基于AC_QS多模式匹配算法的优化研究
2017-11-08董志鑫方滨兴
董志鑫+方滨兴
摘要:随着互联网的日益强大,互联网上数据急剧增多,如何在海量的数据中快速准确地找到所需信息,就显得尤为重要,这就需要多模式串匹配算法。多模式串匹配算法在越来越多的领域里都有应用,比如:信息安全领域中,入侵检测系统、防火墙等,在医学领域、数据挖掘、信息检索等等领域中均有广泛的应用。AC算法在多模式串匹配算法中是一个能达到线性时间的算法,其算法效率较高,AC_QS算法是在AC算法基础上增加坏字符规则,进一步增加了AC算法的匹配效率,但其空间复杂度较高。本文在AC_QS算法的基础上,对算法预处理和匹配过程中继续优化,并对字典树存储时进行了优化,使算法在空间和时间复杂度上得到进一步优化,提高了算法性能。实验结果也验证了该算法的高效性。
关键词: 多模式; 模式匹配; AC算法; QS算法
中图分类号: TP301
文献标志码: A
文章编号: 2095-2163(2017)05-0100-04
Abstract: With the Internet becoming more and more powerful and the data increasing dramatically on the internet, it is very important to find the needed information quickly and accurately in the mass of data, so it is determined to require multipatterns string matching algorithm. Multi-patterns string matching algorithm has been used in more and more fields such as information security, intrusion detection system and firewall, data mining and medicine, and also has a wide range of applications in the field of information retrieval and so on. AC algorithm in multipatterns string matching algorithm is a linear time algorithm, which can achieve high efficiency. AC_QS algorithm is to increase the bad character in the AC algorithm and then improve the matching efficiency of AC algorithm, but its space complexity is high. In this paper, based on the AC_QS algorithm, the algorithm will continue to optimize the preprocessing and matching process, and in the dictionary tree storage are optimized. After that, the algorithm in space/time complexity is further optimized, therefore the algorithm performance is improved. The experimental results also verify the efficiency of the algorithm.
Keywords: multiple patterns; pattern matching; AC algorithm; QS algorithm
0引言
模式串匹配算法,适用于从某个序列中,找到具有某种属性的模式段或者位置等信息。其中字符串查找就是最简单最常用的模式串匹配问题。多模式串匹配算法,就是从某个序列中,查找发现多个属性的模式段。在现实的应用里,多模式串匹配算法更加常用有效,有着许多典型的应用场景和巨大的需求。例如,应用在数据挖掘领域从新闻流里来寻找一些被选择的模式;应用在计算机、网络安全领域中检测识别某些敏感危险关键词来避免计算机或者网絡被攻击;应用在生物信息DNA搜索识别中[1],将DNA序列的近似搜索转换为大量精确模式的搜索。
基于现今主要的多模式串匹配算法,本文分析了各主流算法的优缺点,考虑到算法的有效实现的简易程度和算法复杂度等方面,对AC_QS算法[2]进行了优化,取得了良好的实验效果。
1主流多模匹配算法介绍
AC自动机算法[3]对于多模式串匹配问题给出了一个线性时间的算法,该算法基于一个有限自动机。一个线性时间的算法在最坏情况下,算法的运行效率是具有相当优势的。但另一种单模式串匹配的BM算法[4],就可以在匹配过程中进行跳跃,在文本匹配过程中跳过一部分不可能包括待匹配模式串的文本串继续搜索。CW算法[5]就是将上述2种算法进行结合,处理多模式串匹配问题,增加了AC算法在模式串匹配过程中的跳跃距离,减少了比较次数,算法更高效,但是占用的空间更多。其后,Horspool根据BM算法提出Horspool算法[6],该算法考虑了BM算法过于复杂,对算法进行了精简。Horspool算法应用于多模串匹配问题中的算法被称为Set Horspool算法[6]。后来,Wu与Manber 发现Set-Horspool算法在多模式串匹配中效果欠佳,提出与模式串结尾的2个字符进行比较的WM算法[7]。QS算法[8]也是一个单模式串匹配算法,相对于较经典的单模式匹配KMP算法[9],该算法在字符串匹配失败时,至少能够保证移动一位。AC_QS算法则是将上述2种算法的思想进行合并,对AC算法进行了优化,使得算法的效率进一步提升。在这之后,不断地出现各种基于AC算法以及其他多模式串匹配算法的优化算法。endprint
2优化算法DAC_QS算法
本文对于AC_QS算法的优化主要考虑从加大算法跳跃距离和减少每轮匹配字符比较次数两方面对其进行改进。本文主要在预处理、字典树存储和匹配过程三个方面进行优化,在减少匹配字符的比较次数上进行了一些特殊的优化,以达到提高算法效率的目的。
2.1预处理的优化
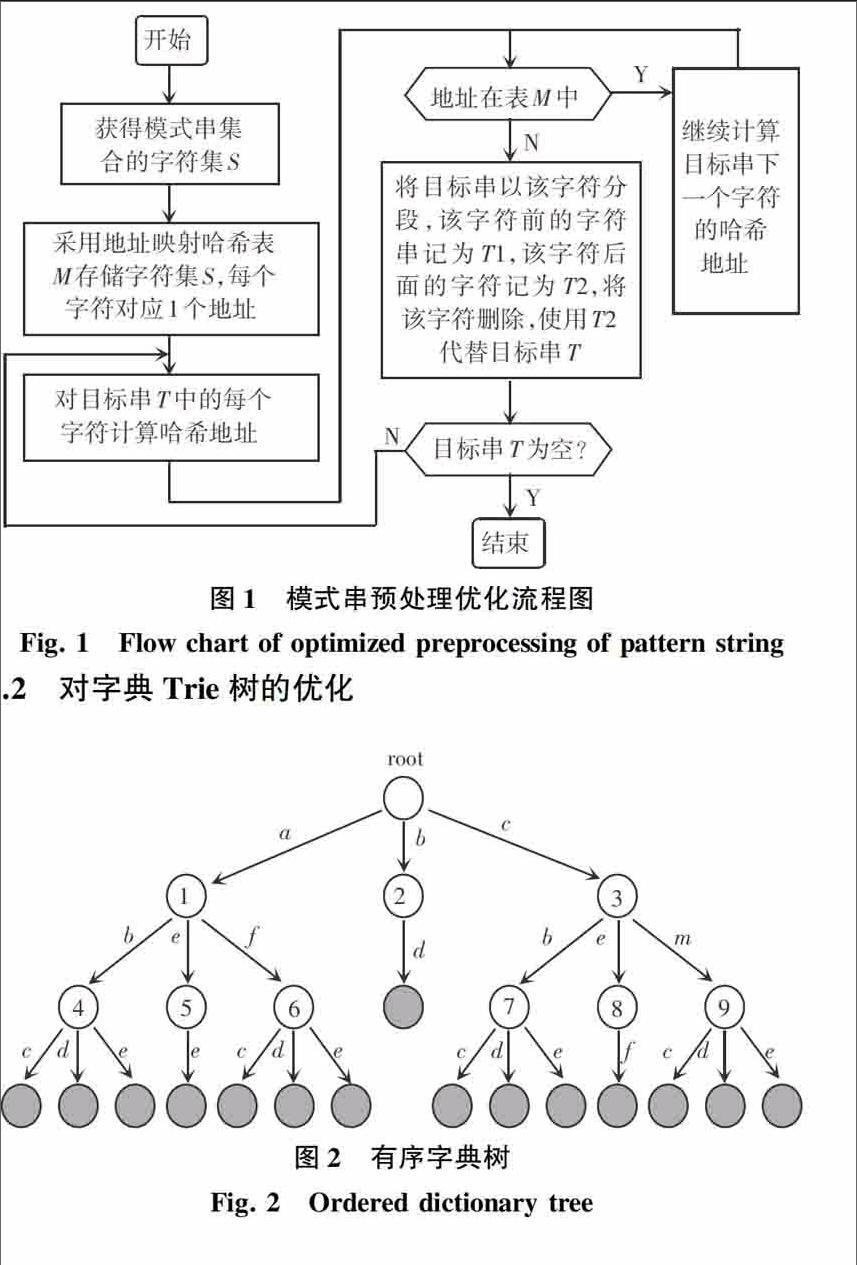
首先当网络上采集到数据,对数据分析处理后得到用于串匹配的数据,研究中用目标串T来表示。对于模式集合中的模式串,首先获得模式串集合的字符集S,即包含所有模式串中的字符的最小集合。对于目标串T中的每个字符,检验其是否在字符集S中出现,若字符c未出现在字符集S中,则以该字符为标准对目标串T进行分段,字符c前的字符串记为T1,字符c后面的字符记为T2,将字符c删除;依次继续向后进行检验,直到检验到目标串T的最后一个字符,此时目标串T被分为{ T1,T2,…,Tt+1},其中t为目标串T中不出现在字符集S中的字符个数。
因为字符集S不会经常变动,为了提高查找效率,对字符集采取哈希表的方式进行存储,提高查找效率,哈希函数即为每个字符对应的地址,因每个字符占用一个地址,所以不会出现冗余的情况,具体方法如下:
1)申请一段大小为28=256 B的内存M,每个内存地址对应字符集S中的一个字符。
2)对于目标串中的每个字符c,计算其哈希地址,判断是否在1)中的内存表M中,若在则表示该字符在模式串集合S中,即该字符在某个模式串中。
3)若字符c不在模式串集合S中,将目标串T以字符c进行分段,字符c前的字符串记为T1,字符c后面的字符记为T2,将字符c删除。
4)依次继续向后进行检验,直到检验到目标串T的最后一个字符,此时目标串T被分为{T1,T2,…,Tt+1},其中t为目标串T中不出现在字符集S中的字符个数。
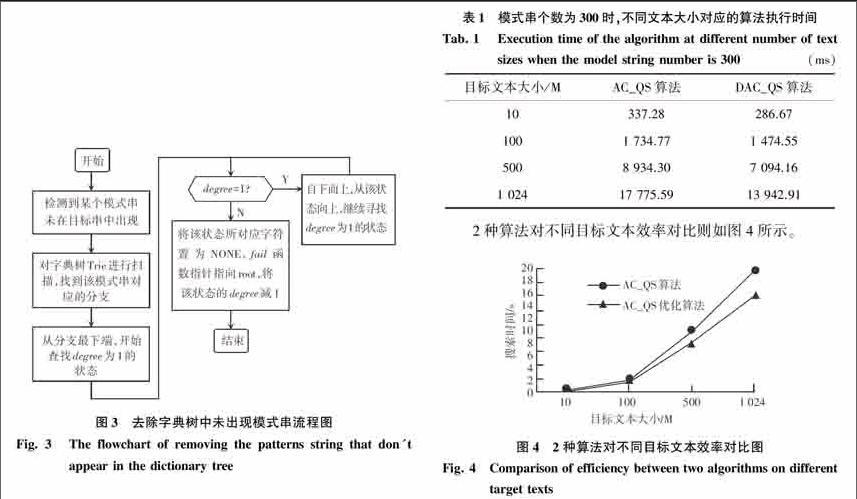
5)记模式串中最短模式串长度为PLmin,若在目标串T划分的集合{ T1 ,T2,…,Tt+1}中,删除其中存在的长度小于PLmin的目标子串Ti,其中0 综上可得,该优化算法的流程如图1所示。 这种方式处理后,相当于把原先在目标串与模式串匹配的时候的比较提前实现,因而并没有增加比较次数,同时因为采用的是哈希地址映射的方法,时间也是相当快的,首先若存在上述第5)种情况,则能进一步减少比较次数,减少的比较次数为删除的目标子串Ti长度之和,理论最好情况下,是删除了全部的目标子串,不需要进行自动机匹配算法,直接可以确定该数据不包含模式串。 对目标子串Ti的处理,可以采用2种思路:一是采用并行思想,在多台机器或者多个并行处理器上运行;二是针对每一个子串继续使用匹配算法进行匹配。因为目标串的不确定和字符集S的未知,无法确定具体情形下分出的目标子串个数,而且目标串本身的大小就并未超过常规,所以并行的思想并不一定能时刻发挥重要作用,且并行的时间会高于模式匹配的时间。针对每个目标子串进行匹配的时候仍然可以优化,以下2节将介绍具体的优化方法。 2.2对字典Trie树的优化 在利用AC算法建立AC自动机的过程中,在Trie树上进行优化,本文采用建立有序的字典Trie树的方式,即对Trie树的每条分支,Trie树同一层中表示的字符,左边小于右边,这样当对目标串进行匹配时,假设目标待匹配的目标串字符为h,总是在字典Trie树当前状态的下一层中选择中间状态对应的字符k进行比较,若目标串中的待匹配字符h大于字符k,则只需在字典树的右侧进行匹配,而无须比较同一深度内左侧的字符;同理,若目标串中的待匹配字符h小于字符k,则需在字典树的左侧进行匹配。举例说明如下: 对于模式集{abc, abd, abe, aee, afc, afd, afe, bd, cbc, cbd, cbe, cef, cmc, cmd, cme},图4展示了有序字典Trie的构建过程,构建的字典树如下: 在具体的实现上,可以对每个状态设置一个新的degree变量,用来存储当前状态的所能达到的下一状态的总数和,即相当于树的出度,当degree>2时,对此算法的优势即能体现出来,每次从degree/2所对应的状态开始比较。 该方法在字典树中的分布比较平均,每一状态所对应的下一状态较多,即对应较多的分支时,可明显减少比较次数,相当于二分查找,最优时间复杂度可达到O(log n),平均情况也明显好于未排序的Trie字典树。但此方法在建立字典树时会造成一定的时间和空间开销,但这都是在预处理时可以做到的,对于高效的匹配来说是值得的。 [BT5]2.3匹配过程中的优化 在實际中,可能存在这样的情况:某个或者某几个模式串并没有在目标串中出现,但是如果单纯地计算每个模式串中的每个字符在目标串中出现时,会花费大量的时间,特别是当模式串和目标串都比较有规模的情况下。因此,本文利用每个模式串的最后2个字符,若最后2个字符未在目标文本中出现,则表示该模式串肯定不在目标文本中出现,相对于完整的查找比较,可以大量减少比较次数,查找较高效。同时,因为该过程与模式匹配属于不同的处理过程,可以并行运行,在时效要求较高的时候可以采用一边对目标串进行串匹配,另一边并行地运行查找。 在并行处理的时候,需要对字典树进行相应的处理,最简单的处理为:当发现某个模式串最后2个字符未在目标串中出现时,直接将字典树中的该节点置为NONE,在自动机匹配时遇见为NONE的节点,不进行比较,直接利用fail函数进行跳转。因为是并行进行的,提高了总的匹配效率。每检查出一个模式串不在目标串中,就可以减少一次比较次数,但这种处理在实际效果中提高甚是有限,除非遇到特定的数据。 然后提出了另一种处理方法:当检测到某个模式串未在目标串中出现时,从头开始对字典树进行扫描,找到未匹配串,若该串只有自己一条分支,则将该串上的所有值置为NONE,所有fail函数指针指向root;否则找到该串中只有自己的部分分支,即由父状态只通过一个字符到达该模式中该字符的状态,而没有其他状态,并且该状态的所有子状态也只有一个状态,即按照从下到上的方式,找到2.2节中该模式串对应的degree连续为1的最上状态,将该状态的上一状态所对应的字符置为NONE,fail函数指针指向root,该状态的degree减一,该状态之后的状态则不会被访问到,相当于删除。该方法的流程图如图3所示。
上述方法的舉例说明如下:针对图2中的有序字典树,若检测到模式串cef不在当前匹配的目标串中,发现状态8的degree为1,继续向上,发现状态3的degree不为1,将状态8所对应的字符e设置为NONE,同时将状态3对应的fail函数指针指向root。
并行的时候并不会发生阻塞,是因为匹配过程是对字典树进行访问,并不改变字典树的值,而只有上述方法的进程改变字典树,只有一个写进程,所以,并不会发生阻塞。
3实验
为了对上述优化算法进行合理全面的验证,本节中将针对正常的AC_QS算法和优化后的算法在相同环境下,对同样的模式串和目标串进行验证,验证的主要标准是比较运行后的时间效率,通过对结果的分析得出最终结论。
3.1实验环境
操作系统:Ubuntu 16.04(64位);
处理器:Intel(R)Core(TM) i7-2670QM CPU @ 2.20 GHz;
处理器核心数:4核;
编译器:gcc version 5.4.0;
编程语言:c语言。
[BT5]3.2实验结果
因本文主要研究算法的高效性,而且是在线匹配的高效,所以只对2种算法的匹配时间效率进行分析,暂不考虑算法的空间效率(占用内存大小)和算法的预处理时间。
[JP2]实验选择数据中,测试目标文本大小分别为:10 M、100 M、500 M、[JP]1 024 M;模式串集个数分别为10、100、300,模式串长度则为5-1 000内,任意长度。
当模式串个数固定为300时,对应不同的目标文本长度,算法测试数据结果如表1所示。
2种算法对不同目标文本效率对比则如图4所示。
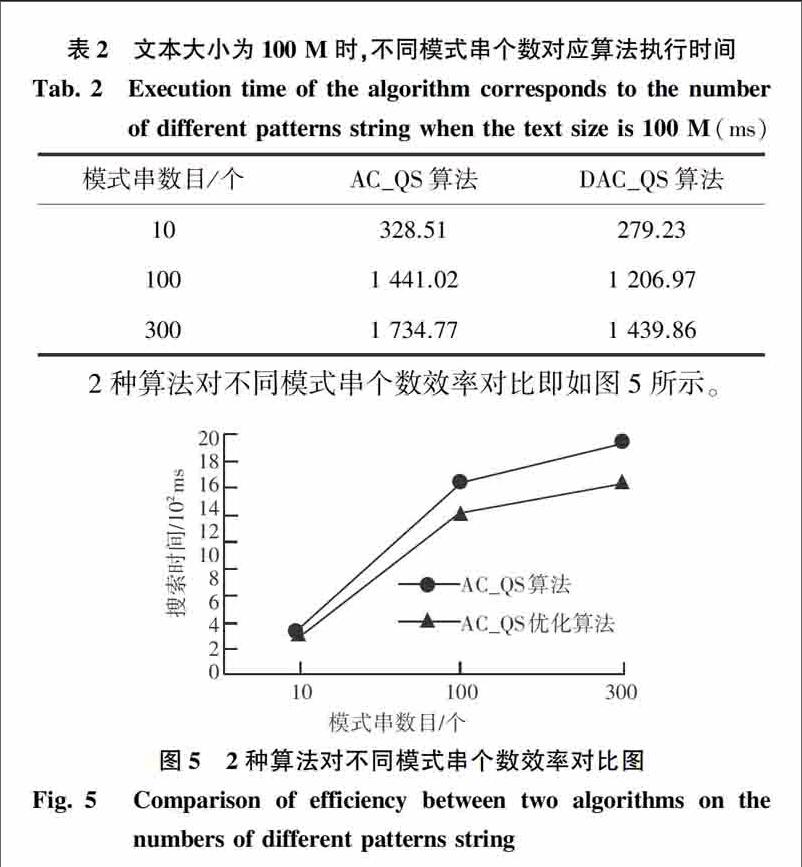
2种算法对不同模式串个数效率对比即如图5所示。
3.3实验分析
通过对以上结果的分析,可以得出本文所提出的优化算法在效率上具有更好的匹配效率,能达到15%左右的优化幅度,跟模式串的个数和文本大小关系不大。
4结束语
本文在AC_QS算法的基础上,对原算法运行过程中的几
[LL]个重要步骤:模式串预处理、字典树存储和匹配过程中提出了针对性的优化,提出了DAC_QS算法,实验结果显示,提出的优化算法在空间和时间复杂度上得到进一步优化,在效率上具有更好的匹配效率,能达到15%左右的优化幅度,证明了DAC_QS算法的有效性。
参考文献ALTSCHUL S F, GISH W, MILLER W, et al, Basic local alignment search tool[J]. J. Molecular Biology, 1990,215(3):403-410.
[2]FAN J J, SU K Y. An efficient algorithm for matching multiple patterns[J]. IEEE Transactions on Knowledge and Data Engineering, 1993,5(2):339-351.
[3] AHO A V, CORASICK M J. Efficient string matching: An aid to bibliographic search[J]. Communications of the ACM, 1975, 18(6):333-340.
[4]BOYER R S. MOORE J S. A fast string searching algorithm[J]. Communications of the ACM,1977,20(10):762-772.
[5] COMMENTZWALTER B.A string matching algorithm fast on the average[C]//Proc. 6th International Colloquium on Automata, Languages, and Programming. London, UK:ACM, 1979:118-132.
[6]HORSPOOL R N. Practical fast searching in strings[J]. Software Practice and Experience, 1980,10(6):501-506.
[7] WU Sun, MANBER U. A fast algorithm for multipattern searching[R]. Tucson, AZ:University of Arizona, 1994.
[8] [JP4]SUNDAY D M. A very fast substring search algorithm[J]. Communications of the ACM,1990,33(8):132-142.
[9] KNUTH D E, Jr MORRIS J H, PRATT V R. Fast pattern matching in strings[J]. SIAM Journal on Computing,1976(2):323-350.[endprint
