分布式数据流分类关键技术研究
2015-05-07徐花芬毛国君
徐花芬,毛国君,吴 静
(1.华北科技学院计算机学院,北京东燕郊 101601;2.中央财经大学信息学院,北京 100039)
0引言
作为一门应用技术,数据挖掘可谓涵盖广泛,尤其是在发达国家,数据挖掘技术的触角已经伸向了各行各业。只要企业拥有具有分析价值的数据源,皆可利用数据挖掘工具进行有目的的挖掘分析。如在销售数据中发掘顾客的消费习惯,找出顾客偏好的产品组合;分析信用不良的客户数据,从而预测可能的欺诈交易。然而上个世纪末开始在一些新型应用中出现的数据,却对传统数据挖掘技术提出了新的挑战,例如传感器网络、网络监控、WEB日志以及多站点的信用卡交易数据等。这些数据不仅具有实时、连续、规模大的特点,还具有分布式的特征,为了从这些数据中获取有价值的信息,就需要相关的分布式数据流挖掘算法,正是在此背景下,分布式数据流挖掘技术被广泛研究。
分布式数据流(Distributed Data Stream)是指相互联系的多个数据流[1]。与之相对应,目前大多数文献所说的数据流(Data Stream)或称流数据(Streaming Data)是指单数据流。近年来,(单)数据流的挖掘得到了广泛的研究[2-5],提出了许多有价值的模型和算法。然而,分布式数据流挖掘的研究刚刚起步,一些关键的科学问题已经提出,但是对应的理论和方法有限。本文主要讨论了分布式数据流分类算法的最新进展,归纳了分布式数据流挖掘面临的问题和挑战。
1 定义
分布式数据流挖掘是数据流挖掘技术与分布式计算的有机结合,主要用于分布式环境下的数据模式发现。分布式数据流挖掘是一个快速的发展领域,受到国内外的广泛关注。它考虑两种分布式数据——同构和异构。在同构的分布式环境下,每个站点观测相同的属性集,即一个实体(或事件)的全部信息集中在一个局部节点上,每个局部节点上收集整个系统的一个数据子集,所有局部节点上数据的并集构成整个系统的完整数据集。同构分布式数据流的形式化描述如下。
定义1 同构分布式数据流HoDDS。给定属性集 A{A1,A2,…,Am}和它的数据定义域 D{D1,D2,…,Dm},同构分布式数据流表示为:HoDDS=S1∪S2∪,…,∪Sk∪,…,∪Sn,其中 m 为被观察的属性个数;n为节点的个数;Sk(k=1,2,…,n)是一个节点上的数据流,Ak表示节点k上观测的属性集,满足:Ai∩Aj=A 且Ai∪Aj=A(i≠j,i,j1,2,…,n)。
在异构的分布式环境下,每个站点观测不同的属性集。即一个实体(或事件)的完整信息分布在不同的局部节点上。每个局部节点上观测的数据是相关实体(或事件)的部分信息。异构分布式数据流的形式化描述如下。
定义2 异构分布式数据流HeDDS。给定属性集 A{A1,A2,…,Am}和它的数据定义域 D{D1,D2,…,Dm},异构分布式数据流表示为:HeDDS=S1∞S2∞,…,∞ Sk∞,…,∞ Sn,其中 m 为被观察的属性个数;n为节点的个数(n≤m);Sk(k=1,2,…,n)是一个节点上的数据流,它对应着 A的一个属性子集,len(k)表示节点k上观测的属性个数,并且满足:Ai≠Aj(i≠j,i,j1,2,…,n)且∪i=1,2,…nAiA。
同构和异构有时也被称为水平和垂直划分。在同构站点的情况,每行定义了一个特有的实体,然而在异构的情况下,同一个实体的观测属性被分布在不同的位置。因此异构的情况下必须预先定义一些方法来关联同一实体的不同属性,行索引和关键字可用于识别不同站点上不同行之间的对应关系,在数据流环境下,可以时间戳来关联。
2 分布式数据流处理框架
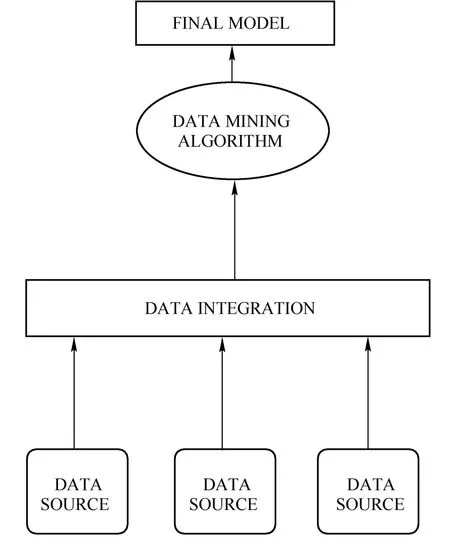
图1 集中式流处理架构
目前,很多系统采用集中式模式挖掘分布式数据流[6],如图1所示。在这种模式下,分布式数据流被集中到一个中心结点,在中心结点上进行数据挖掘。这种计算模式受到如下几个方面的限制,首先,数据流的集中式挖掘导致响应时间长,除中心节点外,其它节点的计算资源也是可利用的,而集中式数据挖掘没有充分利用这些资源。集中式数据收集导致关键通讯链路的严重阻塞,如果这些通讯链路已经限制了网络带宽,那么网络I/O可能成为性能瓶颈。而且,在能源受限的领域,比如传感器网络,就会因过量的数据通讯导致过量的能源消耗。
为缓解以上提到的问题,Cherniack M、Balakrishnan H、Balazinska M等学者讨论了大规模的分布式流处理系统设计中面临的架构问题,提出了一种分布式模型[7],如图2所示。在这种分布式流挖掘模型中,不用集中数据到中心节点,分布式的计算节点执行部分计算,同时当需要时传输计算得到的局部模式到中心结点,这样的架构有几个优点:首先,通过使用分布式的计算节点(这些结点是并行计算的),降低了响应时间;第二,节点之间只传输局部模式,不传输源数据,因而降低了通信量,节省了大量的时间和空间开销,在能源受限的领域可以降低能源消耗。
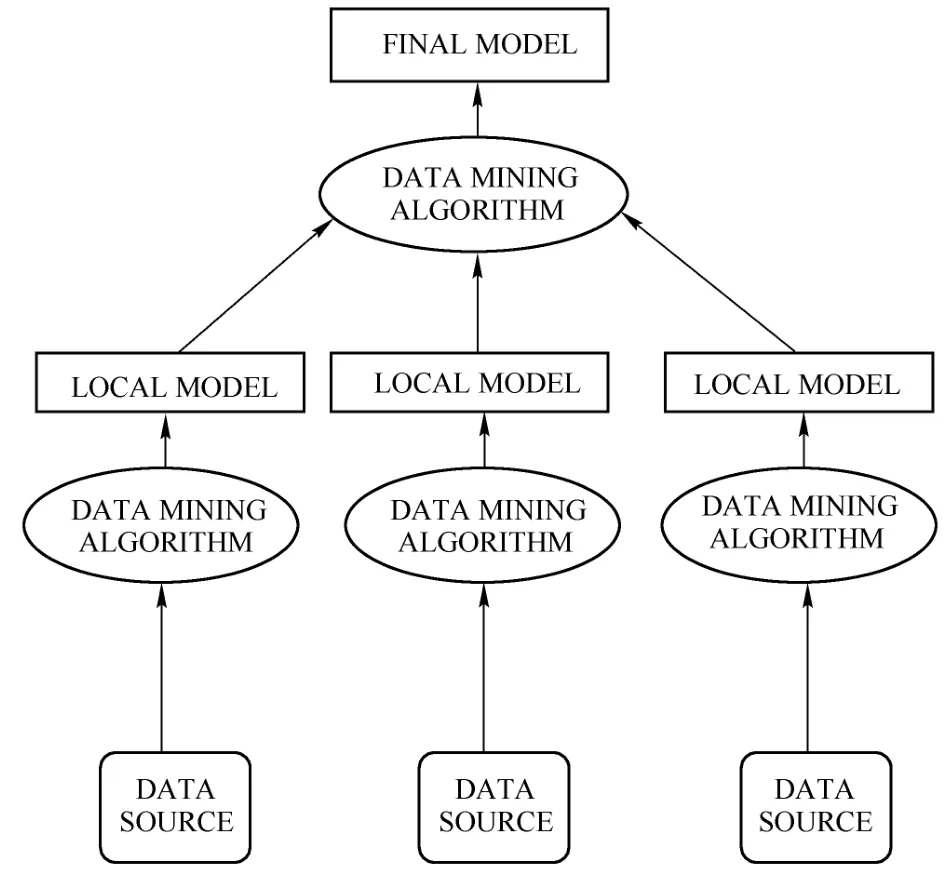
图2 分布式流处理架构
3 分布式数据流分类算法
目前,大部分分布式数据挖掘文献考虑同构的数据站点,同构站点的分布式数据挖掘包括合并来自不同站点的模型。几种集成模型已经应用于同构分布式数据挖掘环境。Bagging方法是同构DDM环境下合并模型的候选方法之一,其观点在文章[10]中有具体讲述。和Bagging方法一样,Stacking也能被扩展用于合并分布式环境下的局部模式,这些合并多个模型的技术在文章[17]中通过实验给出了相关评价。
元学习[12,13,15]提供了挖掘同构分布式数据的另一类技术。这种技术跟Bagging和Stacking方法具有相似之处。在这种技术中,局部数据站点引用有监督学习思想来学习分类,然后将局部学习分类生成的数据集成到Meta-level级后,再进行分类学习。Meta—learning学习过程主要包括以下三个步骤:1)在每个站点使用分类学习算法生成基分类器;2)将基分类器集中到一个中心站点上,用每个基分类器产生的预测信息和一个独立的数据效验序列来生成元数据;3)由元-级数据产生最终分类器。
同构分布式数据使用的基于集成学习的分类方法并不适用于异构分布式数据。由于在分布的数据站点上的数据是异构的,从局部数据挖掘结果中不能得到系统的全部信息。Provost和Buchanan于1995年提出通过将大问题分解为小问题来实现基于特性空间的异构划分,但这种方法要求站点间必须具有相关性。WORLD系统使用一种“激活传播方法”来进行异构数据的概念学习:首先计算各个站点数据属性的主要分布,然后分布信息在个站点问传播,并根据前几阶统计近似值来确定概念空间中具有强相似性的属性值[8]。但当概念学习要求使用高阶统计信息时,这种方法并不适用。
以上这些方法并不是基于分布式数据流环境,2004年,Agrawal等给出了分布式数据流的概念,并建立了Gates原型系统[1]。Ghoting等人给出了分布式数据流的信息交换方法和评估策略。文章[16]从诱导偏见的角度讨论了异构数据站点的学习。该工作指出属性空间的划分可通过将问题分解成更小的子问题来解决。
文章[18]考察了通过传输部分数据的方法处理异构和同构数据的问题,作者定义了一个包含通讯代价和计算代价的代价函数,问题简化成编程问题从而使得传统技术得以应用。
在DDM的实际应用中,经常不能充分存取异构分布式数据集的公共值,为了推广应用DDM,1998年Kargupta和Park等人提出了汇集型数据挖掘系统(CDM)[9]。它使用正交基函数进行局部分析,解决通常的局部数据分析方法不能正确生成构造全局数据模型所需要的局部模型的问题。CDM是一种在分布式垂直划分特征空间中进行归纳学习的新方法,其基本思想是将待学习的函数用一组合适的基函数按分布式方式表示,整个CDM算法与不同站点发现模式的特定归纳学习算法无关。允许各数据点选择不同的学习算法,CDM能够生成整个数据集的全局分布式模式,不必假定按照各站点上特征空间的特殊划分方式,将整个建模问题进行分解。
Kargupta又于2000年提出将CDM技术拓展到决策树领域,提出了分布式决策树生成算法[14]。该算法先在各分站点采用boosting算法建立局部模型,并确定出置信度低于某事先设定阈值的数据为交叉项;然后将局部模型和交叉项数据传送到总站点运用boosting算法进行集成。由于boosting算法得出的分类模型难于理解,分布式决策树运用傅立叶技术将各站点模型转化为决策树表示形式。最后由竞争策略,若事例在某个站点模型上的分类置信度大于设定阈值且最高,则选用该分站点决策树进行预测;否则,采用全局模型进行预测。基于CDM思想的分布式决策树生成算法首先采用boosting算法来构造局部和全局站点模型,然后采用TCFS(Tree Construction from Fourier Spec)算法将得到的模型转化为更易于理解的决策树表示形式。该算法的优点是:(1)产生的分类规则直观易懂;(2)可以直接从函数的傅立叶频谱计算出各属性的信息增益,运算速度较快;(3)函数的傅立叶系数随阶数增长呈指数衰减形式,即只选用几个低阶的傅氏系数即可近似表征决策树的傅氏频谱。该算法的不足之处在于仍然没有产生一个整体的用于分类预测的模型。
Chen et al,给出了一种集合方法挖掘来自分布式异构网络日志数据流的贝叶斯网络[11]。在他们的方法中,他们在每个站点上用局部数据学习局部贝叶斯网络,然后,每个站点鉴别可能是局部和非局部变量结合迹象的观测数据,并且传输这些观测数据的一个子集到中心站点。用来自局部站点的数据在中心点学习另一个贝叶斯网络,结合局部和中心站点的贝叶斯网络得到一个集合贝叶斯网络,这个集合贝叶斯网络模拟了全部数据。这种技术尤其适合非零通讯代价(如无线网络)中分布式数据流的挖掘应用。
Gianluigi等通过构建一个适应的助推集成分类器(An adaptive boosting ensemble of classifiers)处理大规模的分布式数据流分类问题[19],适应的助推集成分类器(An Adaptive Boosting Ensemble of Classifiers)综合在分布式网络结点上训练的模式,学到的局部模式是通过GP(Genetic Programming)获得的,它诱导地生成决策树。
Liu等提出了一种分布式交通流挖掘系统[20]。中心服务器仅在训练和更新阶段执行各种数据挖掘任务,发送感兴趣的模式到传感器。传感器监视并预测将到来的交通流,跟历史交通流中观测的模式相比较,独立发出警报。传感器提供实时响应,只需较少的无线通信和少量资源需求,降低了中心服务器上的通信负担。
4 分布式数据流挖掘面临的挑战
在网络环境下,不仅数据流的产生源分布在不同的网络节点,而且数据的传输路由以及目标地址也具有分布性。很多时间关键的应用像传感器网络、网络入侵检测和欺诈性交易检测产生像“流”一样的数据。它要求基于观测的新数据立刻做出决策。一般来说,这样的流数据在更多的新数据到达之前的短时间内有效。因此,从异构的分布式数据流中进行知识挖掘是一个重要的研究课题,面临着许多挑战性的问题。
1)作为分布式数据流挖掘的基础,(单)数据流提出的问题对分布式数据流来说也同样需要面对。数据流的潜在无限性和达到速率的不可预测性等,使得传统的数据挖掘理论与算法不可能被直接利用。因为传统的处理大数据样本的多遍扫描或者非在线的处理方式显然不能来处理随时间变化的动态数据流。目前研究表明,数据流挖掘采用增量式算法是必须的,即随着流数据的到达不断更新模式。当然,分布式数据流挖掘的增量式模式更新问题,面临着新的挑战:同一时间或者时间段,多个节点都可能有数据到达,而且速率可能差异很大。因此,如何准确而高效的对全局模式进行增量式更新需要有新的构架和模型来支撑。
2)集中式解决分布式数据流的模式挖掘问题是不现实的。由于分布式数据流的每个节点的局部数据流的数据达到速率都是不可控的,假如设想将所有节点的到达数据都及时送到一个中心节点来统一处理,那么网络传输时间和对中心节点的存储需求都是无法克服的问题。因此,研究分布式的模式更新策略是必需的,需要从可用的模型和应用构架到关键的问题(如局部模式与全局模式的融合)的解决算法等方面进行深入研究。另外,对于大规模的分布式数据流来说,为了在线实时跟踪数据的变化,采用“准精确”挖掘手段也是必需的,于是提高挖掘精度成了一个不可回避的问题。
3)为了提高数据流的挖掘精度,近年来人们开始关注数据流的集成学习(Ensemble Learning)模型和方法研究[21-23]。集成学习需要同时维护多个模式,这样可以有效避免高速流动的数据带来的概念颠簸(即由于只保留最新的一个,可能使最近几个常出现的模式频繁切换),也可以改善传统的非集成学习对样本数据的过分拟合的情况。对于分布式数据流而言,这样的问题存在而且更复杂。虽然,目前有些文献提到了相关问题,但是研究还是策略性的。因此,利用集成学习方法来解决分布式数据流的模式挖掘问题有很好的研究价值
4)早期的数据流挖掘方法都假设数据是平稳分布的,即没有考虑潜在的概念漂移(Concept Drift)现象,因此对许多应用(如网络入侵检测、信用卡欺诈等)无法取得好的预测效果。概念漂移是指数据流的数据在很短的时间内从一种概率分布变为另外一种概率分布的突变式现象。很显然,对于分布式数据流而言,它的概念漂移挖掘问题的解决需要更有效和高效的方法。近期出现的分布式数据流的概念漂移检测方法主要还是基于时间或者频率(区间)估计的[23-24]。根据我们的分析,研究基于数据分布评估的概念漂移挖掘问题具有更好的应用价值。解决这个问题,需要从合适的数据概要结构和有效的数据分布评估算法等方面进行研究。
5 结论
本文介绍了同构分布式数据流和异构分布式数据流的概念及相应形式化描述,分析了集中式流处理架构与分布式流处理架构的优势与不足,讨论了分布式数据流分类算法的最新进展,归纳了分布式数据流挖掘面临的问题和挑战。通过本文的阐述可知,分布式数据流需要分布式的挖掘架构,由此带来的理论和方法上的问题需要解决,表现为如何进行分布式数据流集成模式的更新;研究适合于分布式数据流处理的节点级数据流的增量式集成模式学习算法、节点级数据流的数据概要模型与挖掘算法,进一步研究分布式数据流的全局模式挖掘模型与算法;针对数据到达速率不均匀的分布式数据流特点研究概念漂移问题。
[1] Chen L,Reddy K,and Agrawal G.GATES:A Grid-based Middleware for Processing Distributed Data Streams[C].High Performance Distributed Computing(HPDC),2004.[S.l]:IEEE.
[2] Aggarwal C,Han Jiawei,WangJianyong et al.On Demand Classification of Data Streams[C].Proc.of 2004 Int.Conf on KDD,Seattle,WA,Aug.2004.
[3] Qin S,Qian W,Zhou A.Adaptively Detecting Aggregation Bursts in Data Streams[C].Proc.of the 10th Intl Conf on Database Systems for Advanced Applications,2005.
[4] QINShou-Ke,QIAN Wei-Ning,ZHOU Ao-YING.Fractal- Based Algorithms for Burst Detection over Data Stream[J].Journal of Software,2006,17(9):1969 -1979.
[5] Wang Tao,Li Zhoujun,Yan Yuejin,et al.A Survey of Classification of Data Streams[J].Journal of Computer Research and Development,2007,44(11):1809-1815.
[6] Babcock B,Babu S,Datar M,et al.Models and issues in data stream systems[C].Proceedings of the Symposium on Principles of Database Systems(PODS).2002:1-16.
[7] Cherniack M,Balakrishnan H,Balazinska M.Scalable Distributed Stream Processing[C].Proc.of the 2003 CIDR Conference.2003:196-205.
[8] Aronis J M,Kollufi V,Buchanan B G.The WoRLD:Knowledge Discovery From Multiple Distributed Databases[C].Proc.of Florida Artificial Intelligence Research Symposium(FLAIRS-97),1997:337 -341.
[9] Kargupta H,Park B.Collective Data Mining:A New Perspective Toward Distributed Data Mining[C].In Advances in Distributed and Parallel Knowledge Discovery,Eds:H.Kargupta and P.Chan,AAAI/MIT Press,2000:133 -184.
[10] Breiman L.Pasting Small Votes for Classification in Large Databases and On-line[J].Machine Learning.1999,36(1 -2):85-103.
[11] Chen R,Sivakumar D,and Kargupta H.An Approach to Online Bayesian[C].Proc.of the Inter- network learning from multiple data streams.national Conference on Principles of Data Mining and Knowledge Discovery,2001:21-25.
[12] Chan P,Stolfo S.Experiments on Multistrategy Learning by Meta-learning[C].Proc.of the Second International Conference on Information Knowledge Management,1993.[S.l]:[s.n],1993:314 -323.
[13] Chan P,Stolfo S.Toward Parallel and Distributed Learning by Meta-learning[C].In Working Notes AAAI Work.Knowledge Discovery in Databases.1993.AAAI,1993:227 -240.
[14] Johannes G,Venkatesh G,Raghu R et al.BOAT—Optimistic Decision Tree Construction[C].Proc.of SIGMOD,ACM,1999:169-180.
[15] Prodromidis A L,Stolfo S J,and Chan P K.Pruning Classifiers in A Distributed Meta-learning System[C].Proc.of the First National Conference on New Information Technologies,1998,[S.l]:[s.n],1998:151 -160.
[16] Provost F J,Buchanan B.Inductive Policy:The Pragmatics of Bias Selection[J].Machine Learning,1995,20:35 -61.
[17] Ting K M,Low B T.Model Combination in the Multiple-database Scenario[C].In 9th European Conference on Machine Learning,1997,[S.l]:[s.n],1997:250 -265.
[18] Turinsky A L,Grossman R L.A Framework for Finding Distributed Data Mining Strategies That Are Intermediate between Centralized Strategies and In-place Strategies[C].In Workshop on Distributed and Parallel Knowledge Discovery,Boston,MA,USA,2000:167-174.
[19] Gianluigi F,Clara P,Giandomenico S.An Adaptive Distributed Ensemble Approach to Mine Concept-Drifting Data Streams[C].Proc.Of 19th IEEE Intl Conf on Tools with Artificial Intelligence,2007,2007:183-187.
[20] Liu Y ,Choudhary A,Zhou J,Khokhar A.A Scalable Distributed Stream Mining System for Highway Traffic data[C].Proc.Of PKDD,2006:309-321.
[21] Wen Yimin,Yang Yang,Lu Baoliang.Research on the Application of Ensemble Learning Algorithms to Incremental Learning[J].Journal of Computer Research and Development,2005,42(extra edition):222-227.
[22] Wang H,Fan W,Yu P S,Han J.Mining Concept-drifting Data Streams Using Ensemble Classifiers[C].The 9th ACM Int’l Conf on KDD,Washington,ACM.,2003.
[23] Gianluigi F,Clara P,Giandomenico S.An Adaptive Distributed Ensemble Approach to Mine Concept-Drifting Data Streams[C].Proc.Of 19th IEEE Intl Conf on Tools with Artificial Intelligence,2007,Volume 2.
[24] Zhang D,Li J,Kimeli K,Wang W.Sliding Window based Multi- Join Algorithms over Distributed Data Streams[C].Proc.of the 22nd International Conference on Data Engineering,Apr.2006.
[25] Ghoting A,Parthasarathy S,Facilitating Interactive Distributed Data Stream Processing and Mining[C].Proc.of the IEEE Intl Symposium on Parallel and Distributed Processing Systems(IPDPS),April 2004.
[26] LIU Bin,Survey on distributed data mining[J].Journal of Hebei University ofScience and Technology.2012.2,35(1):80-90.
[27] QU Wu,SUI Hai- feng,YANG Bing-ru.Advances in study of Distributed Mining of Data Streams[J].Computer Science,2012.1,39(1):1-7.
