基于Hadoop云计算平台仿百度智能输入提示算法的研究与实现
2015-06-27华志洁
华志洁
(1.同济大学 上海 200092;2. 天津普泰国信科技有限公司 天津300384)
应用技术
基于Hadoop云计算平台仿百度智能输入提示算法的研究与实现
华志洁1,2
(1.同济大学 上海 200092;2. 天津普泰国信科技有限公司 天津300384)
云计算是指基于互联网、通过虚拟化方式共享IT资源的新型计算模式。Hadoop以Hadoop分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce分布式计算框架为核心,为用户提供了底层细节透明的云分布式基础设施。系统研究的主要内容在基于Hadoop的云计算平台上实现通过检索不同文件系统下的输入接口,输入内容的分布式统计结果,智能提示和匹配后续的内容,完成智能输入提示功能的算法研究与实现工作。
云计算 Hadoop 智能输入 智能匹配 HDFS MapReduce
0 引 言
近年来,全球云计算市场迅速发展,世界信息产业强国和地区对云计算给予了高度关注,已把云计算作为未来战略产业的重点,纷纷研究制定并出台云计算发展战略规划,加快部署国家级云计算基础设施,并加快推动云计算的应用,抢占云计算产业制高点。新兴云计算技术和服务企业也凭借先发优势,发展势头强劲。
本文在对Hadoop的核心组件Hadoop分布式文件系统HDFS和分布式计算模型MapReduce进行深入分析和研究的基础上,搭建基于Hadoop的云计算平台,在该平台上实现通过检索不同文件系统下在搜索引擎的输入接口,输入内容的统计次数,智能提示和匹配后续的内容。在云平台下完成仿百度搜索引擎智能输入提示功能的算法研究与实现工作。
1 云计算技术研究
云计算即一种基于因特网的新型超级计算模式,用户只需要通过简单的联网设备接入云数据中心,就能切身体验到每秒十万亿次的计算能力。广义云计算是指服务商提供给用户交付和使用服务的一种模式,用户仅需要一台普通PC就可以通过网络按需获得所需服务。狭义云计算就是指用户能够像购买水电一样,根据需求随时获取所需资源和IT基础设施。
Hadoop采用分布式存储结构,读写速度有了极大提高。其基于Java语言开发,HDFS分布式文件系统具有高容错的特性,并且具有超强的数据管理能力。
HDFS是Hadoop分布式文件系统,是分布式数据计算和文件存储的基础。HDFS 的名称节点即NameNode,在Hadoop中充当一个全局管理者的角色,负责调度数据节点去执行系统最底层的任务,以及负责监控整个系统的运行状态。
主节点(NameNode)负责管理该文件系统中的元数据,数据节点(DataNode)则负责存储该文件系统中的实际数据。客户端通过与主节点和数据节点的交互来访问文件系统。图1为HDFS体系结构图。

图1 HDFS体系结构图Fig.1 HDFS architecture
MapReduce是一种编程模型,可用于大规模TB级别以上数据集的并行运算。在Hadoop中,每一个MapReduce的任务都被初始化为一个job,每个job又可分为Map和Reduce阶段。他们可用两个功能函数来表示,即Map函数和Reduce函数。Map函数是负责接收一个<key,value>形式的输入,然后产生同形式的中间输出结果,然后Hadoop将中间结果集合到一起传递给Reduce函数,Reduce函数再去接收<key,(list of values)>形式的输入,然后进行并行处理。图2 描述了MapReduce处理大数据集的具体流程。
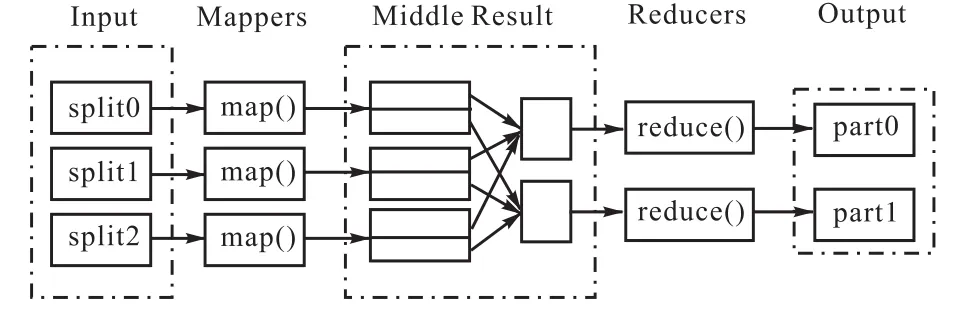
图2 MapReduce处理过程Fig.2 MapReduce processing
Hadoop的第三大核心技术就是HBase,它是一个面向列的、分布式的数据库,同时也是一种开源数据库。相对于普通的数据库,HBase非常适合于非结构化的数据存储。其次,HBase还是一种基于列的模式存储。这两个特点使得HBase成为一种在性能、可靠性、伸缩性等方面都大放异彩的分布式存储系统。
2 Hadoop开发环境配置
云计算平台机群中包括了3个节点:1个Master、2个Slave,节点之间采用局域网连接并且相互之间可连通。节点IP地址分布如表1所示。
这3个节点上均是CentOS6.4系统,Master虚拟机主要扮演NameNode和JobTracker的角色,另外的两台Salve虚拟机扮演DataNode和TaskTracker的角色。

表1 节点IP地址Tab.1 Node IP addresses
2.1 Hadoop集群成功截图
① 在浏览器里地址栏输入“http://hadoop001∶50030/”,显示结果如图3所示。

图3 50030界面Fig.3 50030 interface
② 在浏览器里地址栏输入“http://hadoop001∶50070/”,显示结果如图4所示。
这样就完成了Hadoop集群平台的搭建。
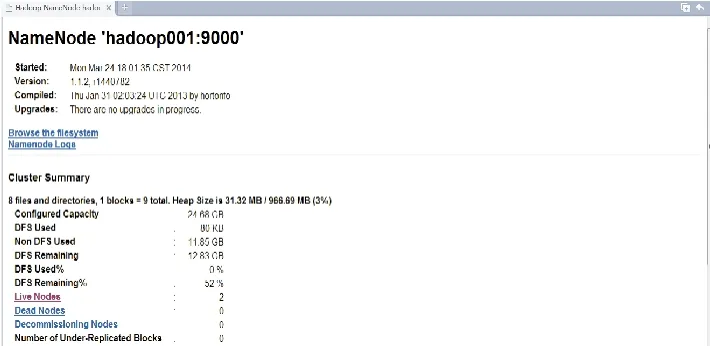
图4 50070界面Fig.4 50070 interface
2.2 基于Eclipse的Hadoop应用开发环境配置
操作系统为centos6.4(1个NameNode 2个DataNode);Hadoop版本为hadoop-1.1.2;Eclipse版本为Eclipse IDE for Java EE Developers。
第一步:先启动hadoop守护进程,执行start-all.sh指令。
第二步:在eclipse上安装hadoop插件。
①把Hadoop插件放到Eclipse安装目录的plugins中,重启Eclipse生效。
②配置Map/Reduce Locations。新建一个Hadoop Location,配置对应的Location name和Map/Reduce Master、DFS Master,如图5所示。

图5 配置Map/Reduce LocationsFig.5 Deployment of Map/Reduce Locations
③ 配置完后退出。点击DFS Locations->Hadoop,如图6所示。
图6 DFS LocationsFig.6 DFS Locations
第三步:新建项目。新建一个Map/Reduce Project,此处项目名取为WordCount。复制 Hadoop源文件中WordCount. java程序到刚刚新建的项目中。
第四步:上传测试数据,上传成功后如图7所示。
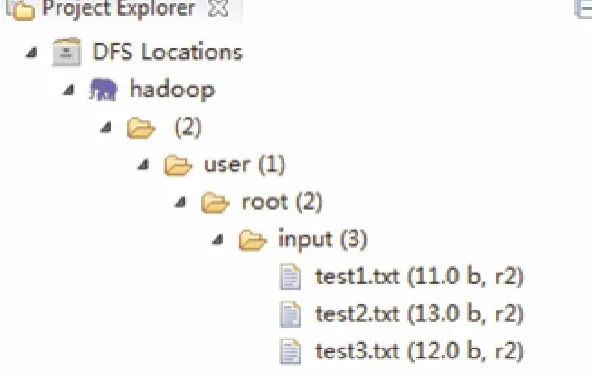
图7 HDFS文件系统Fig.7 HDFS file system
第五步:点击Run,运行程序,显示结果如图8所示。

图8 运行结果Fig.8 Run results
2.3 PieTTY
PieTTY是一种基于Putty开发的工具,它的用户界面相对于Putty得到了有效的改进,并且还提供了更多的语种支持功能。Putty作为远程连接linux的工具,支持SSH和telnet。如图9所示。
图9 PieTTY界面Fig.9 PieTTY interface
2.4 WinSCP
WinSCP是一种基于Windows环境的SFTP客户端,它同时也支持SCP协议。其主要功能特点就是可以在本地计算机与远程计算机间进行安全的复制文件。
安装非常简单,按照提示一步一步操作即可,中间没有需要选择、判断的地方。如图10所示。
3 仿百度搜索引擎自推荐功能设计与实现
百度搜索提示功能实际上需要处理每天数以万计的信息,将用户搜索最多的前10个关键词做以提示推荐。本研究模拟了类似百度搜索提示功能,使用JqueryUI+Ajax+Redis搭建前后台框架,期间用到了搜索引擎自动推荐算法,并且是使用MapReduce实现数据统计算法,最终定制MapReduce输出,将数据直接写入Redis内存数据库,最终完成初步的仿百度搜索提示功能。
① 搭建了一个struts2的开发环境。
② 使用JqueryUI+Ajax+Redis搭建前后台框架,采用ajax技术作出用户在Sug.jsp页面输入搜索后的响应动作。具体代码如图11所示。

图11 Sug.jsp部分代码Fig.11 Sug.jsp code(partial)
在后台Sug.java部分,通过连接虚拟机主节点IP地址192.168.80.101,将该程序与Redis数据库进行连接。Sug.java部分代码如图12所示。

图12 Sug.java部分代码Fig.12 Sug.java code(partial)
③ 在虚拟机主节点hadoop001里安装配置Redis数据库和Tomcat,并开启运行状态。
④ 使用MapReduce实现数据统计算法,统计出用户搜索的关键词的次数。Map函数负责将用户搜索产生的日志文件里的记录找到相应的重要关键词,然后通过文本处理统计频率的程序,记录关键词出现的次数并把他们交给Reduce函数进行合并。图13为Map函数的代码。

图13 Map函数代码Fig.13 Map function code
⑤ 定制MapReduce输出,将数据直接写入Redis内存数据库。这样,当把程序通过Eclipse运行起来时,MapReduce将自动记录下数据日志文件,并做相应的处理,写入到数据库中。
⑥测试运行。在浏览器中输入字母“h”就会出现搜索提示,如图14所示。
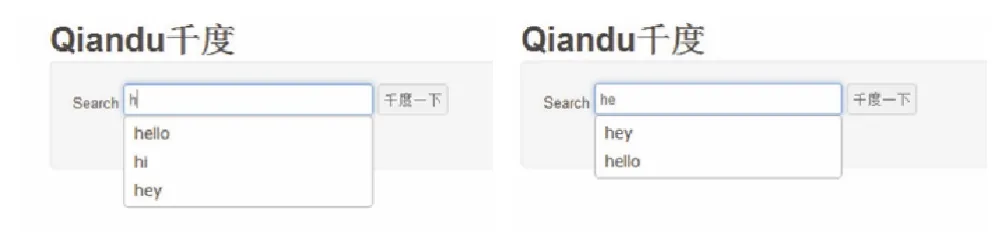
图14 搜索提示运行结果Fig.14 Run results of search tips
4 结 语
本研究对Hadoop的核心组件HDFS和MapReduce进行深入分析,搭建基于Hadoop的云计算平台,通过实验有效验证了该平台仿百度搜索引擎智能提示算法的研究与实现任务。
[1] 张健. 云计算概念和影响力解析[J]. 电信网技术,2009(1):15-18.
[2] 潘富斌. 基于Hadoop的安全云存储系统研究与实现[D]. 成都:电子科技大学,2013.
[3] 翀栾亚建,黄民,龚高晟,等. Hadoop平台的性能优化研究[J]. 计算机工程,2010(14):262-263.
[4] Mackey G,Sehrish S,Wang J. Improving metadata management for small files in HDFS[C]. IEEE International Conference on Cluster Computing and Workshops,2009.
[5] Borthakur D,Gray J,Sarma J S. Apache Hadoop goes realtime at Facebook [C]. Proceedings of the 2011 international conference on Management of data,2011.
A Hadoop Cloud Platform Based and Baidu Modeled Intelligent Input Algorithm:Research and Realization
HUA Zhijie1,2
(1.Tongji University,Shanghai 200092,China;2.Tianjin Ptgosn Science and Technology Ltd.,Tianjin 300384,China)
Cloud computing refers to the new Internet-based computing model which shares IT resources by way of virtualization.HDFS(Hadoop Distributed File System)takes MapReduce distributed computing framework as the core to provide users with low-level details of transparent distributed cloud infrastructure.This study focuses on the design and implementation of the algorithms of providing smart tips and matched contents for users’ inputting through searching input interfaces,distributed statistics of users’ input contents,smart tips and matched follow-up contents.
cloud computing;Hadoop;intelligent input;intelligent match;HDFS;MapReduce
TP311.1
:A
:1006-8945(2015)12-0020-04
2015-11-05
