一种基于线性时间概率计数算法的数据聚集技术*
2015-05-09应可珍邬锦彬戴国勇苗春雨范聪玲陈庆章
应可珍,邬锦彬,戴国勇苗春雨,范聪玲,陈庆章*
(1.浙江工业大学计算机科学与技术学院,杭州 310014;2.浙江财经大学东方学院,浙江 海宁 314408)
一种基于线性时间概率计数算法的数据聚集技术*
应可珍1,2,邬锦彬1,戴国勇1苗春雨1,范聪玲1,陈庆章1*
(1.浙江工业大学计算机科学与技术学院,杭州 310014;2.浙江财经大学东方学院,浙江 海宁 314408)
无线传感器网络中,通过数据聚集操作在中间节点预先对数据进行处理,可去除大量冗余,减少数据传输,实现节能。针对多路径路由下数据聚集操作的重复计数问题,研究对副本不敏感的概要结构并优化某些特性,在线性时间概率计数算法的数学模型基础上提出一种新的数据聚集技术FA(Fan Aggregation)技术,实现高能效的数据聚集。理论分析和仿真实验均表明,FA技术相较于FM(Flajolet Martin)技术和LC(Linear Counting)技术在存储空间和准确率上均有更好的性能体现。
无线传感器网络;数据聚集;概要结构;重复计数
无线传感器网络为人类提供了一种新的感知世界的方式[1]。人类可以在军事、医疗、环境监测等领域方便地开展各项活动。这些活动中,对各项数据的收集、传输、存储和分析至关重要。其中数据收集模式[2-3]主要包括基于查询、周期汇报和事件汇报等。基于查询形式的数据收集仅当查询下令时,网络中的节点才会执行数据收集工作,并将数据收集的结果反馈给基站或用户。而数据聚集查询则是基于查询模式的其中一种数据收集方式,这里统一用“数据聚集技术”来描述。在查询过程中直接将所有原始数据传到基站集中处理,此时各节点大量的冗余数据不仅使传输效率低下且更为耗能。为了降低数据传输量,一种方式是在数据采集时即进行压缩处理,如压缩感知技术[4];另外一种方式是在数据传输时对数据进行处理,减少数据的传输量。如在路由的同时由中间节点先对数据进行聚集操作,过滤冗余数据,再将结果转发给父节点,这种也称为网内聚集[5-7]。聚集操作主要包括求和(SUM)、计数(COUNT)、最大值(MAX)、最小值(MIN)、求平均(AVERAGE)乃至求中位数(MEDIAN)等。目前对于数据聚集技术的研究是无线传感器网络的研究热点之一[2]。
1 数据聚集技术概述
在进行聚集操作时,Madden[8]等人研究了基于树型拓扑结构的高效数据聚集算法,聚集计算由叶节点沿着路由树传递给父节点,逐层向上进行,最后由根节点计算出整个网络的聚集值。但是由于节点间通信的不稳定性,丢包时有发生,因而导致聚集结果不准确。为了避免这种情况,多路径路由[9]技术应运而生,事件区域的数据可以在算法所形成的多路径上进行数据包的发送[10-11]。各节点将中间结果发给多个邻居节点,使得节点读数的多个副本在网络中传输,造成部分节点数据被重复计算。对于某些对副本敏感的操作(如SUM、COUNT、AGERAGE等)会使得最后的聚集结果不准确。为了避免副本的影响,文献[9]及文献[12-14]提出一种对副本不敏感的概要结构,采用这种结构可避免节点值被重复计算,即为扩散性概要聚集技术(Synopsis Diffusion)。这些技术主要包括两类,一是Flajolet和Martin等人在1985年提出的概率计数算法[15]基础上产生的数据聚集技术,此种记为FM技术。二是在Whang等人于1990年提出的线性时间概率计数算法[16]基础上产生的线性计算(Linear Counting)技术,此种记为LC技术。采用以上技术均可从多重数据集中估算出不重复的数据集的个数。
对FM技术,需同时使用多个独立的概要结构,再对其取平均值从而产生较为精确的估计值。精确度与概要结构的数量成正比。然而多个概要结构增加了各节点的存储空间需求,而少量的概要结构却导致精度不高的问题。LC技术只适合小数据聚集。它通过线性的方式将各元素映射到LC概要结构上,每一次聚集均会产生相应长度的位相量,如果是大数据的聚集,会占用大量的存储空间,因而不适用。
针对这种情况,本文在线性时间概率计数算法的数学模型以及基于该模型的现有的LC技术基础上提出一种新的对副本不敏感的技术即FA(Fan Aggregation)技术,利用FA概要结构来表示节点值和中间聚集值,并用于聚集操作和计算。
2 FA技术
2.1 网络定义和问题描述
本研究的网络模型如图1所示,假定为由一个基站和一组传感器组成。该网络具有如下特征:①每个节点都有足够的处理能力和存储空间;②网络同步性高,无通信延迟;③节点间逐层侦听,第i层节点侦听i+1层节点发送的信息直至基站。
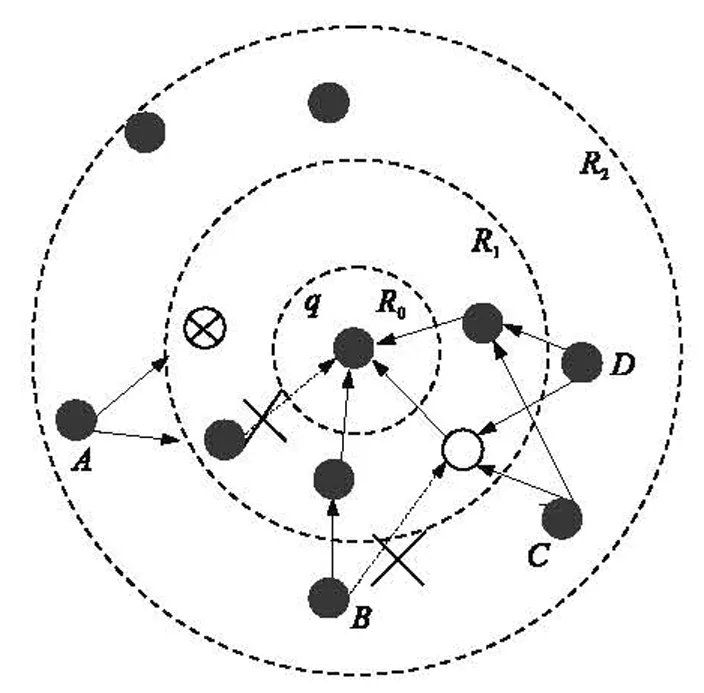
图1 环形拓扑结下的Synopsis Diffusion
假设传感网络S由k个节点组成,用{ui|1≤i≤k}表示,在每个时间戳里,各节点ui从整数值域为[D]={0,…,D-1}里读取一次数值vi;用以聚集操作的聚集函数是可分解的f如Sum,Avg和Count;精度由一对参数(ε,δ),0≤ε≤1,0≤δ≤1来保证,即聚集操作的近似误差在ε内的概率是1-δ。
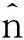
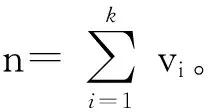
2.2 FA的数据结构和基本操作
如下定义1针对FA概要结构进行了具体定义。
定义1FA概要结构由一对参数(ε,δ)保证精度,由d个长度为li的数组FA[i]组成:
FA[0][0],…,FA[0][l1-1]
FA[1][0],…,FA[1][l2-1]
⋮
FA[d-1][0],…,FA[d-1][ld-1]
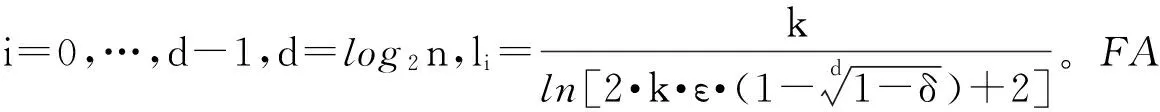
①FA结构中的传感器读值表示
对于一个传感器节点u,其读值v用二进制数来表示,其中最右边末位标记为第0比特位。对于i=0,…,d-1,若有FA[i]=1,则节点u在[0,li-1]内相应产生一个整数j,并有FA[i][j]=1。图2中,v=11,用二进制表示为(1011)2,那么就在FA[0]、FA[1]、FA[3]3个比特位里分别随机设置一个1位。
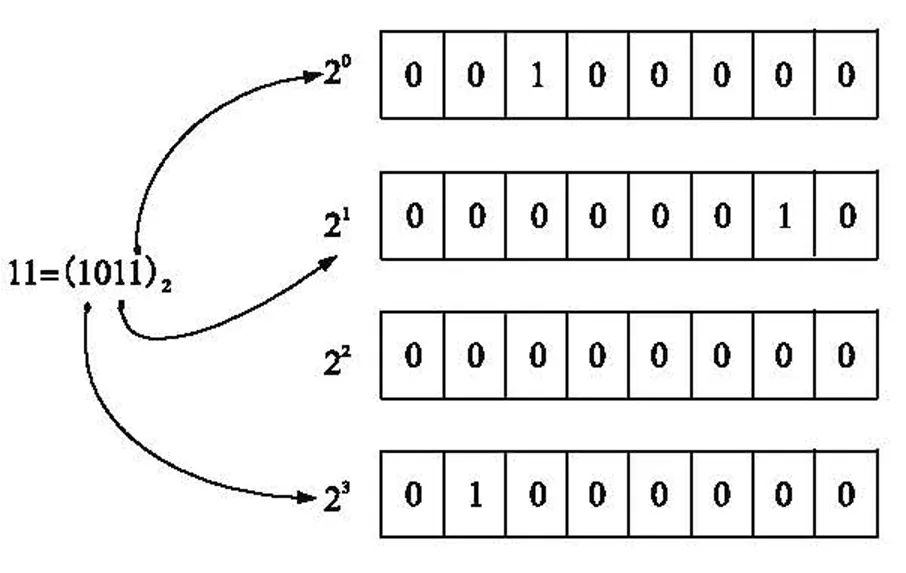
图2 节点读值表示
用FA概要结构来表示节点的读值可以使节点值在FA概要模式下具备对副本不敏感性,即反复计算一个副本并不影响聚集结果。因此,虽然多路径路由技术会增加网络中同一数据的副本数,但在最终的聚集结果里,每个读值vi都只会被计算一次。同时用此结构来近似表示一个节点的读值,则原来的精确值即不再使用。
②求和操作
若有两个概要结构FA1和FA2,则其可能的求和操作将包括如下3种情况:
(i)若FA2=0,则FA[i]=FA1[i]。
(ii)若FA1=0,则FA[i]=FA2[i]。
(iii)FA[i]=FA1[i][j]∨FA2[i][j],j=0,…,li-1。
③网内聚集
用相应元素按位或表示两个FA概要结构的加法操作。比如FA1[0]=(10011),FA2[0]=(10100),那么FA1[0]=(10111),以此类推,将所有相应元素位执行此操作即可产生一个新的FA概要结构,从而可计算出v1+v2个不重复记录值。这种性质使得用概要形式表示的节点读值可用于网内聚集操作。每个中间节点在收到其子节点的FA概要结构后,与自身的FA结构进行按位或操作,并将结果传给高层节点。
2.3 FA聚集方案
在执行聚集操作之前首先需要构建一个层次型拓扑结构的无线传感网络。步骤如下:基站广播一个请求报文给周边的节点;接收到请求的节点把自己的层数值设为1,这个值就是该节点距离基站的跳数,它们构成了第1层节点;接着,第1层节点继续广播请求给周边节点;周边的节点接收到请求后,先查看层数值是否已经被设置,若已设置则不做处理,若没有就在广播的层数上继续加1即i+1,层数值为2;层数值为2的节点构成了第2层节点;以此循环往复就构建成了一个层次型的无线传感网络,如图3所示。
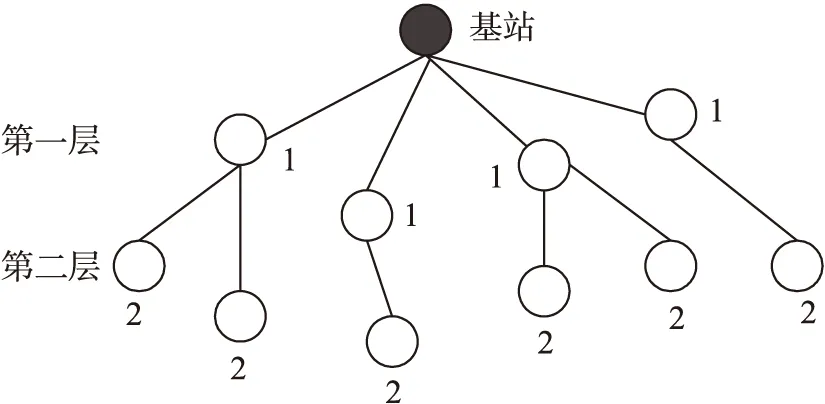
图3 层次型网络拓扑结构
FA技术由构建阶段和聚集阶段组成。在构建阶段,由基站沿着路有拓扑广播一个具体的聚集查询请求。各节点收到这个聚集查询请求后,产生一个FA概要结构用于表示自身的读值。聚集阶段从叶节点开始,逐层往上进行,在每个i+1层上的节点广播各自的FA概要结构给i层上的节点;i层的节点把接收到的FA概要结构与自身的FA概要结构做聚集操作,并将聚集结果继续发给i-1层上的节点;最后由基站计算出最终的聚集值FAfinal。
2.4 FA估计值
当聚集数据汇聚到基站时,由基站计算出整个网络的最终聚集值FAfinal。用式(1)来表示的n的估计值:
(1)
其中Vi是FAfinal[i]中0比特位所占的比例。式(1)记为FA—估计,其基本思路如下:
首先,FA技术可以看成由d个单独的LC概要结构组成,即各FA[i]大小为li,而i=0,…,d-1。用Di表示映射到FA[i]上的数目,每一映射到FA[i]上的位都用值2i表示,那么FA[i]的总大小就是2iDi。因此,n就可以通过对各FA[i]求和获得,即有式(2):
(2)
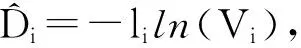
2.5 d和l的设置
最终估计值必须在精度(ε,δ)要求范围内才有效。因此在使用FA技术之前,需要对参数d和l的值进行正确地设置,使得使用FA概要结构表示节点值和聚集值能够满足精度要求。
首先,需要最大的传感器读数用以确定可能形成的FA元素的个数。然而,最大的传感器读数通常不可用,那么这里用最大的可能读值Z来代替,Z始终大于传感器读数的最大值,令d=log2Z。
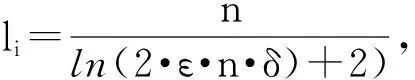
接着验证,在上述参数的设定下,FA估计计算出的n的近似值满足(ε,δ)约束条件。
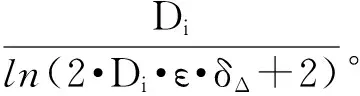
引理1 在每个FA[i]结构里,至多有k个映射,i=0,…,d-1。
接着,验证FA—估计是否满足(ε,δ)精度要求。
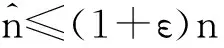
(3)
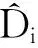
(4)
(5)
然后,
(6)
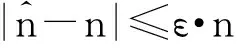
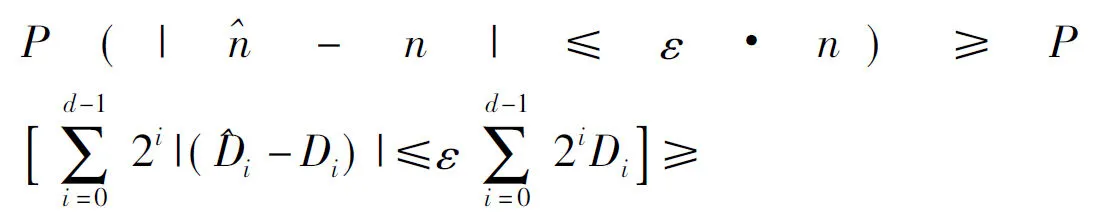
(7)
2.6 算法实例
假定一个传感器网络由一个基站和3个节点A1,A2,A3组成,读值分别为v1=8,v2=11,v3=5,如图4所示。
以Sum聚集为例,假定所有FA结构里的元素长度都是8位。聚集计算过程具体为:首先,每个节点构建一个初始化各元素为0的FA概要结构;然后,在FA概要结构里,节点的读值都用二进制来表示;如图4所示,v2=11=(1011)2,在FA2[0],FA2[1]和FA2[3]上随机选取一位设置为1。
聚集过程仍从叶节点开始,如图5所示。在本例中,由A1节点发送其自身的概要结构给上层节点即节点A2和节点A3。值得注意的是,只有当FA元素里的所有成员都不全为0时,该FA[i]元素才会被发送。图4中,对于A1节点就只有FA1[3]不全为0,因此,只发送FA1[3]=[00000010]给上层节点。中间节点收到子节点的FA概要结构后,与本地节点进行按位或的聚集操作,并把聚集结果发给更高层的节点。如图6所示,节点A2就会把FA1+FA2的聚集结果{FA2[0]=[00000010],FA2[1]=[00100000],FA2[3]=[10000010]}发给基站。同样的,节点A3也会把FA1+FA3的聚集结果发给基站。
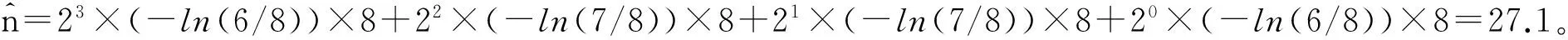
图4 FA概要结构
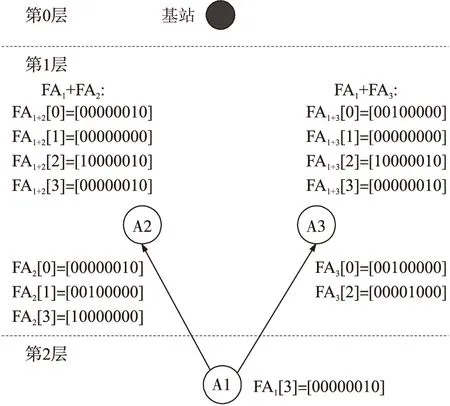
图5 FA聚集过程
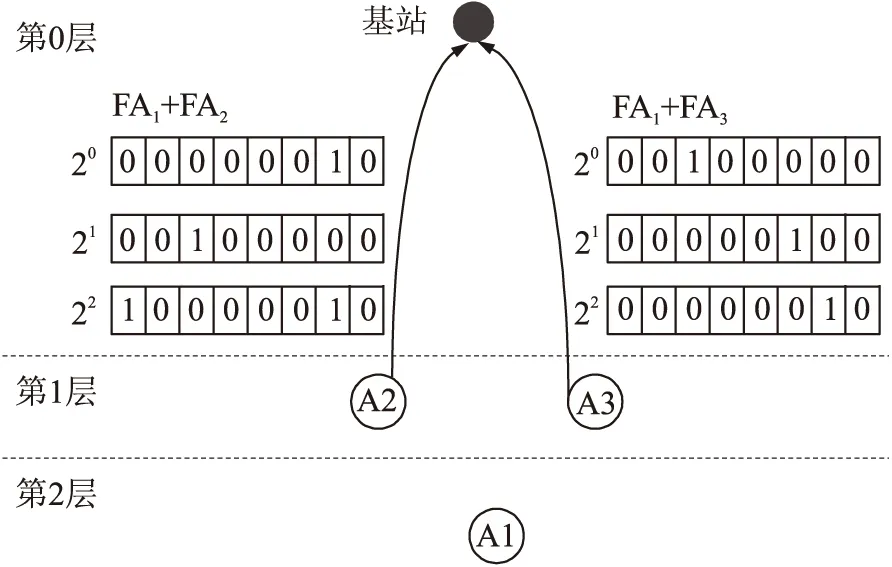
图6 FA聚集传输
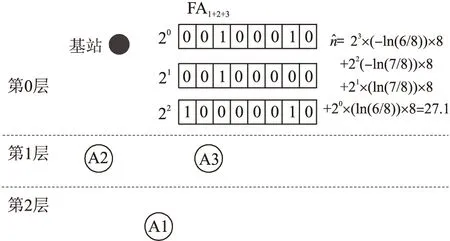
图7 FA最终聚集值的近似估计过程
3 理论分析与仿真实验
3.1 性能分析
①聚集技术所占空间大小
基于FM技术的算法[9,13,15]利用多路径路由方案,采用多个FM概要结构和PCSA技术进行聚集操作。基于LC技术的算法[12,16]创建一个LC概要结构用于聚集计算。FA技术用FA概要结构表示读值和聚集操作,并用FA估计作最终的聚集估计操作。
②概要结构图比较
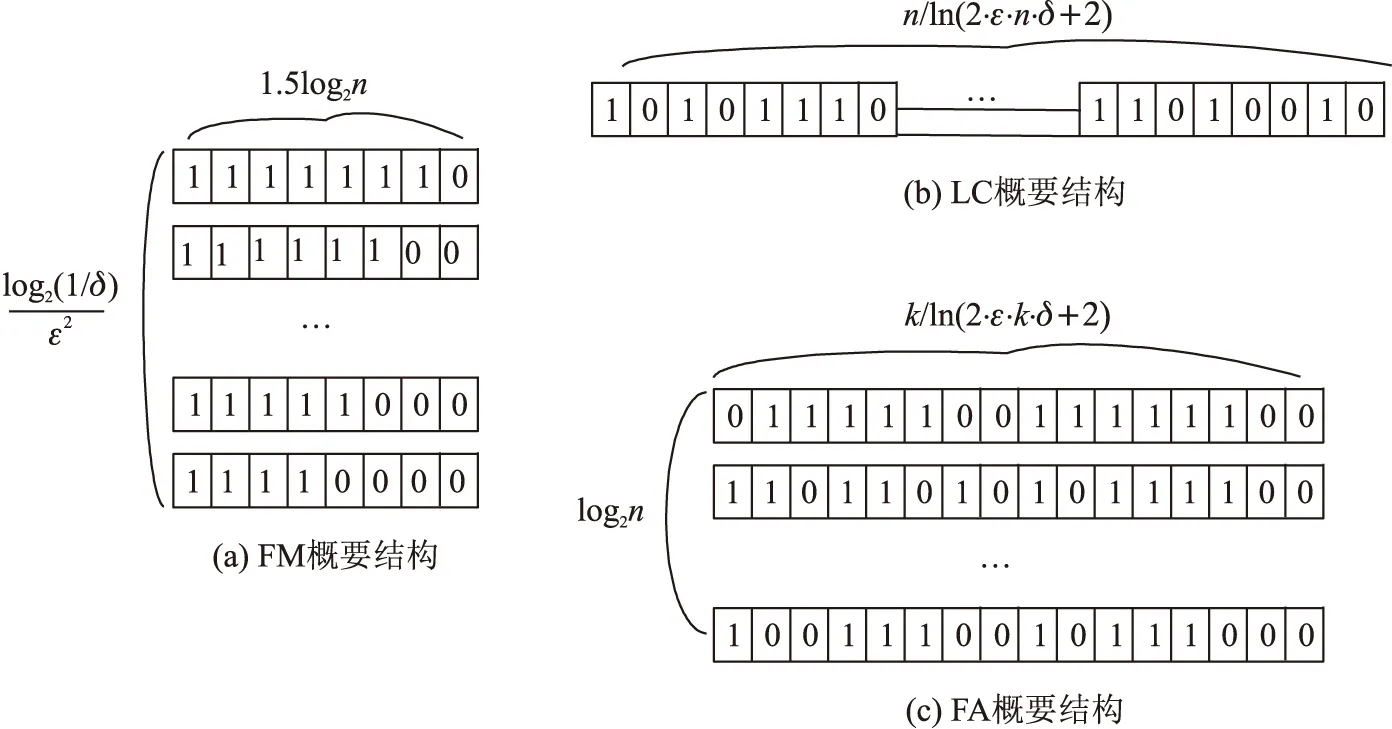
图8 概要结构图
图8分别是FM技术、LC技术和FA技术的概要结构图的设计思想,FA技术可以更精确的表示节点的感知值,有多数个元素则是出于可扩展性的考虑;FM技术表示节点感知值不够精确,因此需要数百个FM概要求取平均值的方式以提高聚集估计计算的精确性。
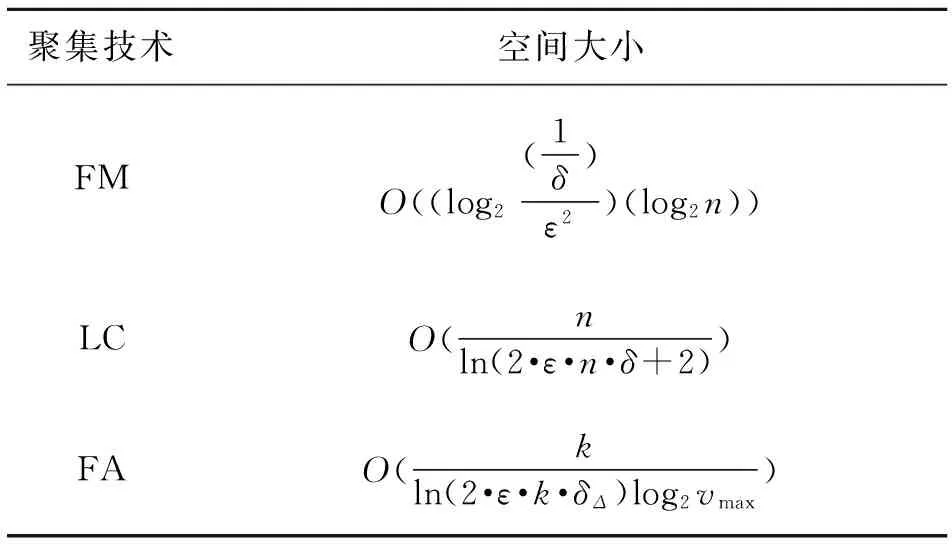
表1 聚集技术与空间大小
③概要结构大小与n的关系
取ε=0.1,δ=0.1,k=50时,各聚集技术所需空间大小与n的关系如图9所示。当n<50 000时,LC技术确实比FM技术占用更少的空间并且当n<4 000时,也比FA技术占用更少的空间。从图中很明显可以看出,FA技术相较于FM和LC技术,其概要结构远远占用更少的空间。
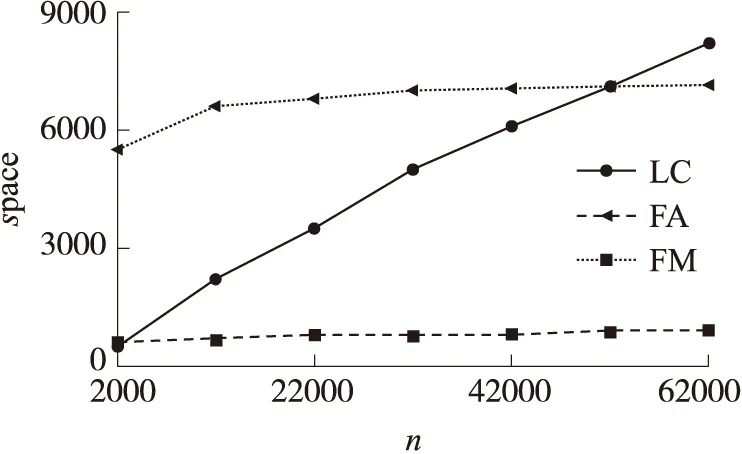
图9 概要结构大小与n的关系
3.2 仿真实验
仿真采用MATLAB作为仿真平台,同时将FA技术与FM技术和LC技术作比较。这些技术都采用多路径路由技术以提高聚集的健壮性并且均是对副本不敏感的概要结构。本例中以Sum聚集为例来比较概要结构和聚集查询的性能。
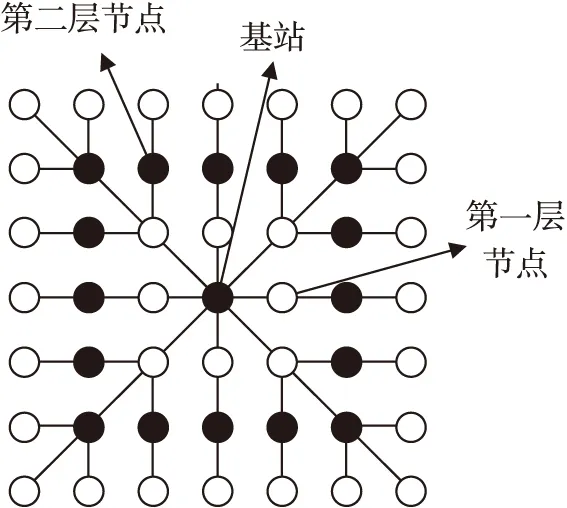
图10 7×7网络的路由拓扑图
①实验参数设计
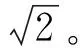
②性能衡量指标
为衡量数据聚集的性能,选取3个指标:传输功耗、相对误差率和置信度。传输功耗即某一节点的平均数据传输量,显然功耗越低越节能,在此用平均传输比特数来表示传输功耗。相对误差率是指聚集技术计算的近似估计值与真实值的偏差程度,聚集相对误差定义为:
(8)
对于置信度,本仿真实验只取精度约束条件(ε,δ)中的δ作为自变量,因δ值的大小直接影响概要结构的大小,并会对传输功耗造成影响。
③仿真结果与分析
按照实验参数设计和性能衡量指标,这里选取FM技术和LC技术作为比较对象,下面分别从仿真结果的3个角度进行说明。仿真结果如图11和图12所示。
图11比较各聚集技术中的节点数对节点传输功耗的影响情况,节点数越多,网络规模越大。图中x轴表示节点数,y轴表示相应的节点平均数据传输量,即传输功耗。仿真结果显示FM、FA技术的传输功耗受网络中的节点数目影响并不大,而LC则相对变化较大,因为当节点数目增大时,聚集值n也会随之变得较大。
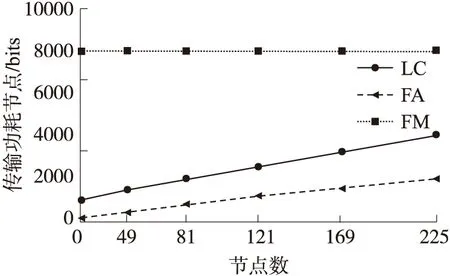
图11 节点对传输功耗影响
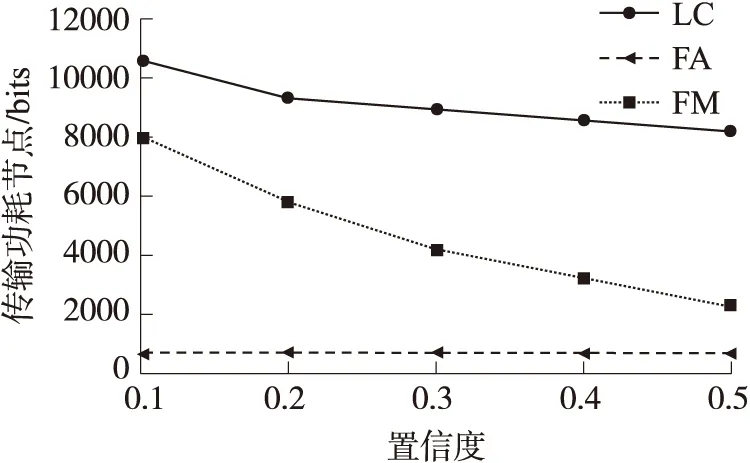
图12 约束条件对传输功耗的影响
图12比较各聚集技术的约束条件对传输功耗的影响。通过改变精度约束条件(ε,δ)中的δ大小来观察传输功耗的变化情况。图中x轴表示置信度δ,y轴表示相应的节点平均数据传输量,即传输功耗。仿真结果显示,由于FM技术的概要结构里有乘法因子Ω(1/ε2),因此其性能明显比较差;而FA技术也优于LC技术,因其相较前两者花费更少的概要结构存储空间。
4 结束语
对于多路径路由下的无线传感器网络的重复计数问题,本文在线性概率时间计数算法的基础上提出了一种新的数据聚集技术即FA技术。其具有副本不敏感、相对占用空间小、传输功耗小的特征。并且通过仿真比较,在同样精度条件下,FA技术在空间占用和传输功耗上优于同类的FM技术和LC技术。在FA技术的基础上,如何抑制那些对聚集结果影响较小的数据的传输是下一步的研究重点。
[1]尚凤军.无线传感器网络通信协议[M].北京:电子工业出版社,2011.
[2]Bista R,Chang J W.Privacy-Preserving Data Aggregation Protocols for Wireless Sensor Networks:A Survey[J].Sensors,2010,10(5):4577-4601.
[3]钱志鸿,王义君.面向物联网的无线传感器网络综述[J].电子与信息学报,2013,35(1):215-227.
[4]吕方旭,张金成,石洪君,等.WSN中的分布式压缩感知[J].传感技术学报,2013,26(10):1446-1452.
[5]于博,李建中.无线传感器网络上数据聚集及调度研究综述[J].智能计算机与应用,2013,3(4):5-9.
[6]Li X Y,Wang Y,Wang Y.Complexity of Data Collection,Aggrega-tion and Selection for Wireless Sensor Networks[J].Computers,IEEE Transactions on,2011,60(3):386-399.
[7]Bagaa M,Challal Y,Ksentini A,et al.Data Aggregation Scheduling Algorithms in Wireless Sensor Networks:Solutions and Challenges[J].Communications Surveys and Tutorials,IEEE,2014,16(3):1339-1368.
[8]Madden S,Franklin M J,Hellerstein J M,et al.TAG:A Tiny Aggregation Service for Ad Hoc Sensor Networks[J].ACM SIGOPS Operating Systems Review,2002,36(SI):131-146.
[9]Nath S,Gibbons P B,Seshan S,et al.Synopsis Diffusion for Robust Aggregation in Sensor Networks[C]//Proceedings of the 2nd International Conference on Embedded Networked Sensor Systems.ACM,2004:250-262.
[10]童孟军,李光辉,徐小良.基于分簇的能量有效多路径路由协议的研究[J].传感技术学报,2013,26(8):1126-1134.
[11]Mohammad Hossein Anisi,Abdul Hanan Abdullah,Shukor Abd Razak.Energy-Efficient Data Collection in Wireless Sensor Networks[J].Wireless Sensor Network,2011(3):329-333.
[12]黄万德.无线传感器网络中采用线性技术的数据融合算法研究[D].浙江工业大学,2012.
[13]Considine J,Hadjieleftheriou M,Li F,et al.Robust Approximate Aggregation in Sensor Data Management Systems[J].ACM Transactions on Database Systems(TODS),2009,34(1):1-35.
[14]Manjhi A,Nath S,Gibbons P B.Tributaries and Deltas:Efficient and Robust Aggregation in Sensor Network Streams[C]//Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data.ACM,2005:287-298.
[15]Flajolet P,Nigel Martin G.Probabilistic Counting Algorithms for Data Base Applications[J].Journal of Computer and System Sciences,1985,31(2):182-209.
[16]Whang K Y,Vander Zanden B T,Taylor H M.A Linear Time Probabilistic Counting Algorithm for Database Applications[J].ACM Transactions on Database Systems(TODS),1990,15(2):208-229.
A Kind of Data Aggregation Technology Based on Linear Time Probabilistic Counting Algorithm*
YINGKezhen1,2,WUJinbin1,DAIGuoyoong1,MIAOChunyu1,FANCongling1,CHENQingzhang1*
(1.Department of Computer Science and Technology,Zhejiang University of Technology,Hangzhou 310014,China;2.DongFAng College,Zhejiang University of Finance and Economics,Haining Zhejiang 314408,China)
Using data aggregation technique to pre-processing the data on intermediate nodes in the wireless sensor networks can remove a lot of redundant information,reduce data transmission and save energy.But sensor readings will be over-counted through multipath aggregation computing.To solve this problem,a new data aggregation technique named FA(Fan Aggregation)is proposed.Basing on the mathematical model of linear time probabilistic counting algorithm,FA optimizes the specific properties of the duplicate-insensitive synopsis.Theory analysis and simulation results show that FA technique performances better both in storage space and accuracy than FM(Flajolet Martin)and LC(Linear Counting)techniques.
wireless sensor network;data aggregation;synopsis;over-counting

应可珍(1978-),女,讲师,在读博士,主要研究方向是无线传感器网络;

陈庆章(1956-),男,教授,博士生导师,主要研究方向是无线传感器网络、分布式处理与协同工作等。
项目来源:国家自然科学基金项目(61379023)
2014-09-26 修改日期:2014-11-14
C:6150P
10.3969/j.issn.1004-1699.2015.01.018
TP393
A
1004-1699(2015)01-0099-08
