基于背景差分的一种运动目标检测方法
2015-04-25张传伟王京梅林晓明赵文俊
张传伟,王京梅,林晓明,赵文俊
(电子科技大学 微电子与固体电子学院,四川 成都610054)
运动目标检测是计算机图像处理领域中的一个重要课题,而清晰、完整的检测结果是目标识别、跟踪、定位的前提和关键。因此,寻找出一种精确可靠的运动目标检测方法尤为重要。从基本原理上,运动目标检测可分为光流法[1]、帧差法[2]、背景差分法[3]等几种方法,另外就是这几种的方法改进或组合[4-5]。鉴于光流法计算复杂,帧差法易产生空洞的不足,背景差分法成为人们研究的热点。背景差分法即通过对当前帧与背景图像做差来检测运动目标,针对于其中的背景建模,已有大量的研究成果。例如有均值法、中值法、高斯模型法、核密度估计法、W4法、VIBE法、码本法等[6],而每种建模方法又有其特定的适用环境。除了对背景建模的研究,也有越来越多的算法开始考虑颜色特性及阈值选取。文献[7]和文献[8]论述了在RGB彩色空间下的运动目标检测过程。文献[9]最早提出利用双阈值的方法提高检测的精确度。本文针对运动目标与背景颜色相近的情形,基于YUV彩色空间,差异性地选取3个通道的阈值,在初次检测之后增加对于运动目标区域的二次检测,提出了一种检测完整运动目标的方法。
1 颜色空间选取
传统的背景差分法都是先将摄像头采集到的图像灰度化,然后在此基础上再进行背景建模等后续处理。某些时候,当运动目标与背景颜色不同时,灰度化后却有可能得到相同的灰度值,此时就不能通过背景差分法来检测运动目标。为克服这一缺点,最大化地利用图像中的色彩信息,需要在彩色空间下直接对图像进行处理。
常见的彩色空间的表示方法有RGB模型、YUV模型、HIS模型、HSV模型、Lab模型等[10],各彩色模型之间可通过公式进行互相转换。其中,YUV模型是欧洲电视系统采用的一种颜色编码方式,Y代表亮度;U和V代表色差,构成两个颜色分量。YUV模型的一个优势是将亮度信号与色度信号分离,二者互不干扰。为了能将亮度信息和色度信息分开独立地处理,本文选择在YUV彩色空间下对3个通道进行独立检测。
2 初次检测
虽背景建模在背景差分法中是极其重要的一步,但本文重点在于颜色特性及阈值的选取。因此本文选用计算较为简单的均值法建立背景模型。从计算的角度,一幅彩色图像可看作一个矢量函数。对于一幅m×n像素的YUV彩色图像,将其表示为
FYUV(x,y)=[FY(x,y),FU(x,y),FV(x,y)]T
其中,FY(x,y)、FU(x,y)、FV(x,y)为YUV分量。x,y为像素点整数坐标,且x∈[1,m],y∈[1,n]。

从第N+1帧开始,将当前帧与背景图像做差,差分后的图像为

针对于YUV分量的不同,选取适合各自通道的阈值进行二值化,计算方法如下
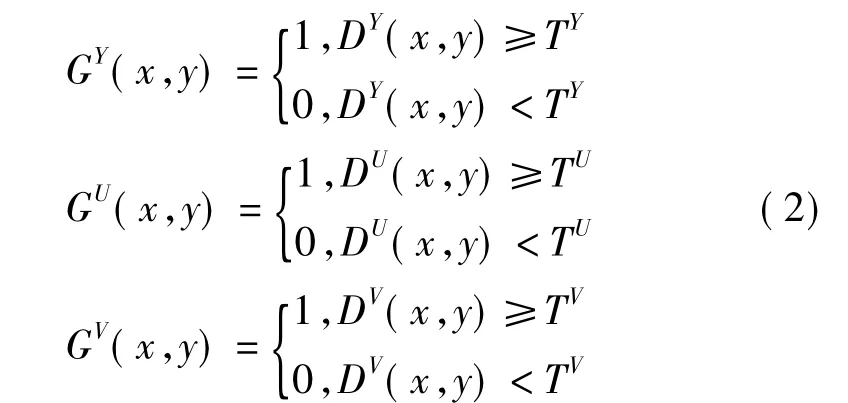
其中,GY(x,y),GU(x,y),GV(x,y)为YUV分量的二值图像;TY,TU,TV分别为3个分量的阈值。
对于式(2)中阈值的选取,采用迭代算法,步骤如下:
(2)利用阈值T把图像分成两个区域R1和R2。
(3)对区域R1和R2中所有像素计算平均值u1和u2。
为避免视频中暂时没有运动目标时产生的误检,在此对迭代法自动选取的阈值最小值进行限制。设定YUV的3个分量的最小阈值分别为tY,tU,tV,通过迭代法得到的阈值为TY,TU,TV,令。式中,为最终阈值。由Y分量代表亮度信息;U、V分量代表色差,可知Y分量对光照的明暗变化更为敏感。为减弱光照对运动目标检测的影响,在此可设定tY>tU=tV。
最终,将得到的YUV分量的二值图像取或运算得

3 二次检测
当运动目标上含有与背景颜色相近的区域时,尽管充分利用了视频中的色彩信息并采用自适应方法选取阈值,这部分区域仍可能被误认为是背景像素而无法检测到。如果此时直接选取更低的阈值进行分割,则会引入大量的背景噪声。为解决此问题,本文在初次检测之后,划定一个包围初次检测得到运动目标的矩形区域,在这个小的矩形区域中再选取更低的阈值进行分割,以便排除其他范围内的噪声影响。具体步骤如下:
(1)找出初次检测所得二值图像G(x,y)中等于1的元素的连通域,个数记为S。
(2)计算出第s(1≤s≤S)个连通域中的元素行坐标最小值、行坐标最大值、列坐标最小值、列坐标最大值,则顶点为的矩形Rs恰好包围第s个连通域。
(3)提取出当前FYUV(x,y)帧和背景图像BYUV(x,y)中对应于矩形区域Rs的元素,即FYUV(x,y)和BYUV(x,y)中x、y取值为的部分。
(4)根据式(1)~式(3),对提取出的部分再次差分和二值化,得到二值图像Gs(x,y)。其中,。
(5)用Gs(x,y)替代相应G(x,y)的部分,得到新的二值图像G'(x,y),此即最终检测得到的运动目标图像。
步骤(4)中的阈值要小于初次检测时的阈值,以便将颜色相近的部分有效检测出。可在初次检测使用的阈值基础上再减去一个固定值,即
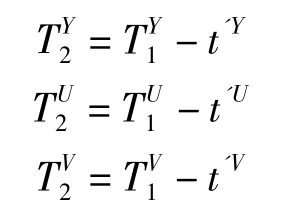
式中,t'Y、t'U、t'V的值可由实验获取。
4 实验结果与分析
为验证本文提出的方法的有效性,利用Matlab软件对本文方法和常规方法进行编程实现,并将仿真结果进行对比。同时,将本文所提方法的初次检测结果与二次检测结果进行对比。为使对比实验更加严谨,实验中背景建模都采用均值法,阈值采用迭代法自动获取。选取的视频中图像序列为15帧/s,360×240像素。

图1 视频中背景图像及运动目标
首先,运用传统方法,将图像灰度化后采用背景差分法对运动目标进行检测,检测结果如图2所示。由于运动的人物目标中有部分区域的灰度值和背景图像灰度值很接近,导致检测得到的运动目标并不完整,效果不理想。

图2 传统的背景差分法检测结果
然后运用本文的方法在YUV颜色空间下对运动目标进行检测。图3中(a)、(b)、(c)分别为YUV的3个通道单独检测时所得运动目标。从图中可知,虽然单独一个通道并没有检测到完整的运动目标,但每个通道都检测到了目标的不同部分。由此,将YUV的3个分量取或运算,可得到较为完整的运动目标,检测结果如图3(d)所示,在YUV颜色空间下采用背景减除法所得到的运动目标比直接灰度化所得运动目标要完整。

图3 YUV通道下检测结果
虽图3中检测到的目标完整度有所改善,但对比原图像可以发现,图中人物的左臂仍未被检测到。因此,需要进行二次检测以获取更加完整的运动目标。图4所示为经过二次检测之后所得运动目标,可看出,此时所得结果更为清晰完整,基本将运动的人物目标身体各部分完全检出。

图4 最终检测结果
5 结束语
本文重点针对运动目标检测的完整性问题,提出了在YUV颜色空间下,充分利用3个通道的信息,选取适应于各自通道的阈值,进行背景差分。在初次检测的结果基础上,划定一个包含运动目标的矩形区域,在此区域中使用更低的阈值进行检测。实验结果证明,通过本方法,可有效地将运动目标完整检出。
[1]Senst T,Evangelio R H,Sikora T.Detecting people carrying objects based on an optical flow motion model[C].Washington DC:Proceeding of IEEE Workshop on Applications of Computer Vision,IEEE Computer Society,2011:301-306.
[2]Ebisawa Y.Robust pupil detection by image difference with positional compensation[C].VEC-IMS,2009:143-148.
[3]Mohamed S S,Tahir N M,Adnan R.Background modeling and background subtraction performance for object detection[C].Proceeding of the 6th International Colloquium on Signal Processing and Its Applications,2010:236-241.
[4] 高美凤,刘娣.分块帧差和背景差相融合的运动目标检测[J].计算机应用研究,2012,29(1):299-302.
[5] 袁国武,陈志强,龚健,等.一种结合光流法与三帧差分法的运动目标检测算法[J].小型微计算机系统,2013,34(3):668-671.
[6] 代科学,李国辉,涂丹,等.监控视频运动目标检测减背景技术的研究现状和展望[J].中国图象图形学报,2006,11(7):919-927.
[7] 徐以美,郭宝龙,陈龙.基于RGB颜色空间的减背景运动目标检测[J].计算机仿真,2008,25(3):214-217.
[8] 吴青青,许廷发,闫辉,等.复杂背景下的颜色分离背景差分目标检测方法[J].兵工学报,2013,34(4):501-506.
[9]Boult T E,Micheals R,Gao X,et al.Frame-rate omnidirectional surveillance and tracking of camouflaged and occluded targets[C].Colorado:Proceedings of the 2nd IEEE Workshop on Visual Surveillance Fort Collins,1999:48-55.
[10]张铮,王艳平,薛桂香.数字图像处理与机器视觉[M].北京:人民邮电出版社,2010.
