一种融合用户偏好与信任度的增强协同过滤推荐方法
2015-07-18
(西华大学计算机与软件工程学院,四川 成都 610039)
·计算机软件理论、技术与应用·
一种融合用户偏好与信任度的增强协同过滤推荐方法
范永全, 杜亚军, 成丽静, 朱爱云
(西华大学计算机与软件工程学院,四川 成都 610039)
协同过滤是一种最流行的推荐技术,但仍然受到数据稀疏和冷启动问题的困扰。针对Shambour提出的信任—语义融合(TSF)的混合推荐方法中计算量较大的问题,提出一种融合用户偏好与信任度的增强协同过滤推荐方法。该方法在计算评分预测时,对基于用户的信任增强协同过滤算法进行改进,先将用户相似度和信任度分别进行近邻选择和加权评分,再通过一个加权因子对2部分进行融合,从而得到总体的预测评分。在Movielens数据集下进行仿真验证,其结果表明,与基准算法相比,本文方法具有更好的MAE性能。
信任; 协同过滤; 推荐系统; 相似度; MAE
随着互联网的不断发展和普及,人们面临着日益严重的信息过载问题。协同过滤推荐因为简单高效,已经成为目前最流行的个性化推荐方法;然而协同过滤方法容易受到数据稀疏和冷启动问题的困扰。随着在线社会网络的普及,利用社会网络中用户之间的信任关系,来缓解传统协同推荐存在问题的信任感知推荐系统(TARS),成为推荐领域新的研究热点[1-5]。
Massa等[6]提出使用信任度取代相似度的TARS系统,根据信任网络传播来估计一个信任度的权值。该方法增加了覆盖范围(可预测的评分总数),并未降低精确度(预测误差),但需要用户的显式信任声明。Yuan等[7]根据隐含信任网络的小世界特性,提出一种基于用户相似度的隐含信任感知推荐系统(iTARS),把用户从显式的信任声明的烦恼中解脱出来,但是该方法需要根据用户之间的相似度构建隐含的信任网络,并估算信任网络的平均路径长度。Ma等[8]把用户之间的直接信任关系融入矩阵分解过程,提出了融合社会信任的协同推荐算法RSTE(recommend with social trust ensemble),但是没有考虑信任关系的传递。Jamali 等[9]提出一种随机游走 (TrustWalker)策略,融合了基于信任和基于项目的协同过滤推荐;但由于受到评分数据稀疏性的影响,推荐精度不高。李慧等[10]提出一种融合信任度与矩阵分解技术实现社会网络推荐的方法,用来降低虚假评分或恶意评分给推荐系统带来的负面影响,有效地缓解数据稀疏性与冷启动问题。徐守坤等[2]提出一种以本体、语义Web为基础的方法,通过构建用户之间的信任网络以及计算用户间的信任权重值,从而增加系统中相似用户发现的数量,改善推荐结果的准确性和可靠性,但是没有在真实的数据集进行充分的实验验证。为有效缓解数据稀疏问题,杜永萍等[1]将信任关系作为影响推荐的一个重要因素,利用信任关系的条件可传递性,设计并构造一个混和信任网络,为目标用户选取基于兴趣和信任双重因素的二维相似近邻。其结果表明该方法可以为目标用户获取新的潜在信任关系。Qusai等[11]在CF框架下融合了用户信任和项目语义信息,提出一种称为信任语义融合(trust semantic fused,TSF)的混合协同过滤方法,改善了推荐的准确度和覆盖率;但是该方法需要分别考虑基于用户信任的增强协同过滤和基于项目语义的增强协同过滤,并将二者的结果进行融合,计算量较大。本文对文献[11]中的用户信任算法进行改进,提出了一种融合用户偏好(相似度)和信任度的增强协同过滤推荐方法,该方法利用用户的评分信息来计算用户之间的隐含信任,并通过信任传播来解决数据稀疏问题,算法的性能通过在MovieLens 数据集下的仿真得到了验证。
1 信任感知推荐模型
信任感知推荐系统(TARS)可以处理用户之间的信任关系。基于信任的推荐系统利用带有信任评分的增强社交网络,基于用户所信任的人来为他们产生推荐。信任网络是一个有向图,其中节点代表用户,边代表一个用户对另一个的信任关系。通过利用信任信息,基于信任的推荐系统让用户知道该推荐的来源要么是从当前用户直接信赖的人,要么是间接通过信任传播方法由其他信任的用户形成。信任传播经常被使用来推断信任,并在没有直接链接的用户之间建立新的信任关系[6]。经过验证,基于信任的推荐系统可以提供比传统的协同过滤更好的效果,特别是在缓解数据稀疏和用户冷启动方面[6-7]。目前文献中主要采用2种信任过滤方法:显式信任和隐式信任。显式信任过滤方法是从用户之间的预先存在的社会关系获得信任值[6];然而,显式信任过滤需要用户进行显式声明以获得对某用户的明确信任,用户需要付出额外劳动,并且显式信任过滤易受到用户冷启动问题的影响,因为在有效过滤之前,新用户必须先建立自己的信任网络。这些局限性限制了显式信任过滤方法在推荐系统中的适用性,使得隐含信任过滤方法[7]更可行。隐含信任基于项目评分[7, 11]推导用户之间的信任值。用户b对给定用户a过去的评分预测得越准确,则用户b的可信度就越高。本文采用隐含信任,假定相似度较高的用户之间也具有较高的信任度,并根据用户相似度来计算用户之间的隐含信任。
2 融合用户偏好与信任度的协同过滤推荐方法
为了计算用户a对项目x的预测评分,文献[11]提出了一种基于用户信任的增强协同过滤算法,其主要步骤为:1)计算增强的用户相似度;2)计算用户之间的隐含信任并进行信任传播;3)根据相似度和信任度进行近邻选择;4)计算最终的预测评分。
2.1计算增强的用户相似度
计算用户之间相似度的方法[11-12]有很多,常用的有约束皮尔逊相关(CPC)、均方偏差(MSD)和Jaccard相似度。这里使用它们的组合来计算用户之间的相似度和信任度。
约束皮尔逊相关(CPC)
CPCa,b=
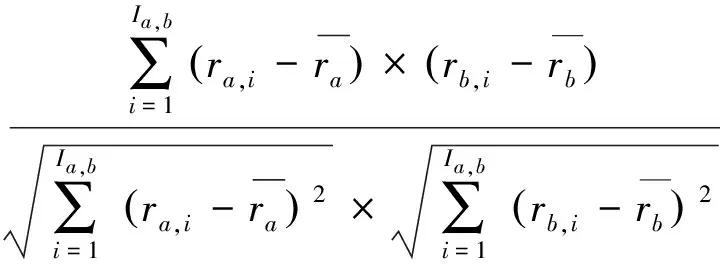
(1)
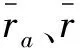
均方偏差相关(MSD)
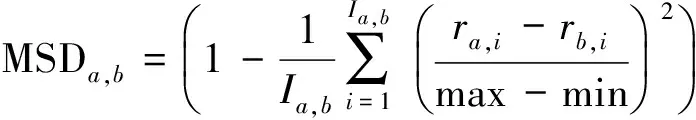
(2)
式中,max、min分别代表用户评分的最大值和最小值。式(1),(2)的相似度机制是基于用户共同评分的项目来度量相似度。这种机制有一个共同缺点,就是在数据稀疏的情况下,2个用户可能仅仅有一个共同评分项目且评分完全相同,这种情况下采用上面公式计算出来的二者相似度为1,这将造成较大的误差。与上面2种相似度不同,Jaccard相似度是基于用户共同评分的项目个数来度量的,其公式为
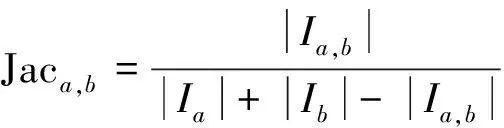
(3)
式中:Ia,b代表由用户a、b共同评分的项目集合;|Ia,b|代表由活动用户a和潜在邻居用户b共同评分的项目数。
参与了较多项目评分的用户优于仅分享了少量项目评分的用户,因此文献[11]结合了皮尔逊相关系数(CPC)和Jaccard相似度,即对任意a,b∈U,采用CPCa,b与Jaca,b的乘积来计算用户a,b之间增强的相似度eSima,b,且eSima,b∈ [-1,1]。
eSima,b=CPCa,b× Jaca,b。
(4)
2.2计算隐含信任及信任传播
该步骤分为2个关联的环节:信任推导和信任传播。信任推导以评分矩阵为输入,计算每一对用户的直接隐含信任值,根据直接信任值,构建用户之间的信任网络;然后,通过信任传播来计算信任网络中无直接连接的用户之间的间接信任值。
2.2.1 直接信任的计算
通过对活动用户以往评分的预测准确度来度量一个给定用户的信任度,例如,如果用户b过去对用户a的以往评分表达了较准确的推荐,那么用户b就应该从用户a得到一个较高的信任。对信任推导,这里使用增强用户相似度来测量它对目标用户的信任度,即对于任意用户a、b,基于二者共同评分项目的增强用户CF相似度来测量用户a对用户b的信任度。
文献[11]使用MSD与Jaccard相似度的乘积来计算用户之间的直接信任度DTrusta,b,即
DTrusta,b=MSDa,b× Jaca,b。
(5)
且DTrusta,b∈[0,1]。式(5)计算的增强相似度表示用户之间的直接信任。如果用户之间共同评分的项目非空,二者之间的直接信任非零;否则如果用户之间没有共同评分的项目,那么他们之间的直接信任为0,这种情况下二者之间的信任度就可以通过用户之间信任网络进行传播得到间接信任。
2.2.2 通过信任传播计算间接信任
在社会信任网络中,当2个用户之间没有直接的信任关系时,就需要信任传播,因此,可以从信任网络推断出间接信任,并在彼此没有信任连接的用户之间建立新的关系。例如,假定用户a(源用户)信任用户b(中间用户),并且用户b信任用户c(目标用户),通过使用信任传播矩阵,可以推导出用户a在某种程度上信任用户c。在中间用户多于一个的情况下,就需要使用信任聚合方法来合并不同的信任。文献[11]采用加权平均聚合的方法来传递信任信息,它确保推断的信任值中最受信任的用户有最大的权重。对任意用户a、b、c,传播的隐含信任值PTrusta,c表示用户a可以在多大程度上信任用户c,其计算公式为
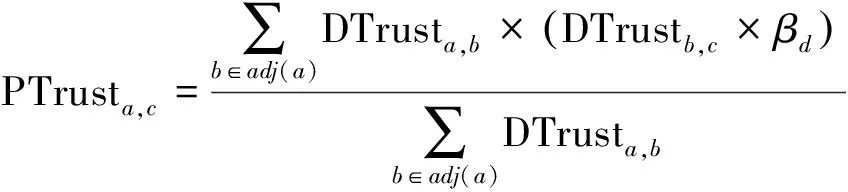
DTrusta,b≥λ。
(6)
式中:βd=(MPD-d+1)/MPD,d∈[2,MPD], MPD为信任传播的最大距离,设MPD=3,则当d=2时,β2=(3-2+1)/ 3 = 0.667;d=3时,β3=(3-3+1)/ 3 = 0.334;DTrusta,b∈[λ,1]为用户a,b之间的直接信任值。用户a的邻居b信任用户c,从而可得用户a,c之间的间接信任,即PTrusta,c∈[0,1]。参数λ是一个可调的信任度阈值,用于在信任过滤中确保被认为不值得信任的用户不参与信任传播;因此,信任度低于某个门限的用户就不能影响信任的传播过程。
综合式(5)、(6),就得到2个用户之间的信任值。因为该信任是通过评分矩阵计算得到的,不同于TARS中用户显式声明的信任,所以称为隐含信任,表示为iTrust,即
(7)
2.3选择邻居
对于邻居的选择过程,根据上一步计算得到的用户相似度和间接信任度,采用KNN方法选择活动用户最信任或者与用户偏好最相似的前N个邻居。
2.4计算加权的预测评分
在推荐过程中最后的重要步骤是计算评分预测。在加权预测模块,文献[11]采取融合信任度与相似度的方式进行加权,公式为
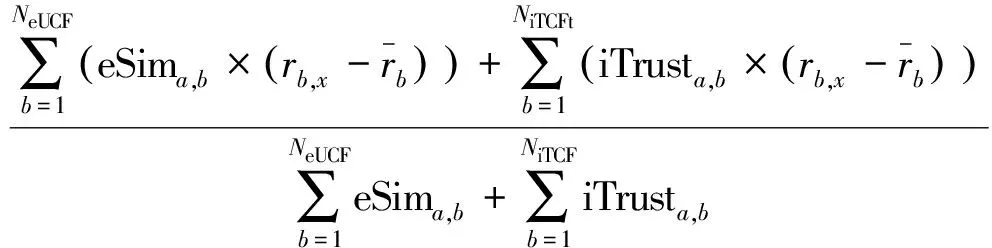
(8)
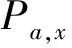
在式(8)中,如果只保留相似度部分,就得到文献[11]的增强用户协同过滤方法,其公式描述为
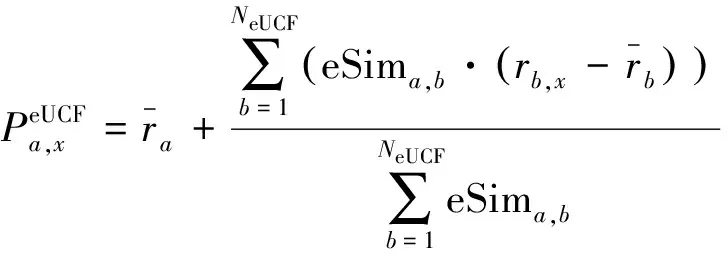
(9)
式(9)表示根据用户偏好得到的评分预测,其中NeUCF代表根据增强的用户相似度选择的近邻数,这里称之为增强的用户协同过滤方法(enhanced user-based CF),标记为eUCF。
如果只保留式(8)中的信任度加权部分,就得到如下的评分预测公式:
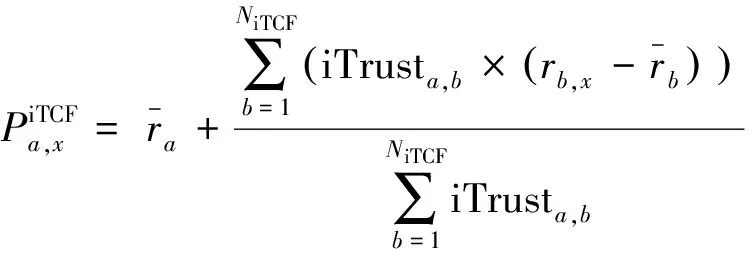
(10)
这里的NiTCF代表根据信任度选择的邻居数。其中iTCF表示基于隐含信任的协同过滤方法(implicit Trust based CF),标记为iTCF。
本文对式(8)的评分偏差的加权平均部分进行改造,如下式所示:

(11)
称为融合用户偏好与信任度的协同过滤方法(Trust-Preference Fused CF),简称TPF。α∈[0,1]是一个加权因子,用于控制用户偏好和信任度在评分预测中的权重。其中α部分采用用户的相似度加权,代表了用户的偏好,而(1-α)部分采用隐含的信任度加权。当α接近于1时,基于用户偏好的评分预测占主导地位,当α=1时,算法退化为eUCF;当α接近于0时,基于用户信任的评分预测占主导地位,当α=0时,算法退化为iTCF。因此,α的取值可根据评分数据的密度来选择。当数据密度较高时,用户的近邻数较多,基于用户的相似度较准确,此时可以取较大的α值;反之,当数据稀疏时,用户的近邻数少,此时可取较小的α值,通过信任传播来找到更多的近邻,从而缓解数据稀疏带来的性能下降。
图1为本文提出的基于隐含信任的协同过滤推荐模型,矩形框代表传递的数据,圆角矩形代表步骤。可以看出,本文方法加权融合了基于用户偏好的近邻评分和基于信任的近邻评分,从而得到最终的用户预测评分。
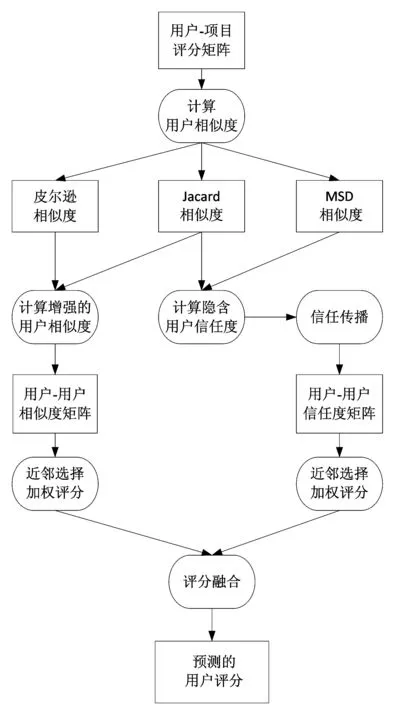
图1 融合用户偏好与信任度的协同过滤推荐模型
3 实验结果及评价
为验证本文方法的有效性,选择广泛使用的MovieLens数据集进行交叉验证测试。此数据集包含943 用户对1 682部电影的10万条评分,评分范围在 1 到 5之间。把数据集划分为训练集和测试集,80%的数据组成训练集, 20%组成测试集,并进行5次交叉验证。
3.1评价机制
本文使用广受欢迎的度量标准平均绝对误差(MAE)来验证推荐方法的性能。在推荐研究中,MAE 是使用最广泛的用来测量推荐精度的度量。MAE通过计算的系统预测评分与用户分配的实际评分之间的平均绝对偏差来度量准确度。越小的 MAE 值表示推荐的精度较高。给定测试集中所有可用的n个项目的实际/预测评分数据对,MAE可表示为
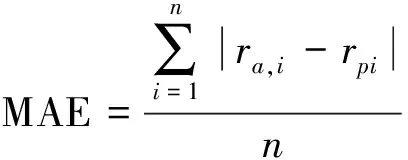
(12)
为验证本文方法的性能,选取4种基准算法与本文算法进行对比,算法名称及所用的公式如表1所示。对于公式(6)的信任传播, 选取参数λ=0.15,最大信任传播距离 MPD = 3。
表1列出了本文算法及相关基准算法的计算公式,其中UCF(user-based CF)为经典的基于用户的协同过滤方法,采用皮尔逊相关来计算相似度,TPF(trust-preference fused)为本文提出的用户信任与相似度(偏好)融合的方法。

表1 本文相关算法使用的公式
3.2实验结果分析
图2为MAE随加权因子α的变化曲线。4个基准算法的MAE值与α取值无关,因此呈现为一条直线。其中近邻数取10,评分数据密度为2%。4种基准算法的MAE由高到低依次是UCF、iTCF、eUCF、TeCF。本文方法的MAE性能随式(11)中加权系数α取值的变化而变化,其MAE随α取值先减小后增大,在0.8时达到最小。这是因为总体上eUCF算法的MAE性能优于iTCF方法,但是没有考虑信任的传播,在评分稀疏时性能欠佳,而iTCF方法考虑了信任的传播,在评分稀疏时优于基本的UCF方法,但不如eUCF方法。TeCF是上述2种方法(eUCF和iTCF)的融合,但采用固定的融合模式,只有在数据稀疏的情形下才有较好的效果。本文方法引入一个可调的加权参数α,可以根据数据的稀疏度来调整基于用户偏好的预测和基于信任度预测这2部分的比例,具有更广泛的适应性。对于MovieLens数据集,本文方法的参数α取0.8,经验证具有较好的效果。
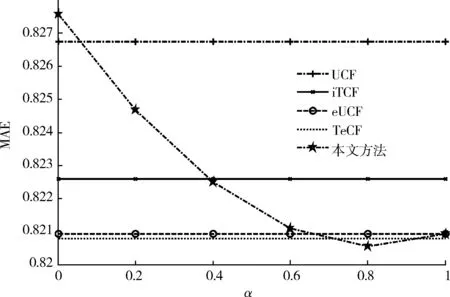
图2 MAE随加权因子α的变化曲线
图3为MAE性能随近邻数的变化曲线,评分数据密度为6.3%,即Movielens数据的原始评分密度。可以看出,所有算法的MAE都随着近邻数的增加而降低。其中经典的UCF方法误差较大,eUCF方法结合了皮尔逊相似度和Jaccard相似度,因而误差大大降低。iTCF方法引入了信任传播,MAE性能比经典的UCF有所降低,但是在数据密度较高时优势不明显。 TeCF方法介于eUCF方法和iTCF方法之间。本文方法具有最低的MAE值,特别是在近邻数较少时,优于TeCF方法。
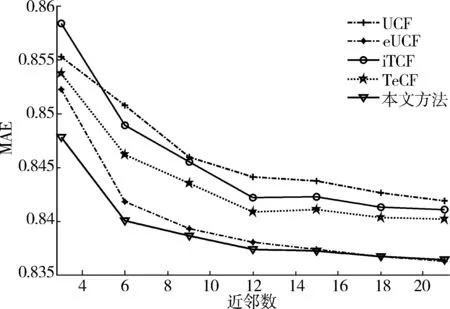
图3 MAE随近邻数的变化曲线
4 结论
本文对Shambour等提出的基于信任增强的协同过滤推荐方法进行改进,在计算评分预测时,先将用户相似度和信任度分别进行近邻选择和加权评分,再通过一个加权因子对2部分进行融合,其仿真结果表明本文方法具有较好的推荐精度,特别是在数据稀疏的情形下。下一步工作将考虑在显式信任声明的情况下,融合用户偏好和信任度的方法。
[1]杜永萍, 黄亮,何明. 融合信任计算的协同过滤推荐方法[J]. 模式识别与人工智能, 2014,27(5):417-425.
[2]徐守坤, 孙德超, 李宁, 等. 一种结合语义Web和用户信任网络的协同过滤推荐模型[J]. 计算机应用研究, 2014, 31(6):1714-1718.
[3]郭磊, 马军,陈竹敏. 一种信任关系强度敏感的社会化推荐算法[J]. 计算机研究与发展, 2013, 50(9):1805-1813.
[4]Eirinaki M, Louta M D,Varlamis I. A Trust-aware System for Personalized User Recommendations in Social Networks[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems ,2014, 44(4):409-421.
[5]Chen C, Zeng J, Zheng X, et al. Recommender System Based on Social Trust Relationships [C]// IEEE 10th International Conference on e-Business Engineering (ICEBE).Coventry:IEEE, 2013:32-37.
[6]Massa P,Avesani P. Trust-aware Recommender Systems [C]//Proceedings of the 2007 ACM conference on Recommender Systems. Minneapolis:ACM,2007:17-24.
[7]Yuan W, Shu L, Chao H-C, et al. ITARS:Trust-aware Recommender System using Implicit Trust Networks[J]. IET Communications, 2010, 14 (4):1709-1721.
[8]Ma H, King I,Lyu M R. Learning to Recommend with Social Trust Ensemble[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval.Boston: ACM,2009:203-210.
[9]Jamali M,Ester M. TrustWalker:A Random Walk Model for Combining Trust-based and Item-based Recommendation[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Paris:ACM,2009:397-406.
[10]李慧, 胡云,施珺. 社会网络环境下的协同推荐方法[J]. 计算机应用, 2013, 33(11):3067-3070.
[11]Qusai Shambour,Jie Lu. A Trust-semantic Fusion-based Recommendation Approach for E-business Applications[J]. Decision Support Systems, 2012, 54(1):768-780.
[12]Haifeng Liu,Zheng Hu,Ahmad Mian, et al. A New User Similarity Model to Improve the Accuracy of Collaborative Filtering[J]. Knowledge-Based Systems, 2014, 56:156-166.
(编校:饶莉)
AnImprovedCollaborativeFilteringRecommendationMethodwithUserTrust-PreferenceFusion
FAN Yong-quan, DU Ya-jun, CHENG Li-jing, ZHU Ai-yun
(SchoolofComputerandSoftwareEngineering,XihuaUniversity,Chengdu610039China)
Collaborative filtering (CF) is the most popular recommendation technique but still suffers from data sparisity and cold-start problems. Shambour proposed a trust-semantic fused (TSF) hybrid recommender approach, which incorporated additional information from the users’ social trust network and the items’ semantic domain knowledge to alleviate these problems, but it involves large computation. In this paper we improved the user-based trust enhanced CF algorithm therein. By introducing a weighting combination parameter we merge the user trust weighted rating and the user preference weighted rating together to obtain the overall rating prediction. Simulation results under the Movielens datasets show the proposed method is superior to the baseline algorithms in terms of mean absolute error (MAE).
trust; collaborative filtering; recommendation system; similarity; MAE
2014-12-08
教育部春晖计划(Z2011088);四川省教育厅重点项目(11ZB002);四川省高校重点实验室基金(SZJJ2012-027, SZJJ2014-033);西华大学重点科研基金项目(Z1412620)。
范永全(1976—),男,副教授,博士,主要研究方向为信息检索、推荐系统。E-mail:Larkfyq@sina.com
TP391.3
:A
:1673-159X(2015)04-0008-05
10.3969/j.issn.1673-159X.2015.04.002
