基于PAAG的纹理特征提取算法的并行实现
2015-06-23李雪丹
李 涛, 李雪丹
(西安邮电大学 电子工程学院, 陕西 西安 710121)
基于PAAG的纹理特征提取算法的并行实现
李 涛, 李雪丹
(西安邮电大学 电子工程学院, 陕西 西安 710121)
针对多态同构阵列机,提出一种新的方法对计算视觉算法中的纹理特征提取算法进行并行处理。该方法在基于计算视觉标准OpenVX的基础上,将纹理特征提取算法的各步骤用OpenVX核函数进行实现,并构造出该算法的图模型,再将图模型利用OpenVX库函数映射到多态同构阵列机上进行并行处理。实验结果表明,该方法所实现的加速比按线性增长,纹理特征提取算法的执行效率得到显著提高。
多态同构阵列机; 计算机视觉;纹理特征提取;OpenVX ;并行设计
近年来,计算机视觉的理论研究和实际应用都取得了飞速的发展[1]。纹理特征提取是计算机视觉领域的一项热门应用,其在目标识别和工业检测等领域有着广泛应用[2]。
常用的纹理特征提取算法有灰度直方图法、共生矩阵法及小波变换法等[3],灰度直方图法无法利用像素相对位置这一空间信息,因而对纹理特征描述的准确度相对较差;共生矩阵法算法实现较复杂,尤其是构造共生矩阵需要很大的计算量;而小波变换的冗余度很大。基于Haar特性局部二元模式(Local Binary Pattern,LBP)的纹理特征提取算法[4],具有优良的统计特性,能够在效率与速度之间找到最佳平衡点,并且计算简单可行,已经在许多研究领域取得了实效。
在纹理特征提取算法的并行处理方面,传统的图形处理器(Graphics Processing Unit,GPU)仅支持单指令多数据流 (Single Instruction Single Data, SIMD)模式或者是单指令多线程 (Single Instruction Multiple Data,SIMT)模式[5]的并行计算,而新型多态同构阵列机[6](Polymorphic Array Architecture for Graphics and image processing,PAAG)有专门的硬件配置机制,可以结合数据级并行、线程级并行以及操作级并行[7]的并行方法进行并行计算。
本文拟利用最新计算视觉标准OpenVX 1.0[8]对纹理特征提取算法进行并行处理。在第1节中对PAAG阵列机进行简单介绍,在第2节中对OpenVX图的执行模式及基于Haar特性的LBP纹理特征提取算法进行分析,在第3节中介绍算法的并行设计方案和实现,第4节讨论实验结果,第5节是结束语。
1 PAAG多态并行处理器
PAAG阵列机系统由多个簇构成,每个簇是由16个处理单元(PE)组成的4×4阵列,如图1所示。该结构的处理单元有单指令多数据SIMD和多指令多数据(Multiple Instruction Stream Multiple Data Stream,MIMD)两种运行模式,兼有异步执行机制、硬件的多线程管理器和高效通信机制[9],并且支持主要并行方法,包括数据并行(Data Level Parallelism,DLP)、线程级并行(Thread Level Parallel,TLP)、指令并行(Instruction Level Parallelism, ILP) 和操作并行(Operation Level Parallel,OLP)。每行的行控制器(Row Controller, CRi)控制该行中4个PE的SIMD运算;每列的列控制器(Column Controller, CWj),作为共享存储管理,可供处理单元读取和发回数据。

图1 PAAG 阵列机单个簇基本架构
每个处理单元由1个算数逻辑运算器(PE pipelines)、1个线程控制器(ThMan)、1个路由器(RtMan)、4个邻接共享存储(NEWS)、数据存储数据存储(dCache)和指令存储(iCache)组成,每个PE的存储大小为4 K。该阵列机支持PE间的近邻通信和远程路由通信,PE可通过近邻通信与上下左右4个PE进行直接通信,也可通过PE之间的路由器进行远程通信[10],PE之间通过使用阻塞和非阻塞方式实现数据传送。
2 OpenVX及纹理特征提取算法
2.1 OpenVX
OpenVX是计算机视觉的底层加速标准,主要被用来设计视觉应用以支持各种硬件系统。OpenVX将计算视觉的应用抽象为图(Graph)模型,计算视觉的处理过程用OpenVX中的核函数(kernel)实现,并将核函数关联到相关的结点中,以调用的先后顺序将各结点进行连接,构建成OpenVX中的图模型。
2.2 纹理特征提取算法
基于Haar特性局部二元模式的纹理特征提取算法[4]的步骤如下。
步骤1 对图像进行平滑去噪处理[2]。平滑去噪过程为通过一个卷积核在整个图像上移动,利用卷积算法求出中心点的输出值,选取高斯滤波算法,卷积矩阵[2]为
步骤2 计算图像的Haar特征[11]。首先定义特征模板,矩形模版类别如图2,模板大小为3×3的区域,模板的特征值为白色区域像素和减黑色区域像素和,每个3×3窗口内有两个Haar特征值。

图2 Haar特征模板
步骤3 计算完每个3×3窗口内的特征值后,将两个特征值分别通过阈值比较做二值化处理,大于等于阈值的为1,小于阈值的为0,此处阈值取T=20。再将两个二值化的结果进行加权求和,得到中心点的编码值,窗口在整个图像上移动,得到整幅图像的编码值。
步骤4 得到整幅图像的编码值后,作直方图处理,统计出的直方图即为整幅图像的纹理特征向量。
基于Haar特性的LBP纹理特征提取算法中,步骤1中的高斯滤波可用OpenVX中核函数Gaussian Filter实现,步骤2中提取Haar特征的过程,可用核函数Integral实现,步骤3计算编码值的过程可用OpenVX中用户自定义函数实现,步骤4统计直方图的过程可用核函数Histogram实现。上述核函数在OpenVX中定义如下。
Thresholding——输入图像的像素值与阈值进行比较,若大于阈值则输出像素值为1,若小于则输出像素值为0[8]
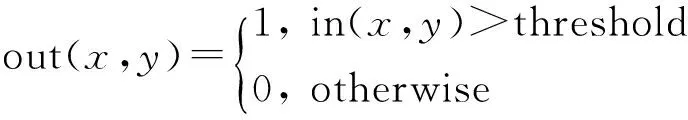
此算法中阈值T=20。
Gaussian Filter——图像的平滑滤波计算输入图像每个掩膜窗口乘相应的卷积核,此时的卷积矩阵[8]为
Histogram——对图像的各像素值的数量进行统计,图像的像素值为0~255。
Integral——输出点的像素值由其左上方所有已计算出的像素值进行运算[8]得出
sum(x,y)=in(x,y)+sum(x-1,y)+sum(x,y-1)-sum(x-1,y-1)
核函数关联到相应结点,并根据调用的先后顺序构成OpenVX的图模型如图3所示。

图3 纹理特征提取算法的图模型
3 算法的并行化设计和实现
OpenVX系统以通用CPU作为主机端,控制图的创建和资源调度,将图模型中的结点映射到硬件设备上执行以实现算法的并行加速。据此并行机制,将纹理特征提取算法图模型中的结点映射到PAAG上的PE上进行处理。
纹理特征提取算法图模型中,OpenVX核函数为顺序执行,故可采用PE之间流水线结构进行处理。该算法的串行设计为将图中每个结点映射到一个PE上,具体映射关系如图4所示,各PE对相应结点进行处理,并依次执行。

图4 纹理特征提取串行设计
在并行设计方法中,将图模型中各结点分别映射到PAAG阵列机的不同个数的PE上进行处理。映射关系如图5所示,通过各结点的并行处理,完成整个算法的并行化。针对每一个结点,都用4个PE进行并行处理,而对于每一个结点,由于其关联到的核函数内部算法并行度不同,PE之间又采用不同的方法进行并行处理。
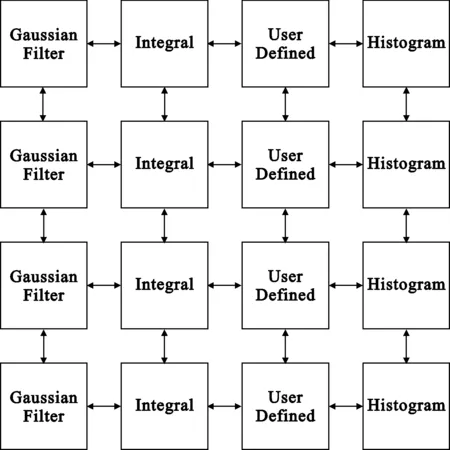
图5 纹理特征提取算法并行设计
3.1 Gaussian Filter的并行化设计和实现
采取数据并行的方法进行处理,将图像的数据进行分配,如图6所示。
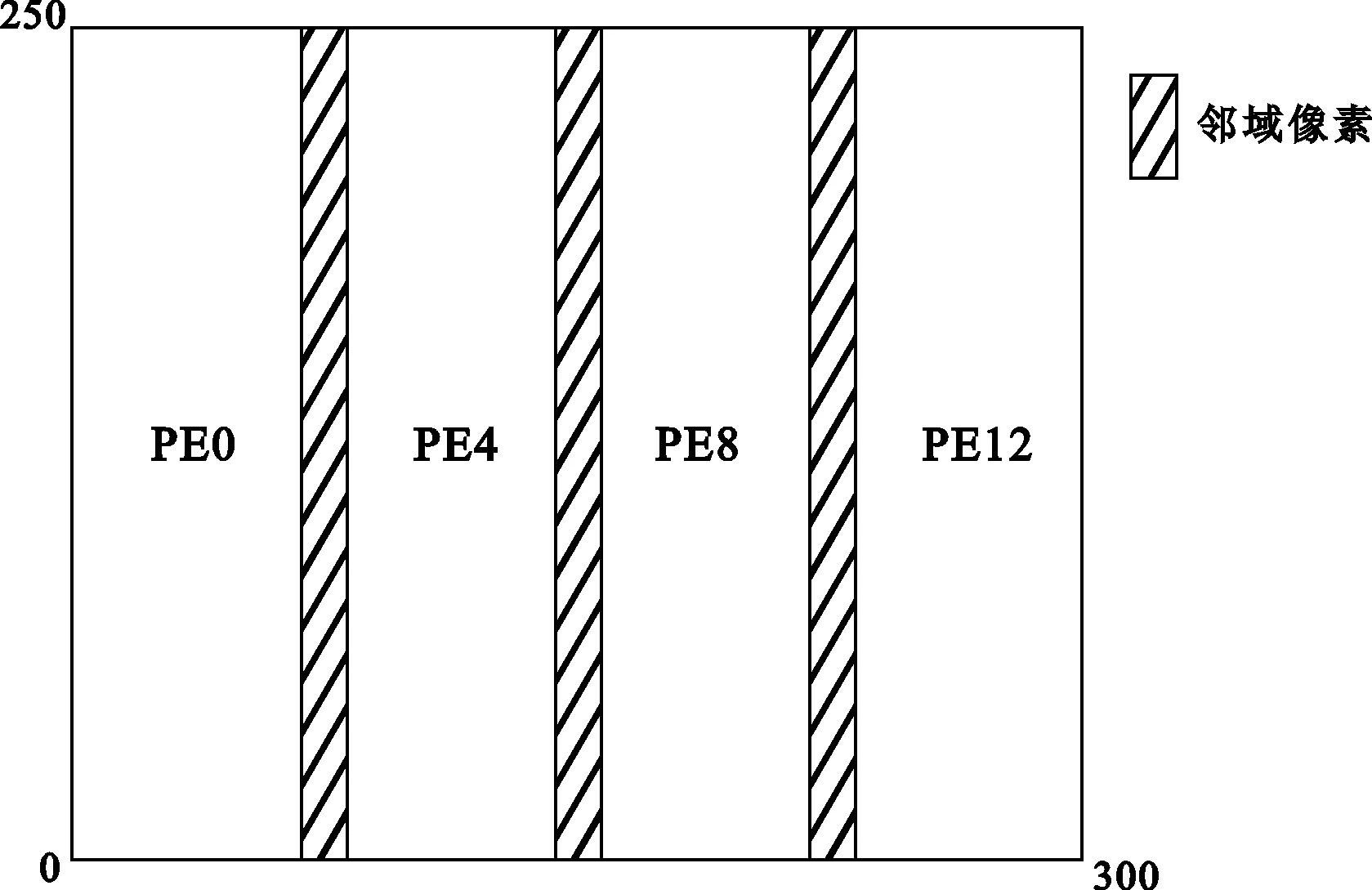
图6 Gaussian Filter算法数据分配方法
PE0、PE4、PE8和PE12分别读取相应的数据块及相邻阴影部分数据。
3.2 Integral并行化设计和实现
根据Integral算法的特点,采用操作并行的方法,如图7所示。图像积分算法映射到各个PE上之后,按上三角的形式形成波前阵列,标号相同的表示对像素的处理过程在各个PE中同时进行。每个PE处理一行中的数据,在计算出位置0处的像素点的积分值后,才可进行位置1处的像素点的积分运算,以此类推,计算出位置1的像素点的积分值后,才可进行位置2的像素点的积分运算,形成波前阵列。
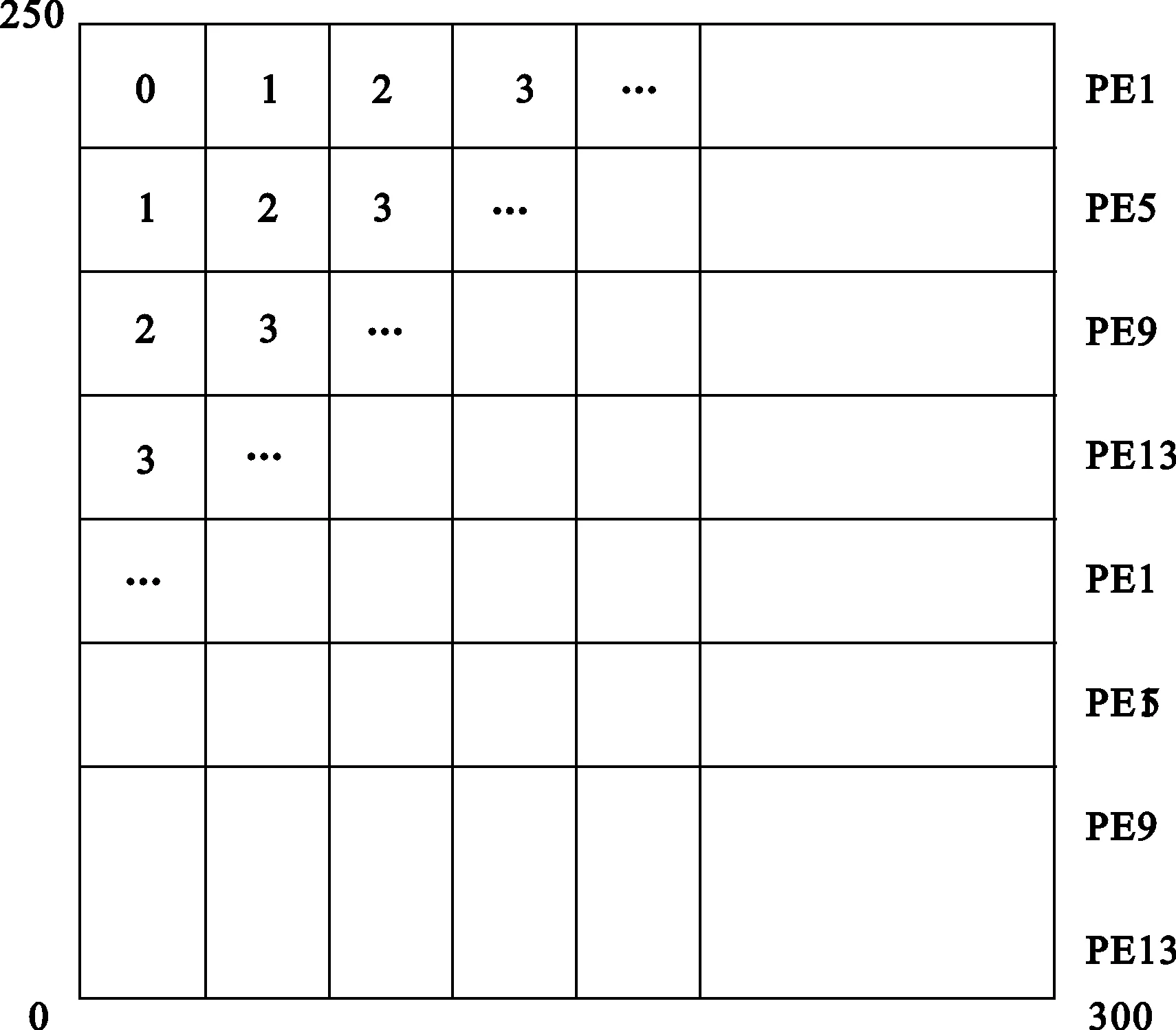
图7 Integral算法操作并行方法
并行处理步骤如下。
(1)PE1首先读取图像第一行第一个像素值,由于计算过程涉及到邻域像素,图像边界像素没有邻域像素,故采用复制原边界法。PE1首先在阻塞模式下将位置0的像素值发送给PE5,PE5接收到位置0的数据,进行第二行中位置1的像素积分值运算,同时PE1也进行第一行中位置1的像素的积分值运算。
(2)PE5计算出位置1的像素积分值后,将此值在阻塞模式下发送到PE9,PE9接收到此值后,进行第三行中位置2处的像素的积分值运算,同时,PE1将第一行中位置1处的积分值传送到PE5中,PE5进行第二行中位置2处的像素积分值运算,同时,PE1进行第一行中位置2处的像素积分值运算,此时,PE1、PE5和PE9同时计算三行中位置2处像素的积分值。以此类推,在计算出位置2处的像素的积分值后,PE1、PE5、PE9和PE13可同时进行位置3处的像素的积分值运算。
(3)PE1处理完第一行后,跳到第5行接收PE13发送的数据继续对第5行的数据进行积分运算,以此类推,PE5、PE9和PE13在处理完一行的像素值后,跳到第6,7,8行进行计算。由此可计算出整幅图像的积分值。
3.3 用户自定义函数并行化设计和实现
用户自定义函数需对窗口内不同方向上求出特征值进行加权求和运算,涉及到像素值的邻域像素,故采用数据并行的方法,图像数据分配方法与Gaussian Filter相同。
3.4 Histogram并行化设计和实现
Histogram为直方图统计算法,采用操作并行方法,PE之间以流水线处理的方法,每个PE在进行运算的同时向下一级PE传送结果数据,所有PE计算出的Histogram的值需累加到一个PE上存储。
并行处理步骤如下。
(1)PE3、PE7、PE11和PE15接收到其左侧PE传送的编码值后,进行直方图统计,将特定的像素值个数存放到某段连续的地址中。
(2)PE3统计完之后,在阻塞模式下,向PE7发送数据,首先传送像素值为0的像素个数,PE7在统计完当前PE中的数据后,接受PE3发送的数据,与PE7中的存放像素值0的个数的地址中数据相加,依次处理,将0~255像素值的个数进行相加统计到PE7中。
(3)PE7统计完后,再向PE11发送数据,PE11再与本地的统计数进行累加,最终结果存放到PE15中。
4 实验结果分析
在衡量并行处理的效率时,使用加速比[12]作为加速效率的基准,加速比定义为算法串行执行的时钟数与并行执行的时钟数之比。当加速比大于1时,表示优化后的计算速度较之串行时有所提高。而当计算出的加速比接近所使用的处理单元个数时,加速比为线性增长。
将纹理特征提取算法及OpenVX核函数在PAAG上进行串行处理与并行处理,得到实验结果如表1所示。
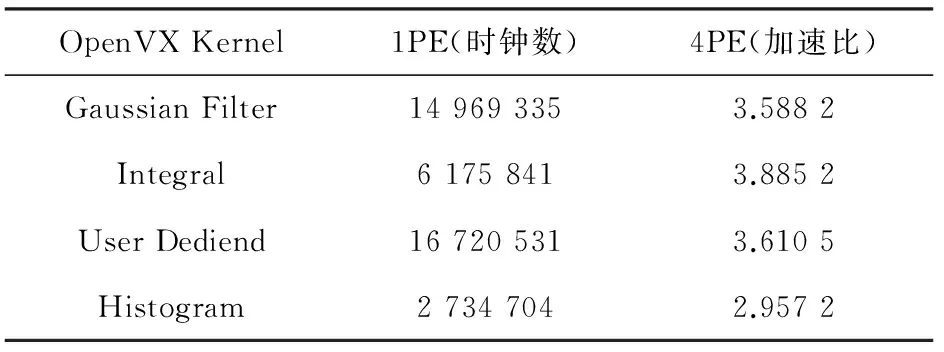
表1 OpenVX核函数并行加速比
实验中,纹理特征提取算法的图模型的执行过程为流水线结构,串行执行的时钟数统计为26512875,并行执行的时钟数统计为763082,并行加速比为3.4744。
实验结果表明,OpenVX单个核函数中,Histogram算法因涉及到PE之间大数据量的通信,加速比未达到线性加速,Integral波前阵列算法加速比达到最高,接近于4,其他大部分核函数经过并行化处理后的加速比呈线性加速度。纹理特征提取算法经并行化后的加速比也接近并行处理所使用的PE数与串行处理使用的PE数之比,故加速比呈线性加速度,执行效率得到了显著提高。
5 结束语
将OpenVX核函数和纹理特征提取算法在PAAG平台上进行并行处理,实现算法的并行加速,得到了线性增长的加速比,提高了算法的执行效率。实验结果表明通过OpenVX标准的PAAG阵列机上并行化的实现,可以充分加速图像处理计算。相信这种方法在计算机视觉领域的其他方面会得到一定的应用。
[1] 陈天华.数字图像处理[M]. 北京:清华大学出版社,2007:12-25.
[2] Parker J R.图像处理与计算机视觉算法及应用[M]. 景丽,译.北京:清华大学出版社,2012:54-70.
[3] 王惠明,史萍. 图像纹理特征的提取方法[J]. 中国传媒大学学报:自然科学版,2006,13(1):50-52.
[4] 周书仁,殷建平.基于Haar特性的LBP纹理特征[J].软件学报,2013,24(8):1909-1926.
[5] 韩俊刚, 刘有耀, 张晓.图形处理器的历史现状和发展趋势 [J]. 西安邮电学院学报,2011,16(3):61-64.
[6] 李涛,肖灵芝.面向图形和图像处理的轻核阵列机结构[J]. 西安邮电学院学报, 2012, 17(3): 41-47.
[7] 陈国良,孙广中.并行计算的一体化研究现状与发展趋势[J].科学通报,2009,54(8):1043-1049.
[8] Erik Rainey,Susheel Gautam. r26495, The OpenVXTM[Provisional] Specification Version1.0 [S]. USA:Khronos Vision Working Group, 2014.
[9] 朱豪杰,韩俊刚,邓军勇,等. GPU命令处理器的存储管理单元设计[J]. 西安邮电大学学报,2013,18(1):78-81.
[10] 冯宝丽.动态路由选择协议在网络通信中的应用[J].科技信息,2008(30):283-294.
[11] 刘丽,匡纲要.图像纹理特征提取方法综述[J].中国图象图形学报,2009,14(4):622-635.
[12] Boyd C. Data-parallel computing[J]. Queue, 2008, 6(2): 30-39.
[责任编辑:祝剑]
A parallel implementation of texture feature extraction algorithm based on PAAG
LI Tao, LI Xuedan
(School of Electronic Engineering, Xi’an University of Posts and Telecommunications, Xi’an 710121, China)
A new method for parallelizing texture feature extraction algorithm on Polymorphic Array Architecture for Graphics processor is presented in this paper. In this method, each algorithm based on the newest low-level computer version standard- OpenVX is evaluated by analyzing the control dependencies and data dependencies of the image algorithms. By constructing the graph mode of the algorithms and map these on the PAAG, executing the paralleling computing, a linear speed can be obtained in the experimental result and the efficiency of processing is improved.
polymorphic array architecture for graphics and image processing (PAAG), computer vision, texture feature extraction, OpenVX, parallelization
2014-12-16
国家自然科学基金重大项目(61136002)
李涛(1964-),男,博士,教授,从事计算机体系结构、集成电路设计等研究。E-mail:litao@xupt.edu.cn 李雪丹(1989-),女,硕士研究生,研究方向为图形图像与视频处理技术。E-mail:lixuedan1988@sina.com
10.13682/j.issn.2095-6533.2015.02.003
TP302
A
2095-6533(2015)02-0011-05
