基于多重压缩感知和距离计算的视频关键帧提取
2015-06-23祁云嵩
潘 磊,束 鑫,张 静,祁云嵩
(1.江苏科技大学计算机科学与工程学院,江苏镇江 212003) (2.江苏大学现代农业装备与技术教育部重点实验室,江苏镇江 212013)
基于多重压缩感知和距离计算的视频关键帧提取
潘 磊1,2,束 鑫1,张 静1,祁云嵩1
(1.江苏科技大学计算机科学与工程学院,江苏镇江 212003) (2.江苏大学现代农业装备与技术教育部重点实验室,江苏镇江 212013)
关键帧提取是基于内容的视频检索技术的关键问题.文中提出一种基于多重压缩感知和距离计算的关键帧提取算法,首先将镜头内的各帧图像分割为若干不相交的块,通过滤波器生成块的高维特征;然后利用多个不同的、具有有限等距性质的稀疏矩阵对块高维特征进行采样,将采样的均值作为块的低维特征;采用多种距离计算相邻帧对应块之间的差异,完成子镜头的分割操作,在每个子镜头内部,选取与该子镜头平均内容最接近的帧作为关键帧.实验表明,该算法提取出的关键帧能够准确描述镜头的主要内容.
关键帧提取;压缩感知;距离计算;子镜头
关键帧是指视频镜头内部能够准确描述该镜头内容的帧图像序列,广泛应用于视频压缩与存储、快速检索、场景分析等领域.由于关键帧的重要作用,相关的分析和提取向来被认为是基于内容的视频分析与检索技术的核心问题[1],在工业界和学术界得到了广泛重视与研究.
传统的关键帧提取算法主要包括运动分析法、内容差异法、聚类分析法、压缩域法、边界法等.运动分析法利用镜头内部物体的运动信息进行估计,存在计算量大、复杂度高的缺点;内容差异法考虑相邻帧间的像素值差异,在超过某个预定的阈值时提取关键帧,对运动、噪声和特效比较敏感;聚类分析法利用聚类算法将镜头内容聚为若干类别,取各类别的中心作为关键帧,算法受到聚类效果的影响,且存在时间不连续的问题;压缩域法通过视频的压缩信息进行关键帧提取,无法应用于非压缩域的视频,对压缩算法的性能也较为敏感;边界法通常提取镜头的首尾和中间帧作为关键帧,无法准确描述镜头内容.
近年来,许多学者提出了相应的改进或新型算法.例如,文献[2]中采用稀疏基进行降维,通过基于稀疏基矩阵的时空信息聚类进行关键帧提取;文献[3]中采用 Jensen-Shannon、Jensen-Rényi和Jensen-Tsallis 3种散度作为相邻帧的差异度量方式进行关键帧提取;文献[4]中通过一种迭代的边缘裁剪方法,利用动态德劳内图聚类进行关键帧提取;文献[5]中利用运动、颜色和纹理特征构造动态与静态显著映射,通过注意力模型进行关键帧提取;文献[6]中采用一种视觉特征聚合机制,将RGB空间颜色相关性、颜色直方图和惯性矩相结合进行关键帧提取;文献[7]中利用共生矩阵提取帧图像的高级语义上下文信息,通过监控该信息的变化进行关键帧提取.
由于采用了较为复杂的特征运算和匹配方式,当前的关键帧提取算法普遍需要较高的运算和存储开销,提取的关键帧也不一定能够准确地描述镜头内容.据此,文中提出一种基于多重压缩感知和距离计算的关键帧提取算法,不仅可以降低运算和存储的需求,同时能够得到较为准确的关键帧集合.
1 基于块的帧图像特征
1.1 图像分块
随着视频编解码和采集技术的发展,高清视频的应用越来越多.以720 P视频为例,分辨率达到1 280×720,在如此大的范围内采用帧图像的全局特征进行匹配显然是不合理的.由于视频中的运动和特效往往只在某些局部发生,因此,将帧图像进行分块匹配,能够较好地避免运动与特效等消极因素带来的干扰.文中将帧图像分割为若干不相交的块,采用对应块匹配的方式进行特征比较,如图1.

图1 图像分块示例Fig.1 Illustration of image blocks
1.2 高维特征生成
使用滤波器对图像进行滤波是获取图像高维特征的常用做法.在视频中,滤波模板内的像素点有时需要赋予相同的权值,有时需要赋予不同的权值,因此采用均值和高斯两种滤波器进行滤波.滤波尺度从3开始,每次增加的步长为2,最大尺度限制在块宽和高的25%.经过滤波后生成的块高维特征如式(1).

式中:r为滤波最大尺度;Fc为滤波器;Bp,q为第p× q个块;w和h分别为块的宽和高.可以看出,高维特征的维度与块的宽和高成正比,也即块的宽与高越大,滤波生成的高维特征维度越高.
1.3 利用多重压缩感知生成块的低维特征
经过滤波器滤波生成的块高维特征能够准确描述块的信息,然而,由于维度的影响,高维特征往往难以直接应用于计算.例如,将分辨率为1 280× 720的帧图像分割为8×8的块集合,则每个块的大小为160×90,对应生成的高维特征维度约为105,在具有数十万幅帧图像的视频中进行如此高维的运算显然会造成巨大的开销与损耗.因此,利用降维的操作将高维特征转换为低维特征是实际运算中的必然选择.
压缩感知是一种新型信号采样与复原理论[8-15],与传统的香农——奈奎斯特采样相比,压缩感知能够以较低的频率对信号进行采样,得到的低维信号较好地保留了原始信号的信息,并能够以较高的概率复原原始信号.压缩感知进行信号采样的过程如式(2):

式中:x为原始信号;y为采样信号;R为M×N的采样矩阵;为达到降维的目标,一般有M≪N.
根据压缩感知理论,如果x是K稀疏的,则当R满足有限等距性质(RIP)时,y能够以较高概率复原x.常用的符合有限等距性质且具有稀疏性的矩阵如式(3):
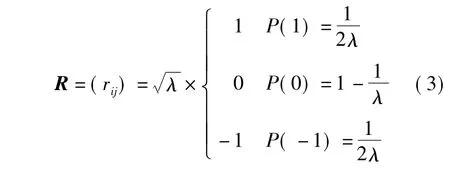
在R为标准正态分布的条件下,λ的取值一般为1,3,N1/2或N/logN.
由以上可以看出,直接使用压缩感知思想能够实现高维特征的降维操作.但是,式(2)、(3)能够准确应用于采样和复原的前提是原始信号必须是K稀疏的,而高维图像滤波信号并不能保证具备这一前提.换句话说,单次使用压缩感知得到的低维帧图像特征,有可能出现较多的信息丢失,导致低维特征不能准确描述图像信息.基于这个推理,文中提出采用多重压缩感知采样的思想,将多重采样得到的均值作为帧图像的低维特征,从而降低采样过程中出现的误差,尽可能多的保留原始帧图像的信息.

式中,yi,j代表第i×j块的低维特征,用于对该块的信息进行描述.
2 基于多距离计算的子镜头分割
计算出镜头中所有帧图像的块低维特征后,下一步的工作就是采用距离度量判断相邻帧图像各对应块之间的差异性,从而完成子镜头的分割操作.由于视频存在多样性的特点,单纯使用某一种距离无法准确判定两个块之间的差异程度.因此,文中采用多距离计算的方式综合衡量块与块之间的差异.
2.1 距离度量公式
块的低维特征可以看作是向量空间中的点,因此,块与块之间的差异可以通过点与点之间的距离进行衡量.从向量的直线距离和夹角距离两个方面考虑,文中采用闵可夫斯基距离族、标准欧几里德距离、余弦距离族和马哈拉诺比斯距离进行差异度量,共8种距离计算方法,如式(8~13):

式(8)为闵可夫斯基距离族,采用该族中的欧几里德距离、曼哈顿距离和切比雪夫距离.式(9)为标准欧几里德距离.式(10)为余弦距离,式(11)、(12)分别为余弦距离族中的修正余弦距离和皮尔逊相关系数距离.式(13)为马哈拉诺比斯距离.
将以上距离进行综合计算,能够有效克服其中一种或几种距离因对量纲、数值、角度等因素敏感而引起的差异度量错误问题,从而提升计算的准确性和鲁棒性.
2.2 多距离计算下的子镜头分割
根据前文描述的图像分块、高低维特征计算、距离度量等,设计子镜头分割算法如下:
1)将镜头内部所有的帧进行分块;
2)计算出每帧的各块高低维特征;
3)对于相邻帧fk和fk+1,可以计算出8个距离矩阵,如式(14):
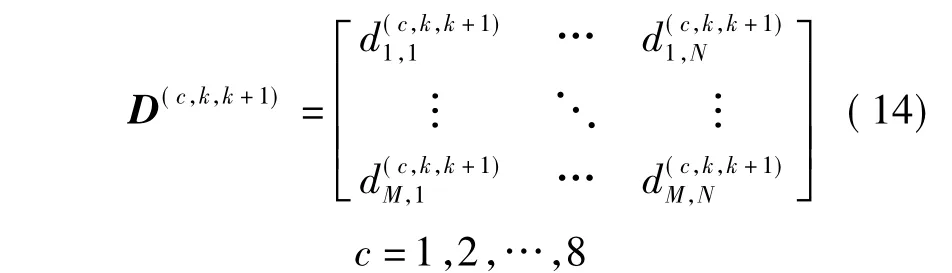
4)计算出所有相邻帧的8个距离矩阵的均值矩阵和协方差矩阵,如式(15)、(16):
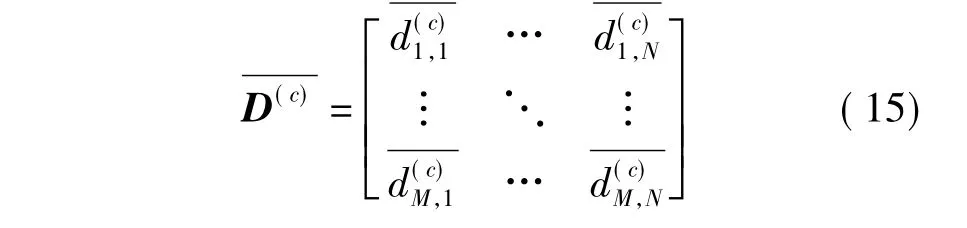
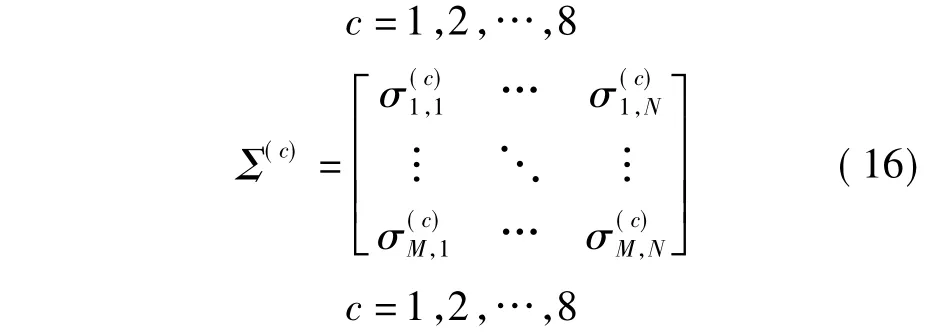
5)在相邻帧fk和fk+1的每个距离矩阵中,找出所有满足式(17)的元素:

式中,μ是一个较小的正数.
6)如果满足式(17)的元素个数超过块数的1/3,则标记该距离矩阵为活跃距离矩阵.当活跃距离矩阵数量超过距离矩阵总数的1/2时,认为相邻帧fk和fk+1是一个子镜头边界.
可以看出,算法的基本思想是通过多种距离计算求出相邻帧发生较大变化的对应块数量,当这个数量超过一定值时,认为当前的相邻帧属于一个子镜头边界,从而达到子镜头分割目标.
3 基于子镜头的关键帧提取
每个子镜头反映了一段内容相对稳定的帧图像序列,因此,从每个子镜头中提取一幅帧图像作为关键帧,按子镜头的先后顺序将这些关键帧进行排列,就可以得到关键帧的集合,而这个集合,能够准确描述整个镜头的内容.
按照分类的观点,不同的子镜头可以看作是不同的类别,因此,选择每个类别中最靠近类内中心的帧图像作为关键帧,显然能够准确反映出该类的主要内容.鉴于以上推理,首先计算各子镜头内部的类内中心,如式(18):

式中:C(k)为第k个子镜头的类内中心;Yi(k)为该子镜头中第i个帧图像的低维特征;L为该子镜头的长度.
其次,根据式(8~13)计算子镜头内部各帧到类内中心的距离,可以得到各帧与类内中心之间的8个距离矩阵,如式(19):
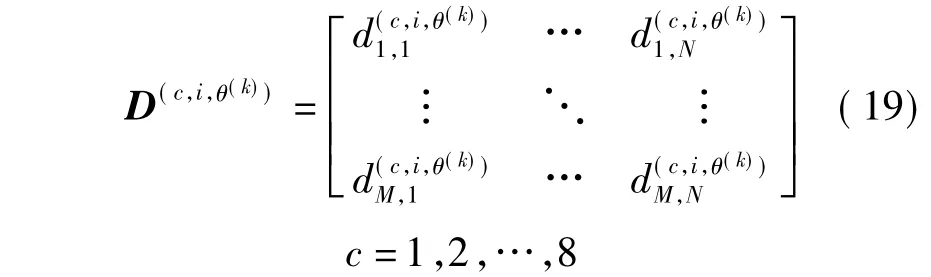
式中,θ(k)为第k个子镜头类内中心的标记;i为该子镜头中第i帧的标记;矩阵中的每个元素是按第c种距离方式计算出的对应块距离值.
然后,对于子镜头内部各帧与类内中心之间的距离矩阵,按照从小到大的顺序计算其每个元素在各自维度上的排序,从而得到每帧的排序矩阵:

按第c种距离方式计算出对应块距离值在所有同位置块距离值中的排序位置,将其作为矩阵中的每个元素.
经8种距离方式综合衡量后,选择最接近于类内中心的帧作为关键帧,如式(21):

式中,j(k)为第k个子镜头的关键帧位置.
4 实验结果与分析
实验在Intel G2020 CPU、4GB内存的PC机上进行,采用Matlab 2013b编程,测试数据集来源于10段1 280×720分辨率的高清视频,这些视频中的镜头和关键帧已通过手工进行标注.具体的测试视频信息如表1.

表1 测试视频信息Table 1 Information of the test videos
关键帧提取的主要用途在于为后续的视频摘要、场景分析和情节重构提供支撑,因此,关键帧的提取应尽可能保证100%的查全率.出于以上考虑,文中采用基准精确率对算法性能进行评价,如式(22):

式中:k为正确检测出的关键帧数量;f为错误检测出的关键帧数量;k+f为满足100%查全率条件的最小数量.
实验中,帧图像被分为8×8块,每块的大小相同.采样矩阵R的行数设为220,采样次数设为10.为验证实验效果,将文中算法与文献[2]和文献[6]中的算法进行了比较.表2和图2列举了实验的定量结果,表2中的A、B和C分别代表文中算法、文献[2]中算法和文献[6]中算法.图3列举了算法在部分视频上进行关键帧提取的定性结果.

表2 实验定量结果Table 2 Quantitative results of the experiments

图2 实验效果比较Fig.2 Comparison of the experimental results
由表2和图2可以看出,所提算法在10段测试视频中取得了较好的实验效果,在每段视频中的基准精确率均高于其他两种算法.从图3可以看出,算法提取出的关键帧没有连续和相似的问题,能够准确描述镜头的主要内容.然而,在帧内目标剧烈运动、拍摄特效和强烈光照等不利因素的干扰下,算法仍然会出现部分误判的问题.这主要是因为在目标高低维特征生成过程中,单纯从数值的角度建立帧图像的特征描述,没有考虑数值变化的速率问题,从而导致计算出的距离矩阵误差较大,直接影响了子镜头分割的准确性.这方面问题的解决,有待于高级语义信息与低级视觉特征相结合的研究.

图3 部分视频关键帧Fig.3 Partial video key frames
5 结论
图像高维特征无法保证满足K稀疏的要求,从而导致单次压缩感知的采样可能会产生较多的信息丢失,鉴于这个问题,文中提出采用多重压缩感知进行采样并取均值的思想,能够较好地抵消信息丢失带来的负面影响.为进一步提高计算的准确性,文中引入图像分块的预处理操作,并通过多种距离度量,从直线和夹角两个方面计算相邻帧的特征差异.排序的运算避免了因量纲和数值范围不同而对距离计算产生干扰的问题.实验结果表明,所提算法在实验视频中取得了较好的效果.为了更好地消除光照、运动、噪声和特效等因素的负面影响,今后的主要工作将集中于帧图像高级语义信息的获取,以及与低级视觉特征相结合生成鲁棒鉴别特征的研究.
References)
[1]Liu Xiao,Song Mingli,Zhang Luming,et al.Joint shot boundary detection and key frame extraction[C]∥In Proceedings of the 21st IEEE International Conference on Pattern Recognition.TsuKuba,JAPAN: IEEE,2012:2565-2568.
[2]Kumar M,Loui A C.Key frame extraction from consumer videos using sparse representation[C]∥InProceedings of the 18th IEEE International Conference on ImageProcessing.Brussels,Belgium: IEEE,2011:2437-2440.
[3]Xu Qing,Liu Yu,Li Xiu,et al.Browsing and exploration of video sequences:A new scheme for key frame extraction and 3D visualization using entropy based Jensen divergence[J].Information Sciences,2014,278:736-756.
[4]Kuanar S K,Panda R,Chowdhury A S.Video key frame extraction through dynamic Delaunay clustering with a structural constraint[J].Journal of Visual Communication and Image Representation,2013,24 (7):1212-1227.
[5]Lai Jieling,Yi Yang.Key frame extraction based on visual attention model[J].Journal of Visual Communication and Image Representation,2012,23(1): 114-125.
[6]Ejaz N,Tariq T B,Baik S W.Adaptive key frame extraction for video summarization using an aggregation mechanism[J].Journal of Visual Communication and Image Representation,2012,23(7):1031-1040.
[7]Yong S P,Deng J D,Purvis M K.Wildlife video keyframe extraction based on novelty detection in semantic context[J].Multimedia Tools and Applications,2013,62(2):359-376.
[8]Qaisar S,Bilal R M,Iqbal W,et al.Compressive sensing:from theory to applications,a survey[J].Journal of Communications and Networks,2013,15 (5):443-456.
[9]Li P,Hastie T J,Church K W.Very sparse random projections[C]∥In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Philadelphia,USA:[s.n.],2006:287-296.
[10]Strohmer T.Measure what should be measured:progress and challenges in compressive sensing[J].IEEE Signal Processing Letters,2012,19(12): 887-893.
[11]Yang Jianbo,Liao Xuejun,Yuan Xin,et al.Compressive sensing by learning a Gaussian mixture model from measurements[J].IEEE Transactions on Image Processing,2015,24(1):106-119.
[12]Engelberg S.Compressive sensing[J].IEEE Instrumentation&Measurement Magazine,2012,15(1): 42-46.
[13]Donoho D L.Compressed sensing[J].IEEE Transactions on Information Theory,2006,52(4):1289-1306.
[14]Friedland S,Li Q,Schonfeld D.Compressive sensing of sparse tensors[J].IEEE Transactions on Image Processing,2014,23(10):4438-4447.
[15] 潘磊,束鑫,程科,等.基于压缩感知和熵计算的关键帧提取算法[J].光电子激光,2014,25(10): 1977-1982.
Pan Lei,Shu Xin,Cheng Ke,et al.A key frame extraction algorithm based on compressive sensing and entropy computing[J].Journal of Optoelectronics· Laser,2014,25(10):1977-1982.(in Chinese)
(责任编辑:童天添)
Video key frame extraction based on multiple compressive sensing and distances'computing
Pan Lei1,2,Shu Xin1,Zhang Jing1,Qi Yunsong1
(1.School of Computer Science and Engineering,Jiangsu University of Science and Technology,Zhenjiang Jiangsu 212003,China) (2.Key Laboratory of Modern Agricultural Equipment and Technology,Ministry of Education,Jiangsu University,Zhenjiang Jiangsu 212013,China)
Key frame extraction is considered as the key issue of content-based video retrieval.An algorithm based on multiple compressive sensing and distances'computing is proposed.In the first step,each frame in one shot is segmented into several disjoint blocks,high dimensional features of which are generated by filtering.Then,multiple different sparse matrices that satisfy restricted isometry property are employed to sample the high dimensional feature of each block,and the mean value of sampling is calculated as the low dimensional feature of each block.Several different distances are used to compute differences between corresponding blocks of neighboring frames to conduct sub-shot segmentation.The frame nearest to the average content of each sub-shot is selected as the key frame.Experimental results demonstrate that key frames extracted by the proposed algorithm can describe the main content of shot accurately.
key frame extraction;compressive sensing;distance computing;sub-shot
TP391
:A
:1673-4807(2015)05-0437-06
10.3969/j.issn.1673-4807.2015.05.006
2015-05-25
国家自然科学基金资助项目(61103128,61471182,61170120,61305058,61503160);江苏省自然科学基金资助项目(BK20130473,BK20130471,BK20140419);江苏省科技创新与成果转化(重大科技成果转化)项目(BA2012129);江苏大学现代农业装备与技术教育部重点实验室开放基金资助项目(NZ201303)
潘磊(1980—),男,讲师,研究方向为模式识别、计算机视觉.Email:just-panlei@just.edu.cn
潘磊,束鑫,张静,等.基于多重压缩感知和距离计算的视频关键帧提取[J]江苏科技大学学报:自然科学版,2015,29(5):437-442.
