基于XML的农产品溯源平台中模式匹配问题的研究
2016-05-03史涛沈艳霞
史涛+沈艳霞

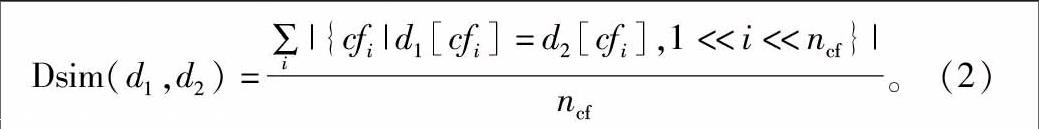
摘要: 针对基于XML的农产品溯源平台中的数据集成问题,提出一种XML Schema模式匹配方法。该方法同时考虑元素的语义性和结构性,结合文档元素的名称、数据类型以及基数约束3个方面,通过相应的度量标准计算出元素的语义相似度,实现语义匹配;通过计算模式树中元素节点的祖先相似度,同时考元素本身的语义相似度,实现结构匹配。阐述了匹配算法的设计过程和试验评估结果。结果表明,相比较现有的几种方法,该方法能实现全自动化的匹配过程,提供更精确的匹配结果。
关键词: 农产品;XML Schema;模式匹配;算法
中图分类号: S126 文献标志码: A 文章编号:1002-1302(2016)03-0442-04
近年来,农产品质量安全问题成为国民关注的重要民生问题[1]。建立面向农产品质量溯源的公共平台,向消费者提供农产品从生产、加工、流通到销售的一个完整的生命周期信息,是避免有质量安全或伪劣产品流入市场,确保食品安全的重要保障[2]。
由于具有平台独立性、可扩展性、自描述性等特点,XML已成为农产品溯源信息网络传输与交换的主要标准[3]。基于XML的农产品溯源系统采用统一的方式来处理不同地区、不同数据源的农产品信息,屏蔽构农产品溯源信息在结构、运行环境上的差异,采用XML构造数据转换的中间层,实现农产品溯源信息的无缝集成。利用XML开发的系统,农产品溯源信息管理员只需遵循一些基本的结构规则,就可以便捷地创建包含溯源信息的XML文档,并将其存储在分布式的计算机环境中。这些结构规则通常通过XML Schema(XSD)和文档类型定义(DTD)得到。XSD本身就是XML 文档,与DTD相比,在支持数据类型和空间定义方面表现更好,更适合为农产品溯源信息定义结构[4]。然而使用不同的XSD文档描述的农产品数据在集成过程中会带来相互冲突的问题,在农产品XSD文档中,许多元素具有相同的语义,但它们的名称和结构可能不同,相反许多元素具有相同的模型,但语义不同。因此,在农产品数据的有效集成中,主要问题之一就是如何在XSD文档中计算出元素之间的相似度,实现高质量的模式匹配。
目前,关于XML模式匹配的研究已取得了一些研究成果。Kim等将树-树的匹配问题分步转换成路径-路径、节点-节点,最终转换成单词-单词的匹配问题[5],该方法的不足之处在于语义匹配算法中没有考虑数据类型和基数约束,匹配精度不高。Wojnar等提出了一种树编辑距离算法,借鉴编辑距离的思想,用语言匹配计算得到元素对应的语言相似值作为输入,计算某一元素的结构完全变为另一个元素结构的操作步数,从而计算结构相似值,其理论主要集中在结构计算[6]。Lee等通过聚合DTD的元素来计算出DTD树之间的相似度[7],Ye等在其聚合方法中增加了权值因素[8]。文献[7]提出的聚合方法(XClust)允许相似的信息存储在一起,分类信息的标准越高,聚合数据的质量就越高。然而,XClust方法主要依赖于人为判断和结构化信息去聚合DTD元素;更重要的是,该方法没有考虑DTD中属性的数据类型相似度。近几年,部分研究借鉴实体识别研究领域的思想来进行模式匹配研究,例如使用一个原型工具Dedoop(使用 Hadoop 的重复删除技术)在大数据集中实现实体识别[9]。另外,基于维基百科,WordNet等的知识网络从实例角度吸引了从事调查数据源管理研究者的兴趣[10]。WordNet广泛用于匹配系统[11]中,例如网络搜索[12]和网络查询扩展[13]。在本研究中也使用WordNet来计算元素的名称相似度。
现阶段的一些研究方法只考虑元素的名称相似度或者结构相似度的计算[5-6],虽然有些研究已经都考虑语义和结构[7],但其度量标准中的部分因素需要通过人为判断来确定。针对农产品溯源信息的XML数据量巨大,且包含对于数据类型和基数约束的多种定义,需要更标准的度量标准得出精确的相似度值。因此,本研究综合考虑元素的语义匹配和结构匹配,提出一种新的XML Schema模式匹配方法。语义匹配中,综合考虑元素的名称、数据类型以及基数约束,提出相应的度量标准计算相似度,无需人为判断,提高匹配精度和效率;结构匹配中,考虑元素中节点的祖先相似度,同时将语义相似度作为计算的参数之一,提高结构匹配的精确度。通过性能研究以及同相关方法对比实现对本研究方法的评估,可以从XSD农产品溯源数据中通过全自动化的方式计算出元素之间的语义和结构相似度,实现模式匹配。
1 模式匹配概念
模式是代表一件设计物的一个比较正式的结构,如XML模式、SQL模式和实体-关系模式等[14]。对于任意的模式S1和S2,模式S1中的某些元素映射到模式S2中的某些元素,其中的映射元素又称为匹配元素对,映射叫匹配结果。模式匹配的目标是利用模式间的所有可用信息,得出模式间最匹配的元素。
模式匹配定义:模式匹配定义为一个函数,输入值为2个模式,输出值为模式之间的相似度计算结果。
相似度计算:对于模式S和T,元素s∈S,t∈T。相似度计算表示一个函数,输入值为s和t,输出值为s和t之间的相似度sim(s,t),其中0≤sim(s,t) ≤1。
相似度表示2个元素之间的相似性,为了精确地评估一个元素对的相似度,相似度计算应该充分考虑元素的特征以及其结构。相似值的大小范围是[0,1],0代表2个元素基本不相似,1代表2个元素相似度极高甚至是完全相同。
2 匹配算法设计
2.1 语义匹配
概念的语义性在文本文档的集成过程中具有重要的作用[14]。XML Schema的语义包含词汇、内容模式以及数据类型。通常来说,XML Schema使用标准的命名空间(xs或xsd)和对应的统一资源标识符(URI)作为文档开头;利用XML Schema,可以定义文档中元素可能出现的次数,分别表示为maxOccurs和minOccurs 2种属性;更重要的是,简单类型和复杂类型元素帮助区分元素中2种属性类型的数据类型相似度[15]。
本研究中,对于任意2个元素s1∈T1,s2∈T2,其语义相似度综合考虑元素名称、数据类型和基数约束3个方面,如公式(1)所示:
式中:Sesim为语义相似度;α和β为程序设定的权值;Namesim(e1,e2)、Dsim(d1,d2)、Csim(e1,e2)分别为名称相似度,数据类型相似度以及基数约束相似度,具体计算分3步骤完成。
2.1.1 步骤1名称匹配 语义相似度计算中的关键因素是元素本身的语言相似度。在实际的农产品溯源XML Schema文档中,表示同一对象的元素可能出现缩写,带有连接符号等形式,导致基于语言本身的差异。首先进行3个预处理步骤:(1)使用符号分析器,将复合词组拆分为独立的单词;(2)通过查找WordNet,将缩写的单词还原成词汇本体;(3)删除惯词、介词等修饰词。预处理完成后,利用表格中的算法对元素e1和e2进行名称相似度的计算。其中,在WordNet中e2的同义词库中,利用深度优先搜索算法查找是否含有e2的同义词,直到e2被匹配。如果没有匹配结果,则语言相似度返回0,否则其值为0.9distance。具体算法如表1所示。
2.1.2 步骤2数据类型匹配 在XML Schema文档,每个元素都是简单类型或者复杂类型。如果2个元素有相同的名称,且数据类型属性是相同的,二者之间的语义相似度可能高于其他情况。对于2个叶元素,考虑其数据类型描述。由于数据类型伴随着属性元素,数据类型相似度的计算仅适用于2种元素都为属性的情况。当2种元素,其一为复杂类型而其二为简单类型,则二者的数据类型相似度为0。
不同于文献[16]提出的方法,数据类型相似度值通过用户判断决定,本研究探索每个数据类型的内部特征,并比较数据类型之间的关联性,通过具体的公式计算实现。基于文献[17]关于XML Schema数据类型的总结,本研究对数据类型的各个约束方面求出数据类型相似度。在此,将其命名为Dsim,由以下公式得出:
Dsim(d1,d2)=∑i|{cfi|d1[cfi]=d2[cfi],1< (2)
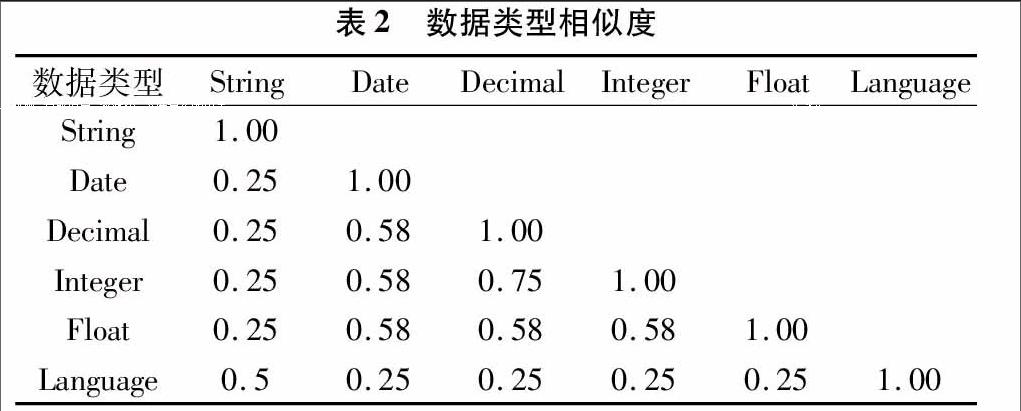
式中:d1和d2为表1中的任意数据类型;cfi为数据类型约束方面的列表,其中包括长度、最小长度、最大长度、模式、枚举数、空格数等等;ncf为约束方面的总个数,本例中ncf为12。
表2显示了XML Schema中6种典型属性类型的数据类型相似度结果。表中的具体值由公式(2)计算得出。在表1中,整数型与小数型2者之间的相似度大于其他类型。当2种元素数据类型相同时,二者相似度最高,为1.0。
2.1.3 步骤3基数约束匹配 基数约束可以描述为XML Schema文档中minOccurs(最小可能)和maxOccurs(最大可能),分别定义1个元素在XML文档中出现次数的最小值和最大值。
定义Csim(e1,e2)为元素d1和d2之间的基数约束相似度。不同于文献[15]提出的约束表格需要通过人为判断得出,本研究通过具体公式来计算约束相似度。对于具体的minOccurs和maxOccurs值,使用公式(3)计算基数约束相似度:
式中,min和max分别为minOccurs和maxOccurs的缩写。一般情况下,minOccurs被指定为0或1,而maxOccurs被指定为1或无穷大。为了计算出具体Csim的值,参考文献[18]的分析,使用公式如下:
结合公式(3)和(4),可以计算出属性基数约束的相似度,如表3所示。其中unbound=5。
2.2 结构匹配
在树结构中,2个元素节点的结构相似度取决于二者在树中的所处位置。即使2个元素节点的语义相似,也无法得出它们各自的祖先相似;但仅仅考虑元素的祖先相似度并不可取,原因在于可能存在2个节点结构相同但语义完全不同。本研究采取计算节点的祖先相似度,同时考虑节点的语义相似度的方法,提高结构匹配的精确度。
范数定义:设V=[x1,x2,…,xn]为一个向量,且V∈Rn,则其范数(欧几里得距离)表示为‖V‖=2∑n i=1xi2。
利用范数可以更有效地运用权值概念。举例说明,如果S=(a,b,b,a,c,b,c)为一组节点,其中a,b,c的权值分别为2,3,2。因此,如果将这些权值保存在如N=[2,3,2]的向量中,则S的范数为‖S‖=222+32+22=217。该范数将起到相似度值的规范化作用。
设T1和T2分别表示XML Schema文档的2棵树,提出其相似度计算如公式(5)所示:
式中:Sesim(e1i,e2j)为元素e1i和e2j的语义相似度值(由公式(1)计算得到);PCC(r1→e1i,r2→e2j)(Path Context Coefficient)表示分别从根节点r1和r2到e1i和e2j的路径相似度。实际上,PCC(r1→e1i,r2→e2j)为元素e1i和e2j的祖先相似度;当2个节点在语义上相同或者高度相似时,只要节点的祖先不相似,则二者不相似。PCC(r1→e1i,r2→e2j)的具体计算公式如下:
式中:Sesim(n1k,n2l)为节点n1k和n2l的语义相似度值;节点n1k和n2l分别属于路径r1→e1i和r2→e2j;p和q分别为2条路径上的节点数目;P1和P2为2个向量,其值分别表示为从属于2条路径上的节点权值。
原则上,公式(7)应该适用于所有节点;然而,假设元素e1i和e2j中至少一个为根节点,则其很明显没有祖先。因此,该相似度计算在系统上存在偏差。为了弥补系统偏差,当出现上述情况时,令PCC(r1→e1i,r2→e2j)=1。
2.3 元素匹配
本研究同时考虑XML Schema树中元素的结构性和语义性。因此,2个XML Schema中的元素相似度可以由上述2个部分计算得到:
当计算得到2个XML Schema中所有的元素对的相似度,可以计算出2个XML Schema的相似度。2棵XML Schema树的相似度由下式计算可得:
3 试验评估
为了验证此方法的有效性,将本研究方法与现有的2种方法,即XClust[7]和XMLSim[19]进行试验对比。试验数据源选用超过20组的XML Schemas(以及对应的DTDs)。试验采用的硬件环境为Intel Core i3 CPU,内存为4GB,操作系统为Windows 7,测试平台是Altova Spy和Microsoft Visual Studio 2010标准环境,系统代码通过C#实现。试验中选取的权值分别为α=0.3,β=0.3,δ=0.6,ε=0.6。通过上述3种匹配算法得到的结果显示在表4中。
如表4中所示,XMLSim匹配率最低,原因在于XML文档中的实例数目是可变的,且各文档之间大多不相同。当文档中的节点与另一个文档中的节点匹配成功后,算法开始计算下一对节点。因此,如果2个文档中的节点数目不同时,匹配值将会下降。
为了更好地评价3种匹配方法,本研究使用Do H-H[20]提出的评价标准,分别为查准率(precision)、查全率(recall)、F_measure,如下公式:
试验在相同的权值和相似度阈值的条件下,得出本研究方法Esim与XMLSim以及XClust方法的计算结果,如图1所示。
试验结果表明,本研究方法的匹配质量高于XMLSim和XClust这2种方法。原因在于,XClust方法没有考虑元素之间的数据类型相似度,然而一些元素对可能有同样的名称,但数据类型不同。XMLSim方法过于重视信息本身内容的相似度,而没有考虑元素之间的数据类型和基数约束相似度,匹配质量最低。
4 结论
本研究针对基于XML的农产品溯源信息平台中异构源XML数据集成问题,提出了一种基于元素语义性和结构性的模式匹配方法。语义性方面,综合考虑数据名称、数据类型以及基数约束3个方面,通过研究分析推断出具体计算公式,无需人为判定;结构性方面,同时考虑元素的祖先相似度与语义相似度,提高相似度计算精度。通过试验比较目前的相似度计算方法,本研究提出的方法计算精确度更高,具有较好的可行性。本方法实现了完全自动化转换,大大减少了人工劳动,提高了效率,具有一定的研究意义。下一步,结合本研究的模式匹配算法,将对农产品溯源信息平台的异构XML数据集成模块进行研究设计。
参考文献:
[1]白红武,孙爱东,陈 军,等. 基于物联网的农产品质量安全溯源系统[J]. 江苏农业学报,2013,29(2):415-420.
[2]毛 林,程 涛,成维莉,等. 农产品质量安全追溯智能终端系统构建与应用[J]. 江苏农业学报,2014,30(1):205-211.
[3]杨信廷,钱建平,赵春江,等. 基于XML的蔬菜溯源信息描述语言构建及在数据交换中的应用[J]. 农业工程学报,2007,23(11):201-205.
[4]Amano S,David C,Libkin L,et al. XML schema mappings:data exchange and metadata management[J]. Journal of the ACM,2014,61(2):488-507.
[5]Kim J,Peng Y,Ivezic N,et al. An optimization approach for semantic-based XML schema matching[J]. Int J Trade Econ,Finance,2011,2(1):78-86.
[6]Wojnar A,Mlnková I,Dokulil J. Structural and semantic aspects of similarity of Document Type Definitions and XML schemas[J]. Information Sciences,2010,180(10):1817-1836.
[7]Lee M L,Yang L H,Hsu W,et al. XClust:clustering XML schemas for effective integration[M]. ACM Press,2002:292-299.
[8]Ye Y,Li X,Wu B,et al. A comparative study of feature weighting methods for document co-clustering[C]. IJITCC,2011:206-220
[9]Kolb L,Thor A,Rahm E. Dedoop:efficient deduplication with Hadoop[J]. Proceedings of the VLDB Endowment,2012,5(12):1878-1881.
[10]Tagarelli A. Exploring dictionary-based semantic relatedness in labeled tree data[J]. Information Sciences,2013,220:244-268.
[11]Shvaiko P,Giunchiglia F,Yatskevich M. Semantic matching with S-Match[M]. Semantic Web Information Management:A Model-Based Perspective,2010:183-202.
[12]Pyshkin E,Kuznetsov A. Approaches for web search user interfaces:how to improve the search quality for various types of information[J]J Conver,2010,1(1):1-8.
[13]Klyuev V,Yokoyama A. Web query expansion:a strategy utilizing Japanese WordNet[J]. J Conver,2010,1(1):23-28.
[14]Agreste S,de Meo P,Ferrara E,et al. XML matchers:approaches and challenges[J]. Knowledge-Based Systems,2014,66:190-209.
[15]Gong J,Cheng R,Cheung D W. Efficient management of uncertainty in XML schema matching[J]. The VLDB Journal,2012,21(3):385-409.
[16]Algergawy A,Nayak R,Saake G. Element similarity measures in XML schema matching[J]. Information Sciences,2010,180(24):4975-4998.
[17]Dan V. XML schema-data types quick reference[EB/OL]. [2015-04-01]. http://www.xml.dvint.com.
[18]Thu P T T,Lee Y K,Lee S. Semantic and structural similarities between XML Schemas for integration of ubiquitous healthcare data[J]. Personal and Ubiquitous Computing,2013,17(7):1331-1339.
[19]Resnik P. Semantic similarity in a taxonomy:An information-based measure and its application to problems of ambiguity in natural language[J]. Journal of Artificial Intelligence Research,1999,11:95-130.
[20]Do H H. Schema matching and mapping-based data integration[D]. University of Leipzig,2005.
