基于语义扩展的句子相似度算法
2015-05-10冶忠林贾真杨燕尹红风
冶忠林,贾真*,杨燕,尹红风
(1.西南交通大学 信息科学与技术学院,成都 611756;2.DOCOMO Innovations公司,帕罗奥图 美国 94304)
0 引言
句子相似度计算是自然语言处理领域中比较基础而重要的研究课题,它在现实中有广泛的应用。在信息检索领域,句子相似度计算方法用来对检索结果进行排序。在问答系统领域,需要使用相似度方法对用户所提问题和系统知识库中的问题进行比较,找到问题的最佳匹配从而返回最佳答案。在机器翻译领域,通过计算句子的相似度来匹配相似的句子,找出相似的翻译。
Palakorn等 总结了三类计算句子相似度的算法,对当前主要的算法进行了分类,同时分析了各种方法的原理并将它们进行了对比。汉语和英语句子的相似度计算有很大的差别,因为英语是基于语法的句子,而汉语是基于语义的句子,因此,在计算句子相似度时,英语句子相似度是从句子的依存关系、词语距离方面考虑两个长字符串的匹配程度,而汉语句子是从组成句子的词性、词义及整个句子的语义角度考虑。在国外,计算句子相似度主要有基于距离及其扩展算法的相似度模糊匹配[3]、MCWPA字符串快速比较算法[4]、最长公共子序列算法[5]等,这些算法都是基于字符串的比较和处理。比如,最长公共子序列算法就是通过求两个英语句子中公共的子串来计算相似度。在国内,汉语言自然语言句子的相似度研究也取得了很多成果。例如,Yin[6]在向量空间模型的基础上提出了一种同时考虑句子结构和语义信息的关系向量模型。吴佐衍等[7]利用概念层次网络理论词汇层面联想的概念表述体系来计算词语之间的相似度。李彬等[8]提出了基于语义依存关系的汉语句子相似度计算方法。此方法基于董强和董振东先生创建的《知网》知识资源,首先采用哈尔滨工业大学计算机科学与技术学院信息检索研究室所做的依存句法分析器建立句子依存树,然后利用依存结构计算有效搭配对之间的相似程度。该方法测试结果的准确率严重依赖于所生成的句法依存树,在分析句子较长、动词较多的网络文章时,正确率常常比较低。李茹等[9]提出了基于汉语框架网语义资源,通过多框架语义分析、框架的重要度度量、框架的相似匹配、框架间相似度计算等关键步骤来实现句子语义的相似度度量。张奇等[10]通过回归方法将uni-gram、bi-gram、tri-gram几种相似度结果综合起来,提出了一种新的句子相似度度量方法并应用于文本自动摘要中。
本文提出了一种基于语义扩展的句子相似度计算方法。首先,利用现有的搜索引擎技术,对句子进行语义扩展得到与句子相关的长文本;其次,使用特征提取获得长文本的特征项及分布概率,将句子转化为具有与句子含有相同语义的特征项组;再次,取两个特征项的交集,利用其分布概率建立向量空间模型,求得向量的夹角的余弦值即为相似度值。因此,本文提出的方法将句子相似度的计算从词形、词序、词义、依存关系的理解转移到对句子语义间的相似度计算,从而减少在相似度计算时对句子语义的歧义理解。
1 基于语义扩展的句子相似度算法介绍
1.1 算法原理
现有的计算句子相似度的方法仅仅从词形、词序、句子结构、依存关系等方面考虑句子表面的信息,没有尝试去理解句子的隐含语义。比如,基于空间向量的句子相似度算法把词当作一个维度,于是,一个句子的每个词以及词的权重就构成了一个n维空间图,那么求两个句子的相似度,也就是求两个空间图的接近度。
本文放弃了对句子的词形、词序、句子结构、依存关系的分析,而考虑句子所隐含的语义特征,类似于知网中的义原,即利用搜索引擎,对句子进行知识扩展,挖掘出更多与句子相关的知识文本,如此,一条较短的句子扩展为一个较长的文本,进而将句子之间的相似度计算转化为文本之间的相似度计算。相较于短句子,长文本具有大量的信息可以利用,更加有利于计算相似度。然后使用潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)模型,对扩展后的文本进行特征提取,获得该文本的主要内容,即特征词以及特征词在主题空间上的概率分布,最后将特征词转化为向量空间模型,计算取交集后两个共同部分的向量之间的夹角的余弦值,该值即为两个句子的相似度。
本文中的相似度计算算法主要由以下三个步骤组成:
(1)知识扩展:基于搜索引擎的句子内容扩展;
(2)特征提取:基于LDA的特征提取;
(3)向量空间模型建立:将特征项转化为向量模型。
1.1.1 知识扩展
知识扩展是对句子语义的深度理解,对一个句子单独地进行语义理解具有很高的难度,但是如果将一个句子的语义转化为文本,可有效地利用现有的知识挖掘算法对该文本进行特征提取,这有助于对句子语义进行分析。由于搜索引擎返回的页面与所要查询的问题高度相关,所以在搜索引擎中,由页面排序算法可知,排名越靠前的网页标题和摘要信息与查询语句越相关。
本文首先利用搜索引擎下载与句子相关的前100个页面的标题和摘要,然后组成一个长文本,之后去除大文本中的干扰词和噪音信息。其中干扰词包括停用词和搜索引擎中经常出现的词语,比如“问答”、“搜索”、“了解”等词语。噪音信息包括组成网页的HTML语言、CSS视图层、JAVASCRIPT等。
例如,对于句子T1={“西红柿是什么颜色”},利用搜索引擎进行知识扩展得到大文本,然后去干扰词、噪音、分词处理后结果如表1所示。

表1 知识扩展返回的大文本Table 1 Long text after knowledge extension
1.1.2 特征提取
特征提取就是对知识扩展后的大文本提取特征。本文使用LDA进行特征提取。
对于句子T1={“西红柿是什么颜色”}和T2={“番茄是什么颜色”},知识扩展后,获得大文本,之后进行特征提取,根据经验值,设置主题个数为1,取分布概率最高的5个特征项作为句子的特征项。如表2所示:

表2 LDA模型特征项提取Table 2 Features extraction by LDA model
通过LDA特征提取之后,句子可用表2中的特征项表示,即句子的语义可以用特征项表示。因此,两个句子的相似度可以通过特征项的相似度来表示。
1.1.3 空间向量模型建立
空间向量中,文档中的每个词可以当作一个维度,而词的频率作为该维度的值,即向量,于是文档中的每个词和词频就构成了一个多维空间图。求两个文档的相似度就是求两个空间图的接近度,即距离。在信息检索中,常用的计算距离的方式有余弦相似度计算、相关系数、Dice、Jaccard等。本文使用余弦相似度求两个文本的相似度。
当获取了特征项组一和特征项组二(表2所示)之后,需要做交集运算,找出两个特征组向量的共同部分。因为该共同部分虽然特征项相同,但是相同特征项的分布概率却不同,因此取交集运算后得到两个向量长度相同但分布概率不同的向量IP1和IP2。之后计算这两个向量的夹角的余弦值。
例如 表2中,IP1={0.143 6,0.114 9,0.023 7,0.017 1,0.008 8},IP2={0.123 9,0.100 8,0.049 9,0.017 4,0.008 8},则S(T1,T2)=S(IP1,IP2)=cosθ,其中θ为IP1和IP2的夹角。综上,利用空间向量模型,可以将两个句子的相似度计算转化为句子特征项向量的夹角余弦值的计算。
1.2 算法定义
为了便于说明算法,此处对文章中所用到的概念作如下定义。
定义1 句子向量:对于一个句子s使用分词系统,可得到该句子的分词结果,该结果有一个或多个词w构成,得到的所有词wi构成的句子向量叫作句子Si的向量表示,即:Si={w1,w2,…,wn}。
例如 s1:刘德华出演过哪些电影。s2:刘德华的电影有哪些。经过西南交通大学汉语分词系统分词之后,s1:刘德华/nr出演/v过/uguo哪些/ry电影/n。s2:刘德华/nr的/ude1电影/n有/vyou哪些/ry。那么,s1和s2的向量形式为:
S1={刘德华,出演,过,哪些,电影},S2={刘德华,的,电影,有,哪些}。
定义2 句子向量长度:对于Si,如果可用向量的形式表示,那么Si中单词的数量为句子Si的向量长度,即句子Si的向量长度可表示为len(Si)。
例如 对于定义1中的两个句子s1和s2,有:len(S1)=5,len(S2)=5。
定义3 扩展向量表:对于已经分词的句子s1和s2,并且len(S1)>0,len(S2)>0,利用搜索引擎的知识扩展和理解功能,将句子向量表输入到搜索引擎,可获得相关的知识,去除停用词、干扰词,然后使用主题模型进行建模学习,可获得与句子s1和s2的相关词wi与词wi概率分布pi。同时,词wi的向量组成称为扩展向量表Ri,词的概率分布pi组成的向量表称为词的概率分布向量表Pi。即:Ri={w1,w2,…,wn},Pi={p1,p2,…,pn}。
例如 对于定义1中的两个句子s1和s2,利用所有引擎进行扩展,然后使用LDA模型进行建模,最终得到5个推荐词,且在主题空间中分布概率最高,则R1={刘德华,电影,演,出演,拍},R2={刘德华,电影,演,片,出演},P1={0.168 8,0.144 6,0.062 1,0.051 6,0.019 6},P2={0.170 8,0.142 1,0.020 0,0.0118,0.009 8}。
定义4 交集向量表:已知扩展向量表R1和R2,如果R1和R2有相同的单词wi,并且len(R1)>0,len(R2)>0,那么,求得向量R1和R2的交集的结果称为两个句子的交集向量表IR,因为IR中的每个词有2个不同的分布概率,所以与之相对应的分布概率记为IP1和IP2。即:
IR=R1∩R2={w1,w2,…,wn},IP1={p11,p12,…,p1n},IP2={p21,p22,…,p2n}。
例如 对于定义3中的两个扩展向量表R1和R2,有IR=R1∩R2={刘德华,电影,演},其中IP1={0.168 8,0.144 6,0.062 1},IP2={0.170 8,0.142 1,0.020 0}。
该节中,对计算句子相似度的相关概念及下小节中要出现的数学符号做出了定义,比如句子s、句子向量表Si、扩展向量表Ri、交集向量表IR、概率分布向量表Pi以及IP1和IP2等。
1.3 算法过程
语义扩展的句子相似度算法利用搜索引擎,扩展句子的语义信息,然后使用LDA模型,获得主题空间上分布概率较高的某些词wi,同时获得词的分布概率pi,随后获取两个句子的交集向量表IR、概率分布向量表Pi以及IP1和IP2,最后使用IP1和IP2建立向量空间模型,计算向量IP1和向量IP2的夹角的余弦。
在向量空间模型中,计算两个语句s1,s2的相似度Sim(s1,s2)时,常用向量之间的夹角的余弦值表示,所以在该小节中,计算语句s1,s2的相似度Sim(s1,s2)可认为是计算向量IP1和向量IP2的夹角的余弦值。具体公式如下:
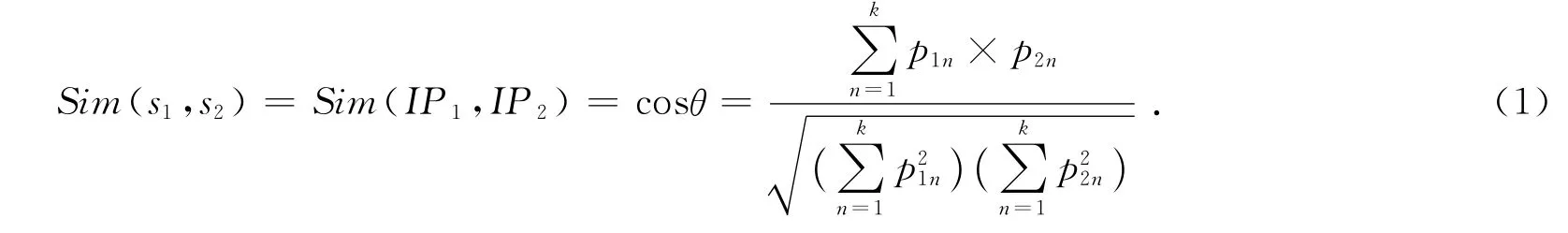
当len(IR)=0时,Sim(s1,s2)=0。
当len(IR)=len(R1)=len(R2)时,Sim(s1,s2)=1。
其中,θ表示向量IP1与向量IP2之间的夹角,p1n为向量IP1中的每一个概率值,p2n为向量IP2中的每一个概率值,k为交集向量表IR中词的个数。
算法伪代码如下:

在1.2中S1={刘德华,出演,过,哪些,电影},S2={刘德华,的,电影,有,哪些},R1={刘德华,电影,演,出演,拍},R2={刘德华,电影,演,片,出演},P1={0.168 8,0.144 6,0.062 1,0.051 6,0.019 6},P2={0.170 8,0.142 1,0.020 0,0.011 8,0.009 8},IR=R1∩R2={刘德华,电影,演},其中IP1={0.168 8,0.144 6,0.062 1},IP2={0.170 8,0.142 1,0.020 0}。则使用公式1计算句子s1与句子s2之间的相似度为:
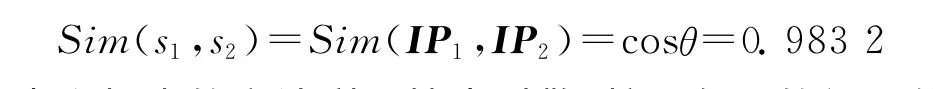
从上面分析中可以看出,本文提出的方法利用搜索引擎,扩展句子的语义信息,类似于知网中的义原,所以当两个句子高度相似时,其扩展后的语义也高度相似,如果当两个句子高度不相似时,其扩展后的语义则相差很大。综上,考虑句子语义扩展的相似度算法可以准确地计算出两个句子之间的相似度,并且可以解决其他句子相似度算法中两个毫无相关的句子相似度很高的现象。另外,本文提出的方法只对两个扩展向量表中的交集向量表IR进行相似度计算,所以能在一定程度上降低运算的时间复杂度。
2 实验结果分析
在该小节,使用2个实验进行算法效果对比。实验一是本文提出的方法与文献[11]提出句子相似度计算方法做比较,同时给出其他常用的相似度计算方法的值。在实验一中,测试了3组句子,每组句子有1个源句子和5个相似的句子构成且与源句子的相似度依次递减。实验二使用Li和David[12]提出的实验方法进行比较,从当前的网络新闻中收集了教育、科技、健康、军事、旅游等10大类新闻文本组成10个测试样本集,每个测试样本集约50个句子,共500个句子。我们从10个测试样本集中随意抽取1条目标语句,然后人工的找出与目标句子语义比较相近的3个测试句子组成一组,即共10组句子,每组1个目标句子,3个测试句子,共40条句子。
2.1 实验一
为了和其他算法进行对比,本文计算了基于语义和词序的句子相似度值、基于词语共现模型的相似度值、基于词类串句子相似度值。
方法1:本文方法。
方法2:基于本文知识扩展的方法,但是使用TF-IDF模型获取大文本的特征词和特征词的词频。
方法3基于词语共现模型的句子相似度计算方法
方法4:基于词类串的汉语句子结构相似度计算方法[14]。
方式5:基于语义和词序的句子相似度计算方法[15]。
关于以上5种方法的句子相似度结果如表3所示。
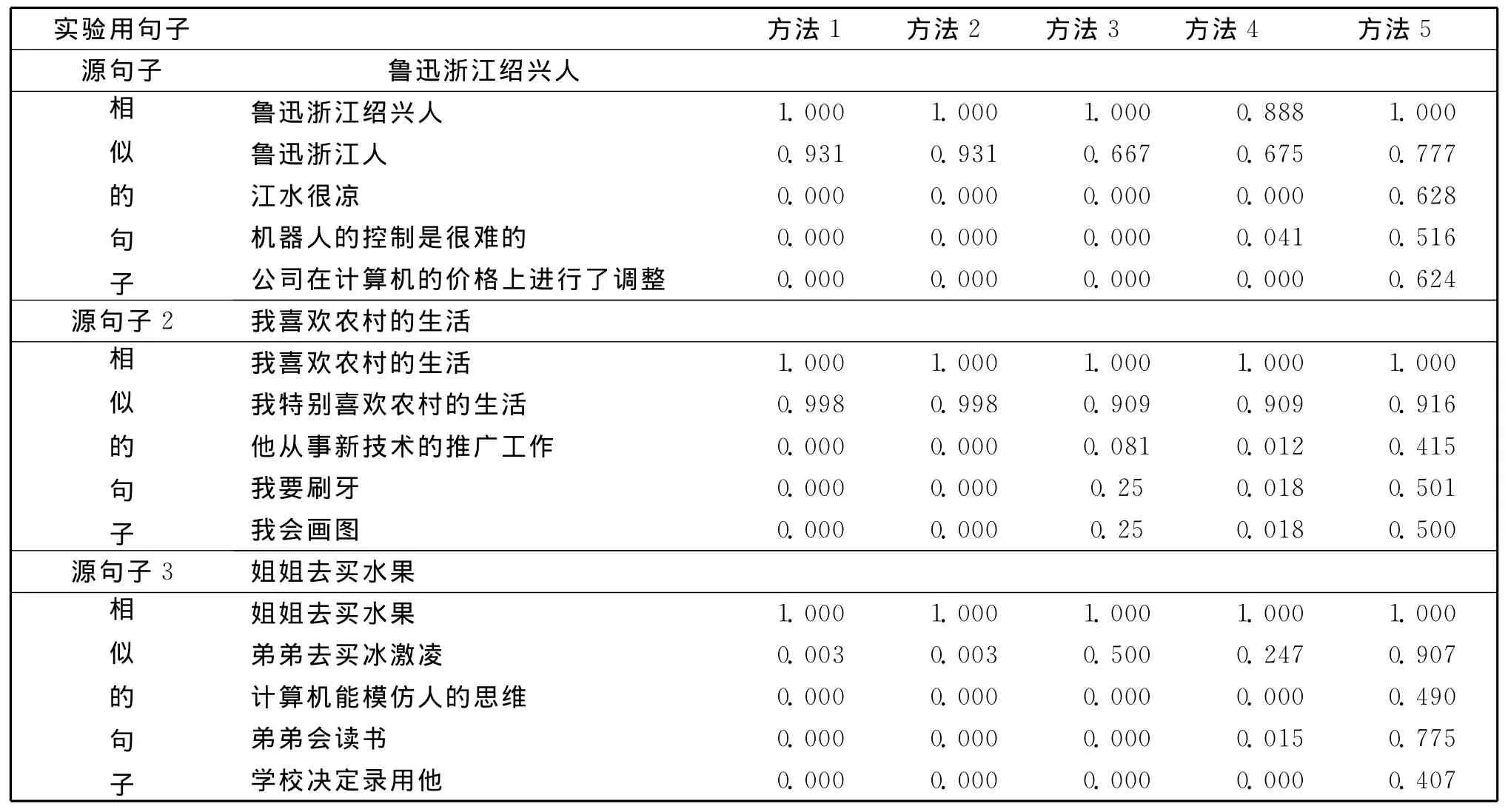
表3 句子相似度计算结果对照表Table 3 Result comparison in different sentence similarity computing method
从表3中看以得出,当两个句子相似度很高时,基于本文的方法1和方法2,可以得到一个较高的相似度值,当两个句子相似度很低时,本文的方法计算所得的相似度值符合常识。方法3、4在实验一中,也具有较好的实验结果,方法5中当两个句子相似时,效果较好,但是当两个句子不相似时,却出现相似度值比较高的情况。
2.2 实验二
实验二中,有10个测试样本集和10组句子,每组句子有1个目标句子和3个测试句子组成。10个样本测试集的文本类别和10组句子的文本类别是相对应的。使用本文提出的方法,使用1个目标句子在其对应类别的样本测试集中计算句子相似度,取相似度最高的3条句子,然后和10组句子中的测试句子相比较。如果通过本文计算相似度方法得到的句子与人工方式找到的测试语句相同,则认为本文的方法有效。表4是采用不同的句子相似度算法获取相似度最高的3条句子,然后和人工选出的3条句子对比后的准确率,共有10个样本集,因此测试句子和人工选出的句子共有30条。

表4 实验二结果Table 4 Second experiment’s result
从表4可以发现,在近500条的句子的测试过程中,基于句子语义扩展的算法其准确率达到0.87,基于词语共现模型的相似度算法的准确率为0.63,而基于语义和词序相似度算法准确率却比较低。主要原因是,在实验二中,目标语句与3条相似语句之间语义很接近,所以在语句的词语构成上,词语共现的频率就会提高,因此基于词语共现的相似度算法在该类数据集上表现较好。而基于语义和词序的相似度算法,由于词语相似度计算的准确率受限,所以句子相似度值准确率较差。基于句子语义扩展的方法,通过搜索引擎进行语义理解,找出与句子含有相同语义的更多特征词组,所以能够获得符合常识的相似度计算结果。
3 结束语
本文提出了一种基于语义扩展的句子相似度算法,将句子相似度的计算从词形、词序、词的语义、依存关系的理解转移到对句子语义的理解上,依托强大的搜索引擎的页面推荐功能,能够将简单的句子进行语义扩展,从而解决句子特征词稀疏问题,提升句子相似度计算的准确性。实验表明,与基于词语共现模型、语义和词序的相似度方法、词类串的汉语句子结构相似度计算方法相比,本文的方法对相似度很高的句子可有效地找出其中的关联,计算出准确的相似度,对于相似度很低的句子,由于其隐含的语义相差很大,所以本文计算出来的相似度值很低,因此,基于句子语义扩展的方法计算所得的值符合常识判断。
[1] Zhang H,Yu Z,Shen L,et al.Naxi Sentence Similarity Calculation Based on Improved Chunking Edit-distance[J].International Journal of Wireless and Mobile Computing,2014,7(1):48-53.
[2] Palakor A,Hu X H,Shen X J.The Evaluation of Sentence Similarity Measures[C]//Proceedings of the 10th International Conference on Data Warehousing and Knowledge Discovery,Stroudsburg:Association for Computational Linguistics,2008:305-316.
[3] Liu X,Zhou Y,Zheng R.Sentence Similarity Based on Dynamic Time Warping[C]//Semantic Computing,2007.ICSC 2007.International Conference on.Irvine:IEEE,2007:250-256.
[4] Chan T P,Callison-Burch C,Van Durme B.Reranking Bilingually Extracted Paraphrases Using Monolingual Distributional Similarity[C]//Proceedings of the GEMS 2011 Workshop on GEometrical Models of Natural Language Semantics.New York:Association for Computational Linguistics,2011:33-42.
[5] Li L,Hu X,Hu B Y,et al.Measuring Sentence Similarity from Different Aspects[C]//Machine Learning and Cybernetics,2009 International Conference on.Baoding:IEEE,2009,4:2244-2249.
[6] Yin Y M,Zhang D Z.Sentence Similarity Computing Based on Reation Vector Model.Computer Engineering and Applications[J],2014,50(2):198-203.
[7] 吴佐衍,王宇.基于 HNC理论和依存句法的句子相似度计算[J].计算机工程与应用,2014,50(3):97-103.
[8] 李彬,刘挺,秦兵,等.基于语义依存的汉语句子相似度计算[J].计算机应用研究,2013,20(12):15-17.
[9] 李茹,王智强,李双红,等.基于框架语义分析的汉语句子相似度计算[J].计算机研究与发展,2013,50(8):1728-1736.
[10] 张奇,黄萱菁,吴立德.一种新的句子相似度度量及其在文本自动摘要中的应用[J].中文信息学报,2004,19(2):93-99.
[11] 陈海燕.基于搜索引擎的词汇语义相似度计算方法[J].计算机科学,2015,42(1):261-267.
[12] Li Y H,David M.Sentence Similarity Based on Semantic Nets and Corpus Statistics[J].IEEE Transactions on Knowledge and Data Engineering,2006:1138-1150.
[13] Ahsaee M G,Naghibzadeh M,Naeini S E Y.Semantic Similarity Assessment of Words Using Weighted Word Net[J].International Journal of Machine Learning and Cybernetics,2014,5(3):479-490.
[14] Huang X,Zhang J,Chen H,et al.Research on Text Similarity Algorithm Based on Sentence Semantic Clustering[J].Journal of Computational Information Systems,2014,10(8):3163-3170.
[15] O’Shea K.An Approach to Conversational Agent Design Using Semantic Sentence Similarity[J].Applied Intelligence,2012,37(4):558-568.
