基于目标逼近特征和双向联想贮存器的情感语音基频转换
2015-06-05凌震华戴礼荣
凌震华,高 丽,戴礼荣
(中国科学技术大学信息科学技术学院,合肥 230027)
基于目标逼近特征和双向联想贮存器的情感语音基频转换
凌震华,高 丽,戴礼荣
(中国科学技术大学信息科学技术学院,合肥 230027)
提出了一种用于情感语音合成的基频转换方法.该方法使用定量目标逼近(qTA)特征作为语音音节层的基频描述,并用高斯双向联想贮存器(GBAM)实现中性合成语音音节层qTA参数向目标情感语音音节层qTA参数的转换.在模型训练阶段,首先基于中性语料库和统计参数语音合成方法构建中性语音合成系统;然后利用少量情感录音数据,将从情感语音文本对应的中性合成语音中提取的qTA参数作为源数据,将情感录音中提取的qTA参数作为目标数据,进行GBAM转换模型的训练.在情感语音合成阶段,利用训练得到的GABM模型,实现中性合成语音基频特征向目标情感的转换.实验结果表明,该方法在目标情感数据较少的情况下可以取得比最大似然线性回归(MLLR)模型自适应方法更好的情感表现力.
情感语音合成;定量目标逼近;高斯双向联想贮存器;基频转换
语音是人类沟通交流的重要方式之一.语音信号除了携带语言学信息外,还包含说话风格、情绪变化、情感表达等超语言学信息.因此,合成能够体现这些超语言学信息的高表现力语音,使得合成语音能够模拟自然人来表达丰富情感,也成为语音合成技术发展的一个重要方向.近年来随着互联网技术和人工智能的发展,情感等高表现力的语音合成在人机交互、休闲娱乐等方面的应用日益广泛,对情感语音合成的研究也有许多新的尝试.
目前,基于隐马尔科夫模型(hidden Markovmodel,HMM)的统计参数语音合成方法(HTS)已经可以合成出具有高可懂度的高品质语音,因此对于情感语音合成来说,最直接的方法是利用录制的情感语料库,基于HTS方法训练目标情感的声学模型[1].但是这种方法存在数据依赖性,即每构建一种目标情感的合成系统,便需要录制较大规模的相应情感的语音数据.情感语料库相对中性语料库在脚本设计、发音人选择、录音控制等方面都存在更大难度,这也造成直接训练目标情感的声学模型较为困难. Masuko等[2]和Tamura等[3]提出了基于模型自适应的情感语音合成方法,该方法先基于中性语料库和HTS方法得到中性语音的声学模型,然后在少量情感语料的基础上,基于最大后验概率(maximum a posterior,MAP)准则或者最大似然线性回归(maximum likelihood linear regression,MLLR)对中性训练模型进行模型参数调整,然后得到体现目标情感的声学模型. 2004年,Junichi等[4]提出了基于情感类型控制的声学建模方法,该方法利用多回归隐马尔科夫模型,在少量情感数据基础上利用情感参数对情感的类型、强弱进行灵活控制.此外近年来基于转换的情感语音合成方法也受到研究关注[5-6].它是一种类似于语音转换的后处理方法,把中性语音作为源数据,情感语音作为目标数据,通过寻找两者之间的映射模型,完成从中性语音到情感语音的转换.因为基频是与情感表现最为相关的声学特征,因此现阶段基于转换的情感合成方法研究主要针对基频特征开展,而高斯混合模型(Gaussian mixture model,GMM)是最为常用的基频转换模型[5-6].
为了更好地体现基频的长时性,笔者首先利用目标逼近(target approximation,TA)模型[7]在音节层对基频进行参数化处理,获得其音节层的量化模型参数(qTA参数[8]),然后对qTA参数进行模型映射.高斯双向联想贮存器(Gaussian bidirectional associative memories,GBAM)是一种两层的随机反馈神经网络,对所观测向量的维间相关性具有很强的建模能力,已经被成功地用于基频后处理来提高HTS合成语音自然度[9]和语音转换[10]问题.本文将采用GBAM模型,实现中性合成语音音节层qTA参数向目标情感语音音节层qTA参数的映射.在模型训练阶段,基于中性语料库和HTS方法构建中性语音合成系统,利用少量的情感录音数据,将从情感语音文本对应的中性合成语音中提取的qTA参数作为源数据,将情感录音中提取的qTA参数作为目标数据,进行GBAM转换模型的训练;在情感语音合成阶段,利用中性语音合成系统预测输入文本对应的基频轨迹,从中提取qTA特征并进行基于GBAM模型的特征转换,再利用转换后的qTA特征恢复出基频轨迹用于情感语音合成.
1 音节层基频参数提取
1.1 基频模型
qTA参数的提取依据目标逼近(TA)模型和定量目标逼近(quantitative target approximation,qTA)模型.目标逼近(TA)模型(见图1)模拟基频产生的内在物理机制,假设基频曲线的运动与音节同步,并且在每个音节的结尾处,基频曲线会逐渐逼近潜在的音高目标.图1中点线表示基频曲线,长划线表示音高目标,竖实线表示音节边界.TA模型假设有静态和动态两种音高目标,针对中文等代表性的声调(阴平、阳平、上声和去声)语言,TA模型存在很大的优势:其动态音高目标对应阳平和去声两种声调,其静态音高目标则对应阴平和上声两种声调.上述特性使得TA模型被成功地应用于从中性语音到情感语音的韵律转换[6].

图1 目标逼近(TA)模型图例Fig.1 Illustration of TA model
定量目标逼近模型(qTA)是TA模型一种具体的物理和数学上的实现模型.它用一个三界临界阻尼线性系统来模拟基频的运动过程,具体形式为
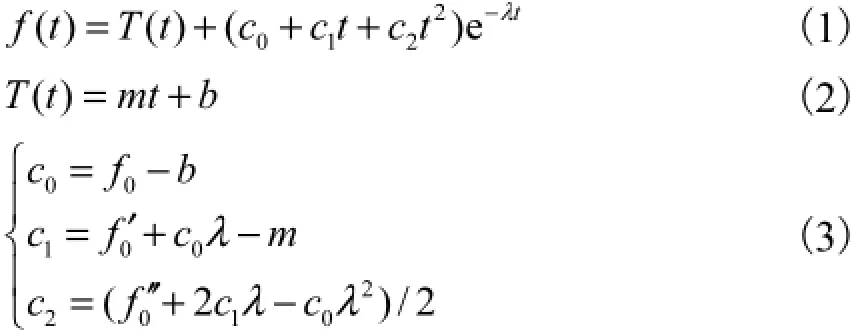
式中:()f t表示完整的基频曲线;()T t表示潜在的音高目标;剩余部分则表示瞬态响应.在()T t中,m和b分别表示音高目标的斜率和高度.瞬态响应多项式中,λ表示基频曲线逼近音高目标的速度,3个瞬态系数可由式(3)计算获得,其中0f、0f′和0f′′表示基频曲线每个音节的起始点状态,0f为起始点基频值,0f′为起始点基频的一阶动态,0f′′为起始点基频的二阶动态.原始的qTA模型假设基频曲线连续,因此除每句话的首音节外,0f、0f′和0f′′均可从上一个音节继承获得.在具体实现中,采用清音段线性插值的方法来获得连续的基频曲线.
在研究中笔者发现:对于中文的连续语流,音节之间基频的协同发音现象非常严重,因此采用在清音段用线性内插来形成连续的基频曲线并不可靠.文中取消了qTA模型的基频连续性假设,并对原始的qTA模型进行了简化.笔者把每个音节的浊音段作为qTA模型的基本单元,对于非连续浊音单元来说,每个浊音段的起始0f′和0f′′被设为零,而对于浊浊拼接的连续浊音单元,浊音段起始的0f、0f′和0f′′仍然从前一个音节的结束状态继承,3个瞬态系数的计算式依然为式(3).因此在改进的qTA模型中,为了重构基频曲线,需要m、b、λ和0f 4个参数,称这4个参数为qTA参数.此外,为去除时长对提取qTA参数的影响,用长度规整的F0向量来提取qTA参数.
1.2 音节层基频参数提取流程
qTA参数的提取流程如图2所示.首先要基于音节边界对F0曲线进行浊音段的检测,然后把每个音节的浊音段规整到相同的点数M,最后再对规整后的基频提取qTA参数.

图2 qTA参数提取流程Fig.2 Framework of extracting qTA parameters
2 基于GBAM的基频转换
2.1 高斯双向联想贮存器
BAM是一种双层的随机反馈神经网络,已经被成功地用于模式识别和语音转换领域.一个BAM网络存在两种模式,分别被称作源特征和目标特征.BAM网络一旦被激活,便会快速到达稳定状态,此时两种模式处于混响状态.该状态下两种模式之间的相互关系可以用权重矩阵W表示,并且此时的系统能量达到局部最小值.当BAM的神经元是零均值的高斯随机变量时,该模型被叫作高斯BAM(GBAM)[10],其能量函数记作



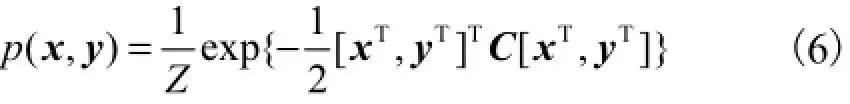
式中C为精度矩阵,表示为

2.2 基于GBAM模型的情感语音基频转换
GBAM已经被成功地用于基频后处理来提高传统HTS系统合成语音的自然度问题[9].在文献[9]中,经过GBAM后处理的基频在动态范围上明显增大,而对于高亢的情感语音来说,其基频的动态范围相对于中性语音来说要大很多[11].因此如果想要合成高兴、生气等高亢的情感语音,可以考虑利用GBAM对合成的中性语音进行基频转换来完成.
基于GBAM的从中性到情感语音的基频转换流程如图3所示.在训练端,首先要构建一个传统的基于HMM的统计参数语音合成系统,并且把中性语音作为语料库,得到合成的中性语音;然后把合成的中性语音所提取的qTA参数作为GBAM网络的源特征,把自然的情感语音基频所提取的qTA参数作为目标特征,进行GBAM训练.GBAM的训练可以看作是最优化权重矩阵W的过程,这里采用CD算法,基于最大似然准则进行GBAM训练[10].
在转换端,已知最优的权重矩阵optW后,可以得到在给定源特征x,即合成中性语音的qTA参数条件下,目标特征y的条件分布,记作
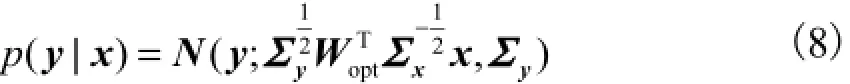
然后通过最大化条件分布()p y|x,即可得到转换的目标特征y,也即目标情感的qTA参数.
需要强调的是在qTA模型中,λ并不完全等价于F0的速度,因为如果m和b不相同,即使相同的λ也会导致不同的基频运动速度[8].笔者初步的实验结果也表明同时转换m、b、0f和λ,其结果没有仅转换m、b和0f的效果好,并且对λ的不恰当转换也可能造成不合理的基频运动速度,所以在最后的实现中,笔者仅转换了m、b和0f 3个参数.
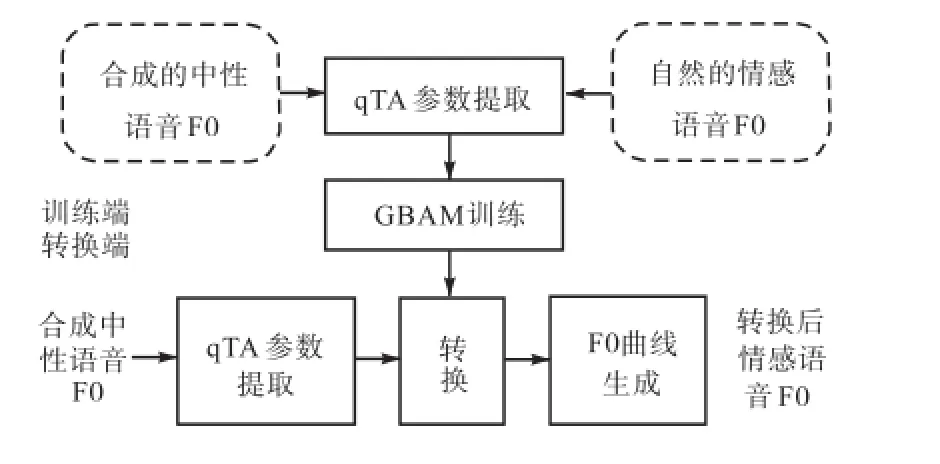
图3 基于GBAM的从中性语音到情感语音的基频转换Fig.3 Framework of GBAM based F0 transformation from neutral speech to emotional speech
3 实 验
3.1 实验配置
笔者以840句中性语音的中文女声数据库作为训练数据,然后基于HMM的参数语音合成系统得到中性的合成语音,并把其作为GBAM转换的源数据.情感数据分别是210句的高兴情感语料库和210句的生气情感语料库.对于每种情感来说,随机选择100句作为MLLR的自适应数据,剩余的110句作为HTS系统和MLLR系统的测试集,然后再从这110中随机选择100句作为GBAM转换的训练集,剩余10句则作为GBAM转换的测试集.
对于HTS系统,HMM选用的是5状态从左到右无跳转的拓扑结构.声学参数是lg F0和41阶的LSP参数以及它们的一阶二阶动态参数.在训练端,声学模型的训练基于最小描述长度准则(MDL),且谱参数和基频参数基于多空间概率模型同时建模.在生成端,通过最大化静态和动态声学特性的输出概率来预测最优的声学参数.
对于qTA参数的提取,每个音节的浊音段基频规整为30个点,qTA参数提取基于开源工具PENTAtrainer1(http://www.phon.ucl.ac.uk/home/yi/ PENTAtrainer1),并结合第1.1节做了相应修改.
3.2 实验和结果分析
本文把基于中性语料库的HTS系统作为基线系统,系统名称记为Baseline;把基于MLLR[3]的自适应方法作为对比系统,系统名称记为MLLR;使用本文提出的基于目标逼近特征和GBAM模型的情感语音基频转换方法的系统名称记为GBAM.在实验中为了重点关注基频预测性能的差异,GBAM系统使用了与MLLR系统相同的时长和频谱特征的预测结果.
在本文的对比实验中,首先对Baseline、MLLR和GBAM 3个系统的自然度和情感表现力分别进行了MOS分的打分,其中关于情感表现力的MOS分打分规则如表1所示.一共8个以中文为母语的说话人参与了测听,并且在测听之前他们均被告知了每组测听句子的目标情感类别.

表1 情感表现力MOS分打分规则Tab.1Scoring principle for MOS score of emotional expressivity
两种情感自然度和情感表现力的MOS分测听结果分别如表2和表3所示,其中p值由显著性检验(t-test)计算得到.

表2 自然度的MOS分Tab.2 MOS score of naturalness

表3 情感表现力的MOS分Tab.3 MOS score of emotional expressivity
由表2和表3可以看出,相比于Baseline,虽然MLLR和GBAM两个系统在合成语音的自然度上有一定程度的下降,但是从情感表现力方面来说,MLLR和GBAM两个系统均获得了更高的表现力得分,且GBAM的情感表现力得分最高.并且对于高兴和生气两种情感来说,MLLR与GBAM系统MOS分的p值均远小于0.05,因此两个系统的差距显著,GBAM系统更优于MLLR系统.
为了直观地对比GBAM和MLLR两个系统,还进行了GBAM和MLLR两个系统情感表现力的倾向性测听实验,其结果如表4所示.从倾向性测听的结果可以看出,GBAM系统的倾向性得分远高于MLLR系统,因此GBAM系统在合成情感表现力语音方面的性能更优,该结果与MOS分的结果一致(http://home.ustc.edu.cn/~gaoliz8/NCMMSC20151).
图4是中文语句“我多么希望能在这里劳动”的基频曲线样例.由图4可以看出,相对于Baseline和MLLR系统,GBAM系统的基频动态范围更大,且更接近于自然情感录音的基频.
4 结 语
本文提出了一种基于GBAM和音节层基频目标逼近特征的从中立语音到情感语音的基频转换方法.首先构建一个传统的基于HMM的统计参数语音合成系统,利用中性语料库得到中性的合成语音,并将其音节层基频特征作为GBAM的输入源特征.GBAM的目标特征则是自然的情感语音的音节层基频特征.本文中,GBAM通过描述中性合成语音的音节层基频特征和情感自然录音的音节层基频特征之间的联合分布,来建立两者之间的映射模型.对于音节层的基频特征,本文采用的是基于基频产生的物理机制的定量目标逼近模型参数qTA.主观的实验结果表明,本文提出的基于GBAM的基频转换方法可以有效地完成从中性语音到情感语音的基频转换,并且与MLLR的自适应方法相比,该方法可以获得更高的情感表现力MOS分和倾向性得分,因此性能更优.
[1] Yamagishi J,Onishi K,Masuko T,et al. Acoustic modeling of speaking styles and emotional expressions in HMM-based speech synthesis[J]. IEICE Transactions on Information and Systems,2005,88(3):502-509.
[2] Masuko T,Tokuda K,Kobayashi T,et al. Voice characteristics conver sion for HMM-based speech synthesis system[C]//Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing. 1997:1611-1614.
[3] Tamura M,Masuko T,Tokuda K,et al. Adaptation of pitch and spectrum for HMM-based speech synthesis using MLLR[C]// Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing. 2001:805-808.
[4] Junichi Y,Tachibana M,Masuko T,et al. Speaking style adaptation using context clustering decision tree for HMM-based speech synthesis[C]// Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing. 2004:5-8.
[5] Veaux C,Rodet X. Intonation conversion from neutral to expressive speech[C]//INTERSPEECH. Florence,Italy,2011:2765-2768.
[6] Tao J,Kang Y,Li A. Prosody conversion from neutral speech to emtional speech[J]. IEEE Transactions on Audio,Speech,and Language Processing,2006,14(4):1145-1154.
[7] Xu Y,Wang E Q. Pitch targets and their realization:Evidence from Mandarin Chinese[J]. Speech Communication,2001,33:319-337.
[8] Prom-On S,Xu Y,Thipakorn B. Modeling tone and intonation in Mandarin and English as a process of target approximation[J]. The Journal of the Acoustical Society of America,2009,125(1):405-424.
[9] Gao L,Ling Z H,Chen L H,et al. Improving F0 prediction using bidirectional associative memories and syllable-level F0 features for HMM-based Mandarin speech synthesis[C]//ISCSLP. Singapore,2014:275-279.
[10] Liu L J,Chen L H,Ling Z H,et al. Using bidirectional associative memories for joint spectral envelope modeling in voice conversion[C]// IEEE International Conference on Acoustics,Speech,and Signal Processing. Florence,Italy,2014:7884-7888.
[11] Pereira C,Watson C I. Some acoustic characteristics of emotion [C]//ICSLP. Sydney,Australia,1998:1-3.
(责任编辑:孙立华)
F0 Transformation for Emotional Speech Synthesis Using Target Approximation Features and Bidirectional Associative Memories
Ling Zhenhua,Gao Li,Dai Lirong
(School of Information Science and Technology,University of Science and Technology of China,Hefei 230027,China)
In this paper,an F0 transformation method for emotional speech synthesis was proposed.Quantitative target approximation(qTA)features were used to represent F0 contour in syllable level.And Gaussian directional associative memories(GBAM)was used to complete the transformation of syllable-level qTA parameters from synthesized neutral speech to target emotional recordings.In the training stage,firstly HMM-based statistical parametric speech synthesis was used to construct a neutral speech synthesis system with neutral corpus as training set.And then,with a small amount of emotional recording data,GBAM-based transformation model was trained by using the qTA parameters extracted from synthesized neutral speech corresponding to the emotional text as the source feature and the qTA parameters extracted from target emotional recordings as the target patterns of GBAM,respectively.In the generation of emotional speech,the trained GBAM model was utilized to complete the transformation of syllablelevel F0 features from synthesized neutral speech to target emotional recordings.The experiment results indicate that,in the case of little emotional recording data,the proposed method performs better in emotional expressivity than the adaptation method using maximum likelihood linear regression(MLLR).
emotional speech synthesis;qTA;GBAM;F0 transformation
TN912.33
A
0493-2137(2015)08-0670-05
10.11784/tdxbz201507028
2015-03-15;
2015-07-09.
国家自然科学基金资助项目(61273032).
凌震华(1979— ),男,副教授,zhling @ustc.edu.cn.
高 丽,gaoli128@mail.ustc.edu.cn.
时间:2015-07-13.
http://www.cnki.net/kcms/detail/12.1127.N.20150713.0857.001.html.
