基于Hadoop的分布式网络爬虫技术的设计与实现
2015-05-15岳雨俭
岳雨俭

摘要:随着互联网行业和信息技术的发展,Google、IBM和Apache等大型公司纷纷投入去发展云计算,其中 Apache 开发的 Hadoop 平台是一个对用户极为友好的开源云计算框架。该文就是要基于Hadoop框架去设计和实现分布式网络爬虫技术,以完成大规模数据的采集,其中采用 Map/Reduce 分布式计算框架和分布式文件系统,来解决单机爬虫效率低、可扩展性差等问题,提高网页数据爬取速度并扩大爬取的规模。
关键词:云计算;分布式网络爬虫;Hadoop
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)08-0036-0c
Abstract: with the rapid development of the Internet industry and information technology, Google, IBM and Apache and other Large Firm are input to the development of cloud computing, in which Apache Hadoop development platform is a very friendly to users of open source cloud computing framework. This paper is based on the Hadoop framework to design and implementation of a distributed web crawler technology, to complete the large-scale data collection, in which the Map/Reduce distributed computing framework and distributed file system, to solve the single crawler low efficiency, poor scalability issues, improve the Webpage crawling speed and expand the scale of crawling.
Key words: cloud computing; distributed web crawler; Hadoop
1 绪论
随着互联网快速的发展,web信息迅速增长,数据量大且种类多,需要把分散的计算机构建成一个系统整体,计算机之间分工协作,减少节点之间的分散,提高网络爬虫的性能。海量且冗杂的数据使得普通的数据库已经不能很好地完成存取,但是分布式文件系统为这样的数据存储提供了强大的支持。且随着互联网中处理海量数据的要求不断增高,云计算就应运而生,云计算框架也被运用于众多的IT行业中。因此,當下对基于Hadoop的分布式网络爬虫技术的研究也有着巨大的意义。
2 相关理论与技术
2.1 云计算
云计算是一种共享的为网络提供信息交付的模式,将互联网中大量的计算机联合起来协同地提供计算、存储和软硬件等服务,为实现超级计算提供了支持。用户可以充分地利用网络联系集中的每一台电脑进行计算或存储。一般的云计算体系结构如图1所示:
2.2 Hadoop
Hadoop 的框架结构主要是由分布式文件系统(HDFS)和Map/Reduce 计算模型两部分组成。其中,Map/Reduce 计算模型是编程模型,如图2所示是Hadoop的分布式平台框架。
从图上可以看出,最底层是物理的计算机节点,这些节点通过HDFS联系整合到一起;Map/Reduce把任务分成若干子任务分配到不同的节点去实现分布式编程,而不必考虑各节点之间是如何共同协作完成的,这样就减轻了程序员的负担。
3 系统分析与设计
3.1 系统布局
本系统是基于hadoop的分布式搜索引擎而设计的,爬虫技术是也是引擎中的一部分,系统可以分成搜索引擎和云计算平台,构架如图3所示:
搜索引擎分为分布式网络爬虫、索引、检索以及界面展示等模块,前三个模块都用到了分布式计算框架来并处处理任务。分布式搜索引擎的功能模块如图4所示:
该引擎的工作过程:首先,数据采集模块需要获取海量的数据作为数据源,就要根据URL链接在网络中不断地爬取网页文件,将这些获取的文件存储到HDFS文件系统中,并对这些文件进行解析有效数据。然后,利用分词技术对文件内容进行处理,再将得到的词串提供给索引模块并建立索引。当用户通过查询界面进行关键词查询时,依次进行查询器的初次处理、分词处理,之后得到关键词串并将这些关键词串传输到检索器,检索结果经过排序后返回给用户。
3.2 分布式网络爬虫框架结构设计
将分布式网络爬虫模块按照爬虫流程进行划分,划分成五个模块,分别为:URL分割注入模块、网页获取模块、网页解析模块、链接过滤模块和数据存储模块。模块图如图5所示:
按照模块之间的联系和功能,并遵循广度遍历的爬取要求,本分布式网络爬虫的详细流程如图6所示:
4 分布式爬虫实现
4.1 爬虫总体设计结构
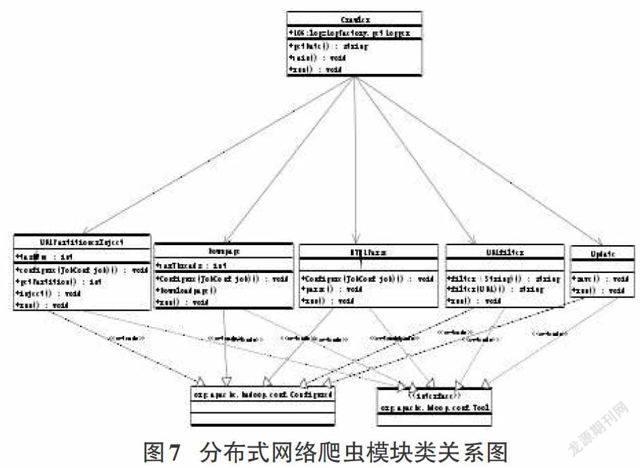
本爬虫系统在hadoop的基础上进行开发的,依照类的不同功能进行划分,可以分为主类和功能类,关系图如图7所示:
其中,Crawler 类为主类,是整个网络爬虫系统的入口,当 Crawler 类运行时,就调用 log4j 记录爬行的信息并保存到日志中,当准备好所有爬虫爬取工作后,接着分别调用五大模块,分别进行相关任务和信息处理。
4.2 功能模块的实现
1)网页获取模块
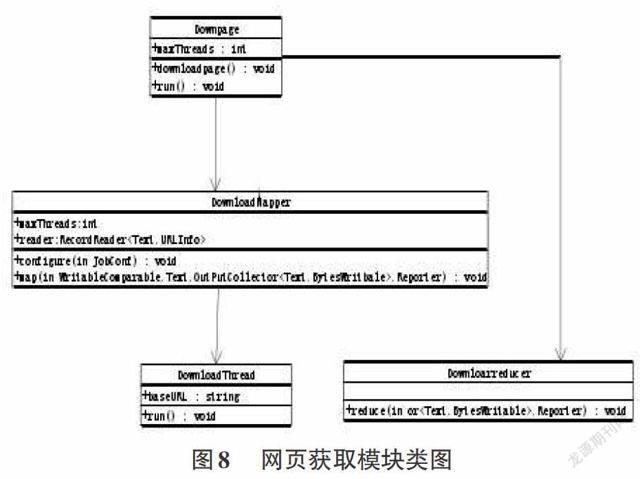
URL 分割注入模块简单,在此就不冗述,执行完URL 分割注入模块后即进入网页获取模块,此模块充分利用并行处理计算的能力,是爬虫的关键部分。此模块涉及四个类,四个类之间的关系如图8所示:
DownPage 类:实现 Tool 接口,是网页获取模块的入口,负责配置抓取任务和启动 Map/Reduce并行处理任务。
DownloadMapper 类:实现了 Mapper 接口中的 map()函数,即启动多个 DownloadThread 线程,将映射数据作为中间数据输出。
DownloadReducer 类:实现Reducer 接口中的 reduce()函数,即可接收 Map 输出的中间数据并对其进行合并。
DownloadThread 类:继承java.lang.Thread 类并实现多线程并发的网页下载。
2)网页解析模块
该网页解析模块包括了对不同类型数据的解析,首先进行读取抓获结果,然后进行类型判断,然后对不同的类型进行解析,解析类型包括HTML解析、Doc解析、PDF解析、PPT解析和Excel解析。
与网页获取模块一样都使用了Map/Reduce 计算模式,由三个类构成,分别是HtmlParser 类、ParseMapper 类和ParseReducer 类。 HtmlParser 类实现了tool接口,ParseMapper 类实现Mapper接口,ParseReducer 类实现reducer接口,其具体工作实现和网页获取模块类似。
3)链接去重过滤模块
由于检索到的网页中有很多是不合乎标准规范的链接,必须对这些链接进行相应处理,对不标准的链接进行规范化处理,对重复的链接进行去重处理。每一个过滤模块都包含这两个功能,且由单独的过滤器实现。其中规范化过滤是先把所有的字符串进行大小写统一转换,即大写转换为小写,然后删除无意义的字符。
4)数据存储更新模块
Hadoop 的文件系统HDFS是一个可以满足使数据存储在稳定且可以并发访问的系统,此模块包含三个类,分别是类 Update、类 URLInfo和类 HTMLPage。数据库的读写操作封装在update类中,类 URLInfo和类 HTMLPage实现Comparable 接口和readFields 、 write 方法。
5 总结
本文先从目前的海量数据搜索入手,阐述基于Hadoop 平台的分布式爬虫研究现状和研究意义,再而研究分析了与此相关的技术和理论,并提出了该爬虫技术的整体布局设计,并对系统的模块进行了划分,并对各模块的功能设计进行实现,用java语言实现了该分布式网络爬虫系统的开发。
参考文献:
[1] 陈俊,陈孝威.基于 Hadoop 建立云计算系统[J].贵州大学学报 (自然科学版),2011, 28(3).
[2] 程锦佳.基于 Hadoop 的分布式爬虫及其实现[D].北京邮电大学,2010.
[3] Evangelinos C, Hill C. Cloud Computing for parallel Scientific HPC Applications: Feasibility of running Coupled Atmosphere-Ocean Climate Models on Amazons EC2[J]. ratio,2008,2(2.40):2.34.
[4] 王俊生,施運梅,张仰森.基于 Hadoop 的分布式搜索引擎关键技术[J].北京信息科技大学学报(自然科学版),2011,04:53-56+61.
[5] IBM CLOUD [EB/OL].http://www.ibm.com/cloud-computing/us/en/
