BP算法与C4.5算法在乳腺癌诊断中的比较分析
2015-05-04杨云,董雪,齐勇
杨 云, 董 雪, 齐 勇
(陕西科技大学 电气与信息工程学院, 陕西 西安 710021)
BP算法与C4.5算法在乳腺癌诊断中的比较分析
杨 云, 董 雪, 齐 勇
(陕西科技大学 电气与信息工程学院, 陕西 西安 710021)
目前数据挖掘技术被大量应用于医学领域,进行疾病诊断。针对乳腺癌发病率不断升高,为辅助医生做出诊断决策,采用具有优秀学习能力的人工神经网络中的BP算法与决策树中的C4.5算法来分析乳腺癌数据,对乳腺癌肿瘤类型进行诊断预测,并对这两种算法建立的分类器性能进行比较分析,研究发现BP算法与C4.5算法都能对乳腺癌类型作出诊断预测,但在分类器的评估中发现BP分类器的性能优于C4.5分类器.
乳腺癌分类; BP算法; C4.5算法; 分类器性能
0 引言
近年来,乳腺癌的发病率逐渐升高,已经成为女性恶性肿瘤的第二名.对女性的健康造成了严重的威胁,因此它的诊断就显得至关重要[1,2].而医疗知识和数据挖掘技术的结合已成为医疗保健方面一个非常重要的跨学科技术创新[3],已有大量的数据挖掘算法运用到了医学领域,辅助医生做出诊断决策并取得了很好的成果[4].庞大的医疗数据中隐含着大量的对诊断决策有用的信息,因此将数据挖掘技术与医疗诊断结合是非常必要的,可以有效地提高医院的服务质量[5].
本文采用BP算法与C4.5算法来对乳腺癌数据建立分类器以预测肿瘤的良性与恶性,通过比较它们各自的实验结果,分析针对乳腺癌两种分类器的性能优劣.
1 数据采集
利用数据挖掘工具Weka分析来自UCI机器学习知识库提供的683个乳腺癌数据,包括444例良性肿瘤类,239例恶性肿瘤,9个数值型属性按顺序排列为肿块的厚度(Clump thickness)、细胞大小的均匀性(Uniformity of cell size)、细胞形状的均匀性(Uniformity of cell shape)、边缘的粘连(Marginal adhesion)、单层上皮细胞的大小(Single epithelial cell size)、裸核(Bare nuclei)、温和的染色质(Bland chromation)、正常的核仁(Normal nucleoli)、有丝分裂(Mitose),这9个属性是从医学的角度看与乳腺癌诊断决策最相关的属性,且均被归一化为1~10之间,可以直接用来建立分类器[6].每个实例都含类属性(Class)2代表良性,4代表恶性.
2 数据挖掘算法
2.1 BP算法
人工神经网络(Artificial Netural Network,ANN),由一系列简单单元相互密集连接构成,其中每一个单元有一定数量的实值输入,并产生单一的实值输出[7].人工神经网络对于逼近实数值、离散值或向量值的目标函数提供了一种鲁棒性很强的方法[8].其中,BP算法(Back Propagation Algorithm )即反向传播算法是目前应用最为广泛和成功率最高的人工神经网络算法之一,它是一种有监督的学习方法,可以用来学习多层网络边的权值,在实际应用中一般较多使用前馈网络,网络的基础是Sigmoid单元[9],定义为公式(1),它的输出是输入的非线性函数,并且输出是输入的可微函数,输出范围为0~1,随输入单调递增.
(1)
整个学习过程可分为两个,输入的正向传播与误差的反向传播.一个多层BP前馈网络如图1所示,由输入层(Inputs Layer)、隐藏层(Hidden Layer)和输出层(Outputs Layer)组成.

图1 一个多层BP前馈网络示意图
BP算法中,每一个训练样例都是以形为
(2)
2.2 C4.5算法
C4.5是数据挖掘十大经典算法中排名第一的算法,已被广泛应用到医药、工业、经济等各个领域[10],它不是一个算法而是一组算法,工作流程如图2所示[11].C4.5继承了早期决策树算法即ID3算法中分类速度快和分类器准确率高等优势,并在此基础上对ID3算法进行了一系列改进,包括使用信息增益率代替信息增益、在树构造中采用悲观剪枝法、处理残缺值,并且能够完全对连续属性离散化[12,13].该算法的核心是决策树分类算法,其流程如下:首先,选择一个属性放置在根节点,为每一个可能的属性值产生一个分支.这将使样本集分裂成多个子集,一个子集对应于一个属性值.然后在每一个分支上递归地重复这个过程,仅使用真正到达这个分支的实例.如果在一个节点上的所有实例拥有相同的类别,即停止该部分树的扩展[14,15].
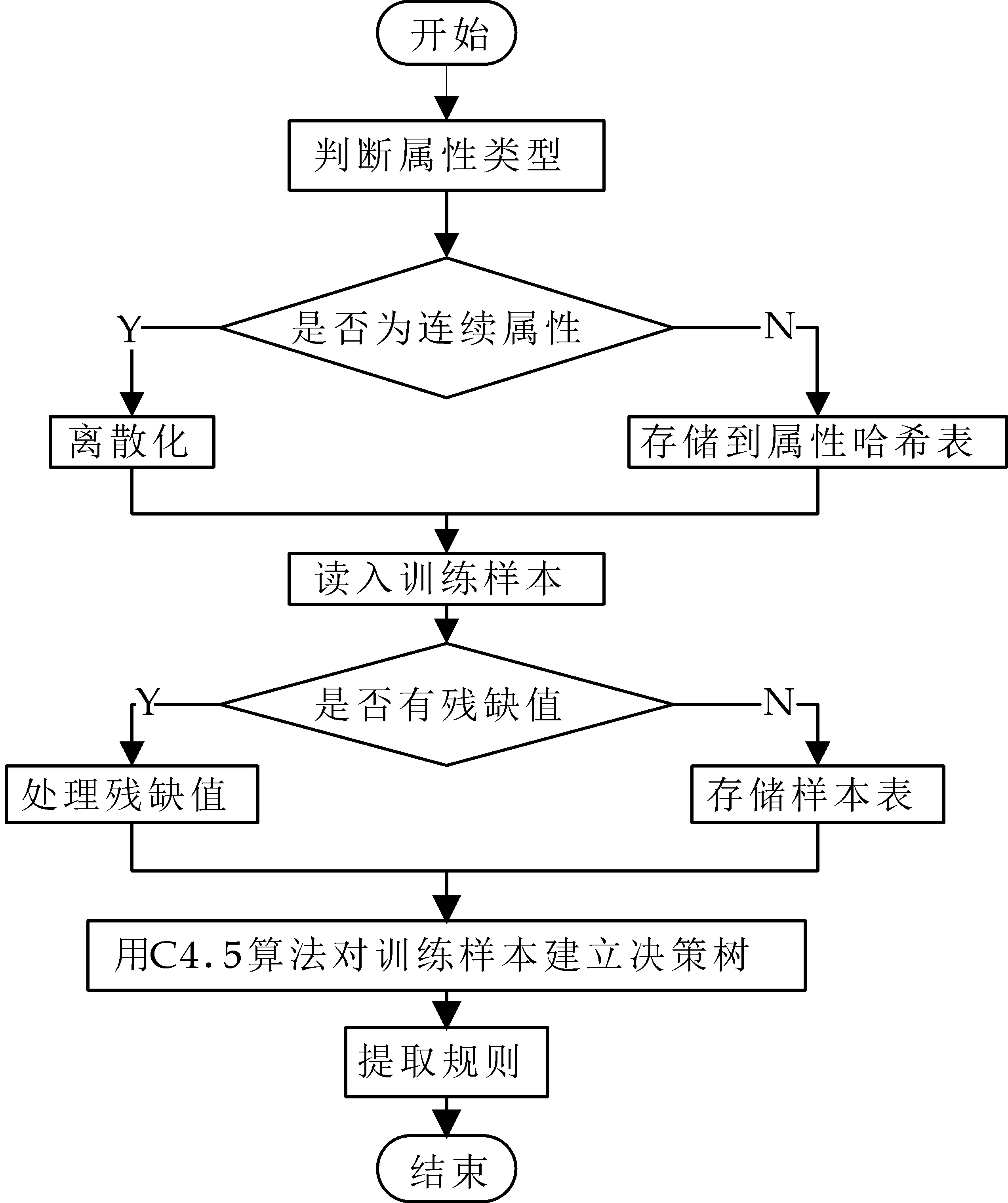
图2 C4.5工作流程图
问题的关键是如何选择分裂属性,可分以下步骤:
(1)计算节点的信息值Info[E1,E2,…,En],即信息熵(entropy)
(3)
(4)
其中En为该节点一个分支上第n类的实例数量;
(2)考虑该节点上所有分支,计算它们的平均信息值,记为Infoavg;
(3)计算根节点的信息值Info[D1,…,Dn],其中Dn为处于根节点处第n类的训练样本实例数量;
(4)计算该属性的信息增益
Gain=Info[D1,…,Dn]-infoavg
(5)
(5)计算信息增益率
GainRation=Gain/Infosplit[S1,…,Sn]
(6)
其中Infosplit[S1,…,Sn]为该属性分裂信息值,Sn为第n个分支的总实例数量.
3 实验
建立分类器一般有以下几个步骤:1.选择一种分类方法;2.选择属性集;3.训练分类器;4.验证分类器;5.评估分类器.
3.1 BP算法实验
BP算法依据现在的数据趋势实现对未来数据趋势的预测,在建立BP网络时,首先要考虑网络的隐藏层层数,以及隐藏层单元的个数,一个好的网络结构能带来更好分类效果,但BP网络的隐藏层层数与隐藏层单元数往往都是一个经验值,因此需要反复实验,来确定各项参数.经过200次反复变换BP算法的各项参数,选取其中最佳的,设定如下:学习速率为0.3、冲量为0.2、训练次数为500次、隐藏层单元数为属性数量和类值数量的平均值、验证集的误差可允许持续恶化20次停止训练.图3所示为建立的乳腺癌BP前馈网络结构.
如图所示,输入层有9个单元,分别为乳腺癌的9个数值属性,隐藏层的单元个数通过属性数量和类值数量的平均值计算得到,即(9+2)/5,取整为5个单元,输出层有2个单元,即类的个数,分别为2良性,4恶性.

图3 乳腺癌BP网络结构图
3.2 C4.5算法实验
C4.5算法系统有两个重要的参数,一个是置信因子,小于该值导致决策树修剪;另一个是叶节点上的最小实例数,小于改值则被认为是噪声数据而剪去,C4.5为解决过度拟合的问题采用悲观剪枝法对决策树进行修剪.同BP算法一致,本次实验同样经过200次反复调整各项参数,选取其中使分类效果最佳的一组参数设定如下:置信因子为0.25、叶节点上的最小实例数为2.建立的决策树结构图如图4所示.
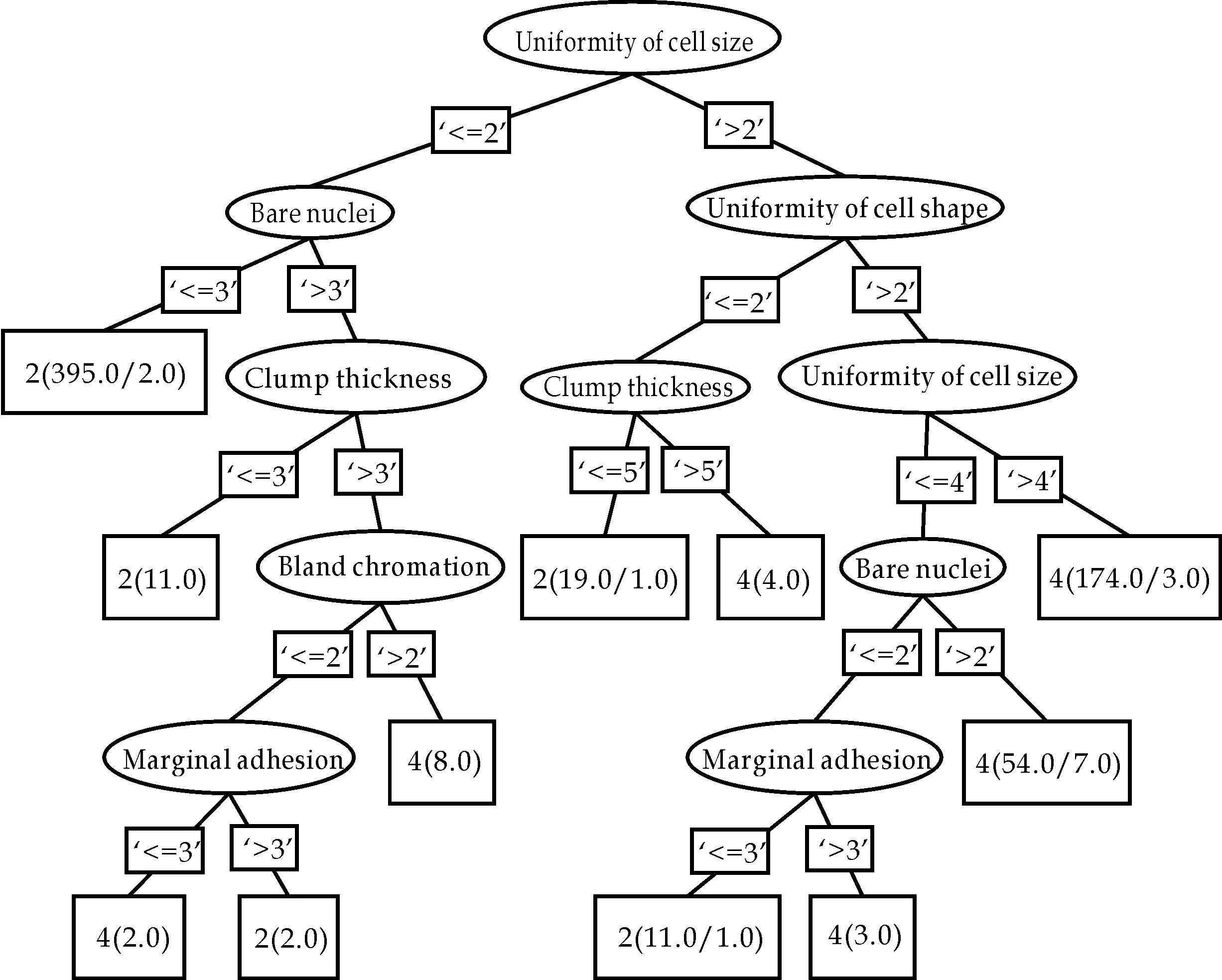
图4 乳腺癌决策树结构图
该决策树在叶节点上给出了到达该类的实例数量与其中错误分类的实例数量.例如,395.0/2.0就是有395个实例被分为2类即良性肿瘤类,其中2个实例是被错分的.决策树中由根节点到叶节点的每条路径给出了相应的分类规则,例如IF:“Uniformity of cell size<=2”AND“Bare nuclei>=3”THEN 2,即如果细胞大小的均匀性<=2并且裸核>=3,那么乳腺癌肿瘤就是良性的.
4 实验结果分析与对比
在相同实验环境与相同的实验次数下都选取能使分类效果达到最佳的参数来建立BP分类器与C4.5分类器.因为数据量有限,对两种分类器的评估均采用十折交叉验证法,数据被随机分成十个部分,每一部分中的类比例与整个数据集中的类比例基本一致,每一部分依次旁置,其余十分之九的数据被用作训练数据,旁置数据用于计算误差,整个过程将重复十次,最后将得到的10个误差率估计值平均而得出一个综合误差估计.首先,比较建立模型的速度,在200次实验中,两种分类器模型建立的平均时间分别为:1.97 s和0.06 s,可以看出BP分类器所用时间较长.其次,通过十折交叉验证法,将得到的结果分别进行对比,如表1所示.

表1 BP分类器与C4.5分类器总体对比
从表1可看出,二者正确分类与错误分类的实例数量一致,但BP分类器的Kappa统计量高出C4.5分类器0.1%,Kappa统计量衡量对一个数据集预测分类与观察分类之间的一致性,Kappa统计量越高分类器的性能越好,反之则越差.再比较各类误差,BP分类器的平均绝对误差、均方根误差、相对均方根误差分别低于C4.5分类器1.5%、1.4%、2.92%,误差越低则分类器的性能越好,反之则越差.综上所述,对乳腺癌诊断而言BP分类器的稳定性和准确性均优于C4.5分类器.
再次,可通过ROC曲线(Receiver Operating Characteristic Curve),即受试者工作特征曲线评价两种分类器的诊断效果,诊断性试验的质量通常用敏感性和特异性来衡量[16].敏感性是指在患病的人群中诊断结果是肯定的比例,特异性是指在没有病的人群中诊断结果是否定的比例.以敏感性为纵轴,特异性为横轴,绘制二分类器的ROC曲线,如图5所示.敏感性和特异性分别表示为公式(7)与公式(8).
TP/(TP+FN)
(7)
FN/(TP+TN)
(8)
其中TP为正确的肯定、FN为错误的否定、FP为错误的肯定,TN为正确的否定.分析两种分类器的ROC曲线,曲线下面积记为AUC,在AUC>0.5的情况下,AUC越接近于1,说明诊断效果越好,而只有当AUC大于0.5且小于1时分类器才是有价值的,AUC在0.9以上时较准确.WEKA给出AUCbp=0.988,AUCC4.5=0.968,AUCbp比AUCC4.5大0.02,因此BP分类器的诊断效果比C4.5分类器的好.
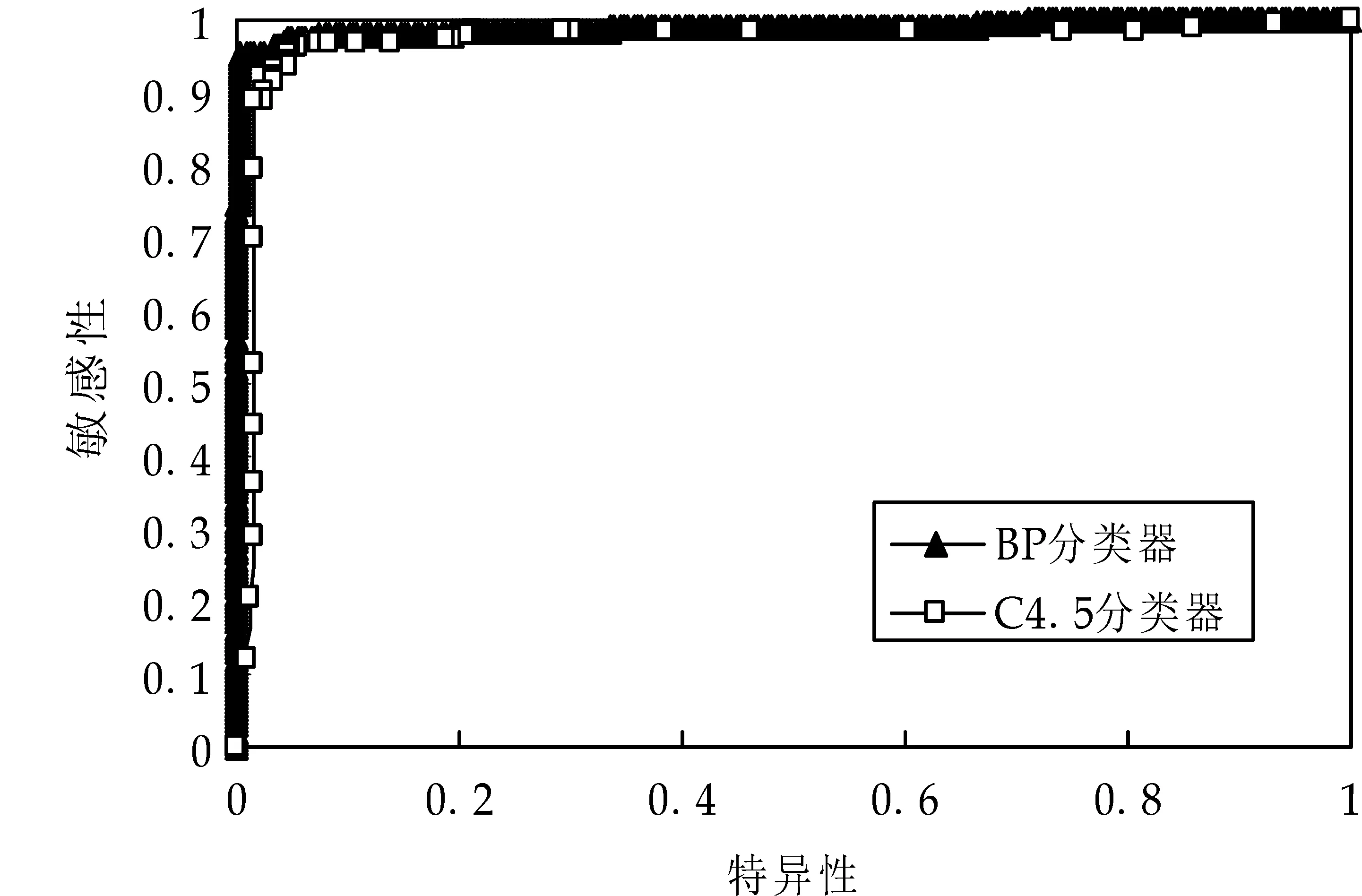
图5 BP分类器与C4.5分类器ROC曲线对比
5 结束语
医生可通过训练数据所建立起的分类器模型,录入经过处理的乳腺癌数据,分类器模型便可给出对乳腺癌类型的诊断结果,以此来辅助医生做出诊断决策.采用BP算法与C4.5算法处理连续数值型的乳腺癌数据都可对乳腺癌进行诊断.虽然建立C4.5分类器的时间比建立BP分类器的时间短,但诊断模型被要求具有很高的稳定性和有效性,而通过上述实验分析比较可知,BP算法建立的分类器模型的稳定性和准确性均高于C4.5分类器.
[1] 顾成扬,吴小俊.基于EST和SVM的乳腺癌识别新方法[J].计算机工程与应用,2011,47(8):183-185,193.
[2] 黄哲宙,陈万青,吴春晓,等.中国女性乳腺癌的发病和死亡现况——全国32个肿瘤登记点2003~2007年资料分析报告[J].肿瘤,2012,32(6):435-439.
[3] Alagugowri.S,Dr.T.Christopher.Enhanced heart disease analysis and prediction system using data mining[J].International Journal of Emerging Trends in Science and Technology,2014,1(9):1 555-1 556.
[4] Kenneth R,Robert K,Joseph.Machine learning,medical diagnosis,and biomedical engineering research-commentary[J].Biomedical Engineering OnLine,2014,13(1):94-103.
[5] Katja Hansen, Grégoire Montavon, Franziska Biegler,et al.Assessment and validation of machine learning methods for predicting molecular atomization energies[J].Theory Comput,2013,9(8):3 404-3 419.
[6] Smaranda B,Florin G.Error-correction learning for artificial neural networks using the bayesian paradigm application to automated medical diagnosis[J].Journal of Biomedical Informatics,2014,52:329-337 .
[7] 李友坤.BP神经网络的研究分析及改进应用[D].淮南:安徽理工大学,2012.
[8] Jose M,Pablo E,Carlo B,et al.Prediction of the hemoglobin level in hemodialysis patients using machine learning techniques[J].Computer Methods and Programs in Biomedicine,2014,117(2):208-217.
[9] 林士杰.ID3算法、朴素贝叶斯算法和BP神经网络算法的比较和分析研究[D].呼和浩特:内蒙古大学,2013.
[10] 林玲玲.基于C4.5算法的高血压分类规则提取的研究[D].太原:太原理工大学,2012.
[11] 王 卓.基于粗糙集和C4.5决策树的临床病例数据分类研究[J].软件导刊,2014,13(5):61-64.
[12] 赵永晖.数据挖掘算法ID3的改进研究[J].电脑开发与应用,2014,27(4):61-63.
[13] 苗红星,余建坤.基于决策树的ID3算和C4.5算法的比较[J].现代计算机(专业版),2014,15(5):7-10,14.
[14] 刘晓宇.C4.5算法的一种改进及其应用[D].青岛:中国海洋大学,2013.
[15] 魏 浩,丁要军.一种基于属性相关的C4.5决策树改进算法[J].中北大学学报(自然科学版),2014,35(4):402-406.
[16] Ya Wen Hsiao,Urban Fagerholm,Ulf Norinder.In silico categorization of in vivo intrinsic clearance using machine learning[J].Pharmaceutics,2013,10(4),1 318-1 321.
Comparison and analysis of BP algorithm and C4.5algorithm in diagnosis of breast cancer
YANG Yun, DONG Xue, QI Yong
(College of Electrical and Information Engineering, Shaanxi University of Science & Technology, Xi′an 710021, China)
At present,a large number of data mining techniques are applied in the medical field for diagnosis of the disease.In view of breast cancer incidence rate increased continuously,in order to assist the doctor make a diagnosis decision-making,the BP neural network algorithm and C4.5 decision tree algorithm which have excellent learning ability were used to analyze the data of breast cancer.In order to predict the type of breast cancer tumor,and the performance of the two established classifiers were compared.The study found that the performance of BP classifier in the diagnosis of breast cancer is better than C4.5 classifier.
breast cancer classification; BP algorithm; C4.5 algorithm; classifier performance
2015-04-12
陕西省科技厅科学技术研究发展计划项目(2014K15-03-06); 西安市科技计划项目 (NC1403(2),NC1319(1))
杨 云 (1965-),女,陕西咸阳人,教授,博士,研究方向:数据仓库与数据挖掘
1000-5811(2015)03-0163-04
TP391.9
A
