分布式一致性算法的研究及应用
2015-04-29王志瑞王幕天刘正涛黄慧
王志瑞 王幕天 刘正涛 黄慧


摘 要: 为了能在分布式环境下使用FibJs开发出持续高可用性的服务,并能保证分布式环境下的数据一致性,研究了分布式系统中的一致性问题。分析了分布式一致性算法Paxos,研究了该算法的工作原理,并对该算法进行了优化。根据算法思想设计了一种适应于分布式环境下的数据一致性的方案,采用FibJs对该方案进行了实现,并在集群环境下对该方案进行了检验。验证结果表明,该方案能够很好的解决分布式环境下数据一致性问题。
关键词: 一致性算法; Paxos; 分布式系统; 数据一致性; FibJs
中图分类号:TP399 文献标志码:A 文章编号:1006-8228(2015)12-13-05
Research and application of distributed consensus algorithm
Wang Zhirui, Wang Mutian, Liu Zhengtao, Huang Hui
(Department of Computer and Information Engineering, Sanjiang University, Nanjing, Jiangsu 210012, China)
Abstract: In order to use FibJs to develop a continuous high availability service in distributed environment and to ensure the consensus of data in the environment, this paper studies the consensus problem in distributed systems. The distributed consensus algorithm Paxos is analyzed; the working principle of the algorithm is studied and then is optimized. According to the idea of the algorithm, a data consensus scheme adapted to the distributed environment is designed; the scheme is implemented by using FibJs and has been verified in a cluster environment. The verification results show that the proposed scheme can solve the consensus problem in distributed environment.
Key words: consensus algorithm; Paxos; distributed system; data consensus; FibJs
0 引言
當今,企业对计算机的依赖越来越强,为了保证企业的关键业务不出现故障,出现了双机热备,双机双工相关的技术来保证系统的稳定性,但是这些方案的投资和部署难度都比较大,对于一些传统的应用支持比较好,而对于一些新技术的支持不是特别的好。为了能在分布式环境下使用FibJs开发出持续高可用性的服务,并能保证分布式环境下的数据一致性。
本文研究了分布式系统中的一致性问题,研究了分布式一致性算法Paxos的原理,并对该算法进行了优化。基于Paxos算法的思想设计出了一种适用于分布式环境下的数据一致性的方案。采用FibJs对该方案进行了实现,并在集群环境下对该方案进行了检验。结果表明,该方案能够很好地解决分布式环境下的数据一致性问题。
1 一致性算法Paxos
Paxos是由微软的Leslie Lamport提出的一种基于消息传递的分布式一致性算法,其解决的问题是:一个分布式系统中如何就某个决议达成一致。Paxos可以应用在数据复制、命名服务、配置管理、权限设置和号码分配等场合[1-2],是解决分布式一致性问题最有效的算法之一。现实中一些优秀软件的心脏,如Cassandra,Google的Spanner数据库,分布式锁服务Chubby都是利用Paxos算法设计的。
在分布式系统中节点崩溃、网络故障时常会发生,Paxos算法侧重解决的便是在一个可能发生上述异常的分布式系统中就某个值达成一致,保证不论发生何种异常,都不会破坏系统的一致性。
2 算法分析及优化
2.1 算法分析
在Paxos算法中,有三种角色,Proposer,Acceptor,和Learner[3-4],一个节点可以兼有多重角色。Proposer提出提案,提案是一个有序对
提案在批准过程中需要满足三个条件才能保证数据的一致性[1]:①提案只有被Proposer才可以批准;②每次只能批准一个提案;③只有提案被批准后Learner才可以获取这个决议。为了保证提案的惟一性,只有Acceptor没有收到编号大于M的请求时,才可以批准编号为M的提案。在这些约束的基础上可以将提案的批准过程分为三阶段[7-8]:Prepare阶段,Accept阶段,Notify阶段。
Prepare阶段(初次提出提案,查看是否能够被接受):Proposer设定一个新的提案编号M,并将prepare请求发送给Acceptors中的多数派;Acceptor收到请求之后,如果提案编号大于它之前己批准的任何提案编号,则Acceptor将自己上次批准回复给Proposer,并承诺不再批准小于M的提案;否则拒绝Proposer,Proposer收到拒绝后,会设定一个新的提案编号M+n,继续向Acceptors中的多数派发送prepare请求。
Accept阶段(再次确认提案是否被所有的Acceptors接受):当Proposor收到了多数派Acceptors确认回复之后,便进入了Accept阶段。它需要向所有回复prepare请求的Acceptors发送一个针对[M,V]的accept请求,V就是收到响应中编号最大的M提案的值,若响应中不包含任何值,那Proposor可以自由决定value。只要Acceptor没有对编号大于M的提案响应,Acceptor就可以最终批准这个请求,如果在Prepare阶段之后,Acceptor又对大于M的提案作了响应,则Acceptor就可以拒绝这个请求。
Notify阶段(学习过程):当Proposor收到多数派Acceptors的accept请求的确认回复后(反之则回到Prepare阶段重新提交新的提案),该提案被选定,就向所有的Learner发送通知,Learner接受通知更新Value。
2.2 算法优化
Paxos是基于消息传递的算法,当主机数量较多,Proposer角色和Acceptor角色较多时,在每个提案的批准过程中,会出现过多的通信量,使得数据一致性代价过高,因此在实现中需要对Paxos算法进行优化。
Proposer数量过多时,当Proposer提案被拒绝后,Proposer会不断的提高编号继续提交,因此会出现过多的通信量,为了杜绝这种不断竞争的现象,可从所有的Proposer中竞选出一个或少量几个主Proposer,只允许主Proposer提出提案,杜绝恶性竞争,减少提案批准过程中的通信量。但是也会出现单点故障问题,因此在系统运行过程中如果发现主Proposer出现故障,所有的从Proposer就通过Paxos算法竞选出一个新的主Proposer,接替原主Proposer的工作。
3 数据一致性方案的设计与实现
Paxos算法已经有了一些实现方案,其中包括Google的分布式锁服务chubby,Google的Spanner数据库,开源分布式NoSQL数据库系统Cassandra等[6],这些都是当前比较优秀的数据一致性产品。为了能够在开源项目FibJs的开发过程中保证数据一致性,我们在FibJs环境下根据Paxos算法思想对数据一致性进行了设计与实现,并对该方法进行了实验检验。
3.1 一致性方案的设计
Paxos算法设计的角色是三个:Proposer,Acceptor,Learner。本方案在设计过程中,根据Paxos算法思想设计了如下三个角色:Looking,Follower和Leader。要求集群机器数是奇数,最少三台,并通过DNS服务器维护集群内主机的IP和域名信息。
Looking角色:当一个新的节点加入后,它的角色默认为Looking,Looking会向所有的节点发送选举消息来确认Leader,可能是系统中已有的Leader,或者重新选举出的Leader。当发现Leader宕机后,其他节点也会转变为Looking并执行重新Leader选举。
Follower角色:当选举结束后,一个节点会变成Leader,其他节点发现Leader选举出来后则会成为Follower。Follower角色可以当做Paxos算法中的Acceptor和Learner,用来批准Leader的提案和执行Leader的决议。
Leader角色:选举完成后,某个节点会转变成Leader。它负责处理客户端发送的所有请求。对于写请求,Leader会采用一致性协议将请求廣播给所有Follower,得到过半的Follower批准后再通知Follower执行;对于读请求,可由Leader直接执行。它也管理着Follower节点,检测节点是否正常通信,并提供告警功能。
集群中每个服务节点都是平等的,都可以被选举为Leader和Follower角色,因而在架构上也是相同的。每个节点都包含三个基本功能模块。
⑴ 网络通信模块:主要用来实现节点之间的通信,并在通信的基础上实现心跳连接(检测节点间的连接状态)。
⑵ Paxos算法模块:主要用来实现角色转换和Leader选举,是系统中比较重要的模块。
⑶ 数据管理模块:用于执行数据的读/写操作和节点间的数据同步,当有新节点或者故障恢复后的节点时,通过数据同步来保证与其他节点的数据一致。
3.2 一致性方案的实现
3.2.1 网络通信模块
该模块主要包括节点间的网络通信和心跳连接两个主要部分,其中节点通信主要采用RPC(Remote Procedure Call Protocol)框架实现,FibJs中内置有RPC框架的功能,直接使用即可。心跳连接主要用来检测Follower与Leader之间的通信状态,并告知Follower当前的数据日志编号M,当Follower发现和Leader不一致时通知数据管理模块进行数据同步。
具体算法流程:首先由Follower发起keepAlive请求,然后等待一段时间后接收响应。当Leader收到Follower的keepAlive请求时,会将Follower的sid写入阻塞队列,再阻塞一段时间后响应给Follower,同时将该sid移除阻塞队列,等待下次keepAlive请求再写入。而Follower接收到响应后会立刻再次发起keepAlive请求。这样Leader上总会有keepAlive请求阻塞,Leader也从而得知它与Follower之间的通信是否正常。阻塞时间的设定可根据服务器的压力进行调节,以确保运行高效。
当某个Follower等待了两倍于阻塞时间后仍未接收到Leader的响应,则它会认为Leader已不存在或已崩溃,然后它会转变成Looking状态,并开始发起选举。同样的,Leader也会定期检查是否存在Follower节点通信异常(通过检测阻塞队列内节点的个数),若大多数节点都无法与其通信,那么Leader会自己转变成Looking状态并开始选举。
3.2.2 Paxos算法模块
该模块主要包括角色转换和Leader选举。Leader选举借助Paxos算法思想,利于多数派的投票来确定,选举模块包括了选举启动,消息传输,选举算法实现这几个步骤。
首先确定投票所用到相关参数。
sid:用来惟一标识每个节点的整数值,值越大则权重越大。在这里表示为选举的Leader,开始时Looking都会选举自己为Leader。
clock:用来区分不同的选举轮次,初值为0,每进行一轮值加1。
leader:当Leader和Follower接收到投票时会返回当前系统中的leader。
voteSet:Looking接受到投票时,会返回voteSet,即自己的投票集合。
选举算法的工作机制如下,算法中AB阶段的流程图见图1。ACD阶段流程图见图2。
[节点状态][A][Looking] [B][sid,clock] [Looking] [比较clock] [比较sid][相等] [\&忽略\&\&][小][\&更新clock
清空投票
sid加入投票集合\&\&] [大][A] [\&更新clock\&\&] [大][\&sid加入投票集合\&\&][A] [接受返回值] [Voteset,clock] [Voteset,clock] [比较clock] [大][Follower] [Leader] [Voteset,clock][leader,clock]
图1 AB阶段流程图
A:发送投票:当节点状态为Looking时,会向集群内所有节点发送投票,投票中包含投票集合中最大的sid和clock,初次发送时会用自己的sid。
B:接受投票:不同状态的节点接受到投票后处理方式不同。
B.1:Looking节点,会根据投票中clock的值进行处理。
B.1.1:接收到的clock比自己当前的clock大,更新clock,并清空自己的投票集合,将sid加入自己的投票集合,并返回voteSet和clock,然后从A开始继续投票。
B.1.2:接收到的clock比自己当前的小,则忽略该投票,并将voteSet和clock返回给对方。
B.1.3:接收到的clock与自己当前的一致,若接收到的sid比自己大,则更新投票sid,并将该sid加入自己的投票集合,然后从A开始继续投票;若接收到的sid比自己的小,并返回voteSet和clock。
[C] [比较clock] [包含参数] [相等][\&更新clock\&\&] [大] [leader] [判断sid][\&忽略\&\&][D] [大][\&更新投票\&\&] [voteSet] [包含参数] [leader] [voteSet][\&更新投
票集合\&\&][A] [小] [voteSet,clock
leader,clock]
图2 ACD阶段流程图
每个Looking都会维护一个投票集合,当接收到投票时便要根据clock进行更新,然后判断集合中是否存在节点获得的投票已经过半,如果存在,等待一段时候后再观察是否有变话,若有变化则继续执行选举,若无变化则跳至D。
B.2:Follower節点或者Leader节点:会直接返回当前的Leader和clock,并判断clock是否比自己大,如果大就更新。
C:接受返回值:Looking节点会根据返回值的clock值进行处理。
C.1:若clock比自己当前的大,就更新自己的clock。若返回值中包含Leader参数,则跳至D;若包含voteSet参数,则更新投票集合,并从A开始继续投票。
C.2:当clock和自己当前的相同时,若包含Leader参数,则跳至D;若包含voteSet参数,判断sid,若大则更新投票,并从A开始继续投票。
C.3:一般不会有clock比自己当前的小,若出现则通常为网络故障。可直接忽略该返回值。
D:确定Leader:Looking会根据Leader的sid是否是自己来转变自己的角色,若为Follower,则与Leader进行心跳连接,当一段时间都未得到Leader的响应,则放弃,并转变为Looking开始新一轮选举;若为Leader,就等待Follower与自己连接,当一段时间没有过半Follower连接,则转变为Looking开始新一轮选举。
3.2.3 数据管理模块
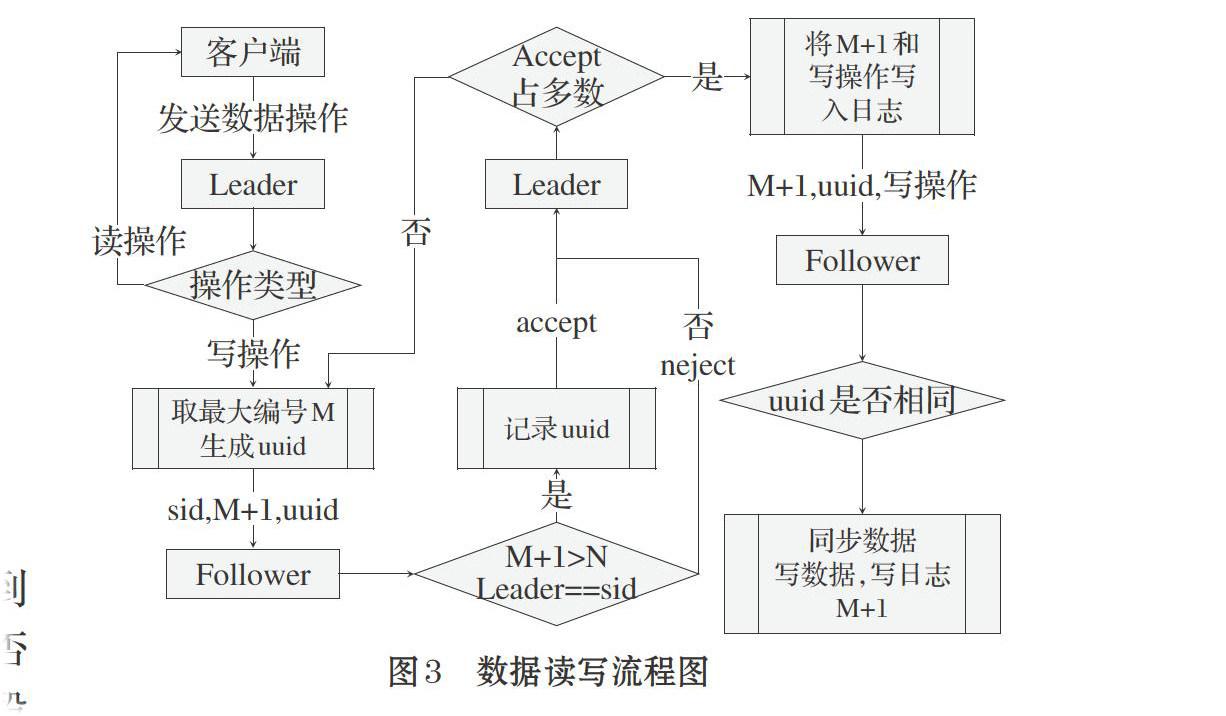
数据同步模块用来实现数据的读写操作,并保证节点之间的数据同步。在数据写入过程中为了能够记录每一次的写操作,并保证节点间的数据一致性,引入了编号M,每写入一次数据则加1;为了保证Follower批准的提案和执行的提案是同一个提案,引入了惟一编号uuid,具体的算法工作机制如下。算法的流程图见图3。
[uuid是否相同][\&将M+1和
写操作写
入日志\&\&][Follower][Leader][\&同步数据
写数据,写日志
M+1\&\&] [M+1,uuid,写操作][客户端] [发送数据操作] [操作类型] [写操作][\&取最大编号M
生成uuid\&\&] [Follower][sid,M+1,uuid][\&记录uuid\&\&] [M+1>N
Leader==sid] [是] [Leader] [accept] [否
neject] [Accept
占多数] [是] [否] [读操作]
图3 数据读写流程图
A:客户端将数据操作请求发送给Leader节点。
B:Leader判断请求类别,如果读操作直接返回读取结果;如果写操作,取出当前保存的最大编号M,生成一个uuid,并将编号M+1同Leader的sid一起发送给Follower,并保存最大编号为M+1。
C:Follower接收到Leader的写请求时会先判断编号M+1是否比本地保存的最大编号N大,并且它的Leader是否为sid,然后记录uuid,并返回accept,否则返回reject。
D:当Leader收到多数Follower的accept反馈后,就将编号M+1和写操作内容同uuid发送给所有Follower,并将操作写入日志,然后反馈给客户端写入完成。若收到多数reject,则应该是发生了Leader更换,先检查与自己连接的Follower是否为大多数,若还是大多数,则跳至B进行重试。
E:Follower接受到执行请求时,判断uuid是否相同,然后从Leader的日志中读取编号N到编号M的写操作,执行并写入本地日志,再执行请求的写操作并写入日志,并更新N为M+1。
4 实验检验
为了方便测试,我们组建了由三台服务器构成的集群,每台服务器上使用FibJs作为服务运行框架,并放置了两个SQLite文件,分别用来存储数据和日志。
服务启动后,首先进行的是Leader选举,选举成功后开始检测心跳,当接受到客户端的写请求后进行数据写入,如果执行成功则将对应的数据操作脚本输出。具体运行结果见图4。
图4 Leader选举与执行数据写操作
5 结束语
本文给出的方案能够将FibJs开发的服务部署到集群中,并对外提供持续的可用性,后期考虑对该方案继续研究和优化,以期将该方案设计成FibJs的一个组件,能够集成到FibJs中,让更多的人员参与该方案的优化和使用。希望该方案可为其他系统的设计提供参考。
参考文献(References):
[1] 许子灿,吴荣泉.基于消息传递的Paxos算法研究[J].计算机
工程,2011.37(21):287-290
[2] 高石玉,艾中良,刘忠麟.应用Paxos算法构建自组织网络[J].
计算机工程与应用,2014.6:88-91,204
[3] Lamport L. Paxos Made Simple[J].ACM SIGACT News,
2001.32(4):18-25
[4] Jim G,Lamport L. Consensus on Transaction Commit[J].
ACM Transactions on Database Systems,2006.1:133-160
[5] 杨春明,杜炯.一种基于Paxos算法的高可用分布式锁服务系
统[J].西南科技大学学报,2014.2:60-65
[6] 赵瑞芬.云存储中基于PAXOS算法的数据一致性研究[J].科
技视界,2013.34:64,121
[7] 赵黎斌.面向云存储的分布式文件系统关键技术研究[D].西
安电子科技大学,2011.
[8] 陈鸿钦.基于Paxos的Leader选举与分布式日志复制系统[D].
东南大学,2012.
[9] 倪超.从Paxos到ZooKeeper分布式一致性原理与实践[M].
电子工业出版社,2015.
