跨平台x86系统虚拟机存储子系统优化
2015-05-04董卫宇蒋烈辉王立新唐永鹤焦建华
董卫宇,蒋烈辉,王立新,唐永鹤,焦建华
(信息工程大学 数学工程与先进计算国家重点实验室,河南 郑州450000)
0 引 言
跨平台系统虚拟机 (cross-platform system virtual machine)利用动态二进制翻译 (dynamic binary translation,DBT)、内存虚拟化、I/O仿真等技术,可使针对某处理器平台 (源平台)编译的操作系统和应用程序运行于其它处理器平台 (目标平台),实现软件的跨平台透明移植,对体系结构创新和新型处理器推广具有重要意义[1]。另外,跨平台系统虚拟机技术在动态二进制优化、漏洞挖掘和利用、体系结构模拟等领域也有广泛的用途[2-4]。
除了对源平台指令集架构 (instruction set architecture,ISA)兼容的完备性之外,性能是跨平台系统虚拟机需优先考虑的问题。源平台与目标平台的ISA间在指令集、存储管理单元 (memory management unit,MMU)、I/O接口等方面的差异,有可能严重制约跨平台系统虚拟机的效率。
目前,提升跨平台系统虚拟机效率的做法主要有两类,一是利用软硬件协同设计技术[1,5,6],在目标平台CPU中增加硬件资源来模拟源平台;二是利用软件方法,通过分析源平台ISA的特性来简化或去除不必要的模拟操作。第一类做法可获得较大加速比,但对CPU进行修改须面临成本、技术、验证等多重风险,处理器厂商对此种方案一般很谨慎。第二类做法如果运用得当也可以获得可观的收益,风险很小,出现错误易于修改,并且可以为软硬件协同设计提供依据。本文以基于申威处理器 (SW-410,以下简称SW)的x86系统虚拟机监控器为实例来讨论跨平台系统虚拟机的访存操作的软件优化方法。
不同于某些进程级虚拟机[7,8],跨平台系统虚拟机需要模拟源平台的MMU,在访存前进行虚实地址转换,以及缺页或内存保护异常检测。由于源平台和目标平台的MMU往往存在很大差异,一般无法使用同构系统虚拟化中的影子页表、EPT (extended page table)等技术,而只能利用软件来串行模拟原本可以用MMU硬件并行完成的工作,因此开销很大,优化价值也很大。
本文的主要工作如下:①介绍了跨平台系统虚拟机ARCH-BRIDGE及其设计;②对ARCH-BRIDGE存储子系统的性能瓶颈进行了识别和分析;③提出了x86段级存储仿真优化、页级存储仿真优化、连续内存访问优化等方法;④对上述方法进行了实现和测试,应用上述方法,ARCHBRIDGE的访存性能提升了2.4倍~3倍,操作系统引导性能提升了30.4%。
1 ARCH-BRIDGE设计
ARCH-BRIDGE是首个基于申威处理器的跨平台系统虚拟机监控器。为丰富申威处理器的软件来源,并考虑到x86ISA在业界的垄断地位,ARCH-BRIDGE选择x86作为源平台。该项目的目的是研究申威与x86间的ISA差异,识别基于申威平台的x86系统虚拟机的性能瓶颈,提出面向x86架构兼容的申威处理器优化扩展方案,并在后续硬件支持的基础上最终演化为一款软硬件协同设计虚拟机监控器 (co-designed Virtual machine monitor),实现x86操作系统和应用程序在申威平台上的透明高效运行。
目前,ARCH-BRIDGE运行于采用SW处理器的神威服务器平台,支持Intel P6处理器定义的全部定点指令、FPU指令和 MMX指令,支持PCI总线、南北桥、IDE、VGA、APIC等典型x86接口,能够运行基于x86Linux 2.6内核的操作系统,能够运行BusyBox工具集中的全部应用程序,通过了SPEC CPU 2006测试集中全部定点程序和12个浮点程序的测试 (另外6个浮点程序为Fortran程序,由于虚拟机映像内运行时库问题暂未测试)。支持Windows操作系统运行以及软硬件协同设计虚拟机的工作正在进行中。
ARCH-BRIDGE的设计方案如图1所示,下面从x86处理器虚拟化、内存虚拟化和I/O虚拟化3个方面介绍其设计。
1.1 x86处理器虚拟化
动态二进制翻译技术是在异构平台上进行x86处理器虚拟化的关键技术。ARCH-BRIDGE的利用DBT引擎完成动态二进制工作,其主要设计要点如下:
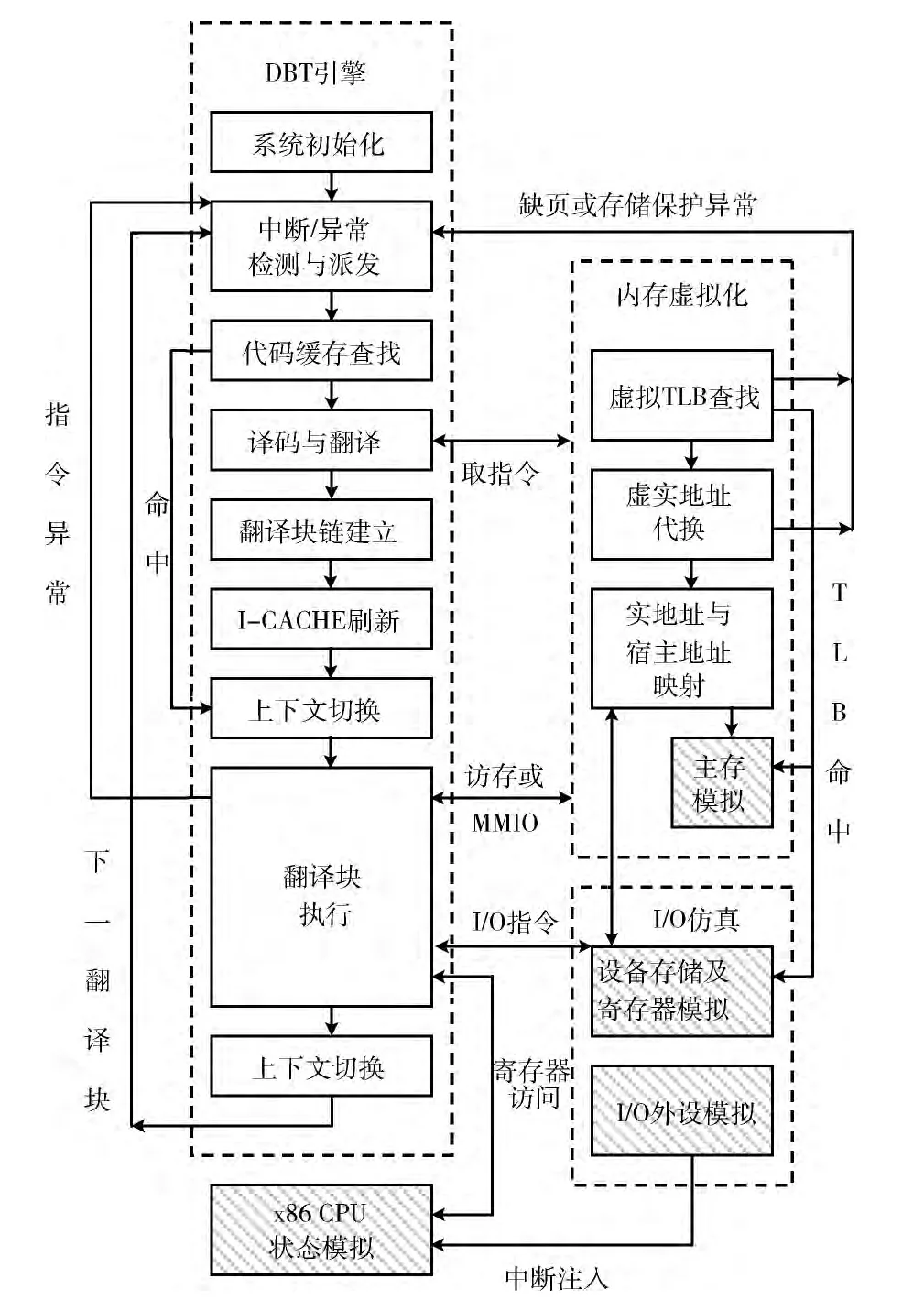
图1 ARCH-BRIDGE设计方案
(1)DBT引擎以动态基本块为翻译单位。为提高翻译效率,采用x86指令到SW指令直接翻译和寄存器静态映射的方式,没有采用其它虚拟机监控器所采用的中间表示以及动态寄存器分配方案。某些x86指令 (如INT指令)的操作十分复杂,ARCH-BRIDGE利用辅助的C代码仿真这些指令。
(2)为提高翻译代码的重用率,DBT引擎采用了代码缓存 (code cache)机制来保存翻译过的x86基本块,当代码缓存满时,采用简单的全清空策略清除所有翻译块。
(3)为降低DBT引擎与翻译块间的上下文切换开销,DBT引擎采用了翻译块链 (Block Chaining)机制来链接翻译过的代码块,为避免构成循环的翻译块阻碍对中断的响应,需定期将当前正在执行的翻译块从块链中移除,以便返回执行引擎检查中断。
(4)在取指令 (实际是访存的一种形式)或翻译块执行过程中检测到x86异常时,采用longjmp()将流程转移到DBT引擎入口位置,进行异常检查和派发工作。ARCHBRIGE支持精确异常,可确保在异常派发前将机器状态(包括通用寄存器、标志寄存器、EIP、内存内容)恢复到异常指令执行前的状态。
(5)采用懒惰计算思想,在执行翻译块时不更新EIP的值,仅在块尾部或遇到异常时才恢复EIP的值;在翻译影响标志位的指令时,仅插入SW指令保存x86指令的操作、执行结果和源操作数 (目的操作数可以由上面3个信息恢复出来),仅在需要引用标志位时才计算标志位的值。
1.2 内存虚拟化
内存虚拟化包括两个任务:一是MMU虚拟化,主要是模拟x86对页表和TLB的相关操作,完成客户虚拟地址(guest virtual address,GVA)到 客 户 物 理 地 址 (guest physical address,GPA)的转换。由于页表属于x86ISA的一部分,因此ARCH-BRIDGE需精确模拟页表的查找过程。由于x86TLB对软件透明,因此TLB虚拟化不受实际硬件的限制,ARCH-BRIDGE以HASH表的形式对TLB进行模拟;二是物理内存虚拟化,ARCH-BRIDGE使用进程地址空间的一部分来模拟虚拟机的物理内存,因此需要建立客户物理地址GPA到宿主机虚拟地址 (host virtual address,HVA)间的映射。由于x86的物理地址空间很可能存在空洞,并考虑到对PAE机制 (36位物理地址)的支持,ARCH-BRIDGE采用3级目录结构来保存这种映射关系。每个映射关系将一个4KB的虚拟机物理页面映射到一个4KB的宿主机虚拟页面。若x86物理页面为RAM或ROM,则映射关系给出物理页面对应的HVA。若x86物理页面以MMIO方式映射到I/O设备的存储区域,则映射关系以回调函数方式给出访问设备存储区域对应的I/O动作。
1.3 I/O虚拟化
I/O虚拟化主要工作有四方面:一是I/O寄存器模拟;二是内存映射 (MMIO)的设备存储模拟;三是设备中断;四是设备的DMA操作。除此之外,ARCH-BRIDGE还实现了软时钟、字符设备抽象层、块设备抽象层等模块,以提供对设备仿真的共性支持。ARCH-BRIDGE的I/O仿真的主要做法是:
(1)在设备初始化时向ARCH-BRIDGE注册I/O端口或MMIO存储的访问回调函数;
(2)在翻译块执行过程中,若访问I/O端口或 MMIO存储,上述回调函数将被调用,I/O操作得到同步处理;
(3)ARCH-BRIDGE以定时轮询的方式检测键盘输入、定时器超时等I/O事件,并在必要时以中断注入的方式通知虚拟机;
(4)ARCH-BRIDGE在基本块的边界检测外部中断并进行中断派发。
2 访存性能瓶颈识别
ARCH-BRIDGE对访存指令的翻译工作可以分为两个部分:
(1)根据指令指定的寻址方式生成用于计算x86线性地址的SW指令序列;
(2)生成调用mmu_rd或mmu_wt所需的SW指令序列。其中mmu_rd和mmu_wt为C函数,用于进行访存涉及的复杂的TLB查询、地址转换和访问宿主机内存的操作。
ARCH-BRIDGE前期的实验数据表明,在引导Linux-2.6.38内核时,从开机到出现登录界面总消耗时间约为65s左右,由于采用指令直接翻译和寄存器静态映射技术,指令翻译效率较高,仅占用了2.1s,但访存时间消耗高达31.7s,约占到了虚拟机总执行时间的48.8%,对虚拟机的性能影响很大,存在很大的优化价值。分析发现,ARCH-BRIDGE的访存操作至少存在如下一些优化机会:
(1)x86访存操作存在复杂的段级存储管理阶段,每个访存操作都需要将有效地址加上段基址来生成线性地址并进行段边界检查,精确模拟上述机制需要一定数量的SW指令。但由于x86操作系统大多绕过了段级机制,采用平面模式内存管理 (段基址为0,段界限为0xFFFFFFFF),精确模拟没有实际意义,存在优化机会。
(2)如图2所示,DBT引擎与翻译块共用一套SW结构寄存器,从DBT引擎切换到翻译块执行需要一次上下文切换;当遇到访存操作时 (翻译块内往往存在多次访存),从翻译块中调用mmu_rd和mmu_wt又引入了额外的上下文切换。另外,利用C函数实现mmu_rd和mmu_wt的效率也不高。mmu_rd和mmu_wt的3项主要工作是TLB查询、TLB脱靶情况下的页表查询、以及宿主存储器访问,其中第1、3项工作比较简单。测试表明,ARCH-BRIDGE的TLB命中率为99.4%,大多数情况下无需页表查询操作,因此可考虑利用较短的SW指令序列对页级存储仿真进行优化。
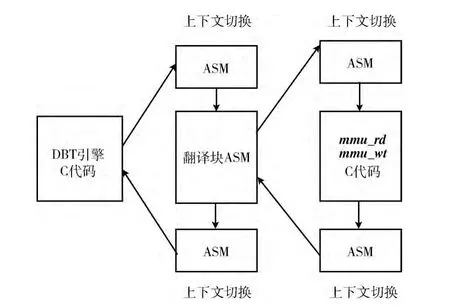
图2 访存时调用mmu_rd和mmu_wt的流程
(3)x86提供了 MOVS、SCAS、INS/OUTS等串指令,并且与REP等指令前缀配合来完成串操作。如表1所示,在系统引导过程中观测到的约1.2×108次访存中,串操作的访存次数总和为53 732 810次,约占总访存次数的44.7%。QEMU、Valgrind[9,10]等跨平台虚拟机采用比较简单的仿真方法,将串指令包含在一个循环内实现串操作,每次循环都需要进行虚实地址转换工作。考虑到串操作具有连续访问存储器的特点,一旦确定了某个访存操作对应的宿主机内存地址,只要不超出当前页面,对后续的访问无须进行GVA到HVA的代换,可以进一步省去TLB查询的开销。
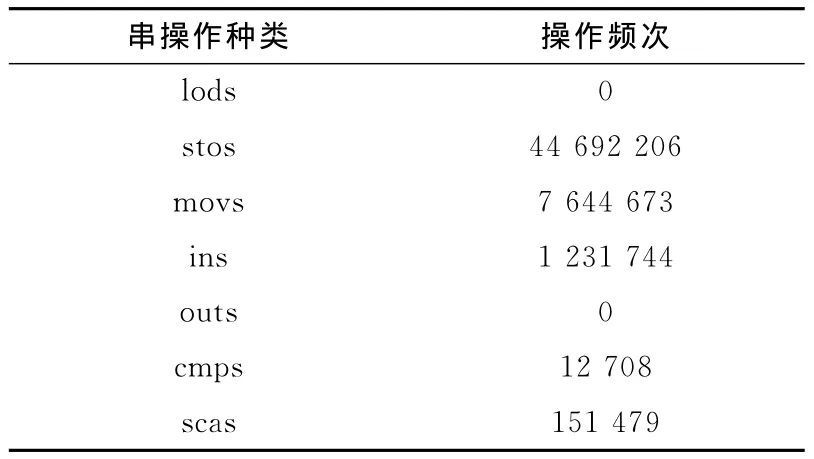
表1 引导过程中的串指令访存频次
针对上述优化机会,本文分别提出了段级存储仿真优化、页级存储仿真优化、连续内存访问优化等方法,并在ARCH-BRIDGE进行了实现,具体做法将在第3节中介绍。
3 访存优化
3.1 段级存储仿真优化
为优化对段级存储的仿真,ARCH-BRIDGE在翻译基本块前检查段寄存器的状态,并将检查结果记录在翻译块描述信息中,每个段寄存器只需2位信息即可,分别表示段基址是否为0以及段边界是否为0xFFFFFFFF。x86的6个段寄存器用一个12位的位图描述即可。
当翻译基本块内的访存指令时,若所使用的段基址为0,则无需生成SW指令进行有效地址与段基址的加法操作;若段界限为0xFFFFFFFF,则无需生成SW指令进行段界限保护检查。由于访存指令普遍存在,因此该优化可在一定程度上去除翻译块中的无效指令。
在存在代码缓存和翻译块链的情况下,需要防止翻译块在段寄存器配置发生变化的情况下被执行。为此,ARCH-BRIDGE采用了以下两点措施:首先,在进行代码缓存查找时,除基本块地址外,还比对段寄存器的当前配置与基本块在翻译时的段寄存器配置,若发生变化 (几率很小),需在新的段寄存器配置下重新翻译基本块。其次,将所有修改段寄存器的指令视为基本块结束条件,并且仅在块以直接跳转或直接函数调用指令结束时才与后续的块建立块链,任何修改段寄存器的指令执行后将返回DBT引擎,这保证了在构成块链的一组基本块中不可能存在修改段寄存器的指令,也就是说构成块链的一组基本块具有相同的段寄存器配置,在从代码缓存中查找到一个翻译块进而进入块链中执行后,无需担心会执行到段寄存器配置与其初始翻译时不符的翻译块。该过程如图3所示。
3.2 页级存储仿真优化
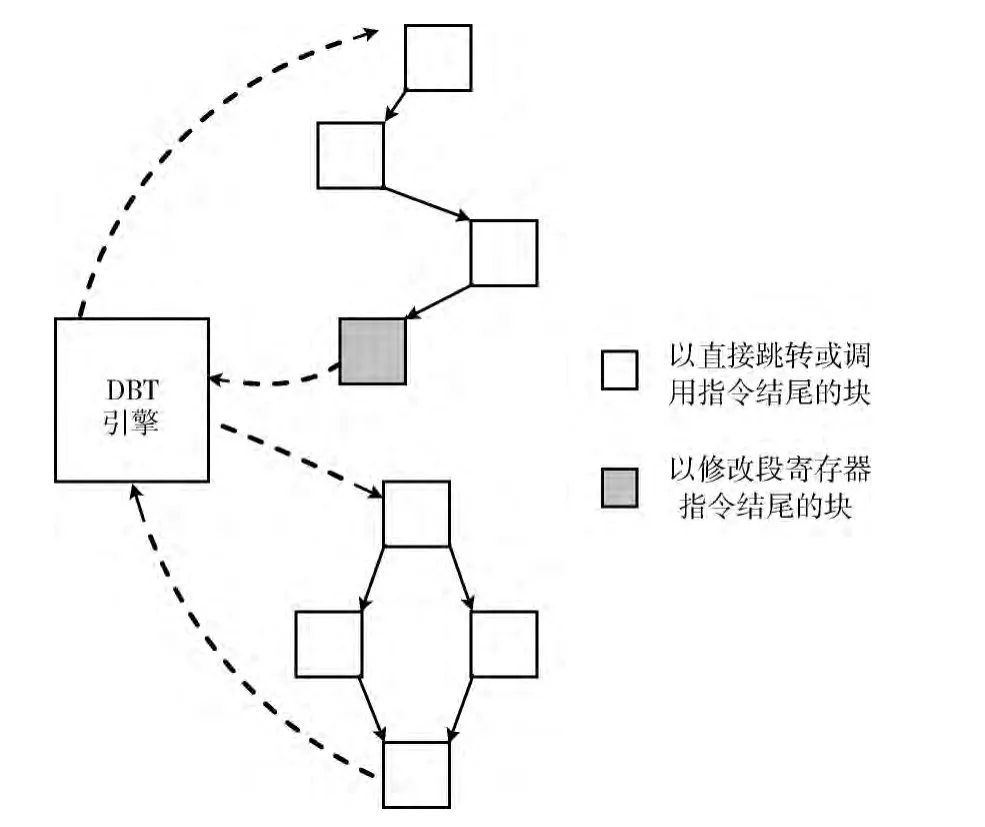
图3 ARCH-BRIDGE的基本块终止和块链退出
为进行页级存储仿真优化,ARCH-BRIDGE引入了指令片段mmu_rd_fast和mmu_wt_fast,负责TLB查询以及TLB命中后的宿主存储器访问,大小为20条指令左右。在指令中的翻译访存操作时,会首先生成对mmu_rd_fast和mmu_wt_fast的调用指令,之后再生成对mmu_rd和mmu_wt的调用指令,仅当TLB未命中时,mmu_rd和mmu_wt才会得到执行。对mmu_rd_fast和mmu_wt_fast的调用只需增加3条指令,代码膨胀很小。
ARCH-BRIDGE采用静态寄存器分配,在翻译块中不会使用处理器 ABI(application binary interface)约定的参数传递寄存器 (r16~r21)和返回值寄存器 (r0)。由于mmu_rd_fast和mmu_wt_fast的任务比较简单,仅使用寄存器r16~r21和r0即可完成工作,因此在调用这两段指令片段时,而无需进行上下文切换。如前所述,TLB命中率很高,因此绝大部分访存操作都可由mmu_rd_fast和mmu_wt_fast完成,可以在很大程度上提升访存效率。
为简化实现,mmu_rd_fast和mmu_wt_fast仅处理TLB命中的、不跨页的、非MMIO的访存操作,其它类型的访存操作仍交由mmu_rd和mmu_wt处理。
3.3 连续内存访问优化
为进行连续内存访问优化,ARCH-BRIDGE以C函数方式来仿真串指令,仅在串指令进入新的页面时,才进行一次GVA到HVA的代换,得到访存所对应的页面的基址。只要不离开该页面,后续的访存操作只要修正一个位移量就可以到所需要的HVA,之后进行内存读写操作。
以rep stos为例,优化后的串操作执行步骤如下:
(1)获取 ECX/EDI/EAX的值;
(2)若ECX为0,转第 (7)步;
(3)根据EDI进行地址代换,确定页面的HVA;
(4)计算本页面内可进行最小操作次数;
(5)将EAX的值循环存入本页面内存区域;
(6)修正ECX/EDI的值,转第 (2)步;
(7)结束。
对于大批量的内存初始化操作而言,rep stos的主要操作集中在了第v步,此时页面内串指令的访存速度可以接近宿主机本地的访存速度。为简化实现,我们仅对正向的(DF标志为1)、对齐的、且采用32位地址的串指令采用上述优化措施。
4 性能测试及分析
本文对上述优化措施的适用性以及优化后的存储系统效率和操作系统引导效率进行了测试。主要测试环境如下:虚拟机监控器为ARCH-BRIDGE,宿主机为运行中标麒麟操作系统的SW-410平台,虚拟机操作系统为经过服务裁剪的tty-linux (内核版本为2.6.38)。
我们通过采样操作系统引导过程中的访存操作来评估上述优化措施的适用性,见表2。其中,在指令流中 (静态)存在的337 623处线性地址计算操作中,97.3%的操作可以被优化掉;在指令流中 (静态)存在的337 133处段界限检查操作中,99.9%的操作可以被优化掉。在动态监测到的25 770万次访存操作中,99.3%的操作可在mmu_rd_fast和mmu_wt_fast中完成。在以rep stos为例的44 692 206次串操作中,99.8%的访存操作可以得到优化。因此上述优化措施具有很好的适用性。
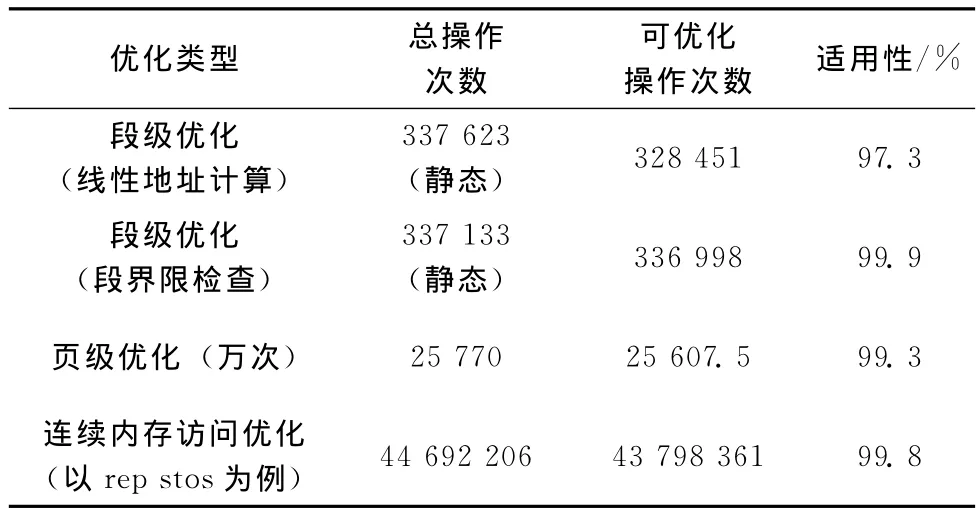
表2 各个优化措施的适用性
本文采用STEAM内存带宽测试程序来测试优化措施对访存带宽的影响。优化前后的ARCH-BRIDGE虚拟机访存带宽如图4所示。由于STREAM中没有采用串指令,因此我们忽略了对连续内存访问优化的测试。测试表明,在启用段级和页级存储仿真优化的情况下,虚拟机的访存带宽提升了2.4~3倍。
ARCH-BRIDGE在采用优化措施前后的操作系统平均引导时间如图5所示,当综合采用上述3种优化措施后,虚拟机的操作系统引导时间由65s降低为45.2s,速度提升了约30.4%。利用QEMU 0.10提供的TCG基址,我们将QEMU移植到了SW平台,移植后的操作系统平均引导时间为48.7s,在仅采用访存优化措施的情况下,ARCHBRIDGE的性能相比QEMU提升了7%。
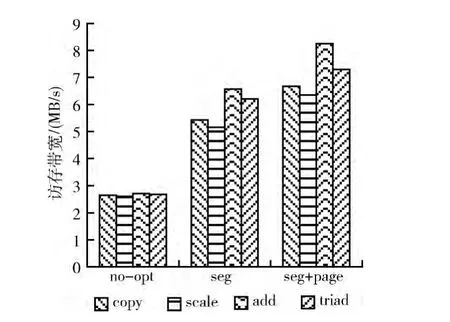
图4 采用优化措施前后的虚拟机访存带宽
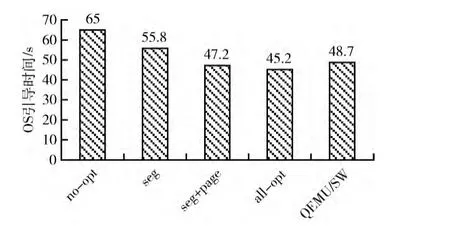
图5 采用优化措施前后的虚拟机OS平均引导时间
5 结束语
本文介绍了基于申威处理器的跨平台系统虚拟机ARCH-BRIDGE及其设计,对其存储子系统的性能瓶颈进行了识别和分析,并提出了x86段级存储仿真优化、页级存储仿真优化、连续内存访问优化等方法,使ARCHBRIDGE的访存性能提升了2.4~3倍,操作系统引导速度提升了约30.4%。
相比典型的跨平台系统虚拟机QEMU,本文的段级存储仿真优化可以在确保兼容的情况下提升访存效率,而QEMU为了换取性能,在访存时并不进行段界限检查,损失了兼容性;页级存储仿真优化利用宿主机的ABI特性,可在不增加上下文切换开销和较小代码膨胀的情况下提升访存效率,而QEMU将每条x86访存指令翻译为几十条宿主机指令并内联在翻译块中,导致了很大的代码膨胀,另外其寄存器动态分配机制还会导致访存过程中的寄存器溢出,降低效率;连续内存访问优化可以使串指令以接近本地的效率进行访存,而QEMU只是简单地将串指令的单次操作嵌套在循环中重复执行,带来很多冗余操作,操作系统中存在许多使用串指令的任务,如C2级操作系统一般都存在将内存页面清0的线程,因此该优化措施有助于提升系统性能。测试表明,在仅采用访存优化措施的情况下,ARCHBRIDGE的操作系统引导性能相比QEMU提升了7%。
[1]CHEN Wei.Research on dynamic binary translation based codesigned virtual machine [D].Changsha:National University of Defense Technology,2010 (in Chinese).[陈微.基于动态二进制翻译的协同设计虚拟机关键技术研究 [D].长沙:国防科学技术大学,2010.]
[2]Tong X,Luo J,Moshovos A.QTrace:An interface for customizable full system instrumentation [C]//IEEE International Symposium on Performance Analysis of System and Software,2013:132-133.
[3]Yin Heng,Song Dawn.TEMU-binary code analysis via wholesystem layered annotative execution [R].Berkeley: UC Berkeley,2010.
[4]Wang Z,Liu R,Chen Y.Coremu:A scalable and portable parallel full-system emulator [C]//Proceedings of the 16th ACM symposium on Principles and Practice of Parallel Programming.ACM,2011:213-222.
[5]El Ferezli E.FAx86:An open-source FPGA-accelerated x86 full-system emulator [D].University of Toronto,2011.
[6]Hu W,Wang J,Gao X.Godson-3:A scalable multicore RISC processor with X86emulation [J].Micro,IEEE,2009,29 (2):17-29.
[7]Guan HB,Ma RH,Yang HB.MTCrossBit:A dynamic binary translation system based on multithreaded optimization [J].Science China Information Sciences,2011,54 (10):2064-2078.
[8]Sridhar S,Shapiro JS,Bungale PP.HDTrans:A low-overhead dynamic translator [J].ACM SIGARCH Computer Architecture News,2007,35 (1):135-140.
[9]Ding JH,Chang PC,Hsu WC.PQEMU:A parallel system emulator based on QEMU [C]//IEEE 17th International Conference on Parallel and Distributed Systems,2011:276-283.
[10]Nicholas N,Seward J.Valgrind:A framework for heavyweight dynamic binary instrumentation [C]//ACM Sigplan Notices.ACM,2007,42 (6):89-100.
