一种基于改进隐马尔可夫的多媒体业务分类算法
2015-07-18王再见董育宁张晖冯友宏
王再见董育宁张 晖冯友宏
①(南京邮电大学通信与信息工程学院 南京 210003)
②(安徽师范大学物理与电子信息学院 芜湖 241000)
一种基于改进隐马尔可夫的多媒体业务分类算法
王再见*①②董育宁①张 晖①冯友宏②
①(南京邮电大学通信与信息工程学院 南京 210003)
②(安徽师范大学物理与电子信息学院 芜湖 241000)
该文提出一种基于改进隐马尔可夫(Hidden Markov Model, HMM)的多媒体业务分类算法。改进后的算法保持典型HMM模型结构不变,通过区分包大小的位置信息,改变发射概率取值,提高了多媒体业务区分性能。理论分析表明,该文模型在计算量上低于高阶HMM;实验结果表明,改进的HMM多媒体业务分类算法的区分效果优于现有的HMM多媒体业务分类方法。
多媒体业务流识别;隐马尔可夫;发射概率;包大小
1 引言
端到端QoS(Quality of Service)保证领域的网络多媒体业务的分类,关注的是QoS特征而不是业务具体内容,希望用较少的QoS特征区分业务所归属的QoS/业务类。典型的基于端口或深度包检测的业务分类方法在效率、安全等方面存在不足。一些机器学习方法由于分类的复杂度较高,影响了分类实时性。因此,近年来有大量工作,研究如何基于可观察的QoS特征状态,准确、高效地识别被隐藏的QoS/业务类别[1]。
HMM(Hidden Markov Model)近年来取得较多的研究成果。文献[2-5]都基于典型HMM分类方法识别网络业务流,规避了传统识别/分类方法存在的法律问题等不足,但识别效果有待进一步提高,部分原因是由于HMM中对隐式序列的一阶假定有很大的局限性,发射概率是随机的。但事实上,网络多媒体业务中用于区分的特征,其所构成的观测序列不仅依赖于隐藏序列现在的状态,与过去的状态也有关,且常常存在高阶依赖关系。业务区分的重要特征包大小被很多研究人员用于业务识别和分类,但其取值并不是随机的,有一定的规律可循。如果放宽HMM的经典假设,将HMM直接拓展为高阶HMM则会引入相当大的计算量。因此,如何在不改变典型HMM结构的前提下,结合多媒体业务QoS特征,既不降低实时性要求,又提高识别准确性,是HMM模型在多媒体业务识别应用中面临的挑战。
本文的主要贡献如下:(1)通过分析典型网络多媒体业务包大小特征,得出了与前人不同的新发现,发现了一组易于提取、计算复杂度低、处理速度快、可有效区分业务所属QoS/业务类别的QoS特征;(2)根据这些新发现,通过融合特征上下文信息,调整发射概率,改进典型HMM模型,设计了一种基于改进HMM的多媒体业务分类算法。
论文具体安排如下:第2节分析典型网络多媒体业务的包大小特征,第3节介绍改进的模型,第4节描述了基于改进HMM的分类算法,第5节给出仿真结果,最后是结论。
2 典型网络多媒体业务的包大小特征分析
图1是实时捕获的土豆视频业务抓包截图,由图可见,当前包大小值与其在序列中位置有以下特点:(1)当某个包大小值首次出现时,其后包大小值以较大的概率与之相等或相近;(2)传输过程中,在一定时间内,包大小取值相同或相近;(3)当前包大小值与相邻的前一个包大小有一定的联系。这是由于协议、拥塞、丢包、排序、优先级、重传等因素的存在,使得包大小值具有阶段性的特点。
本文使用Wireshark[6]在实验室公用网络收集即时通信、标清流媒体(592×252)、高清流媒体(768×326)和游戏4种较流行的多媒体业务。依据标清流媒体业务包大小累积分布曲线,本文将包大小值划为如下4个等级。4种业务包大小值在4个等级之间的转化频率并不一致(见表1)。与标清流媒体类似,其它3种业务包大小值转换频率也有变化,即当前包大小值和前一个包大小值有内在联系。限于篇幅,此处不再一一列出。
3 改进的HMM模型
3.1 改进的模型
定义1 Q={q1,q2,…,qN}代表网络操作的有限状态集合,其中的状态数为N,Qt表示在t时刻的状态。

表1 标清流媒体业务包大小值转化频率(%)
定义2 V={v1,v2,…,vM}代表离散化情况下QoS特征取值的集合,其中M为QoS特征值总数。
将网络操作状态的集合Q看作HMM模型的隐藏状态集合,O=(O1=o1,…,OM=oM)是输出的可观测状态,M是序列中观测值数目。网络操作状态相互转移的概率矩阵为A={αij},1≤i,j≤N (N为状态数目),αij=p(qj/qi)表示从状态qi转移到状态qj的概率,αij=1,1≤i≤N 。B={}表示某个时刻因网络操作状态而得到相应QoS特征输出值的概率,bim=P(vm/qi)描述在给定状态qi输出QoS特征取值vm的概率。随机产生的π={πi,i =1,…,N}, ∑Ni=1πi=1为网络操作状态初始概率分布,那么由网络操作状态和QoS特征状态所构建的模型,形成HMM模型。
本文通过一个修改后的发射概率函数将包大小取值概率与其相邻的前一个包大小取值结合起来,调整发射概率,将混淆矩阵修改为B={bim(ot-1)}, 1≤i≤N,1≤m≤M ,其中ot-1表示上一时刻输出的观察状态,bim(ot-1)=P(vm/qi,ot-1)描述在t时刻时,给定的上一个观察特征状态为ot-1和隐藏状态为qi情况下,观察特征取值为vm的概率。依据特征前后状态间依赖关系,通过设计的发射概率函数确定当前状态的发射概率bim(ot-1),之后利用转移概率矩阵计算下一时刻的系统隐式状态的取值,转移概率矩阵和时间无关,保证了典型HMM模型的结构不变,提高识别准确度。相比其它模型,本文模型既简化了QoS/业务类区分隐式过程存在的高阶依赖关系,又由于发射概率源于历史信息,确保了准确性。此外,本文模型保留了更多训练数据的统计信息,有利于解决训练和分类上的困难。
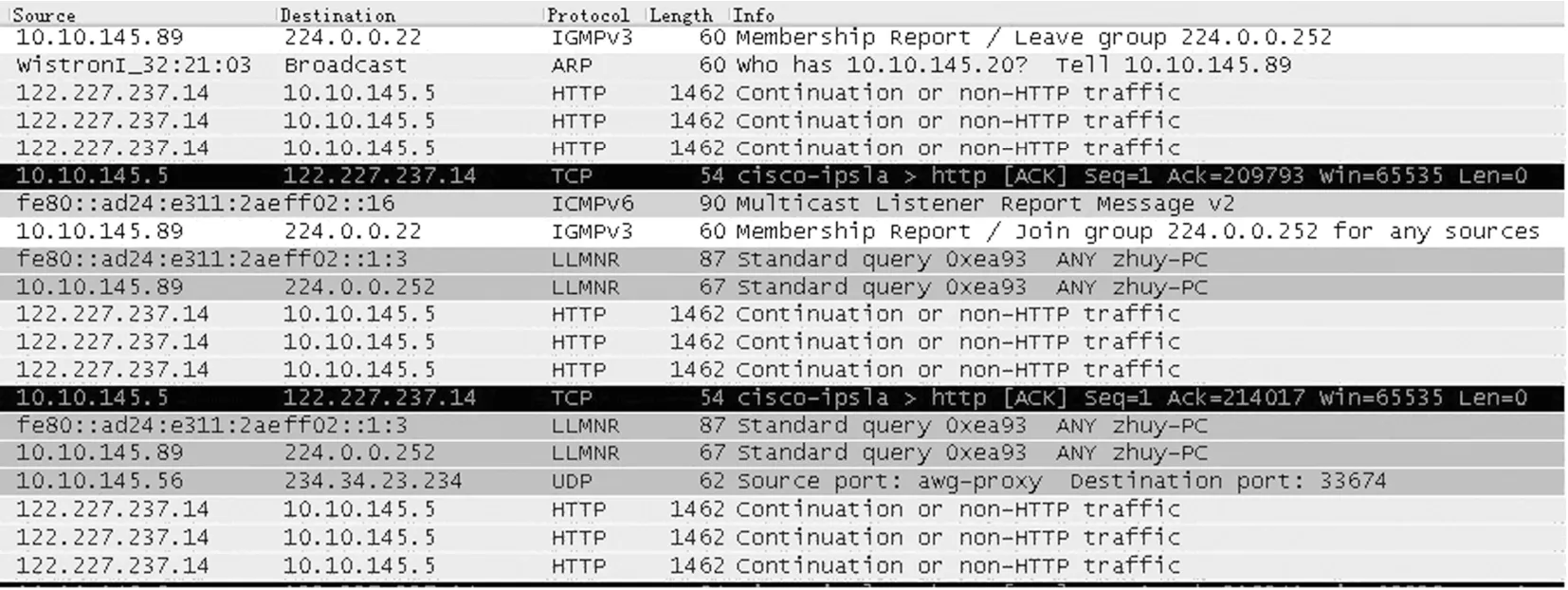
图1 实时捕获的抓包截图
3.2 改进的发射概率
由于HMM的参数主要包括转移概率和发射概率,包大小在状态中的位置信息只能通过参数体现出来,由于与包大小有关,因此只能通过包大小发射概率体现出来。为此,本文参考文献[7]根据包大小所处位置的不同,采用不同的发射概率计算方法。具体说来,就是根据包大小在状态中的位置的不同以及前一个包大小的不同,选择不同的发射概率,公式为式中σ-1表示σ的前一个包大小特征。c(x)表示事件x在训练集中出现的次数,为了计算c(x),需要在模型合并过程中保存状态的一些必要信息,包括状态中各个特征值出现的频率以及顺序关系。
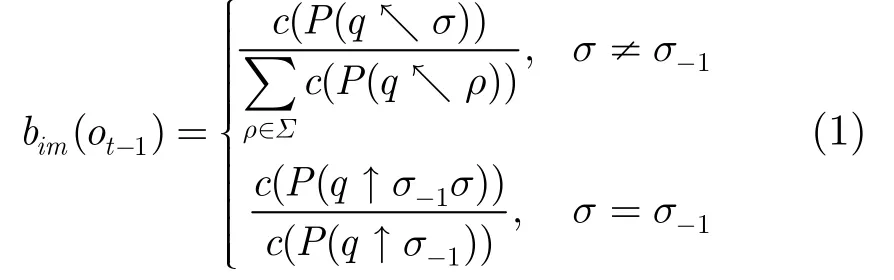
4 基于改进HMM的分类算法
基于易获取、区分效果好、复杂度低的考虑,本文选取包大小作为区分特征,针对不同类型的QoS/业务类网络多媒体业务,训练相应的基于改进HMM的分类器。基于获得的新分类器,对未知网络多媒体业务流进行分类,区分依据是相应分类器产生的概率。这样只需调整发射概率,就可通过一个HMM模型,简单地表述、解决复杂的网络多媒体业务流分类问题。上述过程的详细描述如下:
(1)数据预处理:获取包大小特征及位置信息,采用K-means聚类算法聚类。依据聚类中心,生成训练和识别的特征序列;
(2)改进的HMM:根据数据库中包含的业务类型数目设置N,观测值数目为M;随机产生初始概率向量π,A中的每个元素用业务在数据库中分布概率代表各个状态转移出现的概率,B采用改进的观测值发生概率(见式(1)),初始化该类型业务的HMM为λ;
(3)采用Baum-Welch算法[8]求解HMM参数λ;
(4)判决输出:计算各业务在每个模型下的产生概率,由最优判决输出结果。
不同于基于典型HMM模型的多媒体业务分类方法,本文通过改进发射概率,简化高阶依赖关系降低实现难度,基于历史信息提高准确性,同时实现保持典型HMM模型结构不变,不增加训练和识别阶段的计算复杂度,这是由于本文不涉及联合概率、条件概率等概率公式的求解,也不涉及特征高阶量的计算,其计算复杂度远小于高阶HMM。此外,与典型HMM模型相比,本文模型通过改进发射概率随机取值的不足,较好地考虑了多媒体业务QoS特征的内在规律,有利于提高区分效果。
5 实验仿真
本文使用Wireshark从实际网络中捕获4类流行的多媒体业务,作为样本流,通过人工识别,将流分为训练样本和测试样本(表2),用于评估算法性能,通过与文献[2-5]中相关算法比较,验证本文方法的有效性。
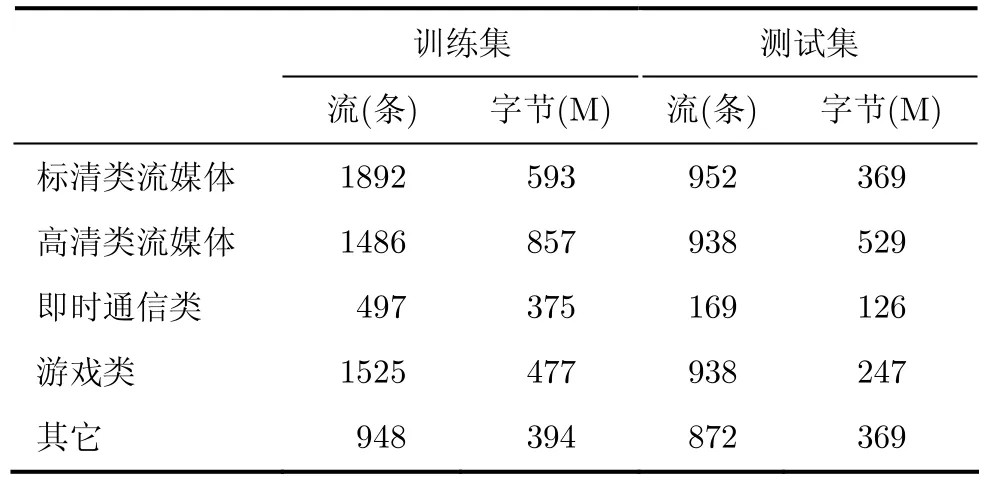
表2 样本统计信息
通过多次实验,使用记录完整的分组信息,并保存在流文件中,下面取2组不同时间段进行的典型实验数据进行分析,其中“其它”包括HTTP等业务和未知流量,作为干扰数据,其中HTTP为主,约占“其它”流量的75%以上。然后基于HMM工具箱[9],将本文方法与典型方法[2-5]进行对比,结果如表3和表4所示。
由表3可见,本文方法对4种业务的区分准确度较高,而基于典型HMM多媒体业务分类方法区分业务效果欠佳。文献[2-5]方法同时忽略了业务内在QoS需求对区分特征的影响,将发射概率设为随机值,且演化过程中保持不变,违背了业务内在结构稳定性特点,导致区分效果欠佳。由于重传、网络资源限制、业务类型特点等因素的存在,相近的特征取值之间有较紧密的联系,输出观察值概率与多个状态有关。因此,似乎应该基于特征取值的上下文信息对业务区分,这体现业务自身内在规律性的要求。
本文方法依据位置信息改变发射概率,反映了特征取值的位置信息,一定程度上体现了特征值位置间的上下文信息,较好地反映了其内在规律,取得较好的区分效果。由于包大小等多媒体业务特征受网络协议、业务类型等因素影响较大,其出现的位置具有内在的规律性。这是由于典型HMM多媒体业务分类方法中隐式序列为一阶马尔可夫链的约束条件具有内在局限性,侧重于反映区分特征的某个侧面,不能反映业务区分特征全部信息,特征考虑的全面程度不足,决定不利于提高区分效果,因此,有必要更深入研究区分特征的上下文信息。

表3 不同方法测试样本集的区分结果

表4 不同方法的计算时间
表4的数据在MATLAB R2008a环境下获得,由表4可见,本文方法耗时较少,这是由于本文方法选择的区分特征最少,而计算复杂度随着状态个数的增加而增长。文献[2]方法选择两个区分特征,通过加权将两个特征联系起来,有较高的计算复杂度。文献[3]方法仅适合区分基于TCP协议的业务,不适合多媒体业务流的区分。文献[4]方法使用的区分特征需要较高的预处理成本,计算时间依然较大。文献[5]针对无线业务识别,计算复杂度较高且联合分布获取很困难。
6 结论
本文针对典型HMM多媒体业务分类方法使用包大小特征区分业务的不足,分析了典型多媒体业务包大小分布特点,通过引入包大小位置信息,改进典型HMM发射概率的取值,提高识别效果。仿真结果验证了本文方法的有效性。由于多媒体业务识别相关研究处于不断发展的阶段,一些其它关键问题还亟待解决。此外,发射函数的引入也改变了HMM中马尔可夫过程的性质,是否有负面效果的存在,也尚待深入展开研究。
[1] Michael F, Chris R, Eduardo R, et al.. A survey of
payload-based traffic classification approaches[J]. IEEE Communications Surveys & Tutorials, 2014, 16(2):1135-1156.
[2] Mu Xue-feng and Wu Wen-jun. A parallelized network traffic classification based on hidden Markov model[C]. IEEE International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Beijing, 2011: 107-112.
[3] El Khadimi A, Lmater M A, Eddabbah M, et al.. Packet classification using the hidden Markov model[C]. IEEE International Conference on Multimedia Computing and Systems, Ouarzazate, Morocco, 2011: 1-5.
[4] 许博, 陈鸣, 魏祥麟. 基于HMM模型的P2P流识别技术[J].通信学报, 2012, 33(6): 55-63. Xu Bo, Chen Ming, and Wei Xiang-lin. Hidden Markov model based P2P flow identification technique[J]. Journal on Communications, 2012, 33(6): 55-63.
[5] Maheshwari S, Mahapatra S, Kumar C S, et al.. A joint parametric prediction model for wireless internet traffic using Hidden Markov Model[J]. Wireless Networks, 2013, 19(6): 1171-1185.
[6] Gold S. Hacking on the hoof[J]. Engineering and Technology, 2012, 7(3): 80-83.
[7] 张铭, 银平, 邓志鸿, 等. SVM+BiHMM:基于统计方法的元数据抽取混合模型[J]. 软件学报, 2008, 19(2): 358-368. Zhang Ming, Yin Ping, Deng Zhi-hong, et al.. SVM + BiHMM: a hybrid statistic model for metadata extraction[J]. Journal of Software, 2008, 19(2): 358-368.
[8] Baggenstoss P M. A modified Baum-Welch algorithm for hidden Markov models with multiple observation spaces[J]. IEEE Transactions on Speech and Audio Processing, 2001, 9(4): 411-416.
[9] Kevin Murphy. HMM Toolbox. http://www.cs.ubc.ca/~murphyk/Software/HMM/hmm_download.html,2014.
王再见: 男,1980年生,博士生,副教授,研究方向为端到端QoS保证技术、业务流识别.
董育宁: 男,1955年生,博士生导师,教授,研究方向为多媒体通信与信息处理、绿色通信.
张 晖: 男,1982年生,博士,副教授,研究方向为无线网络、云计算.
A Multimedia Traffic Classification Method Based on Improved Hidden Markov Model
Wang Zai-jian①②Dong Yu-ning①Zhang Hui①Feng You-hong②
①(College of Communications and Information Engineering, Nanjing University of Posts and Telecommunications, Nanjing 210003, China)
②(The College of Physics and Electronic Information, Anhui Normal University, Wuhu 241000, China)
This paper proposes an improved Hidden Markov Model (HMM) based multimedia traffic classification method. This method preserves the classical HMM model structure, and improves the performance of multimedia traffic classification by changing the emitting probability value with the position information of packet size. Theoretical analysis indicates that the new model can reduce the computational complexity of the classical HMM model. Simulation results show that the proposed method can improve the classification performance compared with the existing HMM based classification method.
Multimedia traffic classification; Hidden Markov Model (HMM); Emitting probability; Packet size
TP393
A
1009-5896(2015)02-0499-05
10.11999/JEIT140340
2014-03-13收到,2014-09-15改回
国家自然科学基金(61401004, 61271233, 60972038, 61101105),教育部高等学校博士学科点专项科研基金(20103223110001, 20113223120001),工业与信息化部通信软科学课题(2011-R-70), 2011年度江苏省研究生培养创新工程(CXZZ11_0396)和安徽师范大学科研培育基金(2013xmpy10)资助课题
*通信作者:王再见 wangzaijian@ustc.edu
