基于形态学的多方向文本定位方法
2015-05-18郭桂芳洪留荣葛方振
郭桂芳,洪留荣,葛方振
淮北师范大学计算机科学与技术学院,安徽淮北,235000
1 问题的提出
视频中的文本作为一种高级语义特征,对视频文本的检测、定位和识别具有重要的作用。视频包含的文本可分为场景文本和人工文本两类[1]。虽然过去提出了很多方法,但文本检测由于受到颜色、尺寸及光照和角度的影响,仍面临很多挑战[2]。
目前,大多数研究针对水平方向的文本检测,如基于颜色模型的方法[3]对每行文本进行颜色聚类,基于梯度方法[4]逐行识别候选文本,基于边缘的方法[5]分析水平或垂直方向的边缘轮廓,因此这些方法都是假设文本是水平方向的。本文提出的方法在保证较高准确率和召回率的情况下,能够检测任意方向的视频文本,具有较强的通用性。该方法假设视频文本成直线方向,利用梯度差聚类得到候选文本区域,选择形态学骨架化的方法提取文本区域的骨架,分割连通分量集合为单连通分量,利用启发性规则去除虚假文本块,获得精确检测结果。

图1 算法流程图
2 多方向文本定位方法
本文提出的文本定位的方法主要步骤如图1所示。
粗检测时,先对文本进行滤波分析,结合最大梯度图进行聚类,去除大部分非文本区域,精确定位时用骨架化分析和规则滤除虚假的文本区域,得到最终检测结果。
2.1 基于梯度聚类
图像中的文本易受各种噪声成分的影响,需对其进行去噪操作,以消弱背景信息、加强文字信息,为后续处理作准备。通过比较分析,本文采用3*3高斯模板去除图像噪声。因为文本区域与背景区域通常具有较强的对比度,且存在很多的笔画边缘,使得文本行具有较高的梯度差。利用文献[4]中方法,对图2计算最大梯度值,得到梯度图如图3所示。采用最大梯度值是因为当文本区域与背景对比度较弱的条件下,也能保留文本区域。根据梯度欧几里德距离选择较简单的K-means聚类把所有的像素分为两类:文本和非文本区域。再用形态学开运算去除图中小的噪声点,得到图4。
2.2 骨架化
对于文本倾斜的图像,如果用矩形框显示检测文本块,行与行之间会出现文本块重叠现象,覆盖背景像素,这种方法适用于水平方向文本,因此本文利用形态学中骨架化的方法提取图中的文本骨架。骨架化是形态学中比较简单且运行时间短的方法。提取骨架可以通过比较、选择合适的结构元素。

(1)获得图像中区域的骨架。假设每行文本都是成直线对齐的,结合聚类图利用骨架化操作提取图4中的文本骨架如图5所示。
(2)骨架分类。文本骨架大致可以分为两类:简单的连接组件和复杂连接组件集合。简单的连接组件可能是单一的文本区域,也可能是非文本区域;复杂连接组件集合包括了多个彼此连接的文本区域或非文本区域。例如,图6中包括了3条较长的文本行区域和左半部分的标志区域(非文本区域),必须把复杂连接组件的集合分割成简单的连接组件,以判断是否为真正的文本区域。
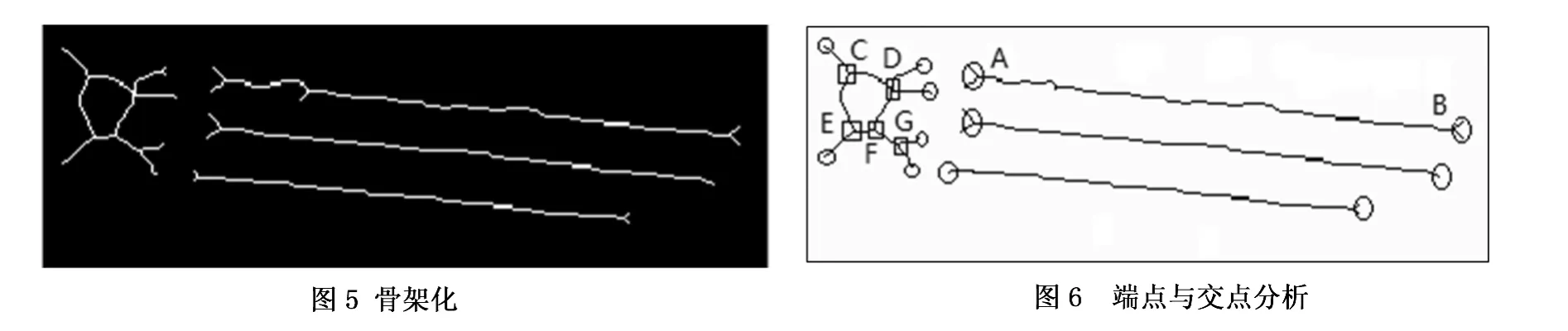
(3)连通组件分割具体如下:①判断端点与交点。用8方向邻域生长算法(算法思路如式(1)所示)进行连通区域标记,为每个连通区域分配一个链表数组元素,用链表记录该连通区的端点。在大尺度范围内(本文采用5*5范围内),判断端点相近(相邻)的个数超过3个以上视为骨架的交点,其余为骨架的端点。
1.3 连通分量分析
通过骨架化得到候选的连通分量,仍有部分分量是噪声。利用启发性知识去除非字符区域,得到真正的文本区域。bi是候选文本区域的骨架,则(1)直线度:Strainghtness(bi)
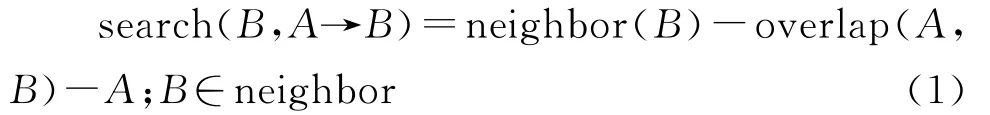
②分割组件集合为简单组件。分割复杂连接组件集合的简单方法是去掉上一步中得到的交点,就可以找到简单的连接组件。参照8方向领域生长算法,按式①调用主生长函数。过程是8个生长函数互相调用,最好是这些函数返回,区域标记完毕。按此方法搜索领域像素,降低了搜索个数,平均效率提高了50%。
如图6所示,对骨架化的结果根据交点进行分割。圆圈表示线端点,矩形表示线与线交点。线段1、2、3是简单的组件,A、B 是端点,C、D、E、F、G 是交点,CD、CE、DF、EF和FG 是连续的线段,从复杂组件集合中分割出来。骨架中的连续线段通过连通分量进一步分析,获得精确检测。线条1、2、3是分割出的文本线段,而线段CD、CE、DF、EF和FG代表标志部分(非文本区域)。该算法实际上在小尺度内搜索连通区得到端点。在大尺度内进行合并,避免了更多的杂点,又改善了标记图像的连通性,并在保证交点正确率的同时,提高了合并效率。Length(bi)是骨架的长度,End_Distace(bi)两端之间的直线距离。直线度值越大,是文本线段的可能性越小,实验中选择≤1.3。
(2)边缘密度:图像中文本存在许多边缘像素,具有较高的边缘密度,因此,只有边缘密度较高的才是文本区域,假设|cc|为连通域内边缘像素点的数量,Area(cc)为每个简单连通区域像素总数。边缘密度定义为:
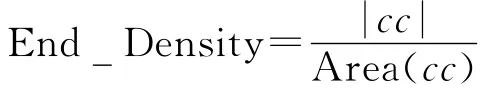
实验中边缘密度的值≥0.2。
3 实验结果
为了验证方法的有效性,以ICDAR2005竞赛提供的数据集为测试平台来进行文本检测实验。实验结果依据业内通用评价标准的准确率和召回率2个指标进行评价。
召回率=正确检测到的文字区域个数/图像中实际存在的文字区域个数
准确率=正确检测到的文字区域个数/由检测算法检测到的文字区域总数
图7给出了本文提出的骨架化检测方法的文本检测结果,图8是基于梯度的方法检测结果。可以看出,本文提出的方法可以较好地实现图像中的文本检测。

将文本提出的方法与基于梯度、基于边缘的方法进行比较,表1列出了比较后的结果。

表1 检测结果
4 结 论
针对图像文本检测假设水平文本的问题,提出了一种基于形态学的多方向图像文本定位方法。与其他方法相比,该方法不受文本方向限制,对倾斜角度任意甚至是垂直分布的文本都可以采用该方法进行检测。只要通过骨架化操作找到简单组件的文本行,将复杂的骨架部分进行分割,最后根据启发性规则过滤筛选来实现文本的检测。实验结果表明,该方法能提高文本检测的准确率和召回率,同时不受文本方向、颜色和大小的限制。

[1]Zang J,Kasturi R.Extraction of Text Objects in Video Documents:Recent Progress[C].Proc of the 8th International Conference on Pattern Recognition.New York:IEEE Computer Society,2008:5-17
[2]Jiang Ren-jie,Qi Fei-hu,XU Li.A Learning-based Method to Detect and Segment Text from Scene Images[J].Journal of Zhejiang University Science,2007,8(4):568-574
[3]Wong E K,Chen M.A New Robust Algorithm for Video Text Extraction[J].Pattern Recognition,2003,36:1397-1406
[4]Cai M,Song J,Lyu M R.A New Approach for Video Text Detection[C]//Proc of 2002International Conference on Image Processing,New York:IEEE Computer Society,2002:117-120
[5]谢昭莉,彭琴.边缘图像连通区域标记的算法研究和SoPC实 现 [EB/OL].[2011-06-13].http://www.eeworld.com.cn/FPGA/2011/0708/article_2306.html
