式向数字形式转移,NLA重新设计了其传统职责,以满足数字环境下的新需求,并致力于扩展数字化项目,让澳大利亚公民能够在线接触到他们的过去以及现在。但是网络信息动态出现和消失的速度极快,保存网络资源极其不易。资源存取的技术必须要跟上引发信息爆炸的技术,而且不同的网上资源也有不同的储存方式。搜集并将网上的所有信息存档是不可能的,如何有效地选择资源采集,并致力于存档资源的开放获取才是关键问题。
数字化馆藏的增长速度正在超过图书馆的管理、保存和传递能力。为适应这种现状,需要更完善的系统去收集和管理数字化与原生数字化的澳大利亚内容信息,需要建设一套新的数字化图书馆基础设施,以获取、保存并传递数字馆藏。
(来稿时间:2015年2月)
参考文献:
1.吴永熹.大英图书馆将存档海量网上信息.[2014-10-20].http://www.bjnews.com.cn/ent/2013/04/09/257230.html
2.美国国会图书馆收录1700亿条Twitter推文.[2014-10-20].http://it.sohu.com/20130105/n362464608.shtml
3-6.About Pandora.[2014-10-20].http://pandora.nla.gov.au/ about.html
7.Reports of new archived instances added to Pandora.[2014-10-20].http://pandora.nla.gov.au/newtitles/new_titles_reports.html
8.PANDORA archive size and monthly growth.[2014-10-20]. http://pandora.nla.gov.au/statistics.html
9.PANDORA: Newly Archived Titles.[2014-10-20].http://pan dora.nla.gov.au/newtitles/new_aug14.html
10.Archived websites (1996—now).[2014-10-20].http://trove. nla.gov.au/website/result?q=Parallel
11.Reports for PANDORA.[2014-10-20].http://stats.nla.gov.au/_ reports/pandora/monthly/11-2014/awstats.pandora.html
12.马宁宁,曲云鹏,谢天.欧洲主要网络资源采集项目研究与启示.图书情报工作,2013, 57(12):10-15
13,14.刘兰,吴振新,张智雄等.Web Archive的采集策略研究.现代图书情报技术,2009(1):10-15
15.PANDORA Fact Sheet.[2014-10-20].http://pandora.nla. gov.au/pandoranews.html
16.Legal Deposit.[2014-10-20].http://pandora.nla.gov.au/lega ldeposit.html
〔分类号〕
〔作者简介〕颜运梅(1979-),研究生,广州图书馆副研究馆员。
Research of Web Archive Projects PANDORA in Australia National Library
Yan Yunmei
( Guangzhou Library )
〔Abstract〕Australia National Library web archiving project called PANDORA that is one of selective web archiving project. The article introduces PANDORA project’s overall situation, discusses the advantages and defects between the two different methods: selective archive and the whole harvest, points out that PANDORA project’s sustainable development faces some difficulties in the specific implementation, including electronic publication’s copyright, funding from government as well as how to keep abreast of web technical developments and other issues.
〔Keywords〕NLA Web archive Selective acquisition Whole domain harvesting PANDORA PANDAS
