一种基于密度的Web文本聚类算法
2015-05-15许芳芳
许芳芳

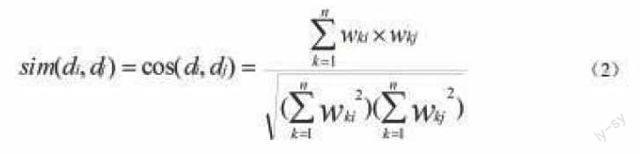

摘要:针对DBSCAN算法采用全局参数Eps、对高维数据处理能力不足等问题,提出一种改进算法,该算法结合蚁群聚类算法实现数据集的划分以获取参数Eps的值组,然后根据不同的Eps值分别调用DBSCAN算法,从而实现对Web文本的聚类。实验结果表明,改进后的算法的有效性有所提高。
关键词:Web文本;DBSCAN;蚁群聚类;Eps值组
中图分类号:TP301 文献标识码:A 文章编号:1009-3044(2015)08-0234-02
Abstract: Focusing on the problem that the DBSCAN algorithm uses the same global Eps and has difficulty with high-dimension of data,proposed an improved web text clustering algorithm.The algorithm use ant clustering algorithm in data preprocessing phase to classify the datasets and to get several values of parameter eps, then call DBSCAN algorithm with different values of Eps to cluster web text . Experimental results demonstrate the effectiveness of the improved algorithm.
Key words: web text; DBSCAN; Ant clustering algorithm; A set of values of Eps
1 引言
互联网的发展使网络上的信息呈爆炸式增长,且超过80%的Web资源以文本的形式存在[1]。这些文本信息的增长对准确检索到相关信息带来了极大的挑战,人们急需某种方法从海量Web文本信息中寻找需要的资源。作为文本分析的一种重要技术,文本聚类可以发现相似文档,以供进一步分析挖掘。由于Web文本挖掘的数据不是事先存储在数据库中,而是利用网络爬虫抓取的大量网页资源,因此,要对Web文本聚类,必须将抓取的Web网页进行文本预处理, 形成文本特征向量,才能进行聚类。
文本聚类算法有多种,但由于Web文本不同于普通文本,这些常用的文本聚类方法必须经过一定的改进后,才可适用于Web文本。基于密度的DBSCAN算法可以发现任意形状的簇,且不需要预先确定数据集将被聚类的簇数,也不受噪声影响。但是该算法需要用户输入统一的全局参数Eps,当数据集的密度不均匀时,导致聚类效果差;并且对于高维数据的处理能力也较差,而Web文本往往是高维的且分布不均的。为了实现对Web文本的有效聚类,本文提出一种改进的DBSCAN算法。
2 Web文本聚类关键技术
要实现Web文本聚类,首先使用网络蜘蛛抓取网页,将网页中与主题内容不相关的HTML标记和广告等移除,并将其转换成文本文件保存;然后对得到的文本进行分词处理,将文本切分成特征词条,去除停用词,统计词频等;将分词后的文本转换为易被计算机理解的形式(即文本特征表示),以及特征降维,之后才能对Web文本进行聚类。
2.1 文本表示
特征词条(即分词后的文本)是用自然语言描述的,计算机无法直接处理,因此需要将文本表示为计算机可以直接处理的形式。向量空间模型(VSM,Vector Space Model)是目前应用最广的文本表示模型。它由哈佛大学的G Salton提出,它将任意一个文本表示成空间向量的形式:V(di)=(w1(di),w2(di),…,wn(di))。其中,n表示总的特征词条数,wj(di)表示第j个特征词条在文档di中的权值。在权值的量化方法上,比较常用的是TF*IDF算法,其中,TF(词项频率)表示特征词条ti在文本dj中出现的次数,记为tfij;IDF(倒排文档频率)表示文本集中总的文档数N与包含该特征词条的文档数n的商值,常用公式log(N/n)来计算,它是特征词条在文本集分布情况的量化。文本特征词条权值的计算如公式1所示:
(1)其中,tfij为在文档dj中含有第i个特征词条的频数,N为文本集中的总文档数,Ni为含有第i个特征词条的文档数。
2.2 文本特征降维
分词后的文本集由众多特征词条构成,且词条数量相当的大。因此表示文本的向量空间维数会很高,将影响文本聚类的效率和精度。一方面大多数聚类算法都难以承受维数太高的向量空间;另一方面在文本中会存在一些通用的、对文本聚类贡献度小的特征词,因此,有必要对文本数据进行降维处理。实验表明,对特征集适当的降维可以减少聚类的计算量且改善聚类效果[2]。目前,用得最多的降维方法有两类:综合评估法和独立评估法[3]。本文选择信息增益法进行降维处理。
2.3 文本相似度计算
对文本集进行聚类处理,需要先度量文本对象之间的相似度sim(di,dj),并且文本聚类的质量一定程度上也取决于度量方法的选择。聚类分析中通常使用欧式距离函数或余弦距离来度量对象之间的相似度。本文采用余弦计算法来度量两个文本间的相似度,其定义为:
(2)其中:wki和wkj分别表示文档di和dj的第k个特征词的权值,n为文档特征词条数。Sim(di,dj)值越大,则表明文本di和dj越相似,反之则区别越大。
3 文本的聚类
3.1 DBSCAN算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法[4]是一個被广泛用于文本聚类分析的算法,它将簇定义为密度相连的点的最大集合,能把具有足够高密度的区域划分为簇。该算法需要用户输入对象邻域半径Eps和邻域内最少对象数MinPts这两个参数来识别一个簇。DBSCAN算法的基本思想是:从数据集中任选一对象p,若p在半径为Eps的区域内包含的对象数目大于等于MinPts个,则p为核心对象并建立新簇,找出所有从p密度可达的对象,将这些对象标注为同一簇;否则,没有其他对象从p密度可达,p被暂时标注为噪声。然后,DBSCAN对数据集中其他未被处理的对象均做上述处理。
3.2 LF算法
蚁群聚类算法是由Deneubourg J L[5]等人根据蚂蚁堆积蚁尸等蚁群聚类现象提出的一种基本模型(Basic Model, BM),Lumer E和Faieta B将该模型扩展,提出了用于数据聚类的LF算法[6]。其主要思想是将待聚类的高维数据对象随机投影到一个二维网格上,同时将若干只人工蚂蚁随机放置到该二维网格内,每只蚂蚁选择一个数据对象,根据该数据对象与局部区域的相似度,决定蚂蚁拾起或放下该对象的概率,从而指导蚂蚁的下一步动作。经过一定代数的迭代后,平面上的属于同一类别的数据对象聚集在一起,从而实现自组织的聚类过程。
邻域相似度f(i)表示蚂蚁在地点r发现的一个数据对象i与其邻域对象间的平均相似度, f(i)可由公式(3)来计算
(3)式中,[0,1]为相似度调节因子;Neighsxs(r)表示地点r周围的以s为边长的正方形局部区域;d(i,j)表示对象i和j在属性空间中的距离,通常采用欧式距离或余弦距离函数。
在LF算法中,若蚂蚁有负载,则按公式(4)计算蚂蚁的放下概率Pd;若蚂蚁无负载,则按公式(5)计算蚂蚁拾起数据的概率Pp。其中,kp和kd均为阈值常数。邻域相似度越高,则蚂蚁放下对象的概率越高,拾起对象的概率越低;反之亦然。
3.3 改进算法描述
LF算法易与其他算法结合,且能有效处理高维数据,但存在计算时间较长等问题;本文采用文献[7]提出的LF改进算法,以减少算法时间成本。改进算法是LF算法與DBSCAN算法的结合,以实现对密度不均的高维数据集的有效聚类。该算法可分为如下三个阶段:
(1)基于LF算法的聚类过程。利用LF算法将高维数据集映射到二维网格中,并将人工蚂蚁和数据绑定,实现对数据集的初始划分。
(2)获取参数Eps的值组。对第一阶段得到的每个数据子集,计算某个到当前聚类中的其他所有点的距离之和最小的点,此点为该类的中心点;计算各类的邻域阈值Epsi(为每个中心点的k个近邻距离的平均距离)。
(3)基于DBSCAN算法的聚类过程。对所有的Epsi按升序排序,依次根据Epsi调用DBSCAN进行聚类,以实现对高密度数据和稀疏密度数据的分别聚类;每次调用后,所有已聚类的数据点将不再参与以后的调用;直到所有的Epsi都使用完毕,剩下的没有被处理过的数据点即是噪声点。
4 实验分析
为了验证本文提出的改进算法的有效性,使用网络爬虫从网易网站爬取了5类约370篇文档作为实验数据,含财经85篇、科技96篇、旅游66、娱乐60和教育63,其中20篇涉及到财经类和科技类,12篇涉及到教育类和娱乐类。将采集到的网页资源进行去噪处理后,以文本文档的格式保存,并采用中科院ICTCLAS分词系统模块对得到的文本信息进行分词;使用公式1进行权值计算,形成向量空间模型并降维。本文采用综合考虑了查准率和查全率的 F-Measure度量[8]作为评价指标,对聚类实验结果进行评价。分别调用DBSCAN算法和改进后的算法对实验数据进行聚类,实验结果的F-Measure值如图1所示。通过图1可以得到:改进DBSCAN算法的F-Measure值高于经典DBSCAN算法,表明改进DBSCAN算法的有效性更好,增强了Web文本聚类的能力。
5 结束语
本文简述了Web文本聚类过程中涉及到的关键技术。提出了一种改进的DBSCAN算法,针对DBSCAN算法用于Web文本聚类时采用全局参数Eps导致聚类效果差、对高维数据处理能力不足等问题给与了有效解决。实验表明,改进后的DBSCAN算法的有效性有所提高。
参考文献:
[1] 陈宇,王强.聚类算法在Web文本挖掘中的应用研究[A].2009全国计算机网络与通信学术会议论文集[C].2009.
[2] 晏璐.基于划分的聚类算法及其在Web挖掘中的应用[D].大连:大连理工大学,2007.
[3] 杨亚坤.基于Web文本挖掘的聚类算法研究[D].包头:内蒙古科技大学,2012.
[4] Ester M,Kriegel H P,Sander J,et al.A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining(KDD96),1996:226-231.
[5] Deneubourg J L,Goss S,Franks N,et al.The dynamics of collective sorting:robot-like ants and ant-like robots[C].Proceedings of the 1st International Conference on Simulation of Adaptive Behavior:From Animal to Animals,1991:356-365.
[6] Lumer E,Faieta B.Diversity and adaptation in populations of clustering ants[C]. Proceedings of the 3rd International Conference on Simulation of Adaptive Behavior:From Animals to Animals.Cambridge,MIT Press,1994:501-508.
[7] 赵烨,黄泽君.蚁群K-medoids融合的聚类算法[J].电子测量与仪器学报,2012,26(9):800-
804.
[8] 黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF的文本相似度量方法[J].计算机学报,2011,34(5) :856-864.
