CPU-GPU协同加速K riging插值的负载均衡方法*
2015-06-21姜春雷张树清中国科学院东北地理与农业生态研究所吉林长春3002中国科学院大学北京00049
姜春雷,张树清(.中国科学院东北地理与农业生态研究所,吉林长春3002;2.中国科学院大学,北京00049)
CPU-GPU协同加速K riging插值的负载均衡方法*
姜春雷1,2,张树清1
(1.中国科学院东北地理与农业生态研究所,吉林长春130102;2.中国科学院大学,北京100049)
Kriging插值算法被广泛应用于地学各领域,有着极其重要的现实意义,但在面对大规模输出网格及大量输入采样点时,不可避免地遇到了性能瓶颈。利用OpenCL和OpenMP在异构平台上实现了CPU与GPU协同加速普通Kriging插值。针对Kriging插值中采样点的不规则分布及CPU和GPU由于体系结构差异对其的不同适应性,提出一种基于不同设备间计算性能的差异和数据分布特点的负载均衡方法。试验结果表明,该方法能有效提高普通Kriging插值速度,同时还能节约存储空间和提高访存效率。
通用计算图形处理器;开放运算语言;Kriging插值;负载均衡
Kriging插值算法是一种考虑区域变量空间变异结构(自相关结构)特点的线性无偏最优估计插值方法[1],它在地学的很多领域都有着重要的应用。但是,当Kriging插值的输出网格增大及输入采样点增多时,其计算时间急剧增加[2]。当前,集成Kriging插值算法的主流地理资讯系统(Geographic Information System,GIS)仍以串行计算为基础框架,不能充分利用多核处理器的优势[3]。随着各种并行技术的不断成熟,地理空间栅格数据算法的并行化研究成为新的热点[4]。很多研究者试图通过不同的并行技术来加速Kriging插值。目前,针对Kriging插值的加速方法主要基于的编程模型有消息传递接口(Message Passing Interface,MPI)[5],OpenMP[6]和通用计算图形处理器(General Purpose Graphics Processing Units,GPGPU)[7-8]。基于这些不同编程模型的Kriging插值算法都取得了很好的加速效果,尤其是GPGPU编程模型的加速比更高。然而,GPGPU加速算法仅将CPU作为一个流程控制端,造成了GPU计算时CPU空闲等待,显然,CPU与GPU共同承担计算任务的方式是未来协同并行计算的发展方向[9]。
多设备协同加速需要解决的核心问题之一是设备间的负载均衡问题。目前关于计算设备间负载均衡的研究主要集中在根据不同设备的性能差异分配计算的静态负载均衡[10-11]以及在计算过程中根据不同计算设备进度分配计算的动态负载均衡[12]。夏飞等[13]对于异构设备(例如CPU与GPU)间的负载均衡给出了根据计算能力分发计算任务的静态负载均衡方法;赵斯思和周成虎[14]对于单个GPU上多个kernel同时执行,提出一种基于动态规划的动态负载均衡方法,有效地加速了算法的执行。对于Kriging插值而言,由于受限于自然环境、经济和人力等条件的限制,采样点通常不规则,表现为分布不均匀。由于体系结构的差异,对于数据量相同但分布密度不同的数据,不同体系结构的硬件通常表现出不同的计算速度。这表明负载均衡时不仅要考虑不同设备间性能的差异,还应考虑数据的特征。
本文提出了一种新的综合考虑设备计算性能和数据特征的负载均衡方法(Load Balancing based on Computation Performance and Data Distribution,LBCPDD),来实现设备间高效合理的负载均衡,以达到更快加速Kriging插值的目的。
1 背景知识
1.1 普通K riging
普通Kriging插值公式可以表示为:
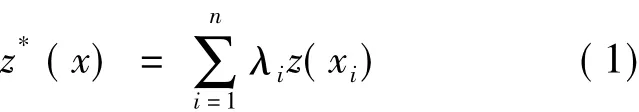
a.无偏性条件。
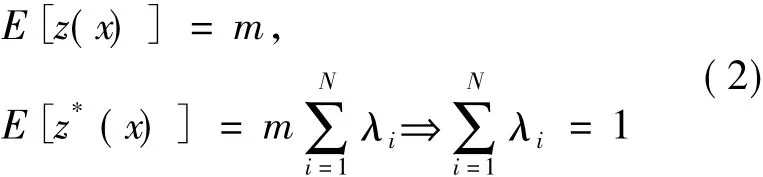
其中,E表示数学期望,m是中间变量。
b.最优性条件(即估计值误差的方差最小)。
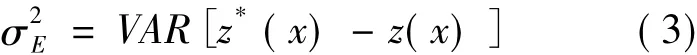
依据拉格朗日乘数法原理,建立拉格朗日函数:
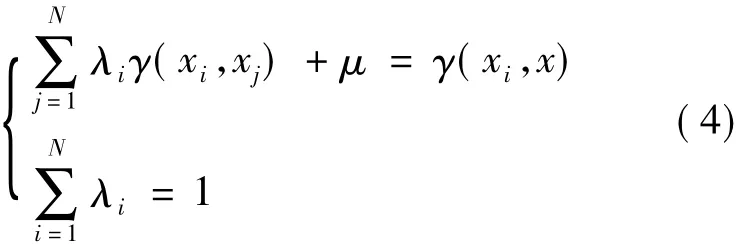
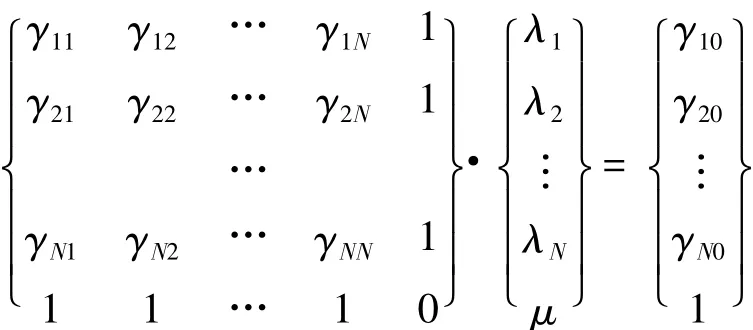
r是变异函数,上述方程组可用矩阵表示如下:解上述方程组,求得λi代入普通Kriging插值公式可计算出待估未知点的值。
1.2 通用计算图形处理器
GPGPU将原本只用于图形处理的硬件用于通用计算领域,OpenCL和统一计算设备架构(Compute Unified Device Architecture,CUDA)是实现这个理念的两种主要软件开发平台,OpenCL由于能够在不同的硬件平台上运行,更具应用前景。目前,GPGPU已经被广泛地应用于各领域的科学研究,其相关知识已经被相关文献大量描述,本文仅介绍在其他文献中被较少描述且被应用于本研究的相关内容。AMD公司和NVIDIA公司对同一硬件概念有不同的称谓,由于本研究基于AMD公司的GPU实现,因此在以后的描述中以AMD公司的概念为准。在AMD公司的GPU中,一个计算单元(Compute Unit,CU)可以同时运行多个workgroup,具体硬件运行的workgroup数及workgroup内的线程数由GPU的硬件环境决定,主要是内存数量,更少的内存消耗,可以让每个CU容纳更多的workgroup和每个workgroup容纳更多线程。workgroup内线程被分成若干个wavefront(等同于NVIDIA硬件中的warp),它是硬件调度线程执行的最小单位,其内部的线程以严格锁同步方式执行。如果wavefront内线程存在不同分支,则每个线程会因为锁同步方式而执行全部分支(无计算任务线程执行空操作),导致执行时间增加。数量足够的wavefront可以保证在一个wavefront等待内存访问结果时,其他的wavefront可以被调入执行单元执行(即交叉访问),这种方式大大提高了GPU的利用效率。因此wavefront对程序的执行速度有着巨大的影响。OpenCL并未对开发者提供wavefront抽象,但是通过对不同线程处理数据的合理安排可以提高GPU的运行效率,即提高wavefront数量以及减少单个wavefront内的线程分支。
2 基于计算性能与数据分布的负载均衡方法
在Kriging插值过程中,相邻的未知点通常有相同的邻近点。由于变异函数矩阵是基于待估未知点的邻近点构造的,因此相邻的未知点通常具有相同的变异函数矩阵。根据这一特点,在Kriging插值算法中增加一个步骤用于检查相邻未知点间是否具有相同的邻近点:若存在,则只存储其中一个未知点的邻近点,并且仅对其构造变异函数矩阵和求逆矩阵,即将相同邻近矩阵合并存储及计算,其他的未知点在计算过程中使用这个计算的结果。
采样点一般是不规则(不均匀)分布的,局部Kriging插值在对每个未知点进行插值时,需要求出离它最近的若干个采样点,在采样点密度较小的情况下,相邻未知点具有相同邻近点的概率更大,如图1左上角所示,两个未知点(*)具有相同的临近采样点(·);而采样点较密集时则相反(如图1右下角所示):两个未知点(*)具有不同的采样点(·)。对于GPU,较多的具有相同邻近点的线程使wavefront内产生更少的分支;由于合并存储和计算,采样点稀疏区域的未知点预测会消耗更少的内存和计算;内存消耗的减少让GPU能够容纳更多的线程并发执行以便GPU线程的交叉执行减少内存延迟,即不同采样点密度会影响GPU的性能。因而在负载均衡过程中不仅需考虑CPU与GPU自身的计算能力差异,还应考虑CPU与GPU对不同数据空间分布特征的适应性差异。在算法中,将插值区域划分为若干个网格,统计每一个网格里面的采样点个数,包含较多采样点的网格中的未知点预测交给CPU处理,反之,交给GPU处理(如图2所示,灰色表示密度较大,白色较小)。
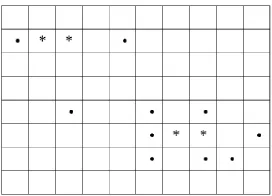
图1 邻近点查找与采样点分布的关系Fig.1 Relation between searching nearest neighbor and the distribution of samples
CPU与GPU之间任务的分配比例通常依据设备浮点计算能力,然而,考虑到Kriging插值的复杂性及数据传输的影响,浮点计算能力不能体现出CPU与GPU在计算Kriging插值时的性能差异,因此,依据CPU与GPU单独计算Kriging插值时的时间初步估计GPU任务分配比例:
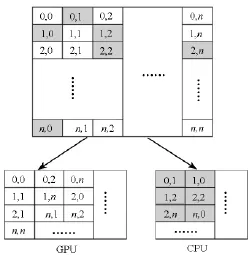
图2 CPU与GPU负载分配Fig.2 Load allocation between CPU and GPU
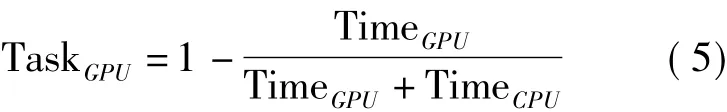
然后根据结果向GPU适当倾斜任务量。上述任务分配估计方法体现了CPU和GPU对本算法的性能差异,因此仅需CPU或GPU单独运行一次就可以估算出结果,在之后的计算中即便针对不同的数据集也不需要再重新估算任务分配比例。由于CPU端的串行执行并不能完全利用CPU的计算能力,因此式(5)中TimeCPU指的是OpenMP并行方式下的执行时间。
在LBCPDD算法的实现中,CPU端以OpenMP方式并行。为了对提出的GPU算法的性能进行比较,实现了同样采用局部插值的Shi和Ye描述的Kriging算法[8]。
3 试验与分析
采用的GPU为华硕R9 280,显示核心为AMD Tahiti XTL次世代图形核心(Graphics Core Next,GCN)架构,拥有3G GDDR5显存,流处理器数量为1792个;CPU为AMD FX-8150主频为3.6GHz,8核心,8线程;操作系统为Win7 64位。实验数据为从美国国家海洋和大气局(National Oceanic and Atmospheric Administration,NOAA)下载的全球降雨数据,为了保证鲁棒性,根据实验所需采样点数据集的大小,随机选择相应数量的点作为采样点。所有的实验中插值的输出网格大小均为1280×800个像素。
试验1:CPU性能。为了测试算法在不同数据量下的表现,选取了5组数据集进行测试,数据量每次增加1000个采样点;OpenMP分别选择2核、4核和8核进行测试(在表1中表示为OMP2,OMP4和OMP8)。算法执行时间见表1:随着核数的增加,运行时间持续减少;随着数据量增加,不同算法的执行时间都有所增加。图3给出了OpenMP在不同线程(核心)下的加速比,从图3可以看出随着线程数的增加,OpenMP的加速比也随之增加,最高达到了3.9倍左右;不同线程的OpenMP方法加速比对数据集大小不敏感,只是数据量比较大时有些轻微波动。

表1 串行与OpenMP运行时间对比Tab.1 Time comparison of sequential code and OpenMP ms
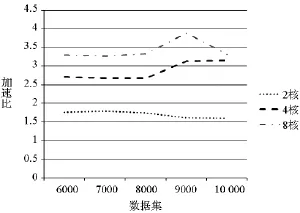
图3 OpenMP加速比比较Fig.3 Comparison of speed-up of OpenMP
试验2:GPU性能。表2给出了GPU并行的运行时间及加速比。GPU1并行程序依据Shi和Ye描述的方法实现[8],GPU2是改进后的GPU算法,增加了检查相邻未知点间是否具有相同的邻近点的步骤。从表2可以看出:GPU算法在不同的数据集下都表现出很好的加速效果,GPU2最高达到21.53倍;GPU2由于对Kriging插值过程中各未知点的邻近点进行了比较,对拥有相同邻近点的未知点,只计算其中的一个未知点的变异函数矩阵和逆矩阵,因此GPU2的加速比明显高于GPU1的加速比;同OpenMP算法类似,GPU算法的运行时间随数据集的大小增加而增加,但其加速比同数据集的大小无关,波动不大。
试验3:CPU-GPU性能。表3给出了通过LBCPDD进行负载均衡后的CPU-GPU协同执行时间。表中,OpenMP表示CPU端并行方式,采用8核并行,任务量占1/8;GPU2L表示GPU端使用表2中GPU2算法且通过LBCPDD方法负载均衡分配数据,任务量占7/8。由于GPU并行与OpenMP并行同时执行,因此算法的执行时间取决于较长的时间(负载分配时间小于3ms,未列入统计)。表3中性能提升指总时间相对GPU单独执行时间(表2中GPU2)的性能提升((GPU2-总时间)/GPU2)。从表3中可以看出,CPU-GPU的运算总时间比GPU单独运算时在不同的数据集下都有提高,最高达到了29.95%。CPU-GPU算法减少的时间一部分来自于CPU分担了部分计算,另外一部分来自于GPU由于处理数据的优化而节约的时间。
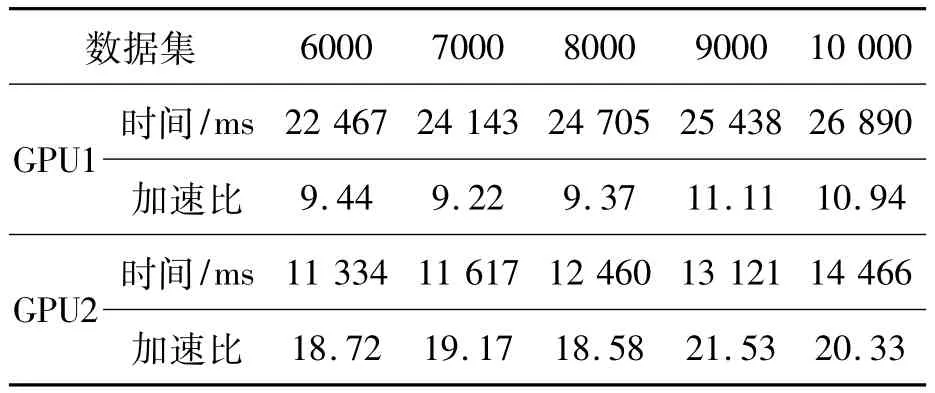
表2 GPU程序运行时间及加速比Tab.2 Time and speed-up of GPU program
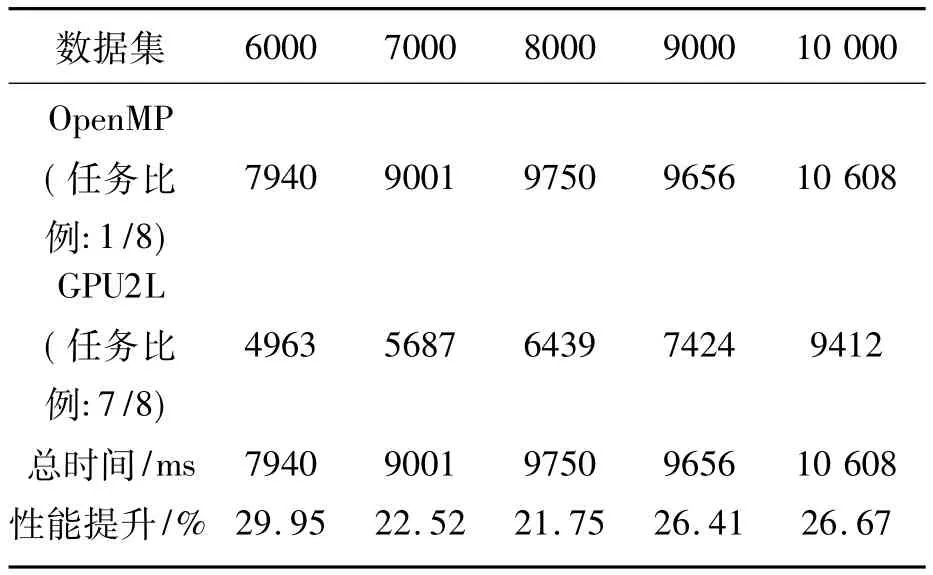
表3 引入LBCPDD后CPU-GPU协同运行时间Tab.3 Run time of CPU-GPU cooperation with LBCPDD
试验4:LBCPDD方法对性能的影响。表4给出了OpenMP及GPU并行在应用LBCPDD前后完成各自分配任务量的计算时间及性能变化。标准方法指在分配任务时根据插值点在二维平面上的坐标顺序将前7/8分配给GPU,剩余部分分配给CPU。表中GPU2S和GPU2L分别表示经过标准方法和LBCPDD方法进行任务分配后的GPU端执行,任务量为7/8;OpenMP1和OpenMP2分别表示经过标准方法和LBCPDD方法进行任务分配后的CPU端执行,任务量为1/8;GPU2L性能提升指GPU2L相对于GPU2S的性能提升((GPU2S-GPU2L)/GPU2S);OpenMP2性能提升指OpenMP2相对OpenMP1的性能提升((OpenMP1-OpenMP2)/OpenMP1)。从表4中可以看出,LBCPDD方法有效减少了GPU的计算时间,性能最多提高50.43%,而对OpenMP方法的性能影响相对较小。这主要是由于将适合GPU计算的数据分给了GPU,而将其余数据分给了对数据分布并不敏感的CPU。由于OpenMP运行时,各线程间以无序方式异步运行,这样做有利于OpenMP线程间动态负载均衡,但如果各线程间需要同步,则会极大地影响其速度,故OpenMP程序无法从减少冗余矩阵和数据重组中获得好处。
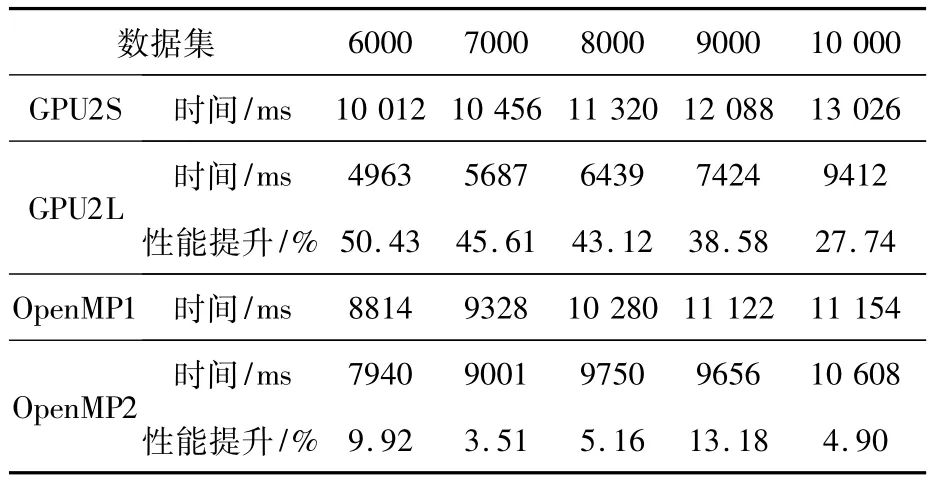
表4 LBCPDD对CPU和GPU的影响Tab.4 Impact of LBCPDD on GPU and CPU
在CPU与GPU协同计算中,对采样点的密度进行了分析,将采样点分布密度较低的区域分给了GPU。这样做有很多好处:更多的冗余矩阵分布在一个workgroup中,将有利于单个wavefront内的线程具有更少甚至没有分支。大量的冗余矩阵分布在一个workgroup内会使后续计算读取同一块内存区域,从而可以基于GPU内存存取机制(广播)减少延迟。CPU与GPU之间解决内存延迟使用两种不同策略,CPU用了大量的芯片空间构造片内缓存,主要通过多级缓存来减少内存访问的延迟;而GPU芯片大量空间被用来构造计算单元,通过大量线程的交叉访问来隐藏内存延迟,更多的冗余矩阵导致更少的内存消耗,从而可以让更多的线程调度到CU中执行,为线程的交叉访问提供条件。在冗余矩阵合并存储时,通过一个全局变量记录每个线程对应的矩阵编号,由于OpenCL不支持全局同步,因此,通过对全局变量的原子操作来完成编号的记录,原子操作具有排他性,会严重影响性能,冗余矩阵减少后,原子操作减少。一个workgroup内冗余矩阵增多,意味着线程计算时的内存消耗减少(大量线程空操作),这样会减少变量溢出到全局存储器中,全局存储器的存储周期约500个时钟周期,由于等待时间还可能翻倍,而寄存器存储周期只有1个时钟周期,马安国等[15]在通过预取对GPU程序进行优化时,性能影响最高达38%。基于以上原因,数据重分配后GPU计算的时间明显减少。从表4可以看到,随着采样点数据的增多,采样点的密度增加,导致冗余矩阵减少,这将导致性能改善降低,表4中数据重分配与按序分配时GPU性能改善随采样点数据增加而减少就验证了这一点。
4 结论
Kriging插值算法是一种广泛应用的算法。利用CPU与GPU协同计算对Kriging插值进行加速,基于CPU与GPU的计算性能差异和插值数据采样点的不均匀分布,对CPU与GPU进行负载均衡。测试结果表明,采用了LBCPDD后的CPU-GPU协同加速方法优于单纯依赖CPU的OpenMP加速方法、完全GPU的算法和未采用LBCPDD的CPU-GPU协同加速方法。LBCPDD法对其他数据分布敏感的CPU-GPU协同加速算法在进行负载均衡时也同样具有参考价值。
References)
[1]Krige D G.A statistical approach to some basic mine valuation problems on the witwatersrand[J].Journal of the Chemical Metallurgical&Mining Society of South Africa,1951,94(3):95-111.
[2]De Baar JH S,Dwight R P,Bijl H.Speeding up Kriging through fast estimation of the hyperparameters in the frequency-domain[J].Computers&Geosciences,2013,54:99-106.
[3]吴立新,杨宜舟,秦成志,等.面向新型硬件构架的新一代GIS基础并行算法研究[J].地理与地理信息科学,2013,29(4):1-8.WU Lixin,YANG Yizhou,QIN Chengzhi,et al.On basic geographic parallel algorithms of new generation GIS for new hardware architectures[J].Geography and Geo-Information Science,2013,29(4):1-8.(in Chinese)
[4]程果,陈荦,吴秋云,等.一种面向复杂地理空间栅格数据处理算法并行化的任务调度方法[J].国防科技大学学报,2012,34(6):61-65.CHENG Guo,CHEN Luo,WU Qiuyun,et al.A task schedulingmethod for parallelization of complicated geospatial raster data processing algorithms[J].Journal of National University of Defense Technology,2012,34(6):61-65.(in Chinese)
[5]Hu H D,Shu H.An improved coarse-grained parallel algorithm for computational acceleration of ordinary Kriging interpolation[J].Computers&Geosciences,2015,78: 44-52.
[6]Cheng T P,Li D D,Wang Q.On parallelizing universal Kriging interpolation based on OpenMP[C]//Proceedings of the9th International Symposium on Distributed Computing and Applications to Business,Engineering and Science,Hong Kong:IEEE,2010:36-39.
[7]Cheng T P.Accelerating universal Kriging interpolation algorithm using CUDA-enabled GPU[J].Computers&Geosciences,2013,54:178-183.[8]Shi X,Ye F.Kriging interpolation over heterogeneous computer architectures and systems[J].GIScience&Remote Sensing,2013,50(2):196-211.
[9]卢风顺,宋君强,银福康,等.CPU/GPU协同并行计算研
究综述[J].计算机科学,2011,38(3):5-9.
LU Fengshun,SONG Junqiang,YIN Fukang,et al.Survey of CPU/GPU synergetic parallel computing[J].Computer Science,2011,38(3):5-9.(in Chinese)
[10]方留杨,王密,李德仁,等.负载分配的CPU/GPU高分
辨率卫星影像调制传递补偿方法[J].测绘学报,2014,43(6):598-606.FANG Liuyang,WANG Mi,LIDeren,et al.A workloaddistribution based CPU/GPU MTF compensation approach for high resolution satellite images[J].Acta Geodaetica et Cartographica Sinica,2014,43(6):598-606.(in Chinese)[11]Wang S,Armstrong M P.A theoretical approach to the use of cyberinfrastructure in geographical analysis[J].International Journal of Geographical Information Science,2009,23(2): 169-193.
[12]Dong B,Li X,Wu QM,et al.A dynamic and adaptive load balancing strategy for parallel file system with large-scale I/O servers[J].Journal of Parallel and Distributed Computing,2012,72(10):1254-1268.
[13]夏飞,朱强华,金国庆.基于CPU-GPU混合计算平台的RNA二级结构预测算法并行化研究[J].国防科技大学学报,2013,35(6):138-146.XIA Fei,ZHU Qianghua,JIN Guoqing.Accelerating RNA secondary structure prediction applications based on CPUGPU hybrid platforms[J].Journal of National University of Defense Technology,2013,35(6):138-146.(in Chinese)
[14]赵斯思,周成虎.GPU加速的多边形叠加分析[J].地理科学进展,2013,32(1):114-120.ZHAO Sisi,ZHOU Chenghu.Accelerating polygon overlay analysis by GPU[J].Progress in Geography,2013,32(1): 114-120.(in Chinese)
[15]马安国,成玉,唐遇星,等.GPU异构系统中的存储层次和负载均衡策略研究[J].国防科技大学学报,2009,31(5):38-43.MA Anguo,CHENG Yu,TANG Yuxing,et al.Research on memory hierarchy and load balance strategy in heterogeneous system based on GPU[J].Journal of National University of Defense Technology,2009,31(5):38-43.(in Chinese)
A load balancing method in accelerating K riging algorithm on CPU-GPU heterogeneous p latforms
JIANG Chunlei1,2,ZHANG Shuqing1
(1.Northeast Institute of Geography and Agroecology,Chinese Academy of Sciences,Changchun 130102,China;2.University of Chinese Academy of Sciences,Beijing100049,China)
Kriging interpolation algorithm is of great practical significance and is widely applied to various fields of geoscience.However,Kriging interpolation would inevitably encounter the performance bottleneck when the output grid or input samples increase.Implemented with OpenCL and OpenMP,the ordinary Kriging interpolation was accelerated on heterogeneous platforms:GPU and CPU.By considering the performance difference of CPU and GPU on the densities of samples,a new load balancing method of LBCPDD(Load Balancing based on Computation Performance and Data Distribution)was proposed,in which not only hardware performance but also data distribution characteristics were taken into account.Experiment results show that LBCPDDmethod can effectively enhance the speed of ordinary Kriging,savememory space and improve the efficiency ofmemory access.
general purpose graphics processor units;open computing language;Kriging interpolation;load balancing
F209
A
1001-2486(2015)05-035-05
10.11887/j.cn.201505006
http://journal.nudt.edu.cn
2015-06-24
国家自然科学基金资助项目(41271196);中国科学院重点部署资助项目(KZZD-EW-07-02)
姜春雷(1981—),男,吉林德惠人,博士研究生,E-mail:jiangchunlei@iga.ac.cn;张树清(通信作者),男,研究员,博士,博士生导师,E-mail:zhangshuqing@iga.ac.cn
