基于罚分因子的论文相似度检测研究
2015-05-11韩雅清
韩雅清, 李 军, 钮 焱
(湖北工业大学计算机学院, 湖北 武汉 430068)
基于罚分因子的论文相似度检测研究
韩雅清, 李 军, 钮 焱
(湖北工业大学计算机学院, 湖北 武汉 430068)
提出一种特殊标记符和词根沙普利值二步骤分词模型,提高分词的准确率,通过搜索引擎指数来识别新词。在相似度比较方面,提出了带行列顺序罚分因子距离矩阵模型,该模型综合了向量检测、汉明距离和最长公共子串的特点,重新定义了距离矩阵。与传统的论文相似性检索相比,具有分词准确,计算量小等优点。
中文分词; 相似度比较; 距离矩阵
论文检测以相似度计算为基础,利用计算机自动计算文本间的相似度[1]。文本相似度的计算广泛应用于信息检索、机器翻译、自动问答系统、文本挖掘等领域,是一个非常基础而关键的问题,长期以来一直是人们研究的热点和难点[2]。
当前文本相似度检测的主要算法有:向量空间模型Vector Space Model(简称VSM)[3]、近似指数、隐性语义索引模型LSI(Latent Semantic Indexing)[4]、汉明距离[5]等。几种主要的检测方法存在一些问题[6],比如考虑了词在上下文中的统计特性,而没有考虑词本身的语义信息、未能很好地考虑不等长度的文本以及文本中分词顺序的影响、论文回溯查找出处存在着局限性等[7]。本文从分词及文本相似度研究入手,在总结分析主要的检测技术基础上,综合主要模型的优点,针对抄袭、换词、换序等几种主要手段进行了针对性的建模[8]。给出了一种基于特殊标记符的分词预处理和句级别的论文相似度比较模型。
1 基于特殊标识符的分词预处理
特殊标识符是在文本句子中具有特殊意义和作用的词或者是符号,由标点符号、单位符号、数学符号、数字符号、字母等非汉字类的标示符号以及汉字类的特殊标志词共同组成。本文的分词是基于特殊标识符的,因此在分词之前,需要建立汉字类和非汉字类的特殊标识符词典,然后按照以下步骤进行分词:1)对输入文本进行扫描,切分出文中的非汉字类特殊标识符;2)对上述结果进行再次扫描,切分出文中的汉字类特殊标识符。
对于上述分词结果,采用沙普利值模型进行优化。假设初步分词后某部分M需要进一步划分,S={a1,a2,…,an},ai为不同的切词组合(如一词根、二词根、三词根等),Pre_M为该部分的前置语义,Fol_M为该部分的后置语义,M中各个切词为合作博弈的关系,其划分的方式使得最后的N-GRAM值最大。Max{V(Pre_S)+V(S)+V(Fol_S)},依据Shapley定理,存在着唯一的一个价值函数:
(1)
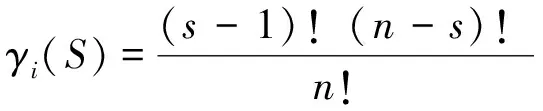
合作联盟成员所得利益分配值成为Shapley值,通常记作φ(v)=(φ1(v),φ2(v),φ3(v)…,φn(v)),其中φi(v)表示联盟中成员i的所得利益,用N-GRAM值来衡量,在不同的组合中,各个成员的收益不一样,以最大的句级N-GRAM值下为最终的分词结果。分词过程如图1所示。通过以上分析可以看出,本文采用的分词算法在特殊标记符分词的基础上,又利用沙普利值模型对分词结果进行了优化,将使分词准确率更高,取得更加满意的分词结果。
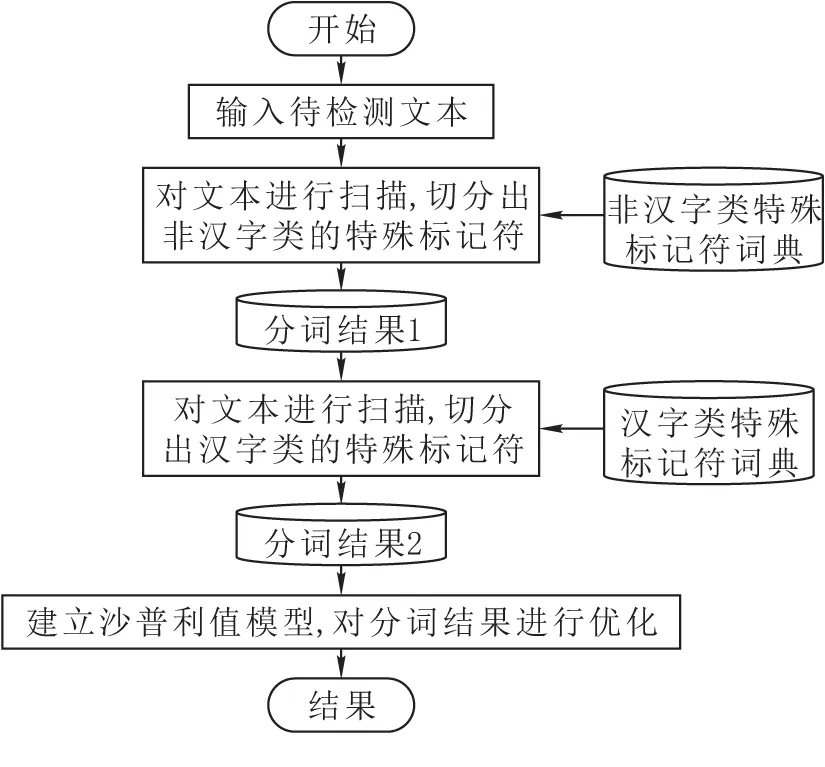
图1 基于特殊标记符的分词流程
2 基于带罚分因子距离矩阵模型的相似度计算
2.1 罚分因子
VSM模型(如TF-IDF方法等)综合考虑了不同的词在所有文本中的出现频率(TF值)和这个词对不同文本的分辨能力(IDF值),将文档信息的匹配问题转化为向量空间中的矢量匹配问题。汉明距离采用模2加运算,完全避开了在欧氏空间中求相似度的大量乘法运算,计算速度较快。这几种方法具有各自的优点,但也存在着回溯慢、文本分词顺序未考虑等问题,例如:a)“词汇之间的搭配方式繁多”b)“搭配的词汇种类繁多”c)“英文词汇之间的搭配繁多”,若不考虑顺序,三种方式VSM和汉明距离以及最长公共子串相似度接近,但显然a、c之间比a、b之间意思更为接近,因此,在比较句级别的相似性时考虑词汇顺序的影响,将带来更为满意的结果。
基于这样的考虑,本文提出了罚分因子的概念,其作用就是在计算相似度的时候将词语的顺序因素考虑进来,使得相似度的计算结果更加准确。罚分因子建立步骤如下:
步骤一:建立句分词向量,将待检测论文和比较论文以句为单位分词,得到了逐句的句分词向量LA={A1,A2,A3,…,An}和LB={B1,B2,B3,…,Bn},得到了2个矢量,元素个数不同可用空词补齐。计算:
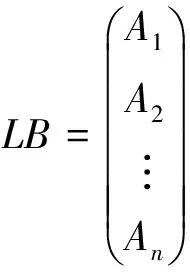
(2)
其中,|LA′⊗LB|代表了2个句中相同分词的最大个数,类似于最长公共子串,但不同于最长公共子串的是该方法考虑了多个相同的子串带来的影响。LA′⊗LB结果将得到n×n的稀疏矩阵,2个分词向量在相乘时采用~xor异或乘法,在分词元素作乘法时,若为相同分词结果为1,不同分词结果为0。
步骤二:对矩阵中的非零元素分别按行统计,统计出每行第一个非零元素的列号,并形成集合,构造成列序表TA,代表着待检测文本和句料库文本间最长公共子串的分词顺序。若令句料库中的分词序号默认为(1,2,3,4,5),即原始句的分词顺序为TB={1,2,3,4,5},则对TA和TB2个数列用函数f(TA,TB)来计算罚分因子,此时将采用欧氏距离。f(TA,TB)定义如下:
f(TA,TB)=sqrt(∑|TAi-TBi|2)
(3)
其中i表示TA和TB中的第i个元素,n表示TA和TB中元素的个数,其计算结果作为罚分因子。
2.2 相似度计算
通过上节的分析和介绍,我们得出了罚分因子的概念和作用,在此基础上对分词结果进行建模,并计算相似度。本文提出的基于带行列顺序罚分因子的距离矩阵模型,它兼具有VSM和汉明距离以及最长公共子串3种模型的特点,通过不同的参数配置,可以实现这3种模型的转化。文中,相似度的计算将采用以下公式
Sim(LA′,LB′)=
(4)
其中,如果将f(A,B)设为1,不考虑顺序,则该模型演变成Dice系数VSM模型,在此基础上若不考虑每个分词的权重值以及顺序,并设定分词之间的乘法为与运算规则,则演变成了汉明距离模型。该模型中,k代表与矢量长度相关的常数,如果设定
并取出顺序相同的最长连续分词个数作为秩,通过补齐的方式设定为固定长度文本比较,每个分词设定为1(不考虑权重),不考虑顺序,则该模型演变为最长公共子串。若考虑顺序,则结果为受顺序罚分因子影响的最长公共子串。
3 实验结果及仿真
3.1 分词预处理
随机选取了一个新闻网页,并将其文字按照我们的分词模型进行了单独的分词。在图2中,第一步是按特殊标记符后分词的结果,第二步表明了基于沙普利值的切词方式后的结果,经过2步的分词,分词准确率达到了满意的效果。
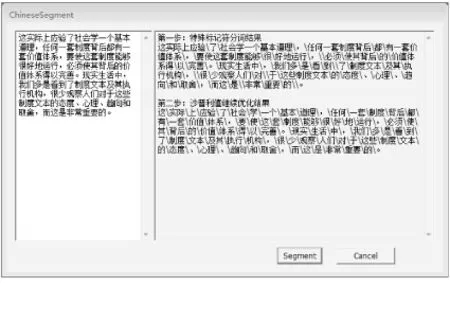
图2 特殊标记符和沙普利值优化后的结果
3.2 考虑顺序因素的相似度比较模型研究
实验中,选取如下句子进行分析:
原始句Ps: 大家是世界的希望和未来
待检测句Pa: 大家是世界的未来和希望
待检测句Pb: 希望未来的世界是大家的
原始句Ps在句料库中的结果如下:
大家 是 世界 希望 未来
150 503 204 350 180
经过分词预处理后,各句的ID如下:
Ps= [150*503*204*350*180];
Pa= [150*503*204*180*350];
Pb= [350*180*204*503*150];
‘*’标识中间可能存在的其他分词,经过异或乘法处理后,不相同的分词为全0的行,剔除后可得到如下的矩阵:

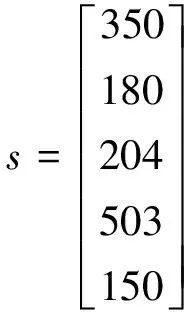
按行统计矩阵中的非0行元素顺序可得到句a比较后的行距离向量为:(1 2 3 5 4),同理句b比较后的行距离向量为:(4 5 3 2 1),设定原始句子的顺序为:(1 2 3 4 5)。经过Matlab仿真运行后,三个行向量的分词顺序曲线如图3所示。进一步比较3个曲线的欧氏距离见图4、图5。
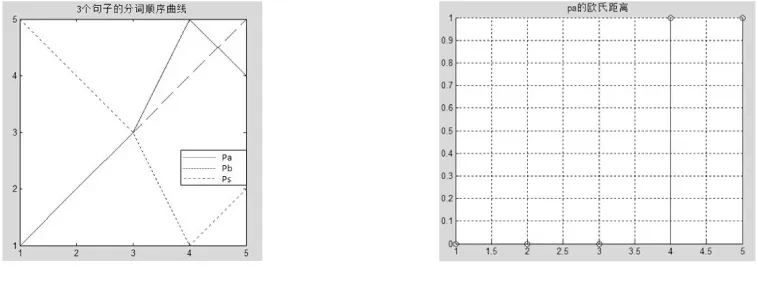
图3 三个句子的分词顺序曲线 图4pa向量与原始分词向量的欧氏距离
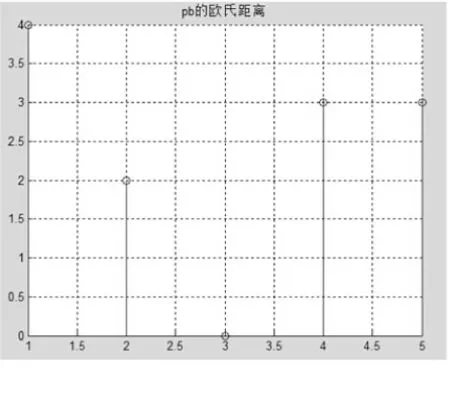
图5 pb向量与原始分词向量的欧氏距离
经过计算f(pa,s)后的结果为:1.4142,经过计算f(pb,s)后的结果为:6.1644。在分词相同个数一样的情况下,pa的罚分因子更小,说明pa与s更为相似,显然与人工评估结果一致。
4 结束语
本文提出了基于特殊标识符的分词算法及新词的搜索引擎识别评估模型。句级别的相似度比较模型,能够演化为3种主要的相似度检测算法。并在模型中增加了顺序罚分因子、近义词处理的方法,能有效的应对添减词、部分顺序抄袭和替换词等常见手段。经过实验可以看出,该方法能够对论文的相似性给出准确的评估结果。但由于对大规模的论文检测需要大量的词库和数据预处理,以及建立大规模的检索库,在实现推广上需要更多的统一规范才能取得较好的推广效果。
[1]ChenFei,WangXiufeng,RaoYimei.AhybridapproachtoChinesewordsegmentation[C].TianJin,ActaScientiarumNaturallumofUniversitatisNakaiensis,2000(05):27-32.
[2] 桓乐乐. 基于马尔科夫模型的文本相似度研究[D].武汉:湖北工业大学,2011.
[3] 周凤玲. 基于向量空间模型的方面挖掘方法研究[D].哈尔滨:哈尔滨工程大学,2013.
[4] 王春红,张 敏. 隐含语义索引模型的分析与研究.计算机应用,2007(05):1 283-1 285,1 288.
[5] 张焕炯、王国胜.基于汉明距离的文本相似度计算[J].计算机工程与应用,2001,19:21-22.
[6]ZhangChunxia,HaoTianyong.Thestateoftheartanddifficultiesinautomaticchinesewordsegmentation[J].JournalofSystemSimulation,2005(10): 138-143,147.
[7] 徐 波,孙茂松.中文信息处理若干重要问题[M].北京:科学出版社,2003:168-172.
[8]LiQinghu,ChenYujian,SunJiaguang.AnewdictionarymechanismforChinesewordsegmentation[J].JournalofChineseInformationProcessing,2003(04)17-19.
[责任编校: 张岩芳]
The Paper Similarity Detection Method Based on the Penalty Factor
HAN Yaqing,LI Jun, NIU Yan
(SchoolofComputerSci.,HubeiUniv.ofTech.,Wuhan430068,China)
A two-step segmentation model of special identifier and root Sharpley value was proposed in this paper, which can improve the segmentation accuracy and recognize new words through the search engine exponent. For comparing the similarity, a distance matrix model with row-column order penalty factor was proposed. This model integrates the characteristics of vector detection, hamming distance and the longest common substring, redefining distance matrix. Compared with the traditional paper similarity retrieval, the present method has advantages in the accuracy of word segmentation, low computation, reliability and high efficiency.
Chinese segmentation; similarity comparison; Ddistance matrix
2014-10-09
湖北省教育厅科学研究计划资助项目(D20141403 )
韩雅清(1987-), 女,湖北宜昌人,湖北工业大学硕士研究生,研究方向为信息处理
1003-4684(2015)01-0036-04
TP393
A
