基于不确定性描述的云化Markov链状态预测方法
2015-06-01倪世宏
查 翔,倪世宏,谢 川,张 鹏
(空军工程大学航空航天工程学院,陕西西安710038)
基于不确定性描述的云化Markov链状态预测方法
查 翔,倪世宏,谢 川,张 鹏
(空军工程大学航空航天工程学院,陕西西安710038)
针对Markov链在预测概率发生跳变时无法有效地衡量样本归属程度的问题,提出一种云化Markov链的状态预测方法,通过云模型描述和处理样本的不确定性。该方法将划分的状态区间视作一种概念,利用云模型对其进行云化表示,据此计算样本对各概念的确定度,得到概念之间的概率转移矩阵,从而实现带有随机特性的状态预测。概念转移概率作为关键随机变量,对其进行了核密度估计。最后以多次随机实验的概率和提取代表性转移概率分别给出了仿真实验结果,表明该不确定性描述的预测方法在解决Markov链预测概率跳变现象的同时,可通过确定度的分配有效地表述样本的归属程度,具有较好的实用性。
不确定性;Markov链;云模型;预测
0 引 言
时间序列的衍变过程蕴含着多种不确定性,通常运用随机过程来模拟、分析和处理这一类问题。针对随时间变化的动态变量预测,基于Markov链模型的状态预测是一个较好的选择[1]。与点预测[23]不同,Markov链模型实现的是定性预测,通过将样本划分多个状态区间,对每个区间赋予带有自然含义的概念,预测结果属于状态区间的范畴,从而可将该模型得到的结果归结为一种定性结论。
然而,这种定性预测方法在定量数据发生微小波动时可能会引起预测状态概率的跳变,即由某一状态变换到另一状态时,概率变化幅度过大,状态转移的过程不稳定。一般而言,事物发展若是平稳的,相应的隶属状态的概率也应是渐进变化的。产生这种现象的本质原因在于状态区间的划分过于明确,属于一种确定性的分析方法。文献[4]根据输入样本的激活强度决定是否采取硬或软划分,从而建立不同情形的Markov链状态空间,但该方法对每种情形下的Markov状态空间单独进行讨论,未实现真正意义上的软化。文献[5]提出了一种加权Markov模型,将明确状态下的划分矩阵拓展为模糊划分矩阵,但需事先确定样本对模糊状态的隶属度分配(即确定隶属度函数的形式)。文献[6]通过引入Dempster-Shafer(DS)证据理论建立了一种信度Markov模型,由基本概率指派函数(basic probability assignment,BPA)所指定的基概率数可类比模糊隶属度,但仍属于一次精确性的方法;它需根据应用背景设计相应的BPA,虽然存在较大的灵活性,但未提及可参考设计的理论和方法,实现起来较为困难。
以上方法在解决预测概率的跳变现象时,均需要通过为已知样本指定精确的隶属度来衡量和表述样本的归属程度,但这一方式缺乏可参考的依据,预测结果的不可预知性成为难以回避的问题。为此,本文考虑引入不确定性人工智能中的云理论,提出一种基于不确定性描述的云化Markov链状态预测方法,以云理论中的确定度类比隶属度,利用区间云化以及概念确定度的分配描述和处理对象的不确定性,并使这种不确定性能贯穿方法的始终。该方法既能弥补Markov链的预测概率发生跳变这一缺陷,又避免了隶属度函数或BPA的设计问题,并且可获得随机描述的预测概率。它在继承模糊理论和信度Markov链优点的同时,将不确定性融入Markov链中进行研究,取得了较理想的实验结果。
1 基于Markov链理论的状态预测
Markov链是一类特殊的时间和状态均离散的随机过程,主要特征在于它的无后效性(即马氏性)[79]。确切地说,已知随机过程在“当前”时刻所处状态的前提下,可以确定其“未来”时刻的状态概率分布,而这一概率分布与“历史”状态无关。Markov链的严格定义由条件概率分布函数给出。
定义1 对于一离散随机过程{Z(t)}以及离散时间集T={0,1,2,…},t∈T,设{Z(t)}定义在概率空间(Ω,Γ,P)上且具有可数状态空间E,满足∀t∈N+以及i1,i2,…,in∈E,有

则称满足式(1)条件分布函数的离散随机过程为Markov链,这一性质也被称作马氏性。Markov链简化的表达形式为
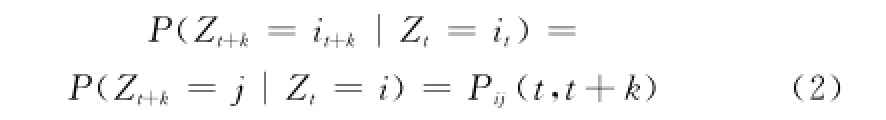
在式(2)中,Pij(t,t+k)表示随机过程在t时刻处于状态i的条件下,在t+k时刻转移至状态j的概率。若k=1,则构造一步状态转移矩阵P=(pij)m×m,其中,m为划分的状态数,pij由状态转移频数矩阵确定,满足1,2,…,k)。当k>1时,可类似构造多步状态转移矩阵P,通过Chapman-Kolmogorov方程计算得到。本文主要利用一步状态转移矩阵建立Markov链预测模型。
应用Markov链分析和解决问题的首要前提是随机过程必须符合马尔可夫性,需要作马氏性检验,具体过程可参考文献[10]。另外,Markov链预测方法中一个关键问题是如何实现区间的划分,每个区间对应一个Markov状态,常用的划分方法有经验法、均值-方差法、平行曲线法以及聚类分析法等,需根据具体应用合理选取。
2 面向预测的不确定性云化Markov链预测方法
2.1 实现思路
不确定性建模方法主要从两个方面体现:一是模糊性,从概念的区分程度来反映;二是随机性,可体现在结果的表达形式上。现有的模糊集[45]、DS证据理论[6]等建模方法仍然集中在精确的隶属度(或概率指派)上,不论样本属于一种或多种状态,其隶属程度在整个建模过程保持不变,这与模糊的思想是相悖的,为对象分配的隶属度应围绕某一中心值做微小波动,直接表现为具有稳定倾向的随机数;并且模糊性与随机性之间常具有很强的关联性,这一规律不能被简单忽略。文献[11]提出的云模型可有效地描述和处理概念的这种不确定性,能够表达兼有模糊性和随机性的定性概念,在群智能优化[12]、模式识别[13]以及综合评价[14]等领域应用广泛。
本文首先根据所获得的定量数据进行区间划分,将每个区间视为一种状态概念,把精确的数值合理转换成有限个定性语言值;通过融合云模型对区间进行描述并建立云划分,用以表达每个特定区间内数值本身的不确定性,并在此基础上求解概念之间的概率转移矩阵,进一步实现Markov链的状态预测。
2.2 基于云的区间概念描述
云是某个定性概念与其定量表示之间的一种不确定性转换模型,构成了定性与定量之间的相互映射,其定义如下[11]:
定义2 设U是用精确数值表示的定量论域,C为U上的一个定性概念,若U中的定量值x为定性概念C的一次随机实现,那么x对C的确定度y=μC(x)∈[0,1]是具有稳定倾向的随机数,则称在论域U上(x,y)的分布为云,(x,y)为其中的一个云滴。
云的数字特征反映了定性概念的整体定量特性,即期望Ex、熵En和超熵He,其中,Ex表示云滴在论域空间分布的期望值,代表了定性概念的重心位置;En是定性概念随机性以及亦此亦彼性的度量,En越大,可被概念接受的论域范围越大,概念也就更为模糊;He为熵不确定性的度量,即熵的熵,体现了论域值隶属于概念程度的凝聚性,其值间接反映在云的厚度上。根据这3个数字特征,语言集中各定性概念Ci的云模型可表示成Ci(Exi,Eni,Hei),实际中常使用正态云模型[1517],本文也用来表示对应的状态区间。
传统Markov链所涉及的可数个状态区间是确定的,即各区间边界是精确不变的值,它们所代表的概念比较明确和独立,但实际上人对概念区间的理解通常是较为模糊的,概念之间并没有明确的界限,相邻概念之间存在着过渡区域。例如将航空发动机的健康状态划分为5个:健康、亚健康、合格、异常以及故障,它们均是用定性语言表示的状态或区间概念,对处于相邻状态边缘的发动机不能确切指定所属哪一个状态,这也是符合实际的,以上状态的划分只是便于后续的评估。因此,本文考虑首先根据序列样本的取值范围进行状态区间的硬划分,对得到的每一区间用云模型进行概念描述,实现状态区间的软化与云化。与建立隶属度函数的模糊集方法的区别在于,区间云模型的描述只需3个参数,可根据每一区间内的样本分布规律灵活调整参数值;由于云模型本身的特点,采用正向正态云发生器[18-19]获得的定量值对某一概念的确定度(隶属度)具有随机性而非常数,从而使Markov链的预测结果带有不确定性。
假设已经对序列样本{X(t)}进行了区间划分,得到m个状态区间的集合S={Si},(i=1,2,…,m)。根据云化方法的思想,将S视为一概念集C,对其中的每个概念利用云模型来刻画,这样共得到m个概念云,它们共同组成连续语言值上的云标尺,这样就完成了由定量到定性的转换过程。云标尺用来计算每个样本相对于其上各云模型的确定度,其中各云的数字特征根据不同情形确定:
(1)若区间Si为双边有界(包括半开半闭、全闭以及全开区间情形),上、下确界分别为sup(Si)、inf(Si)。此时为Si建立正态云Ci=(Exi,Eni,Hei),Exi自然地用区间的中值表示,即Exi=[sup(Si)+inf(Si)]/2;根据正态云的“3En规则”[13],对定性概念Ti有贡献的云滴主要集中在区间[Exi-3Eni,Exi+3Eni]内,那么近似有
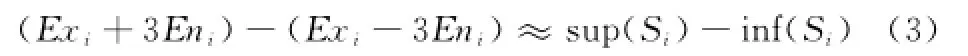
即Eni≈[sup(Si)-inf(Si)]/6,并以此作为Eni的计算式;Hei=ci,其中,ci为一常数,根据变量本身的模糊度和随机度经验调整。ci越大,云滴离散程度越大,概念越模糊,算法会失去稳定性;ci越小,一定程度上会失去随机性;当ci=0时,云将退化为基本的正态分布。
(2)若区间Si为单边有界,即上、下确界只存其一,这种情况下Si只可能位于云标尺的两端。此时为Si建立半梯形云Ci=(Exi1,Exi2,Eni,Hei),它属于一种综合云,与正态云相比多出一个期望参数。首先根据已有的序列样本或先验知识大致给出另一未知的确界值,作为Exi2,然后按照情形(1)中双边有界区间的参数计算方式,由两确界值分别计算Exi和Eni,则Exi1=Exi,Hei仍取经验常数ci。
2.3 云化Markov链预测方法的实现
云化方法将原划分区间理解为状态概念,要建立云Markov链预测模型,关键在于计算概念到概念之间的一步转移概率,继而得到一步概念转移概率矩阵,仍然用P进行表示。为得到P,首先需要计算序列样本相对于各概念云的确定度,用X条件云发生器[11]实现。对于不同的云类型,计算方法也有所区别。
2.3.1 多序列样本多概念的确定度计算
设序列样本x1,x2,…,xn∈{X(t)},云标尺上各概念正态云Cj对应的数字特征为(Exj,Enj,Hej),将序列样本xt看作Cj的一次随机实现(t=1,2,…,n;j=1,2,…,m),那么xt对Cj的确定度μj(xt)计算方法为:
(1)对概念Cj,生成一个正态随机数En′jt=norm(Enj,He2j),其中,norm(·,·)为正态随机数生成函数,以Enj为期望和Hej为标准差;
(2)将xt视为特定取值,得到其对概念Cj的确定度为

(3)对所有序列样本以及每一概念云,重复上述过程,共得到m·n个确定度变量。
若概念对应的云为半梯形云,是一种组合云,数字特征与正态云相比有所不同,此时需要增加对xt所处位置的判别,不同位置得到的确定度不同。假设半梯形云Cj为左半升的,其对应的数字特征(Exj1,Exj2,Enj,Hej),那么xt对概念Cj的确定度μj(xt)分以下两种情况计算:
(1)若xt≤Exj1,即xt位于Cj的上升部分,此时μj(xt)的计算方式同正态云;
(2)若Exj1<xt≤Exj2,即xt位于Cj的平稳部分。根据半梯形云的特点,这一部分是上升部分的延续,考虑到确定度的最大值为1,此时μj(xt)不具备随机性,μj(xt)≡1。
对于右半降的半梯形云Cj,其下降部分是平稳部分的延续,计算确定度的方法类似。
无论概念云为正态云或者半梯形云,根据计算步骤得到的所有确定度变量,共同构成序列样本与概念之间的确定度矩阵V≜(μj(xt))m×n。由于中间变量En′jt或y′是随机的,因此μj(xt)并不是固定值,V构成一个随机矩阵,这一现象体现了序列样本与概念之间的不确定性转换关系,这也是本文云化方法的一个特点。确定度矩阵V具的性质如下:
性质1 对固定的j和t,V中的元素μj(xt)并不为常数,服从某一特定分布;
前3条性质容易理解。对于任何一个定义在已有m个概念云范围内的序列样本,可同时属于其中一个或多个概念云,但所有概念云下的确定度之和应该等于1,这也符合人的认知。然而由性质4可知,确定度矩阵V并不符合这一条件。为此,以单个序列样本为对象,将该样本下所有可能的确定度进行归一化处理,即


进一步地可推知
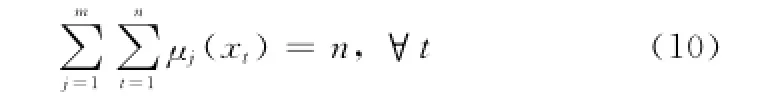
2.3.2 概念转移概率矩阵的求解
概念转移概率矩阵可视为云方法下Markov链概率转移矩阵的一种扩展,可依据更新后的确定度矩阵V对其求解。设概念转移概率矩阵P=(pij)m×m,其中,pij为云Markov链模型中由概念Ci转移到概念Cj的转移概率,类比状态转移概率的定义,有
式中,μi(xt)(或μj(xt))代表序列样本xt对概念Ci(或Cj)的确定度;n为样本长度;m为概念总数。pij的含义是:“所有序列样本由概念Ci转移到Cj的确定度之和”与“所有序列样本由概念Ci转移到所有概念的确定度之和”的比值,满足:pij≥0且
由式(11)可知,V中任意μi(xt)均是随机的,以致pij在每次计算时都会变化,pij仍然构成随机变量,有自己的统计性质。为简单起见,假设所有概念云为正态云,联立式(4)和式(11),得

式中,En′it,En″it~N(Eni,He2i),En′jt,En″jt~N(Enj,He2j)(t=1,2,…,n;j=1,2,…,m);对于每个xt,均存在不同的随机变量En′it、En″it、En′jt和En″it,这样分子和分母各包含2(n-1)个以及2m(n-1)个独立的随机变量,它们组成多维随机矢量Q。将式(12)中出现的各xt、xt+1、Exi、Exj均视为常量,那么复合随机变量pij为Q的函数,记为

若不同的xt对应着同一个概念Ci(或Ci),那么此时En′it(或En′jt)服从同一参数下的正态分布。
要深入考察某一随机变量的统计性质,常需要求解其概率密度函数,继而得到各项数字特征(如期望、方差或各阶距等)。以pij作为目标随机变量,若将En′it或En′jt的正态概率密度函数代入式(12)中,易知pij的计算式含有嵌套的指数函数,很难得到具有解析形式的概率密度函数。对于这种情况,可利用Parzen窗方法对pij进行非参数的核密度估计[20-21]。该方法不需事先假定分布函数的形式,而是直接根据已知的样本进行概率密度估计。核密度估计的函数^f(x)可表示为
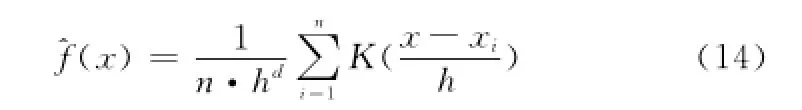
式中,n为样本长度;h为窗的宽度;d为样本维数;K(·)为核函数,本文采用Guass核函数另外,h的选择采用式(15)固定形式[22]。

式中,δ为样本的标准差。
2.3.3 目标概率分布向量的预测
在已知初始状态概率分布的情况下,对未来时刻系统归属各概念的概率分布作出预测,进而根据各概念的预测概率值大小作出决策分析。设t时刻样本xt对各概念的归一化确定度为μ′j(xt)(j=1,2,…,m),对应确定度矩阵V的第t列,将其转置得到初始概率分布矢量π(t)=(π1(t),π2(t),…,πm(t))。在求得概念转移概率矩阵P之后,根据Markov链一步预测思想,计算t+1时刻各概念的概率分布矢量π(t+1)为

对于π(t+1),依据最大概率原则取最大概率对应的概念作为最终的预测结果。由于矩阵P的随机性,π(t+1)相应地表现为随机矢量,这体现出预测结果的不确定性,可进行多次试验对结果进行统计分析。对于新获得的样本,可将其加入到原始样本序列中,按前述方法对概念转移概率矩阵实现更新。
3 仿真实验
这一部分的实验仍然基于文献[6]中澳大利亚Monash大学Hyndman教授公开的测试样本,以验证本文方法的效果。
3.1 区间概念的描述及可视化
测试样本共包含20期的库存需求情况统计,并满足Markov性。为了能与信度Markov模型有更好的可比性,本文按照同一方式,将序列样本硬划分为3个连续的状态区间:[0,150),[150,200],(200,+∞],分别用概念L、M和H表示,易知前两个均为双边约束区间,而第3个为单边约束区间。按照第2.1节云化区间概念的方法,设超熵He=2,则各概念云的参数为C1(75,25,2),C2(175,8.33,2),C3(215,229,0.5,2)。通过正向云(正态云和半梯形云)发生器算法计算云滴的确定度,生成各概念云组成的可视化云标尺,如图1所示。

图1 各概念的云标尺
云标尺图实现了由定性概念到定量表示的过程,图1直观地给出了各区间上库存需求情况统计的确定度分布情况:越靠近区间中心的样本,归属于该区间概念的确定度越大(最大可为1),概念也就越清楚;越靠近区间交集部分的样本,不同交集区间的确定度相对较小,且差异不大,概念也就越模糊。另外,任意样本的确定度也是不确定的,并不是固定值,这恰能反映系统发展规律的动态性。因此,云化方法较好地体现出了建模的不确定性,能够反映序列样本的自身特点。
3.2 概念转移概率的统计规律分析
概念之间的转移概率属于云化Markov链方法中关键随机变量,但因其表达形式复杂,很难挖掘其变化规律。这里不妨以求解p12和p23为例进行说明,即由概念L转移到概念M、概念M转移到概念H的转移概率,其他转移概率的分析方法类似。由样本及概念描述,n=20,m=3,则Q的维数为152。根据pij的定义,每次仿真下均会得到152个随机确定度,它们仍然满足性质4,并由此计算pij的值。对核密度估计而言,样本越多,估计出的概率密度越接近真实情况,为此仿真500次,共得到500个pij的随机取值,然后按照第2.3.2节的方法,画出p12和p23的核密度估计曲线,如图2所示。
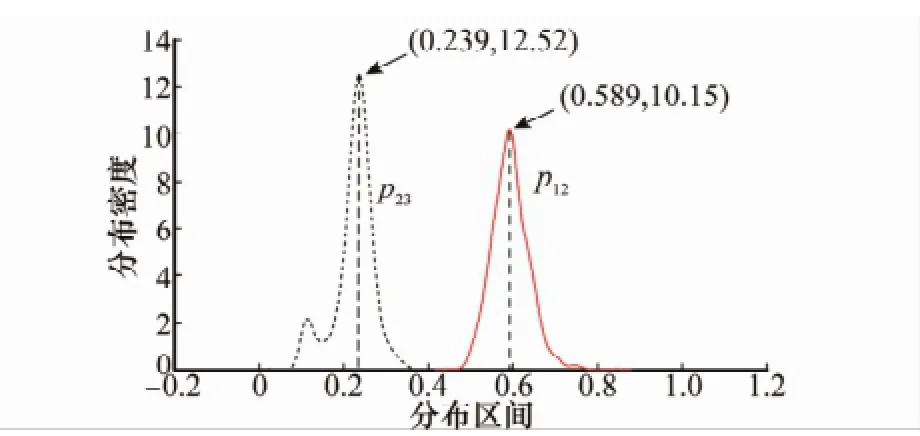
图2 不同概念转移概率的核密度估计曲线(He=2)
图2 说明了p12和p23的核密度估计曲线不同于正态分布的形式,而是呈现未知的特定分布,这与理论分析是一致的。由于各项确定度计算方法的差异,导致p12和p23的核密度估计曲线形式也有所区别,包括中心位置和对称性等方面。
3.3 数据变动对结果的影响
随机性为本文预测模型的特性之一,只进行一次实验无法对其充分描述;另外,为说明最后一期(即第20期)的不同数值对预测结果的影响,将最后一期的数值(记为d(20))由197逐渐增加到204,并在每一数值下重复20次仿真实验,预测第21期(记为d(21))的概率分布,如图3所示。
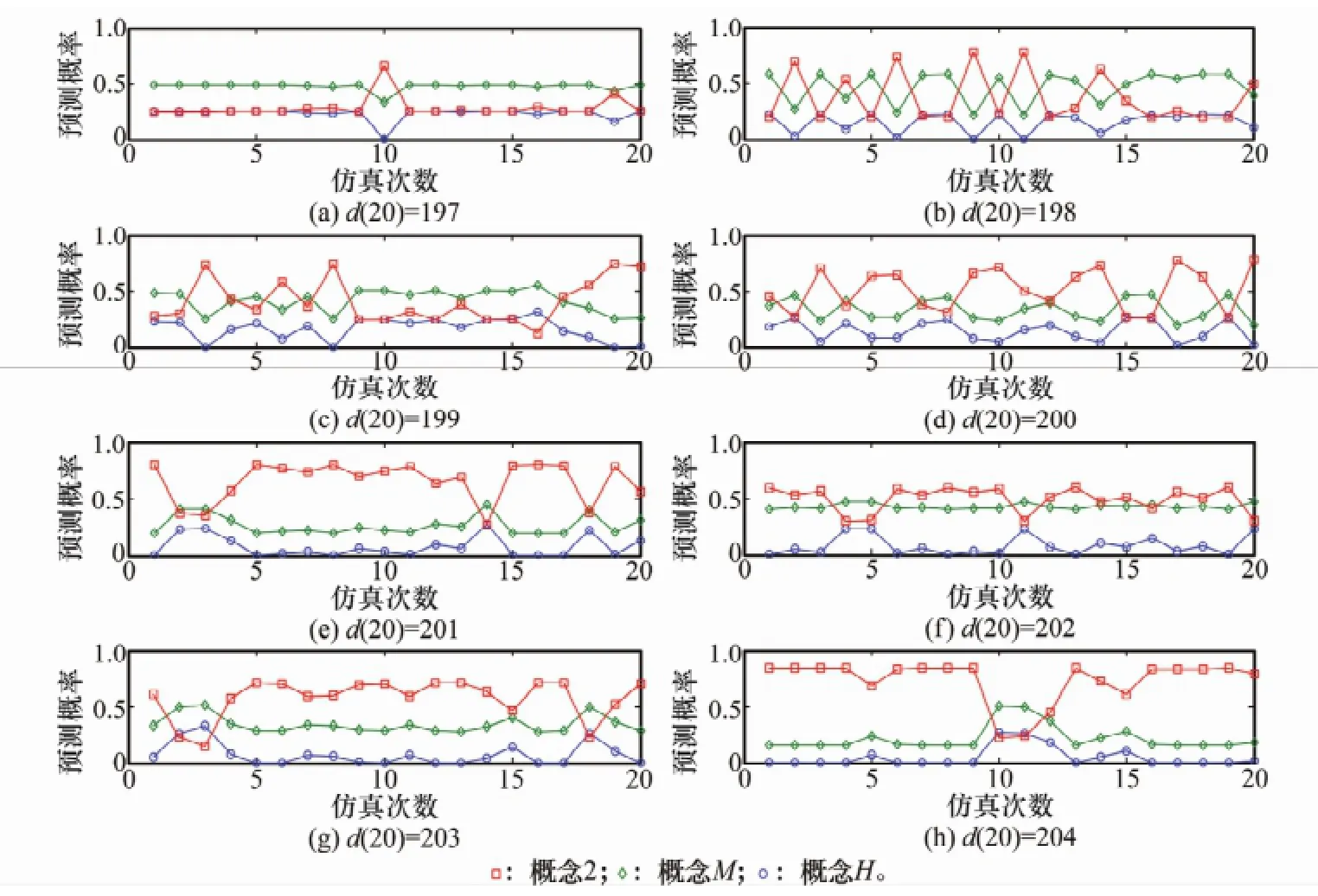
图3 不同d(20)对结果的影响(重复20次实验
在图3中,预测第21期时对应的概率分别记为πL(21)、πM(21)以及πH(21)。可以看出,任意一幅子图中,每次仿真下得到的结果是随机的;d(20)=197时,其距离状态边界相对较远,归属状态M的确定度与其他两个概念的确定度差异较大(可从云标尺中反映出),几乎总有πH(21)<πM(21),πL(21)<πM(21),随机性对确定度的影响不很明显。随着d(20)的增加,其逐渐逼近状态M和H的交界部分,对应着两个概念比较明显的混叠边界,此时πM(21)整体下降,而πH(21)呈整体上升趋势,两者之间的差异逐渐缩小。如d(20)=198以及d(20)=199时,从图3中已经很难判断归属状态M和H的概率差异,这是模型不确定性的原因所致。当d(20)进一步增加时,其逐渐远离状态M和H的交界部分,πH(21)继续保持增加的趋势,d(20)归属状态H的程度更为明显,如d(20)=204时,概念H占主导地位,除了由于随机性的原因少数情况出现πH(21)<πM(21)。另外,最后一期的数值偏离概念L较远,因此在数值变动范围内πL(21)始终保持较小值。
为了更直观地表明以上变化规律,将d(20)作为自变量,取值范围为[195,204],观察第21期概率分布的变化情况,如图4所示。对d(20)的每一取值,在确定概念转移概率pij时,取其核密度估计曲线峰值对应的横坐标值作为此概念转移概率代表性的点,如根据图2,可知p12=0.589,p23=0.239,以此进一步计算d(21)的预测概率。由于估计核密度曲线时所用样本有限,不同取值样本下得到的曲线存在稍许差异。
可以看到,当d(20)逐渐增加时,d(21)的各概念预测概率距呈现缓慢变化的趋势,未出现概率跳变现象,达到了与信度Markov模型同样的效果。根据极大概率判定的思想,当d(20)=200时,d(21)归属的概念发生变化,由概念M转变成概念H;而信度Markov模型则是在d(20)=197时出现这一变化,这是由各模型本身的特点决定的。然而,本文方法有其独特之处:模型的不确定性使得图4的结果不唯一,即使采用核密度曲线中具有代表性的概率点,每次仿真时预测概率曲线仍有些许变动;并且某一概念下的曲线走势可能非单调,如概念M先增后减,相比之下,信度Markov模型得到的各预测概率是确定的并且单调变化。
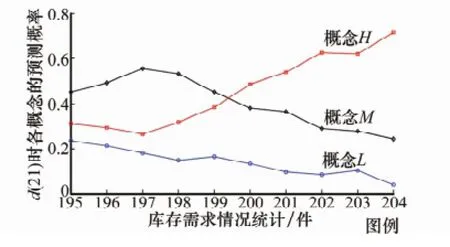
图4 基于代表性转移概率的d(21)预测概率曲线
3.4 不同超熵对结果的影响
若样本已知,按第3.1节描述云概念的方法,云模型的期望和熵可唯一确定,而超熵为可变参数,它对云化Markov链的影响直接反映在概念转移概率的计算上。超熵越大,pij的随机性越大,分布范围也就越广。为了说明这一问题,图5给出了He=5时的核密度估计曲线,并与图2进行对比。
根据图5,p12和p23具有代表性的密度点分别为0.586和0.215,与He=2时的取值(见图2)相差不大,基于代表性转移概率的d(21)预测概率曲线也不存在较大差异(He取其他值时情况类似)。虽然pij为未知解析形式的随机变量,但云模型的超熵对其大体位置不会产生明显影响,进而基于代表性转移概率的预测概率也不会有较大变动。由此可推断,本文方法具有较好的稳定性,对未知参数He不敏感。特别地,当He=0时,核密度估计曲线仅为平行于纵轴的直线,即pij为一固定量。

图5 不同概念转移概率的核密度估计曲线(He=5)
综上所述,基于不确定性描述的云化Markov链方法能够克服数据的微小波动带来的状态跳变现象,能够使各概念的预测概率保持渐进地稳定地变化规律;并且该方法实现过程简单,只需根据样本确定模型参数,不需指定模糊隶属度函数或复杂的基本概率指派函数;结果信息丰富,具有随机性特点;对不同的可变参数(超熵),根据基于代表性转移概率得出的预测结果稳定性保持较好,预测概率受超熵影响不明显。
4 结 论
在运用Markov链实现随机过程的预测时,未来时刻的预测概率可能会出现跳变,以分配隶属度为解决这一问题的手段,现有方法常缺乏有效依据,随意性较大。本文借助于云模型这一新的处理方法,将其引入Markov链预测模型中,提出了一种基于不确定性描述的云化Markov链预测方法,主要体现在对状态概念随机性和模糊性的处理上。它将Markov链状态空间采用云概念来表达,通过X条件云发生器获得样本对每一概念的随机确定度,作为样本归属某个概念的程度标量,以此为基础求解概念转移矩阵,进而实现Markov链的状态预测;样本确定度、概念转移概率以至未来时刻的预测概率,均为不同分布下的随机变量,较好地保持了模型不确定性的传递。对实验结果的分析表明,基于不确定性描述的云化Markov链预测能够解决数据微小波动带来的状态跳变问题,既不需要如模糊方法一样指定具体的隶属度函数,也可避免信度Markov模型设计BPA函数的问题,只需根据已有样本求解少量的云参数,方法简单且易于实现,可视为基本Markov链的一种扩展,具有较好的适应性。由于直接的实验结果表现为随机形态,本文仅简单考虑了核密度曲线峰值位置点的代表性概率,如何对其统计分析并有效利用需作进一步地探究。
[1]Farahat W A,Asada H H.Estimation of state transition proba-bilities in asynchronous vector Markov processes[J].Journal of Dynamic Systems,Measurement,and Control,2012,134(6):1- 14.
[2]Li H L,Guo C H.Piecewise cloud approximation for time series mining[J].Knowledge-Based Systems,2011,24(4):492- 500.
[3]Shang Z G,Yan H S.Forecasting product design time based on fuzzy support vector machine[J].Control and Decision,2012,27(4):531- 541.(商志根,严洪森.基于模糊支持向量机的产品设计时间预测[J].控制与决策,2012,27(4):531- 541.)
[4]Xie D W,Shi S L.Mine water inrush prediction based on cloud model theory and Markov model[J].Journal of Central South University,2012,43(6):2308- 2315.(谢道文,施式亮.基于云理论与加权Markov模型的矿井涌水量预测[J].中南大学学报,2012,43(6):2308- 2315.)
[5]Dang X C,Hao Z J,Wang X J.Forecasting of user behavior based on fuzzy weighted Markov chain[J].Journal of Lanzhou University,2011,47(1):110- 115.(党小超,郝占军,王筱娟.模糊加权Markov链的用户行为预测[J].兰州大学学报,2011,47(1):110- 115.)
[6]Deng X Y,Deng Y,Zhang Y J,et al.A belief Markov model and its application[J].Acta Automatica Sinica,2012,38(4):666- 672.(邓鑫洋,邓勇,章雅娟,等.一种信度马尔可夫模型及应用[J].自动化学报,2012,38(4):666- 672.)
[7]Singh S S,Chopin N,Whiteley N.Bayesian learning of noisy Markov decision processes[J].ACM Trans.on Modeling and Computer Simulation,2013,23(1):1- 25.
[8]Ghidini G,Das S K.Energy-efficient Markov chain-based duty cycling schemes for greener wireless sensor networks[J].ACM Journal on Energy Technologies in Computing Systems,2012,8(4):1- 32.
[9]Malikopoulos A A.Convergence properties of a computational learning model for unknown Markov chains[J].Journal of Dynamic Systems,Measurement,and Control,2009,131(4):1- 7.
[10]Alagoz O,Hsu H,Schaefer A J,et al.Markov decision processes:a tool for sequential decision making under uncertainty[J].Medical Decision Making,2010,30(4):474- 483.
[11]Li D Y,Du Y.Artificial intelligence with uncertainty[M].Beijing:National Defense Industry Press,2005:143- 145.(李德毅,杜鹢.不确定性人工智能[M].北京:国防工业出版社,2005:143- 145.)
[12]Wang W X,Wang X,Ge X L,et al.Muti-objective optimization model for muti-project scheduling on critical chain[J].Advances in Engineering Software,2014,68(12):33- 39.
[13]Jin B,Wang Y,Liu Z Y,et al.A trust model based on cloud model and Bayesian networks[J].Procedia Environment Sciences,2011,11(12):452- 459.
[14]Zhang L M,Wu X G,Ding L Y,et al.A novel model for risk assessment of adjacent buildings in tunneling environments[J].Building and Environment,2013,65(4):185- 194.
[15]Li H L,Guo C H,Qiu W R.Similarity measurement between normal cloud models[J].Acta Electronica Sinica,2011,39(11):2561- 2567.(李海林,郭崇慧,邱望仁.正态云模型相似度计算方法[J].电子学报,2011,39(11):2561- 2567.)
[16]Liu S,Chang X C.Synchro-control of twin-rudder with cloud model[J].International Journal of Automation and Computing,2012,9(1):98- 104.
[17]Li D Y,Liu C Y,Liu L Y.Study on the universality of the normal cloud model[J].Engineer Sciences,2005,3(2):18- 24.
[18]Qin K,Xu K,Liu F L,et al.Image segmentation based on histogram analysis utilizing the cloud model[J].Computers and Mathematics with Applications,2011,62(7):2824- 2833.
[19]Xu J Q,Bi Y M,Zhang X D,et al.Analysis of cost-capability for missile weapon based on cloudy model[J].Systems Engineering and Electronics,2012,34(1):91- 96.(徐加强,毕义明,张晓东,等.基于云模型的导弹武器费用 能力分析[J].系统工程与电子技术,2012,34(1):91- 96.)
[20]Kolomvatsos K,Hadjieftymiades S.On the use of particle swarm optimization and kernel density estimator in concurrent negotiations[J].Information Sciences,2014,262(10):99 -116.
[21]Malec P,Schienle M.Nonparametric kernel density estimation near the boundary[J].Computational Statistics and Data Analysis,2014,72(10):57- 76.
[22]Bolance C,Guillen M,Nielsen J P.Kernel density estimation of actuarial loss functions[J].Mathematics and Economics,2003,32(9):19- 36.
Cloud-transforming method of Markov chain state prediction based on uncertainty description
ZHA Xiang,NI Shi-hong,XIE Chuan,ZHANG Peng
(College of Aeronautics and Astronautics Engineering,Air Force Engineering University,Xi’an 710038,China)
To deal with ownership degree of samples in Markov chain effectively facing with a skip of the predicted probability,a cloud-transforming method of Markov chain state prediction is proposed.Samples’uncertainty is described and processed by using the cloud model.Regarded as a kind of concept,the partitioned state intervals are expressed based on the cloud model,and further the certainty of each objective to all concepts is computed.Then to realize stochastic state prediction,the concept transfer matrix is calculated.The kernel density estimation of concept transfer probability is obtained considering its significance.Finally simulation results are given in form of probability of repeated tests and extracted representative transfer probability,and it shows that the uncertain method can both avoid a skip of the Markov chain predicted probability and measure ownership degree of samples effectively,and is more practical as well.
uncertainty;Markov chain;cloud model;prediction
O 211.62
A
10.3969/j.issn.1001-506X.2015.04.34
查 翔(1988-),男,博士研究生,主要研究方向为飞机状态监控与故障诊断、人工智能及其应用。E-mail:zha_xiang@126.com
倪世宏(1963-),男,教授,博士研究生导师,主要研究方向为飞行数据智能处理。E-mail:470474069@qq.com
谢 川(1974-),男,副教授,博士,主要研究方向为飞行数据智能处理。E-mail:1830486912@qq.com
张 鹏(1982 ),男,讲师,博士,主要研究方向为飞机故障诊断、故障预测与健康管理。E-mail:zhangpeng25@gmail.com
1001-506X(2015)04-0942-07
2014- 07- 15;
2014- 10- 16;网络优先出版日期:2014- 11- 05。
网络优先出版地址:http://w ww.cnki.net/kcms/detail/11.2422.TN.20141105.1633.016.html
国家自然科学基金(61372167)资助课题
