自动组卷系统试题难度和知识点覆盖控制算法
2015-05-22柳浪涛
柳浪涛,谷 林
(西安工程大学 计算机科学学院,陕西 西安710048)
0 引 言
题库管理系统的自动组卷功能在教学活动中可以减轻教师出卷的工作负担,能够科学、全面考核学生的学习成绩,及时反馈学生对知识的掌握情况,提高教学质量[1-4].自动组卷通常需要按照组卷人对试卷的要求设置基本信息(题型,各题型对应题目的数量,题型的难易等级,每道题目的分值),然后依照设置生成一套符合要求的试卷[5-6].
题库管理系统中能够实现自动组卷的核心是自动组卷的算法.目前已有不少学者对此类算法进行了研究,文献[7]以分类的方法将试题库全集划分成若干个子集,并且把将要生成试卷的试题按一定的规则分解成不同的试题子集,然后针对不同的试题子集随机抽取指定数量的试题,此算法缩小了随机抽题的范围,并且在一定条件下提高了组卷的效率,但是在约束条件变少,导致划分的试题子集也减少的情况下,对试题的抽取难以实现精确控制;文献[8]提出了基于线性递减系数粒子群优化算法策略,试图避免粒子群优化算法在组卷过程中陷入局部最优的困局,但本质上是调整了粒子群优化算法的惯性系数,使得算法中的步长减小,这只会减小组卷过程中出现局部最优问题的概率,但不能从根本上避免粒子群优化算法中的局部最优问题;文献[9]在实现组卷的过程中依靠蚁群算法的快速和智能搜索能力,先对建立的数学模型进行求解,然后得到最优组卷方案进行组卷.
文中研究的组卷算法综合考虑了组卷人对试卷各指标(难度、章节、知识点)的设置,在组卷过程中系统依照“卷内分块、组块分层”的机制将被组的试卷按照题目的类型分成若干个题型块,并且在算法实现过程中将每一个块分成数据层、处理层、存储层.系统会在处理层完成每一个题型块的所有组卷操作,每当一个题型块的组卷动作完成,系统会将被组卷模块的难易等级与设置的参数进行比较,如果分析的结果和设置的参数一样则此模块的组卷完成,进行下一个模块的组卷动作,否则系统要不断调整处理层数据的难易等级,向被设置的参数逐渐逼近直到相等为止.
1 设计思想
将题目的知识点和难易程度作为组卷过程的两个因素,为了对其进行有效控制,所定义的题库信息如表1所示.其中,知识点用于说明题目所属章节信息,它是出卷时进行知识点覆盖规则匹配的一个重要参数.将试卷本身看成一个整体研究对象,其组卷过程如式(1)所示:
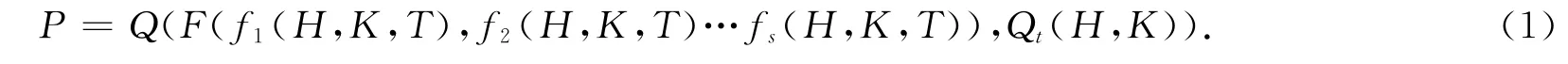

表1 题目信息表Table 1 Title information
式中,P表示一个对象的组卷,Q表示成功组成一套试卷的所有动作,F表示只考虑难易程度(H),知识点(K),题目类型(T)3因素的组卷动作,f1(H,K,T)表示对此模块进行第一次有关难易程度(H)、知识点(K)、题目类型(T)的验证操作,Qt表示对同种类型题目的知识点和难易程度进行平衡操作,其中fs(H,K,T)中s由其迭代的次数决定.依照此方法实现系统的组卷,由于要将题型、知识点、难易等级综合考虑在内,所以涉及的内容广,实现起来对程序员的要求高,并且由于程序的嵌套导致系统的效率不高.
按卷内分块和组块分层的机制把一套完整的试卷按照题目类型分成若干个模块,再将每一个模块看成一个对象,其次再把每个对象分成3个层次:首先,处理层根据随机函数从数据层取出对应数量的题目(数量的大小在试卷的指标信息表里获取,其中试卷的指标设置如表2所示),再将当前题型块的难易等级(其中难易等级的计算如式(4)所示)与试卷指标里设置的难易等级进行比较,如果相等表示此模块的组卷动作完成,并且将处理层数据存入到存储层,否则执行处理层的组卷均衡动作,如式(2)所示.


表2 试卷指标信息Table 2 Papers index information
式(2)所描绘的是单个对象在处理层的验证过程,G表示此次组卷的所有动作,g1(H,U)表示对此模块进行一次有关难易程度(H)、知识点(K)的验证操作,gn(H,K)表示对当前模块信息进行n次查询然后与组卷要求进行比较,如果不符合组卷要求则要剔除相应题目,然后重新来组织此模块,其中n的大小是由验证次数决定.要想依照此设计思想完成组卷,关键点就在于对试卷难易等级的测量.
2 难易等级测量
为了衡量大多数人的学习情况,难易等级是按照正态概率分布思想来划分的,各个等级的概率分布如图1所示.图1中不同难易等级的值是将标准正态分布在-2σ,-σ,σ,2σ处分割成5块,分别取各块所占面积的近似值,其中容易和难各占2.5%,较易和较难各占13.5%,中等占68%.同时,在估计某种题目类型的难易程度时依照统计学中均值的思想,以百分制为例,系统分别给这5个等级赋予一组不同的估计系数,其系数的估计公式如式(3)所示:
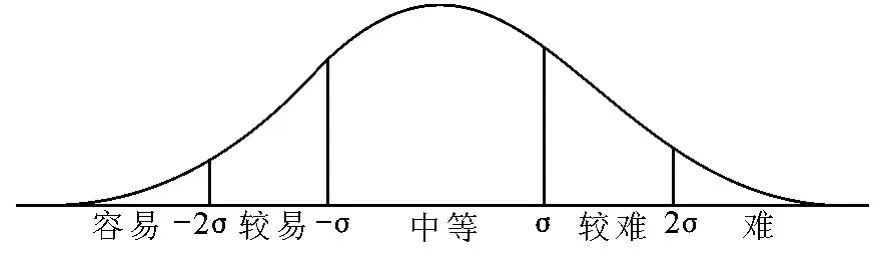
图1 等级概率分布图Fig.1 Level probability distribution

式中,Yn表示第n等级的估计系数,Xk表示第k等级在概率分布图中所占的比重.图1中从右往左5个等级的估计系数分别是0.987 5,0.917 5,0.51,0.092 5,0.012 5.系统通过计算所有题目的分数所对应的均值来估计同一试卷的难易等级.其估计公式如式(4)所示:

式中,Xk表示第k个题目的分数,Yn表示当前题目的难易等级系数,Z是最终计算获得的一个统计分值,通过查看Z值落在的等级区间即可获得试卷的难易等级.其中试卷的等级区间是依靠难易程度所占的比重来计算的.以总分为百分制的试卷为例,易等级所占比重为2.5%,所以它的分值的区间就是[0,2.5],其他等级依次类推.
3 算法实现
本算法优先考虑组卷人对试卷的指标设置,在满足试卷指标设置的情况下,通过难易等级分析公式对组成的试卷进行难易等级分析,如果分析的结果不满足组卷要求则调用均衡难易等级的方法调整组成的试卷,否则执行下一模块的组卷.算法主要过程如下:
(1)初始化数组a[4][4]用于存放组卷人对试卷的指标设置信息,初始化标签i设置初始值0,用于访问第i行指标a[i][0]到a[i][3]的数据.初始化3个缓冲区tempor List、title List、examation List分别用于存储组卷过程中数据层、处理层、存储层数据.
(2)从a[i][0]到a[i][3]中取出第i行的数据,按照取出数据的要求(试卷指标)从数据库里面获取对应的题目(此题目类型中,不同知识点的不同难易等级题目各两道)信息存入tempor List,然后从tempor List里随机获取指定数量(在存储指标的数组中获取)的试题存入title List.
(3)调用式(4)估算title List中试题的难易等级,如果比要求高(低)执行步骤(4),否则执行步骤(5).
(4)从title List中剔除高于或等于(低于或等于)的一道试题,从tempor List里面找出难易等级为次高(次低)的且title List中没有此知识点的试题.如果还高(低)跳转到步骤(3).如果出现低(高)跳转到步骤(6),表示试题不足不能组卷.
(5)将title List数据存入examation List(就是存放整个试卷的试题),如果标签i的值小于4(题目类型只有4种),标签i的值加1,然后跳转到步骤(1),否则跳转到步骤(7).
(6)输出提示,试题不足不能完成组卷.
(7)将titleList中试卷打出组卷完成,结束.
3.1 算法的关键代码

3.2 实验结果与组卷结果分析
实验针对一般随机算法和文中描述算法,在同一难易等级的题目数量不变,组卷中分别取题目数量为15,19,20,21,25的条件下完成.实验结果统计如图2和图3所示,根据数据表明,依靠一般随机算法实现组卷成功与否只取决于题库里试题的数量,但是组卷结果符合组卷要求的概率比较低.图3中实验五的成功率没有达到100%,究其原因发现,在题库中只有20道题目的难易等级为“容易”,不能组成具有25道题目且难易等级为“容易”的试卷,从而造成组卷失败.但是在真实的组卷环境下,题库中题目数量会远远大于要组试题的数量,所以不会出现类似于图3中实验五的情况.

图2 一般随机算法实验结果图Fig.2 General stochastic algorithm test results

图3 文中描述算法实验结果图 Fig.3 Algorithmic test results
表3是使用一般随机算法和文中所述算法实现要求难度为“较难”的组卷结果分析表.由表3看出,一般随机算法的试卷难易等级为“中等”,不符合组卷中难度的等级要求,并且存在知识点重复(同一章节号的多道题目)的现象,而文中描述算法的组卷结果,难度等级为“较难”符合组卷要求,并且克服了知识点重复现象.因此综合对以上2种算法的实验结果与组卷结果可知,文中描述的组卷算法,组卷结果更加合理.

表3 结果分析Table 3 Result analysis
4 结束语
本文采用“卷内分块、组块分层”的组卷机制,设计了一套完整的自动组卷算法.经过实验并与一般随机算法对比分析,证明此算法在试卷难度和知识点覆盖控制方面具有良好的改进效果,并且系统运行速度较快、组卷效率较高.
[1] 李丽,陈未如,王翠青.通用职能题库管理系统的研究与实现[J].沈阳化学学院学报,2005,19(3):236-240.LI Li,CHEN Weiru,WANG Cuiqing.Study and realization of general intelligentItem bank system[J].Journal of Shenyang Institute of Chemical Technology,2005,19(3):236-240.
[2] 夏万东,藏玉红,齐晓旭,等.通用试库管理系统的设计与实现[J].承德石油高等专科学校学报,2014,16(3):44-47.XIA Wandong,ZANG Yuhong,QI Xiaoxu,et al.Design and implementation of general test questions library managenebt system[J].Journal of Chengde Petroleum College,2014,16(3):44-47.
[3] 龙草芳,肖衡.试题库建设与组卷算法研究[J].电脑知识与技术,2013,13(9):2955-2959.LONG Caofang,XIAO Heng.Research on design of test database and algorithm of examination paper[J].Journal of Computer Knowledge and Technology,2013,13(9):2955-2959.
[4] 杨勋.在线考试系统的组卷算法研究[J].电脑知识与技术,2014,10(32):7621-7623.YANG Xun.Research on the test paper composition algorithm of online examination system[J].Computer Knowledge and Technology,2014,10(32)::7621-7623.
[5] 赵静雅,高斐,高震宇.在线考试系统自动组卷算法研究[J].电子制作,2014(8):282-283.ZHAO Jingya,GAO Pei,GAO Zhenyu.Research of auto generating test paper algorithm of online examination system[J].Electronic Production,2014(8):282-283.
[6] 陈晓敏,梁静,葛宇.基于改进遗传算法的智能组卷研究[J].西南师范大学学报:自然科学版[J].2012,37(5):98-101.CHEN Xiaomin,LIANG Jing,GE Yu.On intelligent test paper auto-generation based on improved genetic algorithm[J].Journal of Southwest China Normal University:Natural Science Edition,2012,37(5):98-101.
[7] 吕东哲,苏烈华.基于分类随机算法的试卷生成算法研究[J].计算机光盘软件与应用,2014(8):190-191.LYU Dongzhe,SU Liehua.Based on the papers random generation algorithm classification algorithm[J].Computer CD Software and Applications,2014(8):190-191.
[8] 白雁.基于线性递减系数粒子群优化算法的组卷实现[J].现代电子技术,2014,37(24):41-44.BAI Yan.Implementation of test paper generation based on particle swarm optimization algorithm with linear decreasing inertia weight[J].Modern Electronics Technique,2013,37(24):41-44.
[9] 刘毅.人工智能在自动组卷建模中应用研究[J].计算机仿真,2011,28(8):385-388.LIU Yi.Auto-generating test paper based on artificial intelligence[J].Computer Simulation,2011,28(8):385-388.
