基于SECUNIA漏洞库的数据挖掘算法研究*
2015-05-22宋晨阳蒋丹婷
周 密,宋晨阳,蒋丹婷
(上海通用识别技术研究所,上海201112)
0 引言
当今信息技术的飞快发展,加速了现代社会向信息化社会迈进的步伐。但伴随而来的信息安全问题也涉及到国家的各个层面面,各种漏洞的产生使目前信息安全形势面临严峻考验。如何从既有漏洞数据中发现有价值的信息,为信息安全事件的预防和安全措施的建立提供前瞻性的分析,成为极具意义的工作。通过数据挖掘,分析不同软件之间、同一软件不同版本之间漏洞的关联关系,建立关联规则表。从而当发现某一软件发现漏洞时,按关联规则检查其他软件或软件的其他版本,提前发现漏洞、预防风险。
数据挖掘(DM,Data Mining)技术的出现可以有效解决此类问题。数据挖掘是从大量包含噪声的随机数据中,提取隐含在其中具备潜在意义的信息和知识的过程[1]。通过对信息安全漏洞库进行数据挖掘,建立关联规则,可以对漏洞出现趋势实现预测,为防范信息安全问题和信息安全事件的发生提供依据。
1 基础概念介绍
1.1 数据挖掘
数据挖掘(DM)融合了多个领域的理论和技术,如人工智能、数据库、模式识别、统计学等技术[2]。数据挖掘常与数据库中的“知识发现”(KDD,Knowledge Discovery in Database)进行比较,对于两者之间的关系,学术界有很多不同见解[3]。数据挖掘属于整个知识挖掘过程的一个核心步骤,如图1所示。
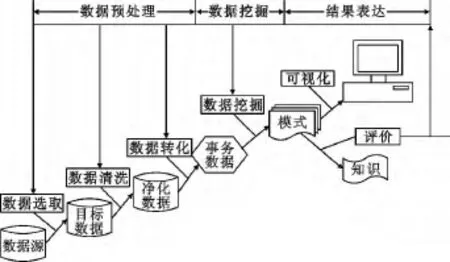
图1 KDD过程示意Fig.1 Schematic diagram of KDD
1.2 信息安全漏洞
漏洞(Vulnerability),又称为缺陷。对信息安全漏洞的定义最早是在1982年,由美国著名计算机安全专家 D.Denning[4]提出,D.Longley 等人从风险管理的角度分三个方面描述漏洞的含义,M.Bishop等人采用状态空间描述法定义漏洞,权威机构如美国NIST在《信息安全关键术语词汇表》[5]以及国际标准化组织发布的ISO/IEC《IT安全术语词汇表》[6]中也对漏洞进行定义。
世界上比较较知名的漏洞数据库包括美国国家漏洞库 NVD(National Vulnerability Database)、丹麦的Secunia漏洞信息库等,我国在2009年也建成了中国国家信息安全漏洞库CNNVD。本文选取Secunia漏洞库的漏洞数据作为样本进行数据挖掘。
2 数据挖掘算法
2.1 数据挖掘任务
数据挖掘任务主要是发现在数据中隐藏的潜在价值。数据挖掘模式主要分为两种:描述型和预测型。描述模式是对历史数据中包含的事实进行规范描述,从而呈现出数据的一般特性;预测模式通常以时间作为参考标准,通过数据的历史值预测可能的未来值。依照不同的模式特征,细分六类模式:预测模式、关联模式、序列模式、分类模式、回归模式以及聚类模式。本文主要针对关联模式进行深入探讨。
2.2 关联规则分析及算法
关联规则算法是指相关性统计分析,基于分析离散事件之间的相关性统计而建立关联规则,关联规则算法是定量分析,所以必须将样本中的数据进行离散化操作,此算法是基于大量数据样本的优化算法。
(1)关联算法中的几个基本概念
关联规则算法包含4个基本概念项集。项集是一组项的集合,每个项都包含一个属性,例如,项集{A,B}。项集的大小是指向集中含有项的数量。频繁项集为样本中出现频率高的项集。
支持度。支持度用来衡量项集出现的频率。项集{A,B}的支持度定义为同时包含项A和项B的项集的总数。定义为:

最小支持度Min_Support是对项集进行限制的阈值参数。
置信度。置信度描述了项集关联的属性,规则A推导出规则B(A→B)的置信度为:

最小置信度Min_Confidence为阈值参数。
重要性。重要性用于度量项集和规则,项集重要性定义为:

项集重要性值反映项集之间的相关性。如果Importance=1,则A和B是独立的项;如果Importance>1,表示正相关;如果 Importance<1,则表示负相关。
规则的重要性公式为:

规则重要性值与0比较,反映规则的关联性。Importance>0表示A发生,则B发生的概率会升高;Importance<0表示A发生,则B发生的概率会降低。
(2)Apriori关联算法
Apriori算法将发现关联规则的过程分为两个阶段:首先通过迭代,检索出数据集中所有的频繁项集,即支持度不低于最小支持度的项集;第二阶段利用频繁项集构造满足最小信任度的规则。步骤如下[7]:
步骤1:产生长度为1的频繁项集。扫描数据库D,产生频繁项集L1。
步骤2:关联。在第k(k>1)次扫描时,通过Lk-1⊕Lk-1,从而产生候选项集 ck。
步骤3:剪枝。删减非频繁项集。设:ck∈Ck,若ck的所有长度为 k - 1 的子集 ck-1都属于 Lk-1,则该ck将被保留;否则则从Ck中去除该ck。
步骤4:产生强关联规则。根据最小置信度Minimum_Confidence遍历频繁项集,得出强关联规则,算法结束。
3 运用关联规则算法挖掘Secunia漏洞数据库
Secunia漏洞库覆盖范围包含程序和系统中的各种漏洞。该数据库持续更新体现最新的漏洞信息。Secunia漏洞公告主要包括:漏洞名称、Secunia公告号、日期、漏洞等级、漏洞来源、影响范围、操作系统版本等。
以Secunia漏洞库中的信息为样本,构建关联挖掘规则,反映出漏洞信息在不同系统中的关联性。
3.1 构建关联规则
(1)挖掘任务
通过历史漏洞信息,挖掘分析不同软件出现同类型漏洞的概率。
(2)挖掘结构
结合挖掘任务,数据挖掘关联表为事例表结合嵌套表的方式。建立漏洞表Vulnerabilities,此表为事例表,漏洞id作为主键。嵌套表为Softwares表,记录软件名和软件版本类型,软件id作为两张表进行关联的外键。关联规则挖掘结构如图2所示。

图2 挖掘结构Fig.2 Mining Structure
3.2 关联规则挖掘结果
通过采集的Secunia库的数据作为样本,应用Apriori算法模型。依据最低支持度(Min_S)和最低置信度(Min_P)的阈值,形成相应的规则集。通过调整Min_S和最低Min_P的值,得到如表1所示的值。

表1 关联规则挖掘结果Table 1 Result of Association Rule Mining
通过表1中结果,可以分析出随着最低支持度的增加,对应的关联规则的数量呈递减趋势;当最低支持度阈值大于0.04时,则关联规则数量很少。当最低支持度恒定时,随着最低置信度的增长,关联规则数量逐渐增加。为了能够取得可靠的关联规则,采用最低支持度为0.02,最低置信度为80%,并且将规则重要度阈值设定为大于1.6,一共获得40条关联规则结果,部分规则如表2所示。

表2 挖掘产生的部分关联规则Table 2 Part association rules of mineing
在表2中关联规则一栏中,“现有”的含义是一种已经存在的漏洞。规则1:软件Red Hat Enter-prise Linux ES 4和Red Hat Desktop 4.x出现相同漏洞的置信度是1,即概率是100%,重要度是3.438;规则2:若软件Red Hat Enterprise Linux HPC Node 6和Red Hat Enterprise Linux Desktop 6同时出现某种漏洞,则Red Hat Enterprise Linux Server 6出现该漏洞的概率是100%,重要度是2.317;规则3:open-SUSE 11.1和openSUSE 11.2出现某种漏洞的概率是100%,重要度为1.899。
通过上述例子可以看出,当关联规则的置信度越高、重要度越高,则该条关联规则的价值越高,根据具体情况,可以设置最低置信度和最小重要度作为该条规则是否有价值的标准,即(Confidence(A→B)min,Importance(A→B)min),根据对置信度和重要的综合考虑,可以得出价值更高的关联规则,从而对信息安全事件有更好的预警分析。
4 结语
本文主要研究了基于Secunia漏洞库的关联规则挖掘算法。介绍了数据挖掘的相关概念、关联规则相关算法、Secunia漏洞库的基本信息。以Secunia漏洞库的数据为样本进行关联规则挖掘,分析了漏洞与软件关系的关联规则,建立了不同软件中出现相关漏洞的联系。如今,世界各国都在建立信息安全漏洞库并发布信息安全漏洞信息,将漏洞信息与数据挖掘结合,可以对信息安全事件进行提前预警,具有重要而且长远的意义。
[1]Han J,Kamber M.Data Mining:Concepts and Techniques[M].Canada:Morgan Kaufmann Publishers,2001.
[2]王光宏,蒋平.数据挖掘综述[J].同济大学学报,2004,32(02):246-252.WANG Guang - hong,JIANG Ping.Summary of Data Mining[J].Journal of Tongji University.2004,32(2):246-252.
[3]毛国君,段立娟,王实,等.数据挖掘原理与算法[M].第2版.北京:清华大学出版社,2007:7-8.MAO Guo- jun,DUAN Li- Juan,WANG Shi.Principles and Algorithms of Data Mining[M].Tsinghua University Press.2007:7 -8.
[4]Denning D.Crytography and Data Security[M].Reading,MA,USA:Addison -Wesley,1982.
[5]Kissel R.Glossary of Key Information Security Terms,NIST IR 7298[R].National Institute of Standards and Technology(NIST),2006.
[6]ISO/IEC SC 27 SD6.Glossary of Information Security Terms[S].International Organization for Standardization(ISO),2009.
[7]刘维晓,陈俊丽,曲世富,等.一种改进的Apriori算法[J].计算机工程与应用,2011,47(11):149-151.LIU Wei-xiao,CHEN Jun -Li,QU Shi-Fu.Improved Apriori Algorithm[J].Computer Engineering and Applications.2011,47(11):149 -151.
