1基于GPU的并行高性能AC算法
2015-04-29徐东亮张宏莉姚崇崇
徐东亮 张宏莉 姚崇崇
摘 要:随着网络的发展,网络流量的增长速度与网络安全系统的过滤能力之间的矛盾日益突出。作为网络安全系统的核心模块——模式匹配模块的处理能力受到严峻的挑战。传统串行模式匹配算法已经很难满足当前网络的需求。本文改进了传统的AC算法,利用高性能专用并行处理芯片——GPU来提高AC算法的处理速度,提出了一种G-AC算法。实验表明,在不同数据集上,其性能分别是传统AC算法的10倍以上。
关键词:AC算法;GPU;模式匹配;G-AC算法
中图分类号:TP391.41 文献标识号:A 文章编号:2095-2163(2015-)02-
GPU-based Parallel High Performance AC Algorithm
XU Dongliang, ZHANG Hongli, YAO Chongchong
(School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China)
Abstract: With the development of the network, the contradiction between the growth rate of network traffic and the filtering capability of the Network security system have become increasingly prominent. As the core modules of network security systems, pattern matching module processing capacity faces serious challenge. The traditional serial algorithm for pattern matching has been difficult to meet the current needs of the network. This paper improves the traditional AC algorithm, using high performance special parallel processing chip GPU to improve the processing speed of AC algorithm, and proposes a new G-AC algorithm. Experiments show that its performance is 10 times more than the performance of traditional AC algorithm on different data sets.
Keywords: AC Algorithm; GPU; Pattern Matching; G-AC Algorithm
0 引 言
模式匹配[1],即字符串匹配,其应用十分广泛,如网络入侵检测,信息检索,生物信息等。模式匹配方法的研究历史已近半个世纪之久。1975年由Ahot Corasick提出的Aho-Corasick (AC)算法[2]是经典的多模式匹配算法之一,至今仍然颇具现实影响及客观性的实用性。经过半个世纪的发展,已经有多个模式匹配算法的性能接近甚至达到理论上限。但随着网络的发展,网络流量的增加却日益加快,模式匹配模块的性能已经成为网络安全系统的瓶颈。
进入21世纪,许多高性能专用硬件芯片的兴起,使模式匹配进入了利用硬件加速传统算法的时代。许多研究者开始转向和聚焦于那些具有强大并行计算能力的硬件上,各种硬件和专用芯片在模式匹配领域的应用日益深入和多样化。本文就是将传统的AC算法进行结构改进,再移植到GPU上,并对其性能进行提高。
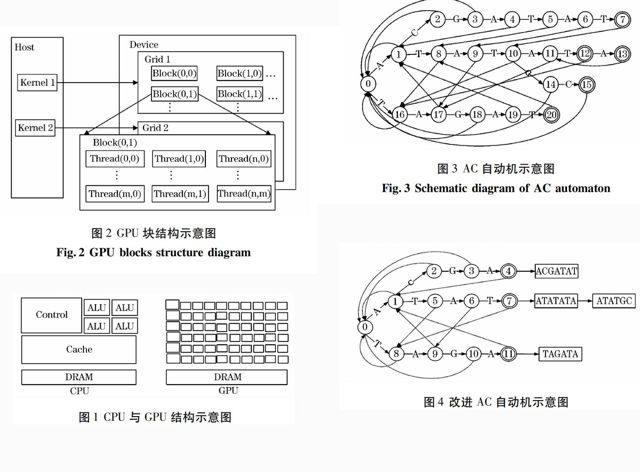
GPU,即图形处理单元。自从1999年NVIDIA公司发布了第一款GPU以来,GPU的发展就异常迅猛,但当时的GPU只能用于处理图形计算,大量的计算资源则处于闲置浪费中。将GPU用于图形处理以外的其它领域即稱为基于GPU的通用计算(General-purpose computing on graphics processing units,GPGPU)。随着GPU的可编程性越来越高,GPU计算研究吸引了越来越多研究者的青睐和关注。CPU的逻辑运算部件较多,具有强大的逻辑运算能力,而GPU数理运算部件较多,由于过多的计算部件占用了GPU太多的硬件空间,从而导致其逻辑部件较少,并不适合处理大量逻辑运算,为此在模式匹配计算中大都需要借助CPU进行逻辑计算。GPU与CPU的结构对比如图1。CPU+GPU的异构模式是GPGPU计算的通用模式,其中,GPU负责密集型海量数据的并行处理,而CPU则主控不适合并行计算的事务管理和复杂逻辑处理。这种模式利用了GPU的高带宽和高性能的并行计算能力,并藉此弥补了CPU的计算能力不足的劣势。但是,传统的CPU+GPU的异构处理模型却并不适用于软件人员的开发,其应用范围较为有限。
图 1 CPU与GPU结构示意图
Fig.1 Structure of CPU and GPU schematic diagram
2007年,随着NVIDIA公司以CUDA(the Compute Unified Device Architecture)[3]为代表的GPU通用计算API的普及,GPU的通用计算在计算机领域的应用范围呈现拓展扩张态势。CUDA是一种软硬件结合的架构,可使GPU更易于解决复杂的计算问题以及更便于实现数据并行计算。其中包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎,开发人员将不再使用图形学API,而是利用C语言来编写程序。支持CUDA的GPU与以前的GPU相比,在架构上完成了两项改进,一是引入了片内共享存储器,支持线程间通信和随机写入;二是采用了统一处理架构,可以更加有效地利用计算资源。CUDA的出现极大地方便了各类研究开发人员。GPU类单指令多数据流(Simple Instruction Multiple Data, SIMD)体系结构(如图2所示),大量的计算部件则使其善于处理模式匹配算法中的对比字符这一类计算密集型操作。
图 2 GPU块结构示意图
Fig. 2 GPU blocks structure diagram
1 相关工作
Giorgos Vasiliadis等人利用CUDA通用并行计算架构实现了Snort中模式匹配模块,将经典的AC算法移植到GPU上,设计了Gnort[4]系统。该系统利用DMA在CPU与GPU之间进行数据传输和GPU的执行计算的异步性实现最大吞吐量到2.3Gbit/s,在真实网络环境中,其性能则是Snort的两倍以上。该工作也将单模式匹配算法KMP、BM在GPU上进行了实现,与在CPU上相应算法相比后得知,性能并未获得显著的提高,这与PixeSnort系统使用KMP算法表现的性能相符,由此即可得出结论,单模式匹配算法不适合移植到GPU上。文献[5]将经典的AC算法在Cray XMT、GPU和分布式内存架构三种不同的硬件上付诸了实现,并根据最小化使用内存的原则,对三种硬件下的AC算法性能进行了对比可知,GPU的性能表现不俗。
近几年,GPU在网络安全系统及模式匹配方面的研究与应用已经更趋深入,也日渐广泛。文献[6]将K-Mismatch技术的近似模式匹配算法用GPU进行了完整的实现。其中,文献[6]还提出了线程并行算法、块-线程并行算法和OPT-block-thread并行算法以及相应的GPU实现。文献[7,8] 则在GPU上设计实现了层次化并行正则表达式模式匹配自动机,且利用GPU作为协处理器,处理字符匹配问题。大多数基于GPU实现的模式匹配方法都是将GPU作为协处理器,协助CPU分担主要的计算工作。
2改进AC自动机
AC算法是一种经典的前缀匹配算法。该算法使用了一种被称做Aho-Corasick (AC)自動机的特殊自动机。该自动机由模式集P生成,也就是对trie树添加了失败转移函数扩展而成。图3所示为集合P={ACGATAT, ATATATA, ATATGC, TAGAT}的AC自动机。自动机在模式匹配的应用中,性能稳定,并因其具有不依赖于模式集合和文本本身的特点,而一直得到应用者的首肯和认定。但自动机有一个缺点,就是将需要很大的内存空间,尤其在正则表达式的匹配中,正则表达式的通配符等引起的状态爆炸,将进而导致内存爆炸,这即使得自动机在应用中受到了强力限制。
图 3 AC自动机示意图
Fig.3 Schematic diagram of AC automaton
由于传统AC算法的结构占用内存过大(每个字符均需要占用1KB的内存空间),当模式集超过1万条时,普通机器的内存也就难以满足要求,为此本文将对标准的AC算法进行内存压缩。
经过统计发现,AC自动机中深度4以内的4个字符被访问的频率总和为83.85%,深度5以内的5个字符被访问的频率总和则为91.6%,而深度6以内的6个字符被访问的频率总和将可达到93.93%,从以上三项统计数据可以看出,前5个字符被访问的频率较高,从第6个字符开始,访问较少。为此研究中可以只建立前5个字符的半AC自动机,而第6个字符以后的字符,即以字符串的形式存储在自动机叶结点的尾部。匹配时,用前5个字符的半自动机进行过滤,前5个字符全部命中,而后再用尾部的剩余字符串进行验证。半自动机结构可如图4所示。
图 4 改进AC自动机示意图
Fig.3 Schematic diagram of the improved AC automaton
3 G-AC算法
GPU的内存分为Globe Memory、Texture Memory和Shared Memory三级,其中Globe Memory是GPU的主存,最大,速度也最慢;Shared Memory属于片上存储器,最小,速度最快,本文所用GPU的Shared Memory即为48KB,Texture Memory则位于两者之间。
实际应用中,半AC自动机远远超过50KB,无法存储于片上的SharedMemory,而只能存储于Texture Memory。
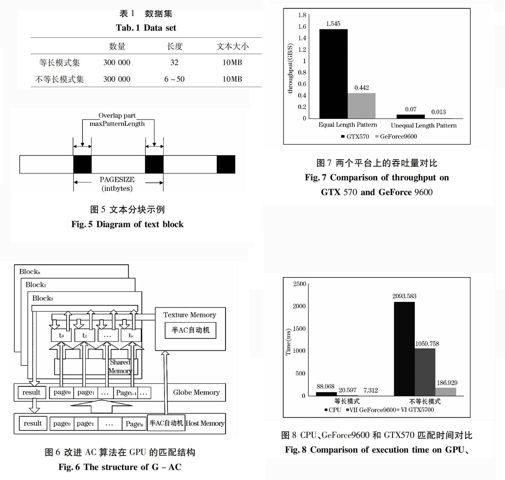
GPU是以块(Block)为计算单位的,每一块默认为64KB,为此可将等匹配文本以64KB为单位划分成块,最后一块可能不满64KB。为了不致遗漏,块与块之间要有一部分重叠,重叠的长度即为最长模式匹配的长度,具体如图5所示。
图5 文本分块示例
Fig.5 diagram of text block
由于GPU中逻辑单元较少,不适合处理逻辑运算,就使得半AC自动机的建立和待匹配的分块都需要在CPU完成。而GPU与CPU的内存却不能统一寻址,所以半AC自动机和文本块即需从CPU的主存中转移到GPU的Texture Memory和Globe Memory中。完整的匹配结构如图6所示。
图6 改进AC算法在GPU的匹配结构
Fig.6 The structure of G-AC匹配时,将n个文本块分别存储到GPU的n个block中,所有的block同时进行匹配,匹配的结构存储到每个Block的Shared Memory中,最后将结果汇总到Globe Memory中,再转送至CPU的主存中输出。
4 实验结果与分析
实验平台为,CPU Intel i5-2300 2.8GHz,内存 4GB;GPU GeForce9600GSO/GTX570,Globe Memory 512MB/1GB,CUDA 3.20,OS Fedora13。
数据集分为等长模式和不等长模式两部分,每部分都是不30万条,不等长模式集中模式长度为6~50个字符不等,待匹配文本的大小为10MB,如表1所示。
表1 数据集
Tab.1 Data Set
数量
长度
文本大小
等长模式集
300000
32
10MB
不等长模式集
300000
6-50
10MB
图7分别是两个数据集在GTX570和GeForce9600并行平台上的实验对比结果。由图7可以看出,GTX570的吞吐量远远大于GeForce9600,这就说明GTX570的性能要优于GeForce9600。
图7 两个平台上的吞吐量对比
Fig.7 Comparison of throughput on GTX 570 and GeForce 9600
图8是CPU、GeForce9600和GTX570三个平台的执行时间对比,在CPU上运行的是经典AC算法。由图8可以看出,在两个GPU上运行的改进AC算法的效率要远远高于原始AC算法。
图8 CPU、GeForce9600和GTX570匹配时间对比
Fig.8 Comparison of execution time on GPU、GTX 570 and GeForce 9600
5 结束语
本文提出了一个改进的AC算法,并将其移植到两个不同的GPU平台上。通过实验发现,不同的GPU平台对算法的性能有较大的影响,性能高的GPU执行算法的效率更高;同时,无论在等长模式集还是不等长模式集上,改进的G-AC算法的效率都远远高于经典的CPU上执行的AC算法。这一结果即可表明,将模式匹配算法移植到GPU上是可行且具有潜力的。
参考文献:
[1] Navarro G, Raffinot M. Flexible pattern matching in strings: practical on-line search algorithms for texts and biological sequences[M].New York: Cambridge University Press, 2002.
[2] AHO A V, CORASICKk M J. Efficient string matching: an aid to bibliographic search[J]. Communications of the ACM, 1975, 18(6): 333-340.
[3] NVIDIA. CUDA Best Practices Guide: NVIDIA CUDA C Programming Best Practices Guide CUDA Toolkit 2.3[M]. Santa Clara : NVIDIA, July 2009:15-25.
[4] VASILIADIS G, ANTONATOS S, POLYCHRONAKIS M., et al. Gnort: High performance network intrusion detection using graphics processors[C]// LIPPMANN R., KIRDA E, TRACHTENBERG A. (eds). RAID 2008. Springer, Heidelberg:LNCS, 2008,5230:116-134.
[5] TURNEO A, VILLA O, CHAVARRIA-MIRANDA D G. Aho-Corasick string matching on shared and distributed-memory parallel architectures[J]. Parallel and Distributed Systems, IEEE Transactions on, 2012, 23(3): 436-443.
[6] LIU Y, GUO L, LI J, et al. Parallel algorithms for approximate string matching with k mismatches on cuda[C]//Parallel and Distributed Processing Symposium Workshops & PhD Forum (IPDPSW), 2012 IEEE 26th International. Shanghai : IEEE, 2012: 2414-2422.
[7] Ponnemkunnath S, Joshi R C. Efficient Regular Expression Pattern Matching on Graphics Processing
Units[M]//Sanjay Ranka,Srinivas Aluru,Rajkumar Buyya:Contemporary Computing. Berlin
Heidelberg: Springer , 2011:92-101.
[8] LIN C H, LIU C H, CHANG S C. Accelerating regular expression matching using hierarchical parallel machines on GPU[C]//Global Telecommunications Conference (GLOBECOM 2011), 2011 IEEE. Houston: IEEE, 2011: 1-5.
1 基金項目:国家973重点基础研究发展计划(2011CB302605); 国家863高技术研究发展计划(2011AA010705, 2012AA012502, 2012AA012506); “十一五”国家科技支撑计划(2012BAH37B01); 国家自然科学基金。
(11226239,6110018,61173144),CNNICk201211043。
作者简介:徐东亮(1984-),男,山东威海人,博士研究生,主要研究方向:模式匹配,入侵检测、信息安全;
张宏莉(1973-),女,吉林榆树人,博士,教授,博士生导师,主要研究方向:信息内容安全、网络测量和建模、并行计算;
姚崇崇(1991-),男,河南驻马店人,硕士研究生,主要研究方向:字符串匹配、入侵检测。
