一种基于空格编码的PDF文本数字水印算法
2015-05-31顾艳春冯君婷
顾艳春,冯君婷
(1.佛山科学技术学院电子与信息工程学院,广东佛山528000;2.佛山市第一人民医院计算机中心,广东佛山528000)
一种基于空格编码的PDF文本数字水印算法
顾艳春1,冯君婷2
(1.佛山科学技术学院电子与信息工程学院,广东佛山528000;2.佛山市第一人民医院计算机中心,广东佛山528000)
提出一种基于空格编码和置乱技术的适用于PDF文档的文本数字水印算法。首先,将水印图像进行置乱变换;其次,将原PDF文档转换成PS文件,PS文件中保存有字符和位置信息。利用空格不可见的特点,在PS文件中叠加若干由空格组成的行,并利用空格的位置信息来嵌入水印信息值及水印的位置信息值;最后,将PS文件转换为含有水印的PDF文档。实验结果表明,该算法具有较好的可视性和鲁棒性。
信息隐藏;空格编码;置乱技术;文本数字水印;PDF文档
作为多媒体产权保护和信息安全维护的一种有效手段,数字水印技术已经成为信息处理领域的一个研究热点[1-2]。当前,数字水印的研究主要集中在图像、音频、视频等方面,对以文本文档为载体的数字水印研究较少[3]。但是,文本数字水印同样具有很广阔的应用空间和重要价值[4]。由于文本文件的特殊性,在嵌入水印的方法上还存在一定的难度。目前,文本水印算法在基于文本格式、结构、语义、语法等方面的研究已取得了长足发展。Bender等[5]从信息隐藏的角度提出对文本中特定单词进行同义词替换的方法。Brassil等[6]提出了基于文本空间特征的水印嵌入算法。Zhao等[7]提出了基于像素统计特征的信息隐藏方案。文献[8-9]分别提出了基于文本特征编码的二值文本水印方案。但是,文本数字水印技术在理论上尚未成熟,已有的研究结果普遍存在水印难以深入到文本的内容中、水印嵌入容量不足、鲁棒性较差、破坏原文档内容等问题[10]。
PDF(Portable DocumentFormat)文档由于其独立于硬件及操作系统,可以方便地在不同计算机平台传播和共享,目前PDF文档已经发展成为网络信息传递中的主流文件格式。因此,研究基于PDF文档的数字水印技术,具有重要的应用价值[11]。
本文在分析以往算法的基础上,提出一种根据PDF文档格式,利用空格编码原理,将不会影响文档视觉变化的空格插入文档中,并利用其对应PS文件中的字符间距等信息,嵌入二值图像水印的算法。插入过程中,首先,对原水印图像进行置乱变换,提高嵌入水印的安全性和检测的准确率;其次,获取原文档对应的PS文件,找到各行中行位置信息和字符的间距信息,添加若干由空格字符组成的行,将置乱变换后的二值图像水印信息依据一定的规则嵌入到这些空格对应的间距信息中,同时,将水印的行值和列值信息嵌入到指定位置,作为检测水印的位置信息;最后,保存嵌入了水印信息的PS文件,并由此得到含有水印信息的PDF文档。
1 有关技术基础
1.1 PDF文本表示方法和基于PDF的水印算法模型
PDF文档的文字内容和页面格式可由相应的PS文件获得,PS文件是用PostScript语言编写的页面描述程序。PDF和PS之间可以相互转换。为了简化页面描述过程和实现文档的随机定位,PDF采用一种严格定义的文件结构,而PS能提供可读性较好的编程语言结构,所以利用PS文件更容易实现水印编、解码的操作,通过修改PS文件中页面输出格式来实现PDF文档水印的嵌入。基于此思想的数字水印模型[12]如图1所示。
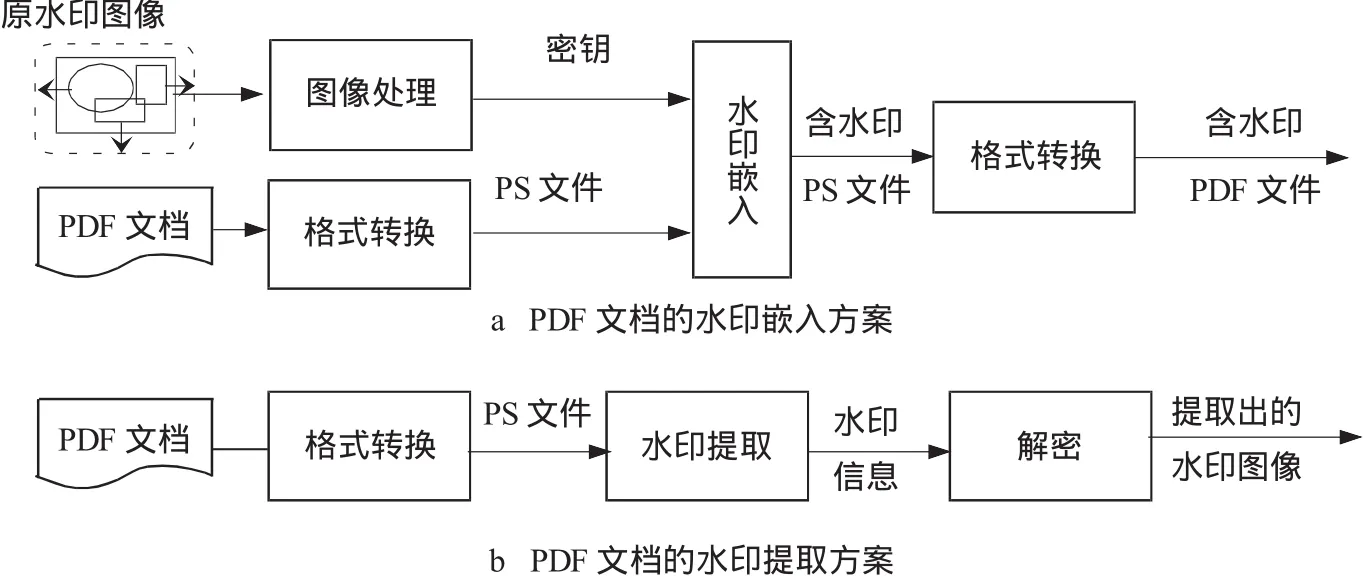
图1 PDF文档的水印嵌入与水印提取模型
在水印编码过程中,先将PDF文档转换成PS文件,然后将处理后的水印信息嵌入到关于PDF文档格式的描述中,最后将修改后的PS文件转换成含有水印信息的PDF文档。水印解码时,同样先将PDF文档转换成PS文件,然后从PS文件的PDF页面格式描述中,依照某种方式提取出水印信息。
1.2 空格编码算法原理
空格编码是指利用文本中的空白空间变换来加入水印。空格编码具有不易引起阅读者注意的优点。空格编码主要有三种实现方式:利用句间空格、利用行尾空格和利用字间空格[13-14]。
第1种方法是在某个特征符号后插入一个或者两个空格来表示放入的信息数据,如在英文诗歌的每行后,C语言源程序的每个分号后等等。这种方法具有如下缺点:首先是编码效率非常低;其次是数字水印的编码方法在一定程度上依赖于文本的内容类型,如有些散文诗缺乏特征字符来标记,一些字处理软件在一个或两个词后会自动插入空格等。
第2种方法是在每一行的行尾插入空格。这种方法的好处在于几乎对所有的文本格式均可进行数字水印的加载,而且不易觉察。这种方法也存在着许多缺点,例如有一些软件会自动删除文本中行尾的空格,无法抵抗复制攻击,水印健壮性较差等。
第3种方法是在词和词之间插入空格从而嵌入信息。为了区别插入的空格和原有的空格,可以使用类似曼彻斯特编码的方法进行编码和解码。这种方法的编码速率较前两种有显著提高。
本文利用在PDF文件中加入空格不会引起读者视觉上的变化的特点,在PDF文件中叠加一些由空格组成的行,并利用所加行中各空格之间的字符间距值来嵌入水印信息。
1.3 Arnold置乱变换
Arnold变换[15]又称猫脸变换,因为经常用一张猫脸演示而得名。Arnold变换与其他一些置乱算法相比,变换简单且具有周期性,因此使用较为广泛。Arnold变换方程如下

其中,x,y∈(0,1,2,…,N-1)表示某一像素点的坐标,N表示图像矩阵的阶数。经Arnold变换后的图像会变得混乱不堪,可以利用Arnold变换的这种性质来增加图像对某些攻击的抵抗力。当被置乱的图像遭到恶意攻击导致局部受到严重毁坏后,在置乱图像的恢复中,Arnold变换将会把原来遭到毁坏的那部分分散开来,减少其对人眼视觉的影响,从而提高了数字水印的鲁棒性。对置乱后的图像继续使用Arnold变换,一定会出现一幅与原图相同的图像,即Arnold变换具有周期性。
2 数字水印嵌入和提取
2.1 对水印图像置乱处理
水印图像为二值图像文件。对原水印图像,做Arnold置乱变换,置乱因子即变换次数,可作为检测水印的密钥。
2.2 水印嵌入算法
(1)运用Arnold置乱方法对原始二值水印图像Iw(图像大小为N×N)进行K次置乱,保存K作为提取水印时的密码,置乱后的图像记为Iw'。
(2)将原始文档Dp转换为PS文件Dps,获取行位置信息和字符间距信息。记行位置信息为Lr,字符间距信息为Lr(x,y)。
(3)增加一些由空格字符组成的行,行位置信息为Lr,将置乱后的水印图像值按下式(2)嵌入到字符间距信息中

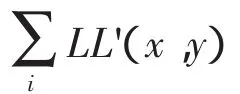
同时,将水印图像的位置信息也嵌入到字符间距值中。嵌入过程为:选取PDF文档增加的空格行的第i个字符间距作为水印位置信息的嵌入起始位置,选取此位置时,应尽量选取每行中间位置处。这是因为非法复制者经常选取中间位置处的内容,而且中间位置处的信息不容易发生改变,这样会提高水印提取的准确率。本文实验中,取i=10,即选取每行第10个字符间距开始处,连续的2*M位作为水印信息的位置信息,其中M=「log2N」。得到每行第i+2*M个字符间距嵌入水印的位置信息,将行列值分别转换为二进制数据,再将此位置的二进制的行列值信息按下式(3)填入此行从第i到i+2*M的字符间距信息内

其中,LL'(x,y)为嵌入位置信息后的字符间距值,LL2(x,y)为初始字符间距值,W2(x,y)为位置信息值,P2为加权因子,可适当调整此值增加鲁棒性。
(4)将嵌入水印后的PS文件转换为PDF文件,从而得到含有水印的PDF文档。
2.3 水印提取算法
(1)将含有水印的PDF文档转换为PS文件。
(2)取出所有由空格字符组成的行,读取字符间距值,获取嵌入的水印信息和位置信息(PDF转换到PS过程中可能有很小的误差,实验中可考虑这些误差)。然后根据获得的位置信息值和水印信息值,得到二值图像。
(3)将得到的二值图像进行反Arnold置乱变换,得到提取出的水印图像。
3 实验仿真及结果分析
本文的实验以Adobe distiller 9为工具,图像处理环境为Matlab 7.0,原始水印图像为32×32的二值图像,Arnold变换次数K为3。
图2给出了实验过程的部分数据。其中,LL1取为2,LL2取为3,P1取为5,P2取为8。
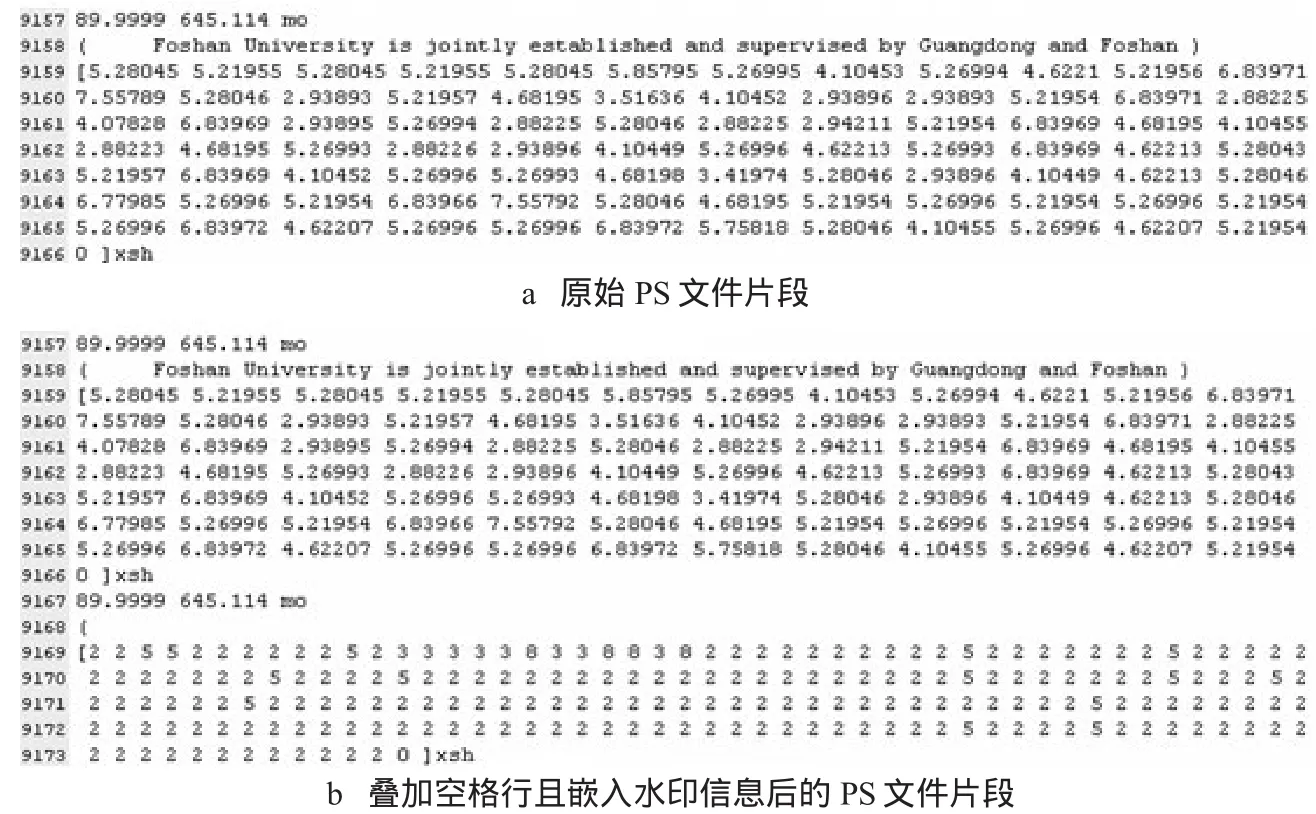
图2 水印嵌入过程效果图
实验结果分析:可感知性方面,由人的肉眼来识别。用NC值来反映提取水印与原始水印的相似程度,计算公式如下

其中,w表示原始水印图像的像素点,w'表示提取出的水印图像中的像素点。NC越接近1,说明提出的水印和原始水印越相似。
图3给出了实验结果。由于水印算法的原理是在原始PDF文档上叠加由空格组成的行,因此,人眼观测到的嵌入水印后的文档与原图完全一致,从中提取出的水印图像跟原始水印图像完全相同,具有很好的效果。
同时,笔者也对嵌入水印后的文档做了一些攻击,以检测水印提取算法的鲁棒性。对于PDF文档,最常见的操作方法就是裁剪。为此,裁剪出其中的一段,根据裁剪出的这一段PDF文档,利用水印提取算法对其分析,得到如图4所示的水印图像。由图4可以看出,即使是裁剪出比较小的一部分文档,仍然能检测出含有的水印图像。

图4 裁剪后提取的水印效果图
由以上结果可以看出,本文提出的算法信息隐藏能力较强,嵌入效果较好,水印提取算法具有一定的鲁棒性。另外,笔者也做了在水印提取时置乱因子值不符的实验,实验结果表明,当密码不正确时,基本不可能提取到正确的水印。
4 结语
本文针对PDF文档的特点,提出了一种适用于PDF文档的水印嵌入方案。实验结果表明,本算法具有较好的透明性、可视性和较强的鲁棒性。同时,利用Arnold置乱技术,进一步增强了水印的安全性和健壮性。水印检测结果准确,从而具有较强的实用性。但本文提到的算法只能针对PDF文档,而且,不能应对文字识别软件类的攻击。
[1]LUCS,LIAO H YM.MultipurposeWatermarking for Image Authentication and Protection[J].IEEE Transactions on Image Processing,2001,10(10)∶1579-1592.
[2]COX I J,MILLER M L.Watermarking Application and Their Properties[C]//International Conference on Information Technology∶Coding and Computing.Las Vegas∶[s.n.],2000∶27-29.
[3]KIM YW,OH S.Watermarking textdocument images using edge direction histograms[J].Pattern Recognition Letters,2004, 25(11)∶1243-1251.
[4]COX L J,MILLERM L.The First50 YearsofElectronicWatermarking[J].EURASIPJofApplied SignalProcessing,2002(2)∶120-132.
[5]BENDERW,KUTTERM.Multimediawatermark technique[J].Proc of IEEE,1999,87(7)∶1077-1079.
[6]BRASSIL J,LOW S,MAXEMCHUK N F.Copyright Protection for the Electronic Distribution of Text Documents[J]. Proceedingsof the IEEE,1999,87(7)∶1181-1196.
[7]ZHAO J,KOCH E.Embedding Robust Labels into Images for Copyright Protection[C]//The Int Congress on Intellectual Perperty Rights for Speciallized Information,Knowledgeand New Technologies.Vienna,Austria∶[s.n.],1995∶8.
[8]RABAH K.Steganography-the ArtofHiding Data[J].Information Technology Journal.2004,3(3)∶245-249.
[9]SHIRALIS.A New Approach to Persian/Arabic Text Steganography Computer and Information Science[C]//5th IEEE/ACIS InternationalConference.Honolulu,USA∶[s.n.],2006∶310-315.
[10]王飞燕,李峰,陈松贵.基于一维正态云模型的半脆弱文本水印[J].计算机工程与设计,2008,29(17)∶4578-4580.
[11]张秋余,余冬梅,管伟.中文PDF文档数字水印算法[J].计算机工程与设计,2007,28(24)∶5983-5987.
[12]顾艳春,杨扬.一种基于PDF文档和置乱技术的文本数字水印技术[J].佛山科学技术学院学报∶自然科学版,2009, 27(2)∶43-46.
[13]STEFANK.Information Hiding Techniques for Steganography and DigitalWatermarking[M].Boston∶Artech House,2000.
[14]傅瑜,王保保.文本水印附加空格编码方法的实现及其性能[J].长安大学学报,2002,22(3)∶85-87.
[15]ARNOLDEA,AVEZA.Ergodic problemsofclassicalmechanics[M].New Jersey∶Benjamin,W A,1968.
【责任编辑:王桂珍foshanwgzh@163.com】
A text digitalwatermarking algorithm for PDF documentbased on spaceencoding and scrambling technique
GUYan-chun1,FENG Jun-ting2
(1.SchoolofElectronicsand Information Engineering,Foshan University,Foshan 528000,China; 2.Information System Department,The FirstPeople’sHospitalof Foshan,Foshan 528000,China)
∶A text digital watermarking algorithm for PDF document based on space encoding and scrambling technique is proposed.Thewatermark image is firstencrypted by scrambling technique.Then,the original PDF document is transformed into PS file,in which preserved the characters and their location information.Thirdly, we superimpose some rows composed of space into the PS file.The binary watermark image with its location information is embedded into the character spacing of the PS file.Finally,we get the PDF document containing watermark through the PS file.Experimental results demonstrate that the proposed algorithm is imperceptibility and robust to some degradation processessuch as cropping.
information hiding;spaceencoding;scrambling technique;textdigitalwatermarking;PDFdocument
TP391.4
A
1008-0171(2015)01-0076-05
2014-05-14
佛山科学技术学院科研基金资助项目(2010X063)
顾艳春(1981-),男,河南信阳人,佛山科学技术学院讲师,博士。
